
多点地质统计学随机建模方法及应用实例分析
2010-11-16 06:38刘颖金亚杰大庆油田勘探开发研究院
石油石化节能 2010年11期
刘颖 金亚杰 (大庆油田勘探开发研究院)
多点地质统计学随机建模方法及应用实例分析
刘颖 金亚杰 (大庆油田勘探开发研究院)
针对多点地质统计学的特点,从多点地质统计学随机建模方法入手,深入分析了多点地质统计学与传统两点地质统计学的区别、优势、方法论和建模流程等内容,并在理论分析基础上给出典型的应用实例。在北海Oseberg油田使用多点地质统计学,并综合其他数据建立河流相油藏模型最终提高了砂体的预测精度,设计了新井,有效提高油田剩余油采收率。认为多点地质统计学方法综合了基于象元的方法易忠实于条件数据和基于目标的方法易再现目标几何形态的优点,同时克服了传统的基于变差函数的两点地质统计学不能表达的复杂空间结构和再现目标几何形态的不足,具有明显的优越性,为大庆长垣“315”工程精细开发地震攻关技术提供了重要的参考和借鉴。
两点地质统计学 多点地质统计学 随机建模 概率摄动法 Oseberg油田 开采剩余油
1 前言
目前,在最大限度地挖潜老油气田和高效开发新区油气藏的过程中面临着一个重要的挑战,就是如何将地震数据有机地加入储层地质模型之中,充分利用地震资料与井资料分别在平面和纵向上具有高密度采样的特点,发挥地质统计学对多学科专业知识的综合能力,使得储层地质模型在地震资料的约束作用下,储层特性不仅在井周围纵向上具有高分辨率,保持测井和岩心测量的储层变化特征,同时又能反映出在地震数据中观测到的大尺度结构和储层连续性,在平面上也具有较高精度的展布,实现高精度储层地质建模。传统的两点地质统计学随机建模方法只能考虑空间两点之间的相关性,而多点地质统计学着重表达多点之间的相关性,克服了两点地质统计学的不足,是目前国际前沿研究方向。
2 多点地质统计学方法的优势[1-3]
2.1 两点地质统计学方法的不足
2.1.1 不能精确表征复杂的空间结构和再现复杂目标的几何形态
传统的两点地质统计学在储层建模中主要应用于两大方面:①应用各种克里金方法建立确定性的模型,这类方法主要有简单克里金、普通克里金、泛克里金、协同克里金、贝叶斯克里金、指示克里金等;②应用各种随机建模的方法建立可选的、等可能的地质模型,这类方法主要有高斯模拟、截断高斯模拟、指示模拟等。这些方法的共同特点是空间赋值单元为象元,故在储层建模领域将其归属为基于象元的方法。这些方法均以变差函数为工具,亦可将其归属为基于变差函数的方法。变差函数是传统地质统计学中研究地质变量空间相关性的重要工具。然而,变差函数只能把握空间上两点之间的相关性,难于精确表征复杂的空间结构和再现复杂目标的几何形态 (如弯曲河道)。
2.1.2 复杂几何形态的参数化和多井数据的条件化
现有储层随机建模的另一途径是基于目标的方法,以目标物体为基本模拟单元,进行离散物体的随机模拟 (HaldorsenandDamsleth,1990;Holden et al,1998),较好地再现目标体几何形态。但这种方法也有其不足:①每类具有不同几何形状的目标均需要有特定的一套参数 (如长度、宽度、厚度等),而对于复杂几何形态,参数化较为困难;②该方法属于迭代算法,当单一目标体内井数据较多时,井数据的条件化较为困难,而且需要大量机时。
2.2 多点地质统计学方法的优势
鉴于传统随机建模方法存在的不足,多点地质统计学方法的优势主要体现在以下两点:
