
基于Lucene的中文分词器的设计与实现*
2011-07-25 00:34彭焕峰
网络安全与数据管理 2011年18期
彭焕峰
(南京工程学院 计算机工程学院,江苏 南京211167)
信息技术的发展,形成了海量的电子信息数据,人们对信息检索的要求越来越高,搜索引擎技术也得到了快速发展,并逐渐地被应用到越来越多的领域。由于搜索引擎技术涉及信息检索、人工智能、自然语言处理等多种学科,很多搜索算法都不公开[1]。Lucene是一个优秀的开源全文搜索引擎框架,通过Lucene可以方便地将全文搜索技术嵌入到各种应用当中,有针对性地实现强大的搜索功能,因此近年来Lucene的应用越来越广泛。
Lucene在对信息进行索引前,需要进行分词,西方语言使用空格和标点来分隔单词,而中文使用表意文字,不能通过空格和标点来进行分词。Lucene自带中文分 词 器 有 StandardAnalyzer、ChineseAnalyzer、CJKAnalyzer,这些分词器要么是单字切分,要么采用二分法切分,它们并不能有效地解决中文分词问题。本文设计并实现了基于全哈希整词二分算法的分词器,并集成到Lucene中,从而提高了Lucene处理中文信息的能力。
1 Lucene简介
Lucene是Apache软件基金会jakarta项目组的一个子项目,是一个优秀的开源全文搜索引擎工具包,并不是一个完整的全文检索应用。它提供了丰富的API函数,可以方便地创建索引,嵌入到各种应用中实现全文检索[2]。Lucene作为开源的全文搜索引擎,架构清晰,易于扩展,而且索引文件格式独立于应用平台,从而使索引文件能够跨平台共享,能够对任意可转换为文本格式的数据进行索引和搜索,例如网页、本地文件系统中的WORD文档、PDF文档等一切可以从中提取文本信息的文件[3]。
2 基于全Hash的整词二分分词器
目前中文分词算法大致可分为三大类:机械分词方法、基于理解分词方法和基于统计分词方法[4]。其中机械分词把待分解的汉字串与词典中的词条进行匹配来判断是否是一个词,是当前应用广泛的一种分词方法。在深入研究整词二分、TRIE索引树和逐字二分这三种传统的机械分词算法及其改进算法的基础上,本文设计并实现了基于全哈希的整词二分分词器。
2.1 词典设计
词典设计是机械分词的关键,词典结构应与分词算法相结合,这样设计的分词器分词效率才能得到最大限度的提高[5]。全哈希整词二分词典机制由首字哈希表、哈希节点、词哈希表和词碰撞表构成,如图1所示。
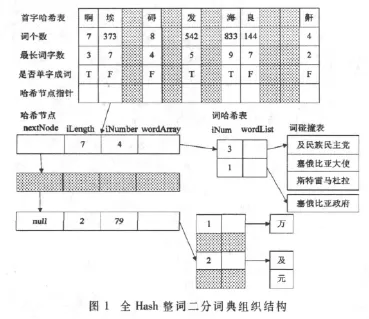
(1)首字哈希表
汉字在计算机中是以内码的形式存储。根据内码获取汉字对应的区位码,从而给定一个汉字,可以通过哈希函数直接得到其在首字哈希表中的位置[6]。用lowByte表示汉字内码的低字节,highByte表示汉字内码的高字节,则哈希函数设计如下:
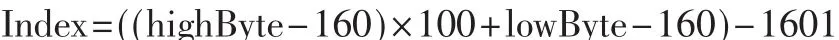
词个数:记录以该字为首字的词的个数。
最长词字数:记录以该字为首字的最长词所包含的字数。
是否单字成词:标识该字是否可以单独成词。
哈希节点指针:指向以该字为首字的第一个哈希节点。
(2)哈希节点
记录了词长(iLength)、相同词长的词的个数(iNumber)、词哈希表的地址(wordArray)以及下一个哈希节点的指针(nextNode)等信息。对相同首字的词条按包含的字数进行分组,再对除首字外的剩余字符串进行全词哈希,哈希节点按照词长倒序排列。
(3)词哈希表
记录了哈希值相同的词条的个数(iNum)、指向保存词条的动态数组(wordList),即词碰撞表。词哈希表的大小为词长相同的词的数量,哈希函数的选取不能太复杂,否则会增加分词时间,同时也要考虑哈希结果的均匀分布。
(4)词碰撞表
词碰撞表实际上是一个动态数组,对于词典中首字相同且词长相同的词条,如果哈希值相同,则以动态数组的形式保存,且只保存除首字之外的剩余字串。对于哈希值相同的词条,采用二分查找。
2.2 分词算法
该分词词典机制适用于正向最大匹配算法和逆向最大匹配算法,本文采用正向最大匹配算法为例使用该词典机制进行分词。
第一步:取待匹配字符串
假设String为待分词语句,如果String不包含任何字符(即长度为零),则表示语句分词完毕。从String=A1A2A3A4…An中读取第一个字A1,从首字哈希表中获取以该字为首字的最长词的字数m,如果String剩余待分词的字数不足m,则取Str为String的剩余待分词的字符串,否则取字符串Str=A1A2…Am为待匹配字符串。
