
基于协同库存和模糊需求的离散选址模型研究
2011-10-18 10:32毕娅李文锋
统计与决策 2011年6期
毕娅,李文锋
(1.武汉理工大学物流工程学院,武汉430070;2.湖北经济学院信息管理学院,武汉430205)
基于协同库存和模糊需求的离散选址模型研究
毕娅1,2,李文锋1
(1.武汉理工大学物流工程学院,武汉430070;2.湖北经济学院信息管理学院,武汉430205)
供应链环境下配送中心的运作是竞争和协作并存的。在满足供应链整体利益的前提下,各配送中心仍然追求个体利益的最大化。因而我们引入协同库存机制来解决这个问题。我们构建了供应链总成本最低和配送中心覆盖率最大的多目标的离散随机选址模型。模型中需求点对配送中心贡献的效益和需求点的需求量是两个重要的参数,对于前者我们采用网络层次法求解,而后者我们采用模糊三角函数来模拟,使其更贴近于现实情况。该模型考虑了随需求量产生非线性变化的配送中心的固定投资以及在配送中心和需求点之间产生的运输费用和仓储费用,对传统的最大覆盖模型进行了优化,提出了覆盖率的概念。
协同库存;覆盖半径可变的最大覆盖模型;模糊三角函数;网络层次法;遗传算法
0 引言
供应链是一个集成的管理理念和思想。我们研究的配送中心是在供应链中起到承上启下的一个重要节点。配送中心选址的决策不仅直接关系到日后配送中心自身的运营成本和服务水平,而且关系到整个社会物流系统的合理化。最早的国外选址研究可以追溯到18世纪Pierre de Fermat提出的基本的欧式空间中位问题。现在已有的选址问题多是研究解决顾客量产生于网络结点的服务设施的选址问题,这些问题可以分为P-中心问题,P-中位问题和覆盖问题。P-中心问题考虑如何在网络中选择P个点,使得需求点离配送中心的最远距离最小。Hakimi首先提出网络P-中心模型[1];Drezner和Wesolowsky随后提出了Drezner-Wesolowsky法解决多设施的P-中心问题[2];然后,Kariv和Hakimi证明了P-中心问题为NP-hard问题[3]。P-中位问题是研究如何为P个设施选址使得需求点和服务设施之间的距离与需求的乘积之和最小。Goldman给出了在树和只有一个闭环的网络上单个设施选址的简单算法[4];Garey和Johnson证明了P-中位问题是NP -hard问题[5]。近些年来,P-中位问题是研究的热点,许多学者仍然在研究P-中位问题的各种变形和扩展模型。覆盖问题分为集覆盖问题和最大覆盖问题两类。集覆盖问题研究满足覆盖顾客要求的条件下,设施的建设费用(或建设设施的个数)最小的问题。集覆盖问题最早由Toregas建立模型[6]。最大覆盖问题是研究在设施的数目和服务半径已知的条件下,如何在设立设施使得可接受服务的需求量最大的问题。Church和ReVelle最早建立了网络最大覆盖问题的模型[7]。最大覆盖问题同样也是NP-hard问题[8]。在以上三个传统的选址模型基础上,若考虑建设设施的固定费用就产生了固定费用下的设施选址问题。以上的模型虽然可以在理论上解决一部分选址的问题,但是存在一定的局限性。比如:配送中心的运行时间,建设成本,需求位置,需求数量等参数都是确定的。这和实际情况不符。现在国内外学者已经逐渐开始研究更逼近于现实的动态的选址问题。在动态选址范围内,如果以上描述的那些参数不仅是变化的,而且变化是不确定的,那么就是随机选址问题。本文研究的就是在配送中心的建设成本、需求位置、运输距离、需求数量都是随机变化的情况下的多目标的离散选址模型。