(1)应用“训练图像”代替变差函数表达地质变量的空间结构性,克服传统地质统计学不能再现目标几何形态的不足,可以精确表征具有复杂空间结构和几何形态的地质体。训练图像是一种数字化的图像,能够表述实际储层结构、几何形态及其分布模式。
(2)以象元为模拟单元,采用序贯算法 (非迭代算法),快速而易忠实硬数据,可以克服基于目标的随机模拟算法的不足。
3 多点地质统计学随机建模方法
3.1 多点地质统计学随机建模基本步骤
多点地质统计学应用于随机建模始于1992年。经过Journel(2001)和Strebelle(2002)等人的不断研究,提出了多点统计随机模拟的Snesim算法。建模基本步骤如下:
◇建立训练图像。
◇准备建模数据,将实测的井数据标注在最近的网格节点上。
◇应用自定义的与数据搜索邻域相联系的数据样板τn扫描训练图像,以构建搜索树。
◇确定一个访问未取样节点的随机路径。在每一个未取样点u处,使得条件数据置于一个以 u为中心的数据样板bn中。令n′表示条件数据的个数,dn′为条件数据事件。从搜索树中检索 c(dn′)和ck(dn′)并求取 u处的条件概率分布函数。
◇从u处的条件概率分布中提取一个值作为u处的随机模拟值。该模拟值加入到原来的条件数据集中,作为后续模拟的条件数据。
◇沿随机路径访问下一个节点,并重复第三、第四步骤。如此循环下去,直到所有节点都被模拟到为止,从而产生一个随机模拟实现。
◇改变随机路径,产生另一随机模拟实现。
多点地质统计学随机模拟方法 (如Snesim算法)与传统的地质统计学随机模拟方法 (如序贯指示模拟SIS)的本质差别在于,未取样点处条件概率分布函数的求取方法不同。前者应用多点数据样板扫描训练图像以构建搜索树,并从搜索树中求取条件概率分布函数 (第一步和第三步),而后者通过变差函数分析并应用克里金方法求取条件概率分布函数。正是这一差别,使多点地质统计学克服了传统两点统计学难于表达复杂空间结构性和再现目标几何形态的不足。
3.2 多点地质统计学随机建模方法
3.2.1 利用3D/4D地震反演预测砂体概率分布(Andersen等人,2006)
第一步:3D地震数据分析。沿钻井井迹从地震数据中获得AI和Vp/Vs值,然后制成交会图并与井中岩相数据进行对比计算出砂体概率分布。仅用AI值计算,砂体预测的概率大约为65%,仅用Vp/Vs值,砂体预测的概率大约为60%,而 AI和Vp/Vs两者综合,预测的概率大约为70%[5]。
第二步:4D地震数据分析。4D弹性反演数据(1992,1999和2004)使用的是Vp/Vs比和 AI比(比值=监测值/基础值)的交会图。结合3D和4D数据最终获得砂体概率分布函数。可以看出,目前砂体预测的最大概率接近80%[5]。
第三步:得出河道砂体的概率分布。
3.2.2 概率摄动法 (Tureyen和Caers,2003)
为了简单起见,假设对一个用于描述事件出现概率的指示变量 I(u)(如砂体/非砂体)进行模拟(Tureyen和Caers,2003):

概率摄动方法的目标是,依靠模拟数据与油田动态数据之间的不匹配情况通过迭代生成条件概率

式中,rD是一个自由参数,选值范围是 [0,1];P(A)是事件A出现的总比率,与位置无关,因此是边缘分布。参数 rD决定了在把初始实现i(0)(u)变成等概率实现 i(1)(u)的过程中,对 i(0)(u)进行摄动的摄动量级。rD的每一个值完全决定每一个 u处的概率P(A|D4)。在使用snesim进行序贯模拟的过程中,把 P(A|D4)与 P(A|D1),P(A|D2)和 P(A|D3)合并,形成 P(A|D1,D2,D3,D4),从中提取出模拟值。以这种方式模拟得出的最终实现记为
