
一类分类数据列联表中基于检验功效的样本量研究
2009-07-05 14:24王顺芳王学仁
纯粹数学与应用数学 2009年3期
王顺芳,王学仁
(1.云南大学信息学院,云南昆明 650091;2.云南大学统计系,云南昆明 650091)
一类分类数据列联表中基于检验功效的样本量研究
王顺芳1,王学仁2
(1.云南大学信息学院,云南昆明 650091;2.云南大学统计系,云南昆明 650091)
对不完全2×2列联表中关于风险比(RR)的假设检验问题,使用基于约束性极大似然估计下的Wald检验统计量和对数变换检验统计量,导出了满足预先给定功效的样本量公式.模拟结果验证了所给检验和样本量公式的合理性,实例分析解释了上述方法的应用.
约束性极大似然估计;功效;样本量
1 引言
在流行病学、生物学以及各种临床研究中经常需处理大量的分类数据问题,其中一类较常见的分类数据可概括为不完全2×2列联表的形式,这类列联表中某一格(一般位于非对角元素上)的频数始终为零,这是结构本身所固有的,称为”结构零”.一般情况下,此类列联表的结构可概括为表1.表1中的结构零位于第(2,1)格,其中0<πij<1((i,j)=(1,1),(1,2)和(2,2))代表相应

表1 不完全2×2列联表
事件发生的概率,π1+=π11+π12,π1++π22=1.a,b,d是相应事件发生的频数,a+b+d=n. 当n一定时,(a,b,d)服从三项分布,其概率分布记为
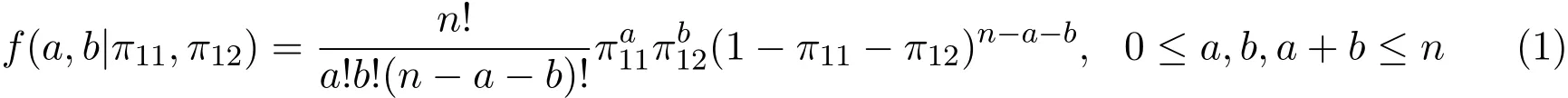
研究不完全2×2列联表时,生物医学上一个常用的统计量是风险比(Risk Ratio,简记为RR),其定义为RR=(π11/π1+)/π1+=π11/.
关于不完全2×2列联表中的风险比(RR),已有的研究工作如下:文[1]讨论了大样本下RR的置信区间估计问题,其中分别使用了基于样本估计的Wald统计量、基于样本估计的对数变换统计量以及基于Fieller定理的统计量;文[2]使用Wald统计量和对数变换统计量从小样本的角度研究了RR的精确非条件推断,提出了检验RR等于某一固定值∆0的精确非条件检验和近似非条件检验;文[3]提出了检验风险比的Score统计量,研究了基于Score方法的置信区间并和文[1]讨论过统计量进行比较.以上文献中,总的来说是Score方法的统计性能较好,在Score方法中,比较重要的一点就是对参数的约束性极大似然估计,文[4]的讨论也表明了在其所研究的情况下基于约束性极大似然估计优于基于样本的估计,于是文[5]使用了基于约束性极大似然估计的Wald统计量和对数变换统计量,对不完全2×2列联表中的风险比进行置信区间构造,导出在一定置信水平下控制置信区间宽度的样本量公式.本文继续使用基于约束性极大似然估计的Wald统计量和对数变换统计量,研究RR的大样本假设检验问题,给出了基于检验功效的渐近样本量公式.
2 两种基于约束性极大似然估计的渐进检验

它渐近服从标准正态分布;给定显著性水平α,当|T1|≥zα/2时,可拒绝原假设H0,这里zα/2表示标准正态分布的上α/2分位点.

渐近服从标准正态分布.
3 功效和样本量计算
定理1若使用检验统计量T1对假设(2)进行检验,在给定的显著性水平α下,为达到功效1−β所需的近似样本量为

定理2若使用检验统计量T2对假设(2)进行检验,在给定的显著性水平α下,为达到功效1−β所需的近似样本量为

可得检验的渐近样本量公式为(6)式.
4 模拟研究
在很多实际问题中,由于似然函数和极大似然估计的复杂性,统计上常需一些研究技巧(例如文[8]).本节为评价两种基于约束性极大似然估计的渐近检验的样本量公式(5)和(6)的精确性(即控制功效的准确程度),拟在各种参数设置下进行模拟计算.
首先应用公式(5)和(6)计算了显著性水平为5%、功效为80%(即β=0.2)下的渐近样本量.为评价这些近似样本量对功效控制的精确程度,本节类似于文[6]的模拟方法,使用如下公式计算了和这些样本量对应的经验功效和经验第一类错误率

其中M是试验重复次数,(a,b)(i)是第i次试验的观察值,R={(a,b)(i):|Tj|≥zα/2,j= 1或2}是拒绝域,I(·)是示性函数(当(a,b)(i)∈R时其取值为1,否则其取值为0);且当各(a,b)(i)(i =1,…,M)是在H0下产生的随机观察值时,(7)式表示经验第一类错误率,当各(a,b)(i)(i= 1,…,M)是在H1下产生的随机观察值时,(7)式表示经验功效.模拟研究中,试验重复次数根据收敛情况设置为10000(即M=10000),当某次试验产生的观察值(a,b)使得统计量T1或T2没有定义时,就用a+0.5,b+0.5,n+1.5分别替换a,b,n后再做计算.整个结果归纳为表2.