本文把供应链大环境下的配送中心的建立,配送中心和需求点的库存和运输成本看成一个整体,提出了基于协同库存和模糊需求的改进的最大覆盖选址模型。模型以供应链的总成本最低和配送中心覆盖率最高为共同目标,考虑了配送中心的建设成本,配送中心到需求点的运输成本,需求点的库存成本等参数,使模型更贴近于实际情况,具有更高的现实意义。模型求解的最终结果会对实际物流系统运作具有指导意义。
1 协同库存和模糊需求
1.1 协同库存
针对需求点而言,供应链上游节点的物资供应是对其下游节点服务水平的重要保证。供应量过多使得运输费用和需求点的库存费用增加;供应量过小导致对下游节点服务水平降低。根据不同需求点的不同需求量合理的控制库存水平是非常关键的。典型的库存策略和需求特征下最优库存成本的分析表明最优库存费用与其要求的需求量之间具有非线性关系,库存和运输费用构成了供应链下配送系统可变总成本中的主要部分。本文提出的协同库存[9]是在供应链框架下把各个配送中心和需求点看成一个逻辑整体,改变了传统的由单一的配送中心固定向不同需求点进行配送的情况,通过相互协作可以做到各个配送中心之间优势互补,产生协同效应,使供应链上的整体效益大于各个独立组成部分的效益总和。协同库存提高了系统的资源的综合利用率和快速响应能力,也改善了单个配送中心由于提前期和订货量的不确定性以及由于生产延迟,运输延迟等而给需求点带来的损失。
1.2 模糊需求
1.2.1 模糊需求的说明
现实情况中需求点的需求肯定是变化的,不同商品随产量、季节、供应能力等变化的规律也不尽相同。无论是配送中心的固定成本、运输成本还是库存成本都和需求点的需求量密切相关,且它们之间不呈线性变化,它们共同组成了物流系统的可变成本。在考虑了可变的需求和库存成本的选址模型里,需求通常是采用某种随机分布来模拟,比如:泊松分布[[p(x=k)=e-λλk/k!,E(x)=λ],λ是唯一的参数,该值越小分布越偏倚;越大分布越对称,当它大于50时认为就是正态分布。我们认为需求的变化是由于下游节点的消耗是变化的,这种消耗有某种内在规律,并不是随机的。用三角模糊数去模拟这个变化,拟合度会比随机分布更好。
例如:某种商品一年的消耗量(表1)
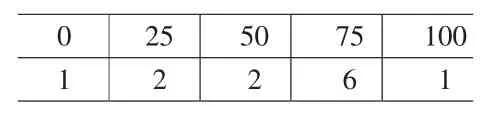
表1 商品消耗量表
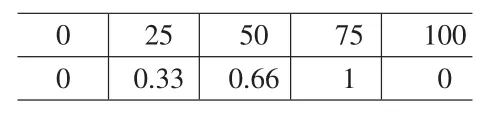
表2 消耗量概率表
表1:第1行表示月消耗量,第2行表示出现的月次数
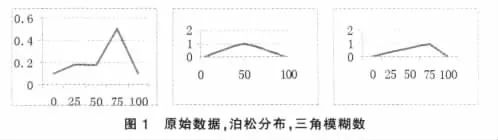
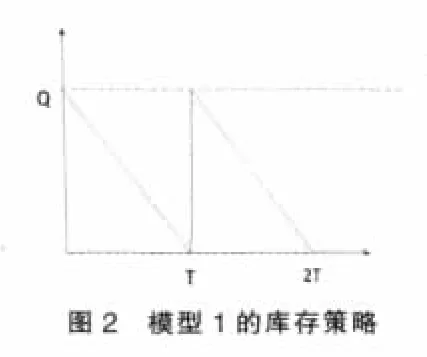
图2:依次是原始数据,泊松分布,三角模糊数对消耗量的模拟曲线。由图2所示,显然模糊三角函数的拟合程度更贴近实际的数据关系。
1.2.2 最优需求量的模糊三角函数建模[10][11]
(1)建模目标:需求点的消耗量是可变的,需求点向配送中心要求的补货量是不变的,要求最优的需求量使得需求点各项成本总和最低。
(2)建模说明:
①需求点的消耗量可以构成一个模糊集,这个模糊集中的任何一个值都有可能成为实
消耗量,但其可能性是不一样的,这些可能性构成了消耗量对该模糊集的隶属度。需求点的可变消耗量用三角模糊数d=(d1,dm,d2)表示,则隶属度表示为U(xi):
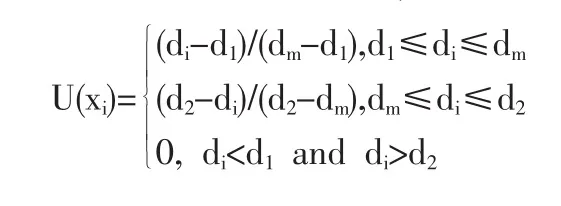
用该三角模糊数去拟合表1的数据,得到消耗量的概率为表2:
②考虑一年的需求,每月产生一个需求期。一个需求期内如果实际需求大于库存,产生缺货损失,反之则产生库存费用。