3.2.3 数据概率综合法
为了综合利用不同来源的数据来模拟未知信息(岩相或岩石物理性质),把各类数据模拟成空间概率分布模型;用 Journel’stau模型 (Journel,2002)把这些单个的空间概率综合到一个简单的联合条件概率中,利用序贯模拟从联合的条件概率中提取油藏模型。
4 应用实例:Oseberg油田利用多点地质统计学模拟河道空间分布
北海奥塞贝格油田在上奈斯 (Upper Ness)组河流相油藏上,成功应用了一种综合3D/4D地震数据等多种不同来源数据进行建模的方法和流程。建模过程中使用多点地质统计学各种方法阐述各种数据之间可能存在的不一致性或重复现象,生成的油藏模型忠实于地质解释,并且与有效的生产数据相匹配;模拟出河道砂体的空间分布,认清了砂体分布垂向上的变化。
4.1 油田概况
奥塞贝格油田1988年投产,最初设计采收率为46%[4],在开发后期大规模应用水平井 (长度达到7 800 m以上)、智能井、3D与4D地震反演数据建模等措施大大提高了设计采收率,到2005年初采收率已提高到72%[5],远远超过设计采收率。该油田被誉为新技术应用的“实验室”,通过采用新技术,使可采储量由最初的 (1983—1992年)2×108t提高到目前的3.32×108t(2005年),增加了1.32×108t。其中,有0.57×108t是1998年产量下降以后使用先进的油藏建模、4D地震和智能完井等先进技术实现的。
4.2 研究区域面临的挑战
河流相的Ness组油藏于1993年投产,储量占原始地质储量的比例约为20%,参数见表1[5]。Ness组油藏的特点如下:

表1 Ness组油藏物性参数
◇砂岩、泥岩及煤岩交互层,砂体薄 (2~8 m),具有严重的复杂性和非均质性,某些井穿透70%河道砂体却一直低产。
◇2口水平井C-19和C-17D产量差异巨大,累计产油量分别为3 610.46 t和264.18 t,暴露出河道砂体内部的连通性问题。到2006年,该油藏采收率只有27%(其上部的 Tarbert层为58%,其下部的ORELN2层为67%)。
由于以上原因,Ness组油藏历来缺少值得信赖的模型。而大量的原油仍然留在地下尚未采出,因此把综合利用各种数据建立油藏模型为目标,利用多点地质统计学模拟河道的空间分布,以便优化新井设计,最大限度地提高采收率。
4.3 建模流程
所用数据有:15口井的测井数据、储层中相分布的训练图像、从3D和4D地震弹性数据反演结果中得出的岩相概率体、4D地震数据和生产数据。作业流程中主要模块如图1所示。
4.3.1 建立高精度3D地质单元模型
首先,利用多点“一元正态方程模拟”(Snesim)算法进行相模拟,模拟了两种相——河道相和泛滥平原相。得出的相实现遵循训练图像所描述的地质概念,受到沉积相硬数据、垂向上砂体比例[6]和河道相概率体[4]的约束。第二,在受孔隙度和渗透率这两种硬数据约束的每个沉积相中模拟孔隙度和渗透率。最后,得出训练图像 (图2)。

图1 油藏建模流程

图2 二元训练图像,灰色为河道砂沉积相,黑色为泥质的泛滥平原相
4.3.2 建立3D粗化模型
