
云数据管理研究综述*
2010-06-27 02:29吴吉义傅建庆张明西平玲娣
电信科学 2010年5期
吴吉义,傅建庆,张明西,平玲娣
(1.杭州师范大学杭州市电子商务与信息安全重点实验室 杭州310036;2.浙江大学计算机科学与技术学院 杭州 310027;3.东华大学计算机科学与技术学院 上海 201620)
1 引言
在过去的近10年中,学术界与企业界以充分利用网络计算与存储资源、实现大范围的协作与资源共享、达成高效率低成本的计算为目标,相继提出了如 “网格计算(grid computing)”、“按需计算”、“效能计算 (utility computing)”、“互联网计算 (Internet computing)”、“软件即服务(software as a service)”、“平台即服务”(platform as a service)等类似“云计算”的概念和模式。“云计算”概念的正式提出是最近两年,“云计算”因其更清晰的商业模式而受到广泛关注,并得到工业和学术界的普遍认可,成为2009年最受关注的十大IT技术之一。
亚马逊 (Amazon)推出的 “简单存储服务”S3(simple storage service)和“弹性计算云”EC2(elastic compute cloud)标志着“云计算”发展的新阶段:即基础架构的网络服务作为提供给客户的新“商品化”的资源,EC2已成为亚马逊当前“增长最快的业务”。谷歌(Google)一直致力于推广以GFS(Google file system)[1]、MapReduce[2,3]、BigTable[4]技 术 为 基 础的应用引擎(app engine),为用户进行海量数据处理提供了手段。IBM于2007年推出的“蓝云”(blue cloud)计算平台[5],采用了 Xen[6]、PowerVM[7]虚拟技术和 Hadoop技术,以期帮助客户构建云计算环境。HDFS[8,9]与其他分布式文件系统有很多相似,但由于其设计基于硬件失效(hardware failure)、流式数据访问(streaming data access)、大数据集支持(large data sets)、简单的一致性模型(simple coherency model)、移动计算比移动数据更廉价 (moving computation is cheaper than moving data)、跨异构软硬件平台的移植性(portability across heterogeneous hardware and software platforms)等目标和假设[8],特色也是非常明显的。HDFS虽然运行在廉价的硬件设施(commodity hardware),但能够满足高可靠性、大吞吐量、大数据集的数据访问需求。微软也在宣布了Windows Azure云计算操作系统计划之后,立即着手从Live Service打开市场。vMware的首个云计算操作系统vSphere 4直指到企业数据中心的前沿,它利用虚拟化将企业数据中心整合为云架构,从而帮忙企业的数据中心达到节能30%~50%的效用。作为云计算服务的4类形式之一,SaaS的成功案例包括Salesforce的客户关系管理(customer relationship management,CRM)平台,国内阿里软件 (Alisoft)中小企业管理软件平台也产生了很大的影响。此外,还包括EMC推出的云存储架构,苹果(Apple)推出的基于移动信息服务的“Mobile Me”云服务。
国内外学术界也纷纷就云计算进行深层次的研究。例如Google启动了云计算学术合作计划 (academic cloud computing initiative),并先后与麻省理工学院(Massachusetts Institute of Technology)、华盛顿大学 (University of Washington)、斯坦福大学(Stanford University)、卡耐基梅隆大学 (Carnegie Mellon University)、加利福尼亚大学伯克利分校 (University of California,Berkeley)、马里兰大学(University of Maryland)、清华大学等高校建立合作关系,推动云计算的普及,加紧对云计算的研究。卡耐基梅隆大学开展的有关 “数据密集型超级计算”DISC(data-intensive supercComputing)[10]研究,国内华东师范大学周傲英教授的研究团队在“数据密集型计算”领域的研究,本质上也是对云计算技术的研究。清华大学的张尧学[11,12]院士的研究团队于1998年提出的“透明计算”,体现了云计算资源池动态构建、虚拟化、用户透明等特征[13]。华中科技大学金海教授[6,14]的研究团队,复旦大学臧斌宇教授[15,16]的研究团队则在云计算的关键技术──虚拟化技术研究领域进行了大量高价值研究。浙江大学也在2008年启动了“云计算”研究项目,建立了云计算中心和平台环境。