第二步:判断Str的长度
(1)如果Str的长度为1,在首字哈希表中找到对应的位置,判断单独成词标志是否为F,如果是说明Str不是一个词;否则说明Str是一个词,分出该词。设置待切分语句String=A2A3A4…An后转第一步。
(2)如果Str的长度大于 1,转第三步。
第三步:对待匹配字符串分词
在A1对应的哈希节点链表中查找词长为字串Str长度的节点,有如下两种情况:
(1)如果没有找到,则 Str字串不是一个词,则去掉Str的最后面的一个字,转第二步。
(2)如果找到对应的哈希节点,则计算Str(除去首字,因为首字不保存)的哈希值,得到在词哈希表中的位置,有如下三种情况:
①若对应的碰撞数(iNum)等于 0,说明 Str不是一个词。
②若对应的碰撞数(iNum)等于1,则比较去掉首字的Str与词碰撞表中的词,如果相等,则Str成词,否则不成词。
③若对应的碰撞数(iNum)大于1,则在词碰撞表中进行二分查找,如果找到则成词,否则不成词。
上述三种情况若都不成词,则去掉Str的最后面的一个字,转第二步;若成词,则在 String中分出一个词 Str,将语句String设置为除去Str的剩余字串,转第一步。
2.3 实验结果及分析
可以很方便地将分词器集成到Lucene中,该分词器不妨命名为 MyAnalyzer。对 3个分词器ChineseAnalyzer、CJKAnalyzer、MyAnalyzer进行实验,采用复合索引结构,只对文档内容创建域,且只对文档内容进行索引但不存储,在分词时间、索引文件大小两方面做对比,分别对两个文档集进行实验,文档集1含有3个文件,共2.38 MB,文档集2含有126个文件,共164 MB。表 1为实验结果数据。

表1 不同分词器实验数据对比
通过实验数据可知,采用CJKAnalyzer二分法切分形成的索引文件要远大于采用ChineseAnalyzer单字切分所形成的索引文件,但两者在索引时间上相差并不大,由于索引文件中记录关键字及其词频和所在文档等信息,所以当测试文档集增大时,采用本文设计的MyAnalyzer分词器所产生的索引文件大小与采用ChineseAnalyzer所产生的索引文件相差逐步减少,但远小于采用CJKAnalyzer分词器产生的索引文件大小。最为关键的是,采用MyAnalyzer生成的索引能大大提高全文检索的查准率和查全率。
3 应用
Lucene具有方便使用、易于扩展等优点,越来越多的开发者将其嵌入到不同的应用中实现全文检索功能。各种应用有着不同的检索需求,本文通过扩展Lucene的中文分词器,使开发者可以针对系统的特点定制自己的分词词典,根据具体的需求进行分词,并创建索引,从而提高全文检索的效率。
[1]胡长春,刘功申.面向搜索引擎Lucene的中文分析器[J].计算机工程与应用,2009,45(12)157-159.
[2]索红光,孙鑫.基于Lucene的中文全文检索系统的研究与设计[J].计算机工程与设计,2008,29(19):5083-5085.
[3]吴青,夏红霞.基于Lucene全文检索引擎的应用与改进[J].武汉理工大学学报,2008,30(7):145-148.
[4]孙茂松,左正平,黄昌宁.汉语自动分词词典机制的实验研究[J].中文信息学报,1999,14(1):1-6.
[5]李庆虎,陈玉健,孙家广.一种中文分词词典新机制-双字哈希机制[J].中文信息学报,2002,17(4):13-18.
[6]张科.多次Hash快速分词算法[J].计算机工程与设计,2007,28(7):1716-1718.
猜你喜欢
电脑爱好者(2021年8期)2021-04-21
校园英语·月末(2021年13期)2021-03-15
电脑爱好者(2020年20期)2020-10-22
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
现代计算机(2016年27期)2016-10-29
工业设计(2016年8期)2016-04-16
电脑爱好者(2015年13期)2015-09-10
软件导刊(2015年6期)2015-06-24
数字技术与应用(2014年12期)2015-05-04
