
使用垂直数据格式挖掘频繁项集
2011-11-27 01:46陈伟
网络安全与数据管理 2011年18期
陈伟
(淮南联合大学 计算机系,安徽 淮南232038)
通常,关联规则挖掘是指从一个大型的数据集中发现有趣的关联或相关关系,即从数据集中识别出频繁出现的属性值集(Sets of Attribute-Values),也称为频繁项集(Frequent Itemsets,简称频繁集),然后再利用这些频繁集创建描述关联规则的过程。
1 关联规则挖掘算法
关联规则挖掘算法——Apriori算法是使用候选项集找频繁项集的过程。
Apriori算法通过对数据库D的多趟扫描来发现所有的频繁项目集。在第一趟扫描数据库时,对项集I中的每一个数据项计算其支持度,确定出满足最小支持度的频繁1项集的集合L1,然后,L1用于找频繁2项集的集合L2,如此下去……在后续的第k次扫描中,首先以k-1次扫描中所发现的含k-1个元素的频繁项集的集合Lk-1为基础,生成所有新的候选项目集CK(Candidate Itemsets),即潜在的频繁项目集,然后扫描数据库 D,计算这些候选项目集的支持度,最后从候选集CK中确定出满足最小支持度的频繁k项集的集合Lk,并将Lk作为下一次扫描的基础。重复上述过程直到不再发现新的频繁项目集[1]。
2 关联规则算法的改进
从Apriori算法中由k频繁项集生成k+1频繁项集时,首先生成候选项目集Ck+1,该函数不仅要对 k项集的所有符合Apriori算法条件的数据进行交集,并且要判断候选项目集的所有子集是否在k频繁项集中。该函数生成的许多候选项目集并不是要找的频繁项集,但在扫描数据库时,要记录下这些数据的出现次数,这会耗费大量的CPU开销。如果D中的事务数很大,k频繁项集中项数很多,则侯选项目集的元素个数就会很大,例如2 000个频繁 1项集,将产生 2 000×999/2=999 000个候选2项集。如此巨大数量的候选项目集,对它进行出现次数的统计时开销非常大,这也是整个算法性能优劣的关键所在。
(1)使用垂直数据格式挖掘频繁项集
Apriori算法是从 TID项集格式(即{TID:itemset})的事务集挖掘频繁模式,其中TID是事务标识符,而item-set是事务TID中购买的商品集。这种数据格式称作水平数据格式。另外,数据也可以用项-TID集格式(即{item:TID_set})表示,其中 item是项的名称,而 TID_set是包含item事务标识符的集合。这种格式称作垂直数据格式。下面使用垂直数据格式进行有效的挖掘频繁项集。
首先,通过扫描一次数据库D,在求频繁 l项集的同时,把数据由水平格式转化为垂直格式,即记录下每个项集在事务数据库中出现时该条数据在数据库D中的TID号,则项集的支持度计数直接是项集的TID集的长度。从k=2开始,根据Apriori性质中相交条件的项集进行Apriroi连接运算,使用频繁k项集来构造候选k+1项集。通过取频繁k项集的TID集的交计算对应的k+1项集的TID集。如果该TID集的长度大于最小支持度计数,则该记录为频繁项集。重复该过程,每次k值增加1,直到不能再找到频繁项集或候选项集。
(2)挖掘实例
设事务数据库D,如表1。
假定要求最小支持度计数为2,扫描一次该数据集可以把它转换成表2所示的垂直数据格式。
2015年东京警视厅的数据显示,一年中有1.3998万人借钱,借出去的金额为688.7346万日元(约40万元人民币),归还率是78.6%,这一数据比2009年的64.3%有了很大进步。但是,也可以看出,超过20%的人,还是借钱没还。
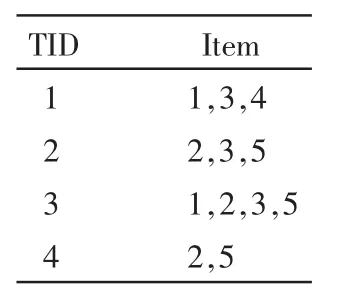
表1 事务数据库
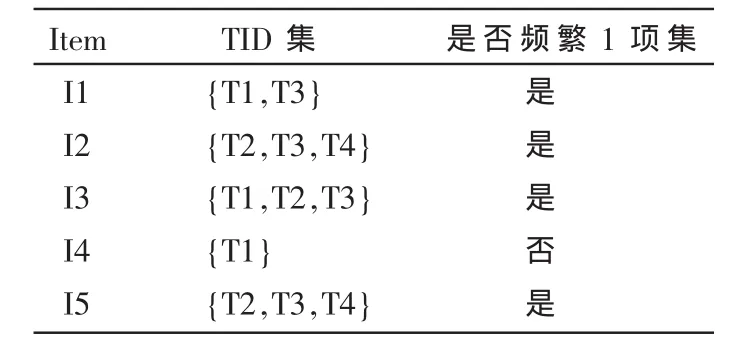
表2 频繁1项集
通过取每对频繁单个项的TID集的交,可以在该数据集上进行挖掘。由于表2中有4个项是频繁的,总共进行6次交运算,结果有6个非空2项集,如表3所示。