③di是需求点产生的当期消耗,wi是当期剩余库存,ci是单位库存成本,cd是单位商品价格,cq是单位缺货成本,Q是需求点的订货量。第一期起始库存w0=Q。
当实际需求≥库存,产生缺货费用:

当实际需求≤库存,产生库存费用:

则,需求点的各项总费用为:
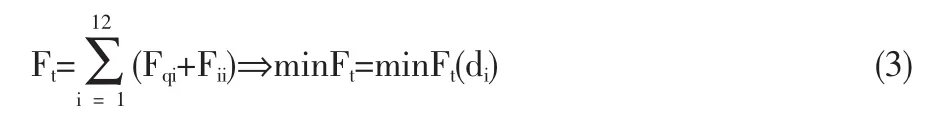
1.2.3 模型求解
di是一个模糊值,因此Ft也是一个模糊值。为求解Q值,需要对其进行反模糊化处理。反模糊化处理的方法很多,我们采用最简单的重心法。将需求点可能的消耗值代入下式。
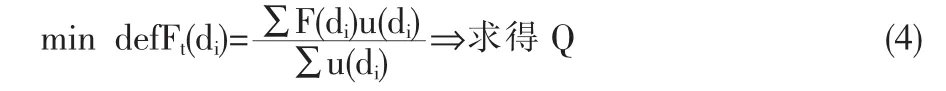
Q值即为需求点最优的需求量。
2 多目标优化模型
2.1 模型假设
建立模型前做如下假设:
(1)把配送中心和需求点看成一个逻辑整体,需求点可以向这个逻辑整体中的任一个配送中心发出需求,配送中心根据整体效益的最大化协调配送量。
(2)供应链上逻辑总成本为:配送中心的总成本+需求点的总成本+运输费用。
配送中心的总成本为:配送中心的固定投资+存储费用。
需求点的总成本为:定购费用(只与定购次数有关,与定购量无关)+定货费+存储费用。
(3)配送中心的固定投资随配送规模呈非正比例变化。它随配送规模的扩大而增加。但是规模效益导致固定成本的下降。因此可以假设它们之间成平方关系[12]。
(4)配送中心向需求点的配送量根据配送中心的最大覆盖模型来决定。也就是说在满足供应链上整体成本最低的情况下,也要考虑配送中心个体的效益的最大化。
(5)根据需求点不同的库存策略,模型有不同形式的变形。
2.2 模型的建立
(1)模型1:不允许缺货,瞬时补货,需求的消耗是匀速的(见图2)。
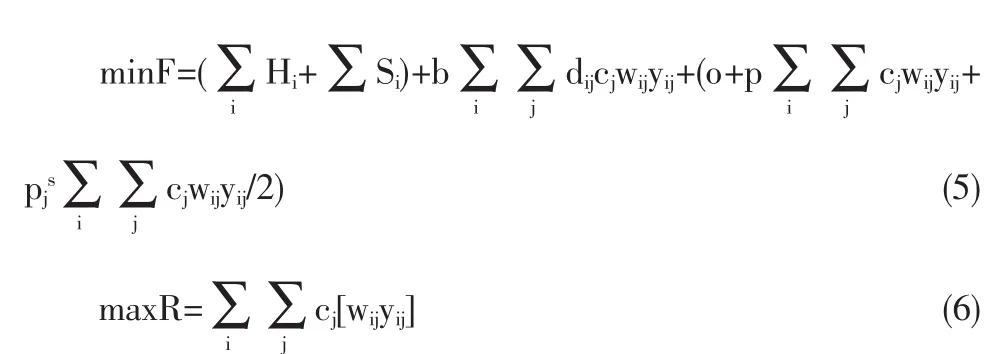
(2)模型2:允许缺货,瞬时补货,需求的消耗是匀速的(见图3)。
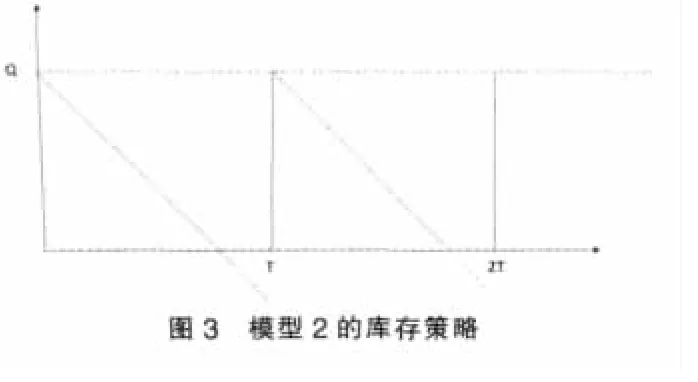
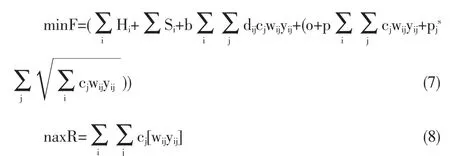
①式(5)、式(7)表示在供应链的协同库存策略下,各项总成本最小。
②式(6)、式(8)表示覆盖半径可变的最大覆盖模型[13]。这个模型是被优化的。传统的最大覆盖模型覆盖状态只有0或1。我们认为当需求点对配送中心贡献的效益权重越大,配送中心对它的覆盖也会越大,覆盖半径可以用一个比例来表示。
③Hi表示配送中心的固定投资
④Si是配送中心的存储费用,我们认为该值是固定值,因为不随需求点的需求量的变化而变化。
⑤b表示单位距离的运输费用,o表示定购费用,p表示单位商品的订货费用,pjs表示单位商品的存储费用。这几个值都是固定值。
⑥dij表示配送中心i到需求点j的距离。
⑦cj表示需求点j的最优需求量。
⑧wij表示需求点j对配送中心i的效益权重。
约束:
①yij取值为0或者1,表示需求点j接受配送中心i的服务。
②xi取值为0或者1,表示是否在i点处设立配送中心。
2.3 模型的说明
(1)模型2的参数表示含义和模型1相同,区别在于当需求点的库存策略改变之后,需求点的库存费用的表达方式发生了变化,表示为存储费用与配送量成平方根关系,现证明如下:
设单位存储费用为cs,每次定货费用为co,单位缺货费用为cq,Q为需求点的需求量,r为消耗速度,消耗为匀速,t1为存储耗尽的时刻,则t1=Q/r。
在t时间内缺货费用为:
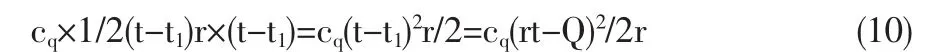
因此,平均总成本

对上式二元函数,求极值,解得