当前,Web数据管理正逐步向云数据管理阶段发展,一个新的云数据管理研究领域正逐渐形成。本文在简单介绍了云计算技术的基础上,提出了云数据管理系统(cloud data management system,CDMS)的概念,剖析了 BigTable、Hbase、Sector/Sphere等当前互联网主流CDMS的基本原理,最后指出了云数据管理领域的主要研究方向。
2 云计算技术
云计算是以虚拟化技术为基础,以互联网为载体提供基础架构、平台、软件等服务为形式,整合大规模可扩展的计算、存储、数据、应用等分布式计算资源进行协同工作的超级计算模式[17]。在云计算模式下,用户不再需要购买复杂的硬件和软件,而只需要支付相应的费用给“云计算”服务提供商,通过网络就可以方便地获取所需要的计算、存储等资源。对于该定义需要特别说明的是,云计算的一个重要价值是软硬件需求的按需扩展能力[18],完全脱离“本地”计算、数据资源的云计算只是一种比较理想的状态,考虑到私有云、遗留系统、可靠性、安全性等因素,云计算具有整合资源按需扩展方面的特殊意义。
虽然对云进行定义、分类是很有意义的事情,但理解云计算的价值则显得更为重要。云计算最关键的特点是计算资源能够被动态地有效分配,消费者(最终用户、组织或者IT部门)能够最大限度地使用计算资源但又无需管理底层复杂的技术。云架构本身包括私有云和公有云,提供了按需扩展 (scalability on demand)、精简数据中心(streamlining the data center)、改善业务流程 (improving business processes),降低启动成本(minimizing startup costs)等一系列核心价值[18]。
云计算是虚拟化 (virtualization)、效用计算(utility computing)、IaaS(基础设施即服务)、PaaS(平台即服务)、SaaS(软件即服务)等概念混合演进并跃升的结果,也是分布式计算、网格计算和并行计算的最新发展,或者说是这些计算机科学概念的商业实现。区分相关计算形式间的差异性,将有助于我们对云计算本质的理解和把握。
云计算属于分布式计算的范畴,是以提供对外服务为导向的分布式计算形式[19]。云计算把应用和系统建立在大规模的廉价服务器集群上,通过基础设施与上层应用程序的协同构建以达到最大效率利用硬件资源的目的,以及通过软件的方法容忍多个节点的错误,达到了分布式计算系统可扩展性和可靠性两个方面的目标[13]。网格计算强调的是一个由多机构组成的虚拟组织,多个机构的不同服务器构成一个虚拟组织为用户提供一个强大的计算资源,而云计算主要运用虚拟机(虚拟服务器)进行聚合而形成的同质服务,更强调在某个机构内部的分布式计算资源的共享,在商业模式[19]、作业调度、资源分配方式、是否提供服务及其形式等方面,两者差异还是比较明显的。
云计算是并行计算的一种形式,也属于高性能计算、超级计算的形式之一,是并行计算的最新发展计算模式[20]。云计算与效用计算的区别不在于这些思想背后的目标,而在于组合到一起、使这些思想成为现实的现有技术[21]。效用计算通常需要类似云计算基础设施的支持,但并不是一定需要。同样,在云计算之上可以提供效用计算,也可以不采用效用计算。基于以上理解,参考文献[22]把效用计算作为云计算的7种服务形式之一。
关于云计算的具体系统和应用实例,云体系结构部分和参考文献[10,13,22,23,25~28]已有比较多的介绍,本文不再重复列举。总体来讲,云计算领域的研究还处于起步阶段,尚缺乏统一明确的研究框架体系,还存在大量未明晰和有待解决的问题,研究机会、意义和价值非常明显。现有的研究大多集中于云体系结构[27,29~31]、云存储[1,8,9,32]、云安全[18,33~37]、虚拟化[6,14,15,26,38,39]、编程模型[2,3,40,41]等技术,但云数据管理领域尚存在大量的开放性问题有待进一步研究和探索。
3 云数据管理系统(CDMS)基本原理
虽然GFS、HDFS、S3等分布式文件系统较好地解决了云计算中海量数据的组织问题,能够高效读写“云端”海量数据,但对于结构化数据的管理仍需要借助专门的数据管理系统。两者之间的关系或分工,类似于操作系统中负责文件组织的文件系统和负责结构化数据管理的数据库管理系统(DBMS)。云数据管理[42]必须有效地解决云计算中大数据集的高效管理、海量数据中特定数据的快速定位等问题。Google 的 BigTable[4]、Hadoop 的 HBase[9]、Sector/Sphere[43,44都是目前相对比较成熟的云数据管理系统。
