
一种基于FoBa算法思想的支持向量机稀疏SMO算法研究*
2011-04-26 05:08梁万路
舰船电子工程 2011年1期
梁万路
(解放军炮兵学院5系43队 合肥 230031)
1 引言
支持向量机[1~2](SVM)是由Vapnik所领导的贝尔实验室在1963年提出的一种非常有潜力的分类技术,主要应用于模式识别[3]领域。近年来,已取得了巨大的发展,成为机器学习领域一个标准的学习算法。当前的研究主要集中在算法本身的改进、拓展和算法实现上。随着计算机技术的日益发展以及互联网的日益普及,大规模,海量数据的处理能力成为分类器算法得以实现的现实要求。
传统的实现方法由于算法复杂、存储要求大、收敛速度慢等弊端无法满足实际应用的要求。支持向量机优化问题具有对支持向量的分类等价于对整个样本集的分类,优化问题的解是样本点的线性组合等特点。基于这些特点人们提出了解析方法,主要包括分块算法、分解算法、SMO[5~6]算法,共同的思想是循环迭代:将原来较大的二次优化问题分解为若干规模较小的子二次优化问题,按照某种优化策略,通过反复优化子问题,最终使结果收敛到原问题的最优解。SMO算法是将分解算法的思想推向极致,每次迭代仅优化两个样本点的最小子集。但是这些方法对支持向量数目的约减并未过多关注,算法的稀疏性[9]有待进一步提高。
支持向量机的分类速度与支持向量的数目成正比。因此对支持向量数目进行约减可以提高算法的分类速度。本文将FoBa算法[10]对特征进行约减的思想引入SMO算法中,对训练产生的作用甚微的支持向量进行约减,提出了稀疏SMO算法,在海量数据的处理上取得了很好的效果。
2 支持向量机的稀疏SMO算法
2.1 求解支持向量机的SMO算法

目前求解SVM最常用的策略的是SMO[3~4]。SMO的主要思想可以分为两步:1)选择包含两个样本点的工作样本集;2)计算两点解析解。
工作样本集选则:当且仅当所有样本点对应的Lagrange乘子都符合KKT条件时,α才为最优解,所以SMO算法每次迭代挑选的两个样本点必须为破坏KKT条件最严重的。
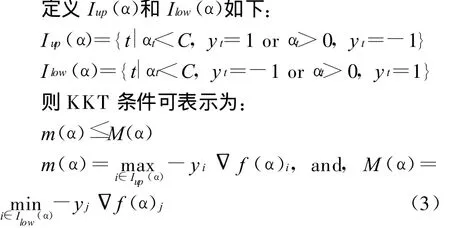
在破坏KKT条件的点对上优化问题能够降低目标函数值,且破坏程度越严重,目标函数值下降的就越快。在 Rong-En Fan et.al方法[7~8]中使用二阶梯度信息来求取最大化违法点对,要求求解包含两个样本点的子问题。


两点解析解:由于工作样本集中只含有两个样本点且符合线性约束,故利用等式约束可以将其中一个用另一个表示出来,所以迭代过程中每一步的子问题的最优解可以直接用解析的方法求出来。解析解如下:

2.2 自适应FoBa算法思想
国内知名学者 T.zhang在NIPS2008发表的文章[10]详细分析了前向贪婪算法和反向贪婪算法在特征选择方面的优劣,认为前向贪婪算法每次迭代都会增加一个使目标函数减小最快的特征向量,保证能够尽快迭代出全局最优值,主要缺陷在于不能自行纠正前期运算的错误,反向贪婪算法把所有特征向量作为模型开始运算,然后逐个删除符合条件的特征向量,当维数远大于样本个数时,计算代价非常高。在此基础上,T.zhang提出了一种新的自适应算法—FoBa算法。算法适当使用反向贪婪算法消除前向算法中所犯的错误,同时确保有用特征没有被删除。
2.3 稀疏SMO算法
通过对Foba算法的分析我们发现,FoBa算法在每次前向步骤中都是寻找一个使目标函数减少最快的特征并添加到特征集合中,这与SMO算法中寻找破坏KKT条件最严重的点对,即使目标函数值下降最快的点对并添加到支持向量集中相类似,它们的更新策略一致,只是目标函数不同,解决的问题不同而已。借鉴 T.zhang提出的FoBa算法思想我们提出稀疏SMO算法,对训练产生的作用甚微的支持向量进行约减,从而使算法具有更好的稀疏性,能够更加快捷的处理海量数据问题。与FoBa算法不同的是,这里的稀疏指的是支持向量的稀疏而不是特征的稀疏。下面给出稀疏SMO算法的流程:

算法流程显示只有当目标函数的增长量不再大于前向步骤中目标函数减小量的υ倍时,反向步骤才得以运行。这就意味着如果我们进行了l次前向运算,那么不管反向步骤运行了多少次,此时目标函数减少量至少为 lε/2,算法最多运行2f(0)/ε,从而说明了算法程序是高效运算。
3 实验结果及分析
实验计算机硬件环境为,CPU:英特尔(双核)2.83GHz,内存 4GB,WindowsXP操作系统。Benchmark数据库是国际上验证机器学习算法性能的标准数据样本集合,主要用于二分类、多分类、ONE-CLASS和聚类等算法的验证。本文选用Benchmark 数据库中的 Banana、heart、Breast-Cancer、Thyroid、Titanic、German 作为验证稀疏SMO算法求解二分类SVM的数据库。

表1 部分benchmark数据库实验结果
所有的核函数均取为RBF核函数。采用交叉验证策略最优化参数。每个实验交叉检验100次。所谓交叉检验就是将样本按比例分为训练样本和测试样本,每次按固定比例从整个样本集中抽取部分样本进行训练,剩余的用来测试,共进行n次,称为n次交叉检验,可以提高模型的鲁棒性。文献[11]中提出用核调用次数作为验证SVM算法性能的评价指标。由于支持向量方法测试时间仅与内积有关,故可用核运算代替内积运算,每进行一次核运算必进行一次内积运算,因此可用核调用次数作为SMO算法性能的评价指标,这一指标已被确认为核算法研究的指标性数据。Benchmark数据库上的实验表明稀疏SMO算法的训练错误率与SMO算法基本上差不多,测试错误率与SMO算法相比略有上升,而测试速度却有显著提高,因此我们有理由相信稀疏SK算法能够解决海量数据的SVM分类问题。
4 结语
实验表明对于二分类SVM 问题,稀疏SMO算法与SMO算法相比训练错误率不相上下,测试错误率下降很少,而训练时间却有明显的降低。所以Sparsity SMO算法可以约减作用不大的支持向量,提高算法的稀疏性,从而提高算法的预测速度,在解决海量数据问题时具有一定的竞争力。
[1]张学工.统计学习理论与支持向量机[J].自动化学报,2000
[2]Cortes C,Vapnik.V.Support vector networks.Machine Learning,1995,20:273~297
[3]边肇祺.张学工,等.模式识别[M].第二版.北京:清华大学出版社,2000
[4]Duda R O,Stork D G,ha rt P E.Pattern Classification(2nd)[M].New York.Wiley,2001
[5]Chih-Wei Hsu,Chih-Chung Chang,Chih-Jen Lin.A Pratical Guide to Support Vector Machines
[6]Chih-Chung Chang,Chih-Jen Lin.LIBSVM:a library for support vector machines,2001
[7]Pai-Hsuen chen,Rong-En Fan,Chih-Jen-Lin.A study on SMO-type decomposition method for support vector machines.Technical report,Department of Computer Science,National Taiwan University,2005
[8]Rong-En Fan,Pai-Hsuen chen,Chih-Jen-Lin.Working Set Selection Using Second Order Information for Training Support Vector Machines.Technical report,Department of Computer Science,National Taiwan U-niversity,2005
[9]Antoni B.Chan,Nuno Vasconcelos,Gert R.G.Lanckriet.Direct Convex Relaxations of Sparse SVM[C]//Proceedings of the 24 th International Conference on Machine Learning,Corvallis,OR,2007
[10]T.Zhong.Adaptive Forward-Backward Greedy Algorithm for Sparse Learning with Linear Models,NIPS,2008
[11]B.F.Mitchell,V.F.Dem'yanov,V.N.Malozemov.Finding the point of a polyhedron closet to the oringin.SIAM J.Contr,1974,12:19~26
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
新高考·高一数学(2022年3期)2022-04-28
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
当代陕西(2019年14期)2019-08-26
新课程·上旬(2019年1期)2019-03-18
教师·中(2017年3期)2017-04-20
中学数学杂志(初中版)(2016年5期)2016-11-01
试题与研究·教学论坛(2016年27期)2016-08-11
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