表2 统计假设(2)在控制检验功效为80%下的近似样本量(α=5%),及相应的经验功效(EP)和经验第一类错误率(ETI)

表2 (续)
分析表2,总的来说,检验T1和T2得到的样本量比较接近,其经验功效一般都能保证80%的水平,经验第一类错误率也都非常接近5%,说明样本量公式(5)和(6)都比较精确.进一步比较发现,当∆<∆0时,同样的参数设置下,检验T1得到的样本量比T2的大;而当∆>∆0时,检验T1得到的样本量比T2的小.因此在实际应用中,当∆<∆0时,可使用基于约束性极大似然估计的对数变换检验统计量;当∆>∆0时,可使用基于约束性极大似然估计的Wald检验统计量.
5 实例分析
本节将前面所得方法和结论应用于文[7]中提到的一实例:小牛的二次感染数据.这一实例考虑了出生于佛罗里达州奥基乔比的156头小牛组成的一个样本,先根据它们在出生60天后是否感染了肺炎分成两类,并对感染了肺炎的小牛进行治疗,等到初次感染治愈后再过两周又根据它们是否感染肺炎再分类,从理论上来说,小牛若没有初次感染,就不存在二次感染,这样在2×2列联表中就引入了一个“结构零”,它对应于初次无感染而二次被感染的情况.此例的数据结构见表3.根据表3的数据,风险比(RR)的样本估计为ˆ∆=0.5411.考虑假设问题(2),取∆0=1.0,经计算,T1=−3.2563,T2=−4.3579,它们相应的p值分别为0.0011和0.00001,若显著性水平为0.05,则可拒绝H0,说明初次感染和二次感染的概率不等.
对这个问题作进一步的拓展,假定研究者想做一个类似于文[7]工作的另一种流行病学研究,同样考虑检验假设(2),其中∆0=1.0,显著性水平给定为α=0.05.当备择假设成立时,例如∆=0.9,π1+=0.7,一个感兴趣的问题是需要多大的样本量才能达到80%的功效.通过计算就可以得到,对应于统计量T1,T2分别需要911和873个个体.

表3 小牛二次感染问题的统计数据
[1]Lui K J.Interval estimation of risk ratio between the secondary infection given the primary infection and the primary infection[J].Biometrics,1998,54(2):706-711.
[2]Tang N S,Tang M L.Exact unconditional inference for risk ratio in a correlated 2×2 table with structural zero[J].Biometrics,2002,58(4):972-980.
[3]Tang M L,Tang N S,Carey V J.Confidence interval for rate ratio in a 2×2 tables with structural zero:an application in assessing false-negative rate ratio when combining two diagnostic tests[J].Biometrics,2004,60(2): 550-555.
[4]Wang S F,Tang N S,Wang X R.Analysis of risk difference of marginal and conditional probabilities in an incomplete correlated 2×2 table[J].Computational statistics and data analysis,2006,50(6):1597-1614.
[5]王顺芳,王学仁.不完全2×2列联表中基于置信区间的样本量研究[J].云南大学学报:自然科学版,2007,29(2):109-113.
[6]Wang S F,Wang X R.Homogeneity test of risk differences of marginal and conditional probabilities in several incomplete correlated 2×2 tables[J].Communications in Statistics-Theory and Methods,2007,36(16),2877-2890.
[7]Agresti A.Categorical Data Analysis[M].New York:Wiley,1990.
[8]任丽梅,师义民.多重II型删失数据场合Logistic分布参数的近似似然函数[J].纯粹数学与应用数学,2007,23(3):341-346.
Sample size determination for power in a sort of contingency table
WANG Shun-fang1,WANG Xue-ren2
(1.School of Information Science and Engineering,Yunnan University,Kunming650091,China; 2.Department of Statistics,Yunnan University,Kunming650091,China)
To test the hypothesis about risk ratio(RR)in an incomplete correlated 2×2 table,a Wald-type test statistic and a logarithmic transformation test statistic on the basis of the constrained maximum likelihood estimation(CMLE)method are proposed.Sample size formulae are derived to guarantee a prespecified power. Simulation results show that the above tests and formulae are valid.An example is used to illustrate the method.
constrained maximum likelihood estimation,power,sample size
O212.1
A
1008-5513(2009)03-0425-06
2008-03-12.
国家自然科学基金(10901135,10626048,10761011),云南省社发计划应用基础研究面上项目(2008CD081),云南大学中青年骨干教师培养计划专项经费.
王顺芳(1974-),副教授,博士,研究方向:数理统计.
2000MSC:62F03,62P10
猜你喜欢
内江师范学院学报(2022年4期)2022-04-27
内蒙古统计(2021年4期)2021-12-06
湖北师范大学学报(自然科学版)(2021年3期)2021-09-08
数学物理学报(2021年1期)2021-03-29
测控技术(2018年4期)2018-11-25
铁道通信信号(2018年9期)2018-11-10
无线互联科技(2017年24期)2018-01-22
上海精神医学(2017年5期)2017-11-29
职工法律天地·下半月(2017年8期)2017-07-24
统计与决策(2012年14期)2012-07-25