BigTable是Google为有效管理大规模结构化数据而设计的分布式存储系统[4],例如数千台服务器的上PB(petabytes)级规模的数据。参考文献[13]把BigTable界定为弱一致性的大规模数据库系统,也有学者认为BigTable是由稀疏多维表组成的面向列存储的数据管理系统。本文则从云计算中数据管理“大规模”、“结构化”、“分布式”等特点出发,把BigTable[4]、HBase[8]等一类海量结构化(半结构化)分布式数据管理系统或其演化系统界定为云数据管理系统。云数据管理系统将成为文件与数据管理领域继文件系统(file system)、数据库管理系统 (DBMS)、Web数据管理系统(WDMS)后的下一个重要发展阶段。]
3.1 BigTable原理
BigTable在很多地方与数据库很类似,使用了很多数据库的实现策略。但不支持完全的关系数据模型,而是为客户提供了简单的数据模型。BigTable对数据读操作进行优化,采用列存储的方式,提高数据读取效率。BigTable的基本元素包括行 (row)、列族 (column families)和时间戳(Timestamps)[4]等。其中,行关键字可以是任意字符串(目前支持最多64 KB,多数情况下10~100字节足够),在一个行关键字下的每一个读写操作都是原子操作(不管读写这一行里有多少个不同列),这样在对同一行进行并发操作时,用户对于系统行为更容易理解和掌控。列族由一组同一类型的列关键字组成,是访问控制的基本单位。列族必须先创建,然后能在其中的列关键字下存放数据;列族创建后,族中任何一个列关键字均可使用。一张表中的不同列族不能太多(最多几百个),并且在运作中绝少改变。表中每一个表项都可以包含同一数据的多个版本,由64位整型的时间戳来标识。时间戳可以由BigTable来赋值,表示准确到毫秒的“实时”或者由用户应用程序来赋值。不同版本的表项内容按时间戳倒序排列,即最新的排在前面。为了简化对于不同数据版本的数据的管理,对每一个列族支持两个设定,以便于BigTable对表项的版本自动进行垃圾清除。用户可以指明只保留表项的最后n个版本,或者只保留足够新的版本(比如只保留最近7天的内容)。
在图1所示的Web网页存储范例[4]中,行名是一个反向 URL(即 com.cnn.www),列族“contents”用于存放网页内容,列族“anchor”则用于存放引用该网页的锚链接文本。这里 CNN的主页被 “Sports Illustrater”(CNN的体育节目)和“MY-look”的主页引用,因此该行包含了名为“anchor:cnnsi.com”和“anchhor:my.look.ca”的列。每个锚链接只有一个版本,分别由时间戳t9和t8标识,而contents列则包括分别由时间戳t3、t5和t6标识的3个版本。
大表(BigTable)的内容按照行来划分,由多个行组成一个小表(Tablet),保存到某个小表服务器(Tablet server)节点中。在物理层,数据存储的格式为SSTable,每个SSTable包含一系列大小为64 KB(可以配置)的数据块(block)。图2所示为BigTable的体系结构。

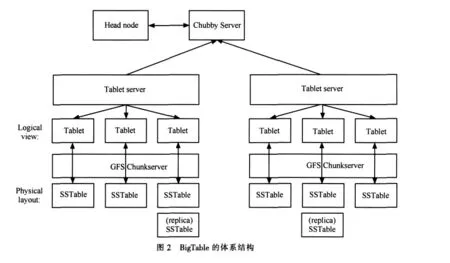
如果说BigTable是一块布,Tablets就好像是从这块布上扯下的布条。每个Tablet所需要的存储空间为100~200 MB,而每台服务器(廉价PC)大约存储100个左右的Tablets,同一台机器上的所有Tablets共享一个日志。SSTable提供一个从关键字到值持续有序的映射,关键字和值都可以是任意字符串。块索引(block index)存储在SSTable的最后,用来定位数据块。Chubby[45]是BigTable采用的一个高度可用的持续分布式数据锁服务。每个Chubby服务由5个活的备份构成,其中一个为主备份并响应服务请求。只有当大多数备份都保持运行并保持互相通信时,相应的服务才是活动的。当有备份失效时,Chubby使用Paxos[46]算法来保证备份的一致性。Chubby提供了一个由目录和小文件组成的名字空间 (namespace),每个目录或者文件可以当成一个锁来用,读写文件操作都是原子化的。
BigTable于2004年开始研发并投入应用,至今已运行了5年,基本上能够满足Google数据管理的需求,处理海量数据,实现高速存储与查找。目前,基于BigTable的应用包括Google Analytics、Google Finance、Orkut、Personalized Search、Writely、Google Earth等60多个项目。