表3 频繁2项集
根据Apriori性质,对得到的频繁2项集求交集,只进行1次交集,所以符合条件的频繁三项集为{I2,I3,I5}。如表 4所示。

表4 频繁3项集
通过挖掘可以验证最终得到的频繁项集和用Apriori算法得到的结果是相同的[2-3]。
(3)算法的描述
输入:事务数据库D;
最小支持度计数阈值min_sup。
输出:D中的频繁项集L。
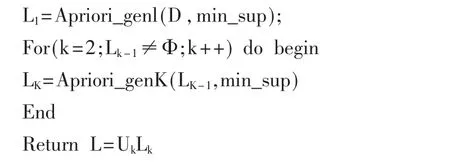
输出:所有的频繁1项集。

输入:频繁k-1项集。最小支持度计数min_sup。
输出:所有的频繁k项集。

3 改进算法的分析
理论上,改进算法应快于算法Apriori,原因如下:
(1)该算法不用求候选频繁项集,从而省去了项集进行连接步以后对该项集所有子集的判断,这会节省大量的CPU开销,尤其是当数据库D中的数据比较多,同时候选项集比较多时,例如频繁1项集2 000个,根据Apriori性质,则候选频繁1项集要有2 000×999/2=999 000个,但其中也许只有少数是要找的频繁2项集。Apriori算法要求其中所有999 000个在数据库中的频繁度。
(2)除了由频繁k项集产生候选k+1项集时利用Apriori性质之外,这种方法的另一优点是不需要扫描数据库来确定k+1项集(k≥1)的支持度。这是因为每个k项集的TID集携带了计算该支持度所需的完整信息。
该算法的缺点是TID集可能很长,长集合不仅需要大量空间,而且求交运算需要大量计算时间。
[1]韩家炜.数据挖掘概念与技术[M].北京:机械工业出版社,2000.
[2]陆楠.关联规则的挖掘及其算法的研究[D].长春:吉林大学,2007.
[3]罗可,张学茂.一种高效的频集挖掘算法[J].长沙理工大学学报(自然科学版),2006,3(3):84-90.
[4]汪光一.关联规则挖掘算法的研究[D].北京:北京交通大学,2007.
[5]高峰,谢剑英.发现关联规则的增量式更新算法[J].计算机工程,2000(12):49-50.
[6]KANTARDZIC M(美).数据挖掘-概念、模型、方法和算法[M].北京:清华大学出版社,2003.
猜你喜欢
中国交通信息化(2022年10期)2022-11-17
河南水利年鉴(2020年0期)2020-06-09
天津科技大学学报(2018年4期)2018-08-22
华中师范大学学报(自然科学版)(2017年6期)2017-12-26
大连理工大学学报(2017年5期)2017-09-20
电脑知识与技术(2017年6期)2017-04-26
科技与创新(2016年17期)2016-11-04
江西理工大学学报(2013年1期)2013-03-20
中南民族大学学报(自然科学版)(2011年2期)2011-02-07
浙江师范大学学报(自然科学版)(2010年2期)2010-01-11