3D粗化模型是利用以单相流为基础的粗化程序对高分辨率3D地质单元模型进行粗化而获得的。高分辨率模型由96×128×70个网格块组成;每个网格块宽25 m(x和 y方向),厚约0.8 m(z方向)。生成粗化模型时选择的粗化比为2∶2∶5,粗化后的网格块减少到48×64×14。
4.3.3 建立流动模拟模型
流动模拟的时间是1992—2005年。有8口井处于生产状态:4口生产井 (2口直井和2口接近油水界面的Upper Ness组长水平井)和4口注入井。Ness组专用的2口水平生产井C-19和C-17D为历史拟合目标井,目标是拟合这两口井的累计产油量和产水量[6]。
4.3.4 建立历史拟合程序
通过Snesim算法对高分辨率相模型进行模拟,利用测井数据、3D/4D地震数据和地质概念 (训练图像)进行约束,从而得到高分辨率相模型的初始推测模型 (图3)。根据概率摄动方法 (Caers,2003),对在建立高分辨率相模型时使用的联合概率分布进行反复摄动,从而得到关于河道位置方面的变化。之后,进行持续摄动直到实现历史拟合时为止,这样得到的目标函数接近限定值。通过上述过程得出最终的高分辨率模型 (图4),该模型同时忠实于动态数据和静态数据[5]。2口井的历史拟合结果见图5和6。
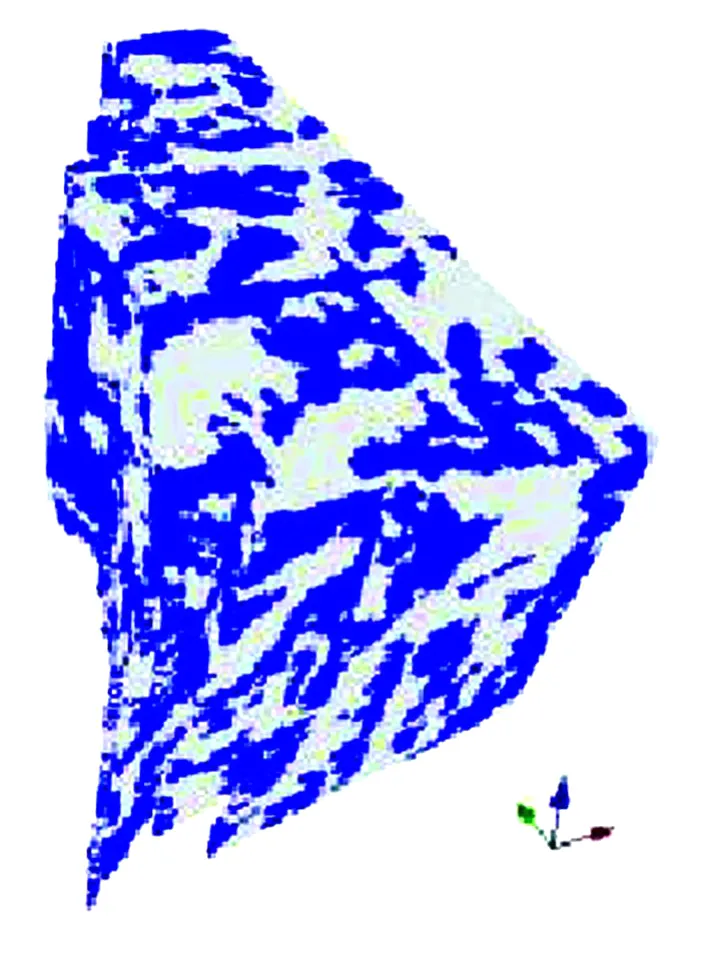
图3 最初推测的高分辨率相模型,作为概率摄动的起始点。蓝色为河道相,灰色为泛滥平原相
4.4 效果分析
(1)通过Ness油藏新的地质模型,找出了2口井产量出现巨大差异的原因。主要是以前对河道走向、连通性、N/G的认识存在偏差。地震数据和动态数据的重新评估结果显示,在Upper Ness组油藏最顶部的1/3,砂体非常分散 (图7)[7],基底砂体砂岩出现的频率较高,河道走向更趋近于东西走向 (原来认为是西北走向的)。原因可能是沉积方向发生了改变,主要是由沉积时期的断层活动引起的。
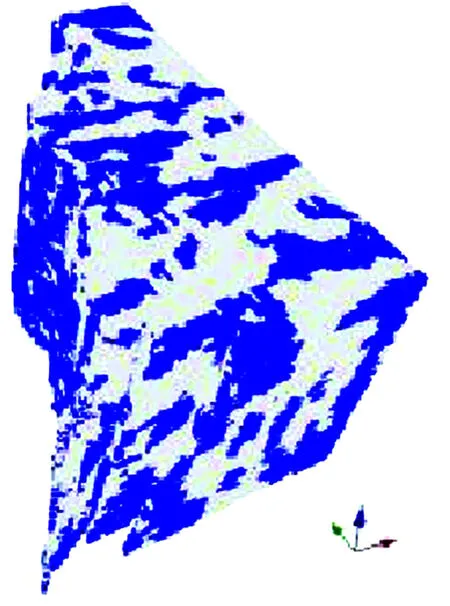
图4 用C-19和C-17D井的生产数据 (累积产油量和产水量)进行历史拟合后得到的高分辨率相模型。蓝色为河道相,灰色为泛滥平原相

图5 C-19井的产油量。黑色曲线为历史数据,粉色曲线是从初始的推测模型中得出的模拟的累积产油量,绿色曲线是经58次流动模拟后得出的最好的匹配曲线

图6 C-17D井产油量。黑色曲线为历史数据,粉色曲线是从初始的推测模型中得出的模拟的累积产油量,绿色曲线是经58次流动模拟后得出的最好的匹配曲线
(2)综合3D和4D弹性反演数据导出砂体概率分布函数,以空间概率体的形式把3D和4D地震数据综合到油藏建模中,提高了砂体预测的准确性。结果表明,利用 AI(概率接近 65%)和Vp/Vs(概率接近60%)的交会图预测的岩性比单独使用一种地震参数预测的效果可靠 (概率接近70%),把4D数据用于岩性分类的结果更可靠(概率接近80%)。
(3)设计了新的 IOR井目标和预测产油量。模拟模型表明Upper Ness油藏的历史拟合结果非常好。该方法用于设计Ness组油藏新井的目标,进一步提高采收率。此外,Upper Ness组的5个历史拟合储层模型还可用于预测未来 IOR井的产油量。
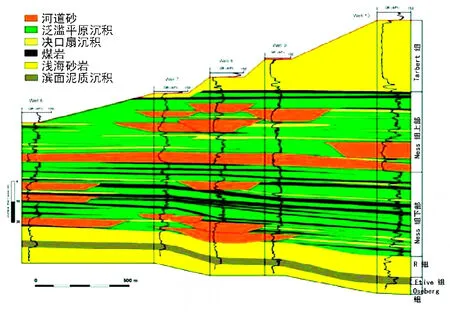
图7 阿尔法北部Ness组井的相关性。注意Upper Ness组底部砂岩的广泛延伸
5 未来研究方向