若由i个配送中心来进行配送,每个配送中心配送量为si,则上式可以演变为:
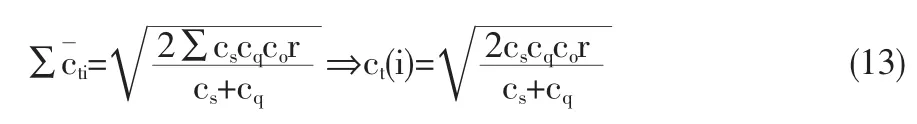
(2)表示需求点j对配送中心i的效益权重。可以根据多个效益参数,构建相互依存和反馈的效益网络,利用网络层次分析法ANP[14]求得每个需求点对每个配送中心的效益权数。ANP系统把复杂的问题分解成各个组成因素,按关系进行聚类形成了复杂有序的网络。上层元素对下层元素有支配作用;同一层次的元素之间既相互独立,又相互依存的;下层元素对上层元素可以存在反馈影响。ANP模型的计算非常复杂,我们采用超级决策Super Decisions软件来辅助解决。该软件基于ANP理论,成功的将ANP的计算程序化,是ANP的强大的计算工具。本文提出的效益权重是指通过ANP建模构建出评价指标体系,再通过评价指标体系的计算得出需求点对配送中心的贡献程度。当贡献程度越高的时候,配送中心对其覆盖的程度也越高,反之则越低。我们综合考虑需求点的成本,服务,风险和机会因素,构造如下的ANP模型结构图4、图5。
图6表示了在“服务”作为判断标准下,评价准则中其他元素的间接优势度比较。
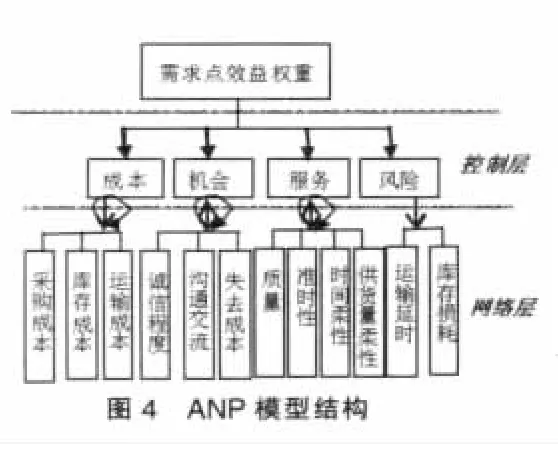

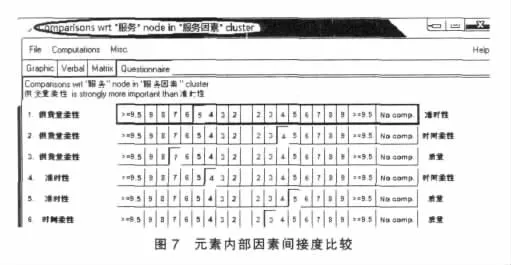
图7表示了“服务”内部元素的间接优势度比较。
3 模型求解
本文所提出的模型是一个多目标的整数混合规划问题,其意义是在供应链的协同库存机制下,实现供应链总成本最低和物流配送中心效益最高的多目标,模型求解的结果是配送中心的选址和配送中心向需求点的供应量。在模型1中目标函数和约束是线性的;模型2中的目标函数是非线性的,约束是线性的;决策变量中有0-1变量和连续变量。我们选择遗传算法[15][16]对模型进行求解。遗传算法是一种全局性的概率搜索算法,它对于函数的形态没有要求,搜索效率高,并且可以处理多目标,混合参数的约束问题。具体算法如下:
(1)采用混合编码方式进行编码。其中0-1变量采用二进制编码形式,供货量采用实数编码形式。个体由1到p的整数排列构成G=(k1,k2,……,kp)表示一个配送中心的解方案。
(2)初始种群的生成。随机生成一组个体,构成初始种群G0,此时迭代次数为gen=0。
(3)适应度函数的选择。采用权重系数法根据决策者的偏好给出两个目标函数相应的权重,将该多目标优化问题转化为单目标优化问题求解。并将该函数作为适应度函数。
(4)交叉与变异。采用单点PMX交叉方式,个体两两交叉。交叉后的染色体按照0.01的概率进行变异操作。每一次操作均对新个体进行约束检查,如不满足约束,则重新进行操作,直至到达群体规模。
(5)迭代次数。当迭代次数达到规定的最大值时终止。
4 结束语
本文将供应链环境下的配送中心和需求点视为利益整体,在利益最大化的前提下采用了覆盖率可变的最大覆盖模型构造了离散的配送中心选址的随机优化模型。目前对于该项目的研究还在进行中,有一些地方还需要继续挖掘。
[1]Hakimi S.L.Optimum Locations of Switching Centers and the Absolute Centers and Medians of a Graph[J].Operations Research, 1964,12.
[2]Drezner Z,Wesolowsky G.O.A New Method for the Multifacility Minimax Location Problem[J].Journal of the Operational Research Society,1978,24.