3.2 HBase原理
HBase[9]是Hadoop[8]的子项目,是目前比较成熟的云数据管理开源解决方案之一。HBase采用与Bigtable非常相似的数据模型。用户存储数据行(data row)在一个标识表(labelled table)中,一个数据行有一个可排序的主键或分类键 (sortable key)和任意数量的列 (column)。表是疏松(sparsely)存储的,因此用户可以根据需要给同一表中的不同行定义各种不同的列。每张HBase表的索引是行关键字(row key)、列关键字(column key)和时间戳(timestamp)。如图 3所示,每个值是一个很难解释的字符数组,数据都是字符串,不区分类型。

列名字的格式是“
Hbase遵从如图4所示的简单主从服务器架构,每个Hbase集群通常由单个主服务器(master server)、数百个或更多区域服务器(region server)构成。每个Region由某个表的连续数据行组成,从开始主键到结束主键,而某张表的所有行保存在一组Region中。通过用表名和开始/结束主键,来区分不同的Region。区域服务器主要通过3种方式保存数据:Hmemcache高速缓存,保留的是最新写入的数据;Hlog记录文件,保留的是提交成功了,但未被写入文件的数据;Hstores文件,数据的物理存放形式。
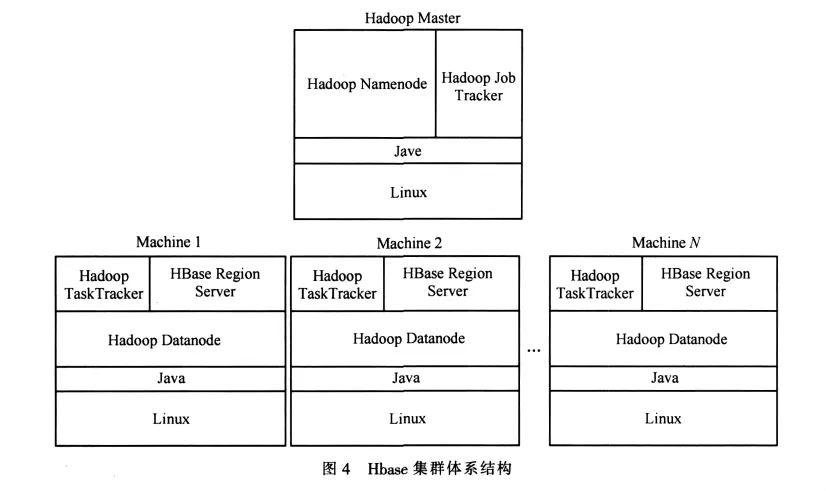
主服务器的主要任务是分配每个区域服务器需要维护的Region,因此每个区域服务器都需要与主服务器通信。主服务器会和每个区域服务器保持一个长连接,如果该连接超时或者断开,会导致区域服务器自动重启,同时主服务器认为该区域服务器已死机而把其负责的Region分配给其他区域服务器。
[47]以 PostgreSQL[48]和Hbase为代表从软件架构、硬件、OS、数据结构、数据处理、扩展性等方面对某电信行业信息系统从传统关系数据库管理系统 (RDBMS)到云数据管理系统(CDMS)的移植过程进行了比较分析,具体差异见表1。
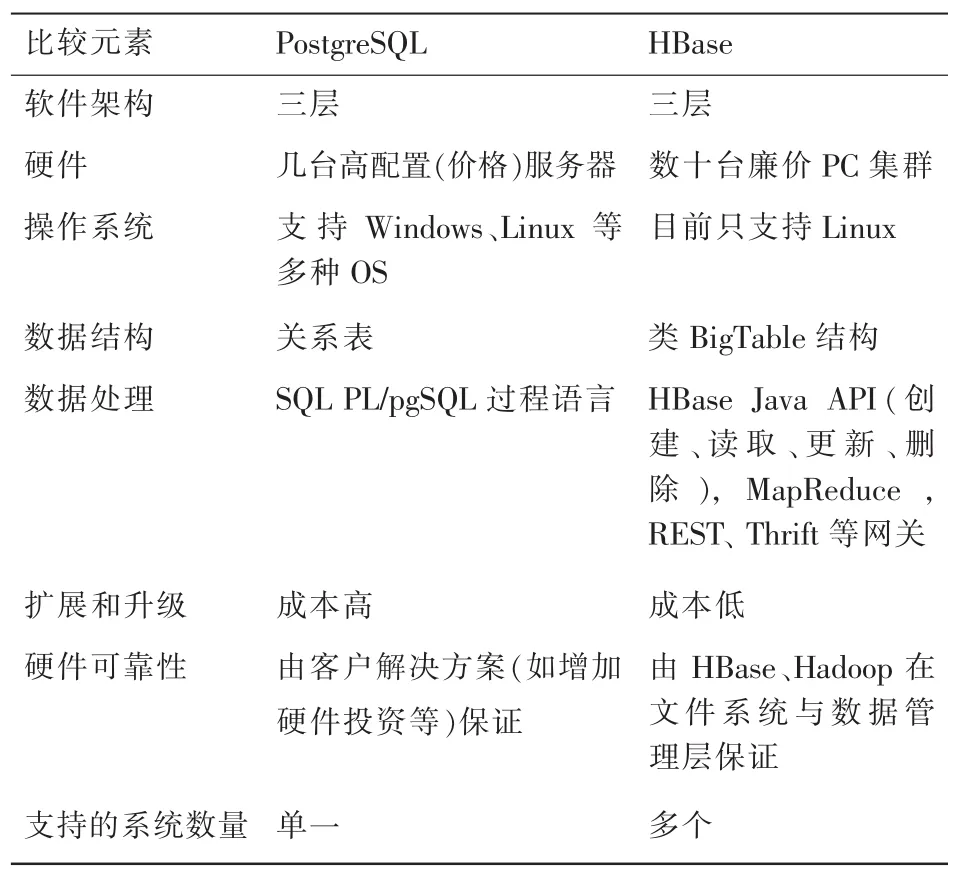
表1 比较分析要素
3.3 Sector/Sphere原理
参考文献[43]还从通信协议、数据传输协议、程序设计模式、安全模型等方面对 GFS/BigTable、HDFS/Hbase、Sector/Sphere进行了比较。Robert L Grossman等在设计并实现Sector/Sphere[43,44]的基础上,利用数据发掘应用进行了性能方面的实验[49]。
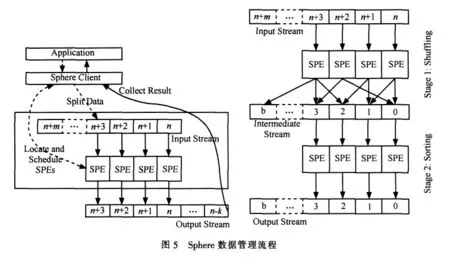
如图5所示,服务器 (sphere server)响应用户(sphere client)的请求而启动 SPE(sphere processing elements)服务。其中,SPE是基于用户定义函数的运算器(operator),能根据输入的Sphere流(stream)产生相应的输出流。Sphere运算器是一个动态的库,存储在服务器的本地磁盘上,由Sector服务器(sector server)负责管理。具体SPE的处理过程可以参考文献[49]。Sphere中的数据段(data segment)可以是一个或一组数据记录,也可以是一个文件。
3.4 其他CDMS相关研究
与 Oracle、DB2、SQL Serverand Sybase[50]等传统的关系型数据库相比,Bigtable、Hbase、Sector/Sphere等基于列模式的分布式数据库,灵活的分布式架构可以基于廉价的硬件设备组建动态扩展的高性能数据仓库,从而更能适应海量存储和互联网应用的实际需求。
此外,Hypertable[51]也是基于C++实现的类Bigtable开源系统。其他与云数据管理相关的研究工作主要集中于“数据密集型计算(data intensive computing)”,“数据密集型超级计算(data-intensive superComputing)[10]”方面的研究。Brandon Rich等[52]提出了一种用于支持动态存储云(active storage cloud)中的事务数据平行计算原型系统架构DataLab。参考文献[53]提出了抽象数据密集型云计算问题的实例All-Pairs。Huan Liu等[54]则提出了一种大规模数据密集型应用系统GridBatch,并在Amazon的EC2平台验证了系统的高性能。GrayWulf[55]也是作为一种可扩展的数据密集型计算集群体系结构而提出。加州大学的Dionysios Logothetis[56]等还开展了云自组数据(Ad-hoc data)处理方面的研究。
