
定期维护书目数据中格式问题的有效方法
2009-09-02 06:43李湜清
河南图书馆学刊 2009年3期
关键词:批处理
李湜清
关键词:CNMARC数据;数据检查;批处理
摘 要:本文总结了书目数据库中数据的来源及建立,详尽地介绍通过计算机排序方式批检查数据中的错误,以进一步提高书目数据的准确性和一致性。
中图分类号:G254.3文献标识码:A 文章编号:1003-1588(2009)03-0104-03
书目数据库是图书馆自动化建设的基础和保障,也是文献检索网络化、信息资源共享的重要依据,同时还是图书馆为读者服务的重要途径。馆藏数据库的质量直接代表了图书馆的基础业务水平。书目数据的标准化、规范化、准确化、一致化是数据库建设的核心问题,定期对数据库中的数据进行批处理检查维护可减少错误率,尤其是采用人工校对在前,批处理检查在后两者相互结合的方式,可以极大地降低书目数据中不必要的错误和不一致的著录问题。作为图书馆的编目部门,应建立起一套书目数据的维护机制,将批处理维护工作纳入日常工作之中。
以首都图书馆具体情况为例,本文所谈到的关于批处理维护的数据主要指经人工审校进入总书目库的数据,其中包括自建数据和套录数据。经过人工审校过的数据一般不存在著录方面的错误,如200字段题名责任者的选取著录、各类附注字段详细著录、名称标目的规范等,但是有不少不一致,不统一的地方,如自建数据与套录数据中丛书与附注著录的不一致,数据各字段相互对应点没有著录一致等问题。通过批处理检查的方式可以快速全面地找到错误点,比起人工翻查数据审校费时、费力是占有绝对优势的。
1 目前数据库中存在的主要问题
1.1 丛书著录不一致
丛书著录一致性是最大的问题。首先,由于总书目库中的数据是由自建数据与套录数据共同组成的,审校人员也是分组的,所以就造成了对数据著录理解不一样、著录不一致的问题;其次由于套录数据主要是下载国家图书馆和几大联合编目中心数据,各家数据著录本身就有不一致的问题存在。另外,还有一些比较模糊、难以界定的系列书也是当前编目人员在著录225字段与300字段的疑难点。
1.2 数据中对应点的问题
图书馆的编目工作是一项非常重注专业技术和认真负责的工作,一条CNMARC数据小至几百个字节,大至两千多个字节,十几项字段几十个子字段确实需要编目员具备踏实的态度和高度的责任心。从数据检查上来说,数据上的细节问题也是比较重要的,数据中的各字段中有许多与其它字段相互对应的地方,比如说210字段与102字段是相关字段;105字段与215字段、6字段都有相关的对应点。
1.3 对于主题字段的检查
相对于数据中的格式检查来说,主题字段的情况比较复杂,但是通过批处理校对,对于主题标引、分类还是可以发现一些一致性的问题。将600、601、602、605、606、607字段中的子字段$a$x$j$y$z分别抽取出来,并给予排序,可以校对出著录错误的字段,例如600字段错著为606字段等常规性问题,还可以将各字段的主题词与分类号分别给予排序,查找出不规范的用词和同类书著录不一致的问题。
2 通过批处理检查数据库中错误的方法
我馆的批处理数据方法主要是对进入总书库的数据进行定期的检查,一般每批的数据在一万至两万种之间比较适宜。在检查时,针对某一方面的问题将字段中的相关子字段按文本文件(TXT文件)抽取出来,导入至EXCLE表格中进行计算机排序。通过排序这种方法,检查人员可以更直观地检查到出现的问题。
流程为:将要检查的子字段抽取至TXT文件中→自建表格→工具→导入外部数据→导入数据→选择我的信息源→选择文件→导入→按检查问题排序→检查。
2.1 对子字段中固定内容的检查方法
对于字段中有固定内容的子字段,通过一级排序方式是比较容易排查错误的。我馆在批检查时,主要有这些子字段:010字段的$a$b$d、102字段的$a、300字段的$a、305字段的$a、306字段的$a、307字段的$a、310字段的$a、905字段的$a、801字段的$a$b$c、905字段的$f。上述这些子字段可以一次性抽取至表格中的各个列中,由于各个子字段的检查问题不相互对应,所以可以依次对每列中的内容进行排序检查。以上述几个子字段为例,抽取至表格中的形式如下:
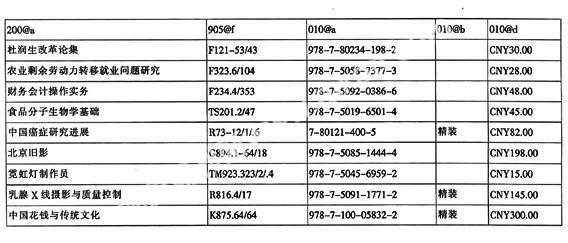
一级排序010@d后发现错误的表格:
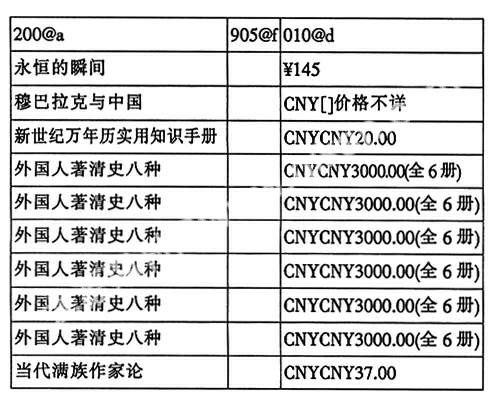
2.2 对子字段中对应点问题的检查方法
对于字段中相关子字段排查一致性问题时,就要将问题所相对应的子字段一并抽取出来,通过二级或三级排序的方法进行检查。我馆所批检查的对应子字段主要有:
100字段$a中第8-16位与210字段的$d$h、205字段的$a