综合国际上多点地质统计学的研究现状及已有实例分析,多点地质统计学随机建模方法尚需在以下几方面进行深入研究:
◇训练图像平稳性
◇目标体连续性
◇综合地震信息
6 结论与建议
(1)多点地质统计学的发展迄今只有十多年的历史,相对于两点地质统计学而言,该方法具有明显的优势,能够综合传统随机建模方法的优点,描述复杂空间结构和再现目标几何形态,是储层随机建模方法的前沿研究方向。
(2)应用多点地质统计学,实现了不同来源的数据综合,得出的模型同时忠实静态数据 (测井、地质信息和3D地震)和动态数据 (4D地震数据和生产数据)。
(3)Oseberg油田使用多点地质统计学建立的高精度地质模型,调整了河道相的位置和连通性,也对其他数据进行了调整。历史拟合后的模型对某些参数,尤其是对河道走向和N/G趋势调整具有决定性意义。
(4)北海地区油田是开发地震技术相关技术成功应用的典范,在利用综合地震数据进行油藏建模,寻找剩余油方面取得了很好的效果,能够为大庆油田长垣“315”工程精细开发地震攻关项目组应用多点地质统计学方法建立老区高精度3D地质模型提供重要的参考和借鉴。
[1]吴胜和等.多点地质统计学——理论、应用与展望[J].古地理学报,2005(2).
[2]骆杨等.多点地质统计学在河流相储层建模中的应用[J].地质科技情报,2008(9).
[3]尹艳树等.储层随机建模研究进展[J].天然气地球科学,2006(4).
[4]Andersen T.Method for Conditioning the Reservoir Model on 3D and 4D Elastic Inversion Data Applied to a Fluvial Reservoir in the North Sea,SPE 100190,2006(6).
[5]Changhong Gao,Rajeswaran T.A Literature Review on Smart Well Technology,SPE 106011,2007.
[6]ScarletCastro.A Probabilistic Integration ofWell Log,Geological Information,3D/4D Seismic and Production Data:Application to the Oseberg Field,SPE 103152,2006(9).
[7]Liestol F M.Imrpoved Modelling and Recovery From FluvialReservoirs in theNorth Sea.IPTC 10378,2005.
10.3969/j.issn.1002-641X.2010.11.001
2010-04-15)
猜你喜欢
中学生数理化·中考版(2022年6期)2022-06-05
中学生数理化·中考版(2021年6期)2021-11-22
——北美又一种非常规储层类型
石油与天然气地质(2021年5期)2021-10-29
新世纪智能(数学备考)(2021年4期)2021-08-06
新世纪智能(数学备考)(2021年4期)2021-08-06
中国海上油气(2021年2期)2021-06-09
化工管理(2021年7期)2021-05-13
矿产勘查(2020年9期)2020-12-25
西南石油大学学报(自然科学版)(2018年5期)2018-11-06
新疆石油地质(2015年5期)2015-10-12