4 结束语
云计算通过对大规模可扩展的计算、存储、数据、应用等分布式计算资源进行整合,通过互联网技术以按需使用的方式为用户提供计算、存储和数据服务。云计算的出现并快速发展,一方面是虚拟化技术、数据密集型计算等技术发展的结果,另一方面也是互联网发展需要不断丰富其应用必然趋势的体现。目前,云计算还没有一个统一的标准,虽然 Amazon、Google、IBM、Microsoft等云计算平台已经为很多用户所使用,但是云计算在行业标准、数据安全、服务质量、应用软件等方面也面临着各种问题,这些问题的解决需要技术的进一步发展。
云数据管理领域迫待解决的问题包括:云数据管理或云数据管理系统(CDMS)基础理论的建立与完善;云计算平台共享存储空间中用户间数据的隔离问题[22];当用户数据发生意外丢失时,高效数据恢复技术与机制的研究;云数据的安全性、一致性如何支持外部审计和安全认证;传统数据库管理系统(DBMS),Web数据管理系统(WDMS)对云计算的支持,向云数据管理方式的改造与迁移研究;能否在云数据管理系统中,实现原有数据库系统中丰富的查询功能、高效复杂的索引以及强大的事务处理功能;云数据挖掘[20]与服务智能等,都是非常具有挑战性的课题。
我们相信,随着工业界、学术界越来越多的关注、参与和支持,云数据管理领域将出现一些新的结构模式、管理平台和应用实例,并推动云数据管理及其应用日益走向成熟。希望本文能对有兴趣于云计算特别是云数据管理领域研究的学者、工程师研究工作起到推动和促进作用。
参考文献
1 Sanjay Ghemawat,Howard Gobioff,Shun-Tak Leung.The Google file system.In:Proc of the 19th ACM SOSP,New York,2003
2 Dean J,Ghemawat S.MapReduce:simplified data processing on large clusters.In:Proc of the 6th SOSDI,Berkeley Calif,2004
3 Ralf Lammel.Google’s MapReduce programming model Revisited.http://www.cs.vu.nl/~ralf/MapReduce/paper.pdf,2007
4 Fay Chang,Jeffrey Dean,Sanjay Ghemawat,et al.Bigtable:a distributed storage system for structured data.In:Proc of the 7th USENIX Symp on OSDI,Berkeley,2006
5 Kelly Sims.IBM introduces ready-to-use cloud computing collaboration services get clients started with cloud computing.http://www-03.ibm.com/press/us/en/pressrelease/22613.wss,2009
6 石磊,邹德清,金海.Xen虚拟化技术.北京:华中科技大学出版社,2009
7 IBM.IBM virtualization.http://www-03.ibm.com/systems/virtualization/,2009
8 Dhruba Borthaku.The hadoop distributed file system:architecture and design.http://hadoop.apache.org/common/docs/r0.16.0/hdfs_design.pdf,2009
9 Hbase DevelopmentTeam.Hbase:bigtable-like structured storage for hadoop hdfs.http://wiki.apache.org/hadoop/Hbase,2009
10 Randal E B.Data-intensive supercomputing:the case for DISC.http://www.cs.cmu.edu/~bryant/pubdir/cmu-cs-07-128.pdf,2009
11 Zhang Y X,Zhou Y Z.4VP+:a novel meta OS approach for streaming programs in ubiquitous computing.In:Proc of IEEE the 21st Int’l Conf on Advanced Information Networking and Applications(AINA 2007),Los Alamitos,2007