102字段的$b与210字段的$a$c
105字段的$a与215字段的$c
106字段的$a与215字段的$d
200字段的$a、$e与517字段的$a
200字段的$d$z与510字段的$a、304字段的$a、312字段的$a
225字段的$a$h$i与461字段、462字段、300字段
200字段的$f$g与701字段、702字段、711、字段、712字段的$a$4
二级排序以102字段的$b与210字段的$a$c为例,相对应子字段抽取:
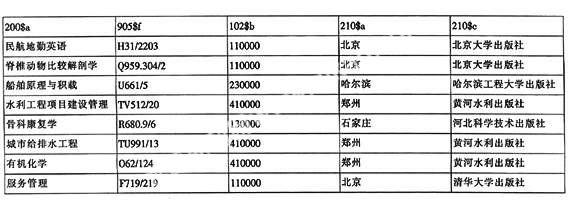
经102$b、210$a和210$c依次三级排序后检出的问题:

2.3 对主题字段的检查方法
相对于书目数据中批处理检查这种方式,对主题和分类的检查比起对格式的检查就有很大的局限性。首先主题标引和分类是比较灵活多变,一条数据经常会出现两个以上的标引字段;其次,同一主题字段的同一子字段会分入不同的大类中,与格式的固定对比是不同的。所以,我们在批处理主题标引和分类字段时,要按照大类号进行抽取,数据一次抽取在五至六万条(一个表格最多存贮6万行),然后按类号、书名和主题字段三级排序进行检查,这样既可以检查出规范用词,也可以查找到同一类、同一题名的分类标引情况。如,同一类号不同主题词:
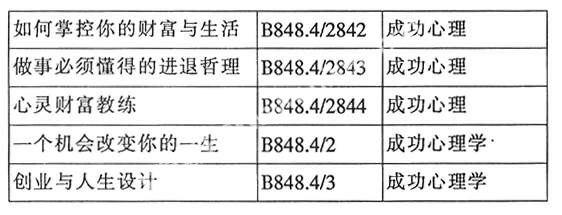
3 通过批处理审校检查出的一些问题
对于做书目数据格式校对的工作人员来说,通过批校对可以既快速又全面地检查数据中的错误点,不但节省时间和精力,而且从错误的查全率和查准率上都比人工校对要准确。以下列举一些通过批校对在具体工作中发现的错误:
其一:
010 ##$a978-7-5006-8417-6$bCNY58.00
2001#$a民营经济“试验田”:温州$9min ying jing ji“shi yan tian”:wen zhou$f卢建文著(010字段子字段著录错误,通过一级排序校出)
其二:
010##$a978-7-5317-2373-8$b精装$dCNY29.00
102##$aCN$b110000
2001#$a爱•配方$9ai•pei fang$f(美)戴安娜•德•卢卡著$g李永灿译
210##$a哈尔滨$c北方文艺出版社$d2009
(102字段$b与210字段$a$c不对应,通过二级排序校出)
其三:
2001#$a宗教论$9zong jiao lun$f冯天策著
215 ##$a341$d21cm
(215子字段$a页数无“页”字)
2001#$a赢在深圳$9ying zai shen zhen$e陈志列的研祥创业之道$f樊荣编著
2252#$a中国制造系列
2001#$a化蛹为蝶$9hua yong wei die$e金蝶集团的成功之路$f田宏文编著
300##$a中国制造系列
(丛书与附注项著录不一致的问题)
其四:
2001#$a信息霍乱$9xin xi huo luan$e世纪末的冷面杀手$f刘树秀主编$g聂巧等编著
6060#$a互连网络$x基本知识
6060#$a计算机犯罪
2001#$a畅游网络世界$9chang you wang luo shi jie$f卓越文化编著
6060#$a互联网络$x基本知识
(主题词改为用代关系,批处理替换)
4 小结
书目数据人工审校后进入总数据库并不意味着大功告成,还要进行经常性的更新和维护。通过收集编目人员在平时使用过程中的反馈信息,定期对数据内容进行更新追加、维护和修改,从而可以极大地提高数据信息资源的质量。
参考文献:
[1] 逯仰章.CNMARC的关联字段[J].图书馆园地,2007,(3).
[2] 张智慧.中文图书套录编目中出现的问题及解决方法[J].图书馆工作与研究,2006,(6).
[3] 倪娟.CNMARC数据套录问题之我见[J].科技情报开发与经济,2007,(6).
[4] 陈晓兰,张德云.论图书馆联机联合编目中套录数据质量控制问题[J].图书馆,2008,(2).
[5] 陈艳茹.丛编字段标准化著录浅析[J].农业图书情报学刊,2007,(7).
猜你喜欢
中国信息技术教育(2022年13期)2022-07-12
电脑爱好者(2021年14期)2021-07-21
科学导报·学术(2020年84期)2020-11-08
电脑爱好者(2019年1期)2019-10-30
电脑知识与技术(2018年23期)2018-11-26
科技资讯(2018年7期)2018-07-28
电脑爱好者(2017年18期)2017-11-03
现代电子技术(2017年14期)2017-07-25
数字技术与应用(2016年10期)2017-04-01
电子技术与软件工程(2017年2期)2017-03-15