[3]Kariv O,Hakimi S.An Algorithmic Approach to Network Location Problems 2:Thep-Medians[J].SIAM Journal on Applied Mathematics,1979,37.
[4]GoldmanA.J.OptimalCenterLocationinSimpleNetworks[J]. Transportation Science,1971,5.
[5]Garey M.R,Johnson D.S.Computers and Intractability:A Guide to the Theory of NP-Completeness[J].The Journal of Symbolic Logic, 1983,498.
[6]Toregas C,Swaim R.The Location of Emergency Service Facilities [J].Operation Research,1971,7.
[7]Church R.L,ReVelle C.The Maximal Covering Location Problem. Papers of Regional Science Association,1974.
[8]Daskin,M.S.Network and Discrete Location:Models Algorithms and Applications[M].New York:Wiley,1995.
[9]徐佳,刘晓冰,王继岩,李修飞.钢铁集团原料协同库存控制模型研究与应用[J].计算机集成制造系统,2009,15(2).
[10]万志成,慕静.模糊需求下物流系统订货点量的建模与仿真[J].决策参考,2009,20.
[11]朱卫锋,费奇.复杂物流系统订货点量建模与仿真优化[J].数学的实践与认识,2005,7(35).
[12]黎青松,袁庆达,杜文.一个结合库存策略的物流选址模型[J].西南交通大学学报,2000,35(3).
[13]马云峰.网络选址中基于时间满意的覆盖问题研究[D].华中科技大学,2005.
[14]T.L.Saaty.Decision Making with Dependence and Feedback[M]. Pittsburgh:RWS Publication,1996.
[15]李敏强,寇纪淞,林丹,等.遗传算法的基本理论与应用[M].北京:科学出版社,2002.
[16]周明,孙树栋.遗传算法原理及应用[M].北京:国防工业出版社, 1999.
(责任编辑/易永生)
F252.3
A
1002-6487(2011)06-0066-04
“十一五”国家科技支撑计划项目(2006BAH02A06)
猜你喜欢
西部交通科技(2022年2期)2022-04-27
中国纤检(2021年3期)2021-11-23
数学大王·中高年级(2021年6期)2021-09-27
当代水产(2020年2期)2020-03-17
山东工业技术(2019年13期)2019-05-30
中国科技纵横(2017年14期)2017-08-17
中国经贸(2017年7期)2017-05-02
中学生数理化·高二版(2016年3期)2016-12-26
专用车与零部件(2016年2期)2016-04-11
汽车维护与修理(2015年2期)2015-02-28