12 Zhang Y X,Zhou Y Z.Transparent computing:a new paradigm for pervasive computing.In:Proc of the 3rd Int’l Conf on Ubiquitous Intelligence and Computing (UIC 2006),Berlin,2006
13 陈康,郑纬民.云计算:系统实例与研究现状.软件学报,2009,20(5):1337~1348
14 金海.计算系统虚拟化:原理与应用.北京:清华大学出版社,2008
15 英特尔开源软件技术中心,复旦大学并行处理研究所.系统虚拟化:原理与实现.北京:清华大学出版社,2009
16 陈海波.云计算平台可信性增强技术的研究.复旦大学博士学位论文,2009
17 吴吉义,平玲娣,潘雪增等.云计算:从概念到平台.电信科学,2009(12)
18 Open cloud manifesto.http://www.opencloudmanifesto.org,2009
19 Ian Foster,Zhao Yong,Ioan Raicu,et al.Cloud computing and grid computing 360-degree compared.In:Grid Computing Environments Workshop,GCE 2008
20 陈国良,孙广中,徐云等.并行计算的一体化研究现状与发展趋势.科学通报,2009,54(8):1043~1049
21 Tim Jones M.Cloud computing with Linux.http://download.boulder.ibm.com/ibmdl/pub/software/dw/linux/l -cloud -computing/l-cloud-computing-pdf.pdf,2009
22 范昊,余婷.一种新型的网络分布式计算──云计算.2008年全国高性能计算学术年会论文集,2008
23 Buyya Rajkumar,Chee Shin Yeo,Srikumar Venugopal.Marketoriented cloud computing:vision,hype,and reality for delivering IT services as computing utilities.In:Proc of the 10th IEEE International Conference on High Performance Computing and Communications,2008
24 司品超,董超群,吴利等.云计算:概念,现状及关键技术.2008年全国高性能计算学术年会论文集,2008
25 IBM. “蓝云”解决方案.http://www-900.ibm.com/ibm/ideasfromibm/cn/cloud/solutions/index.shtml,2009
26 IBM.“智慧的地球”─IBM动态架构之系统虚拟化.http://www.ibm.com/cn/express/migratetoibm/dynamicinfrastructure/download/dynamicinfrastructure_whitepaper_0903.pdf,2009
27 SUN.云计算架构介绍白皮书 (第1版).http://developers.sun.com.cn/blog/functionalca/resource/sun_353cloudcomputing_chinese.pdf,2009
28 潘春燕.云计算实战把数据中心迁移到云环境.信息系统工程,2009(2):30~31
29 Luis M V,Luis Rodero-Merino,Juan Caceres,Maik Lindner.A break in the clouds:toward a cloud definition.ACM SIGCOMM Computer Communication Review,2009,39(1):50~55
30 Buyya Rajkumar,Chee Shin Yeo,Srikumar Venugopal.Marketoriented cloud computing:vision,hype,and reality for delivering IT services as computing utilities.In:Proc of the 10th IEEE International Conference on High Performance Computing and Communications,2008
31 Luiz Andre Barroso,Jeffrey Dean,Urs Holzle.Web search for a planet:the google cluster architecture.IEEE Micro,2003,23(2):22~28
32 Amazon.Amazon simplestorageservice (S3).http://www.amazon.com/s3,2009
33 Above the clouds:a berkeley view of cloud computing.http://www.eecs.berkeley.edu/Pubs/TechRpts/2009/EECS-2009-28.html
34 2009中国云计算发展状况白皮书.http://www.tsinghuausa.org/W0509web/id0509/yun.pdf,2009
35 Patrick Goldsack等.Cells-as-a-Service──一项云计算基础设施服务.中国计算机学会通讯(CCFC),2009,5(6):26~31
36 Gartner.Teleworking in the cloud:security risks and remedies.http://www.gartner.com/resources/167600/167661/teleworking_in_the_cloud_sec_167661.pdf,2009
37 Cloud security alliance.http://www.cloudsecurityalliance.org/guidance/csaguide.pdf,2009
38 VMware.虚拟化技术作为云计算的平台.http://www.yocsef.org.cn/mcti/image/200903301516261.pdf,2009
39 Center for Internet Security.Virtual machine security guidelines.http://www.cisecurity.org/tools2/vm/CIS_VM_Benchmark_v1.0.pdf,2009
40 Yang HC,Dasdan A,Hsiao RL,Parker DS.Map-reduce-merge:simplified relational data processing on large clusters.In:Proc of the 2007 ACM SIGMOD Int’l Conf on Management of Data,New York,2007
41 Ranger C,Raghuraman R,Penmetsa A,et al.Evaluating mapReduce for multi-core and multiprocessor systems.In:Proc of the 13th Int’l Symp on High-performance Computer Architecture,Los Alamitos,2007
42 Daniel J A.Data management in the cloud:limitations and opportunities.Bulletin of the IEEE Computer Society Technical Committee on Data Engineering,2009,32(1):3~12
43 Gu Yunhong,Robert L G.Sector and sphere:the design and implementation of a high-performance data cloud.Philosophical Transactions of the Royal Society,2009(367):2429~2445
44 Robert L G,Gu Yunhong,Michael S,et al.Compute and storage clouds using wide area high performance networks.Future Generation Computer Systems,2009,25(2):179~183
45 Mike Burrows.The chubby lock service forlooselycoupled distributed systems.In:Proc of the 7th Symposium on Operating Systems Design and Implementation(OSDI),2006
46 Tushar Chandra,Robert Griesemer,Joshua Redstone.Paxos made live-an engineering perspective.In:Proc of the 26th annual ACM symposium on Principles of Distributed Computing,2007
47 Jean D C,Alain April,Alain Abran.Criteria to compare cloud computing with current database technology.LNCS 5338,2008,114~126
48 The postgreSQL global development group.Retrieved from http://docs.postgresql.fr/8.4/,2009
49 Robert L G,Gu Yunhong.Data mining using high performance data clouds:experimental studies using sector and sphere.In:Proc of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,2008
50 Olofson C.Worldwide RDBMS 2005 vendor shares.Technical Report 201692,IDC,May 2006
51 Overview of hypertable architecture.http://code.google.com/p/hypertable/wiki/ArchitecturalOverview,2009
52 Brandon Rich,Douglas Thain.DataLab:transactional dataparallel computing on an active storage cloud.In:Proc of the 17th International Symposium on High Performance Distributed Computing,2008
53 ChristopherMoretti,Jared Bulosan,DouglasThain,etal.All-pairs:an abstraction for data-intensive cloud computing.In:Proc of the 22nd IEEE International Parallel and Distributed Processing Symposium,Program and CD-ROM,2008
54 Huan Liu,Dan Orban.GridBatch:cloud computing for large-scale data-intensive batch applications.In:Proc of the 8th IEEE International Symposium on Cluster Computing and the Grid,2008
55 Alexander S S,Gordon Bell,Jan Vandenberg,et al.GrayWulf:scalable clustered architecture for data intensive computing.In:Proc of the 42st Hawaii International Conference on Systems Science,2009
56 Dionysios Logothetis,Kenneth Yocum.Ad-hoc data processing in the cloud.In:Proc of the VLDB'08,2008
猜你喜欢
汽车实用技术(2022年10期)2022-06-09
承德医学院学报(2022年2期)2022-05-23
汽车实用技术(2022年5期)2022-04-02
海洋信息技术与应用(2021年2期)2021-11-02
铁道通信信号(2020年4期)2020-09-21
电子制作(2019年10期)2019-06-17
中国交通信息化(2018年8期)2018-11-09
电子制作(2018年14期)2018-08-21
中国船检(2017年3期)2017-05-18
电子制作(2017年24期)2017-02-02
