
AES快速算法的扩展指令集实现*
2012-01-24 06:21封斌齐德昱
华南理工大学学报(自然科学版) 2012年6期
封斌 齐德昱
(华南理工大学计算机系统研究所,广东广州510640)
随着硅片制造工艺技术的发展,微处理器芯片上的晶体管数目已达到十亿数量级,并且片上晶体管的密度仍然按照摩尔定律持续增加.结构设计者在面对高性能需求压力时,可充分利用硬件和器件技术的发展,通过芯片上丰富的逻辑资源实现附加的应用专用硬件,使系统整体达到较高的性价比,以满足具体应用对性能和能耗的需求.目前,芯片级硬件加速常用的方法有协处理器和指令集扩展,如浮点协处理器、先进精简指令集处理器(ARM)中的CP15协处理器、密码协处理器[1]、多媒体扩展指令集MMX等.
高级加密标准(AES)已在网络通信安全等领域得到广泛的应用[2-4].Soliman 和徐志军等[5-6]给出了AES协处理器的实现方案,可在不修改微处理器内部结构的条件下获得较高的加速比.但在资源受限的嵌入式系统环境下,如无线传感器网络、智能卡、射频标签等,用协处理器实现加密算法的硬件加速缺乏灵活性,并需要更大的芯片面积,产生较大的系统功耗,此时,用扩展指令集的方法,可在不明显增加系统成本和功耗情况下,显著提高系统处理速度.Arif和 Heinrich 等[7-8]在 NiosII处理器上将 AES算法作为一个整体用硬件逻辑实现,并给出了对应的扩展指令,但都是将整个加密流程作为一个整体用扩展指令实现,此种方式实际上与协处理器法消耗的面积相同但效率更低,未体现出扩展指令面向细粒度任务进行硬件加速的特性.Stefan等[9]在leon2处理器上针对AES算法的S盒设计了专用的扩展指令,对加密过程的加速比为1.43,效率并不明显.Elbirt[10]在SPARC V8结构兼容处理器上针对AES算法中轮变换的4个轮函数设计了专用指令;夏辉等[11]对 AES算法的程序代码进行汇编编译后,对耗时较多的5个常用模块设计了专用指令,并与ARM9TDMI处理器上的实现方案进行了比较;Bertoni等[12]在ARM处理器仿真环境下实现了AES算法的指令集扩展;但上述3种方案都没有考虑在32位处理器上实现AES算法时,可通过优化AES算法的结构降低运算复杂度、提高运行效率.
Daemen等[13]以32位数据运算为基础,提出了AES快速实现软件算法,即将AES算法中计算密集的轮变换中的4个轮函数合并为对一组前向查找表的查找操作,大幅降低了算法本身的运算复杂度.本研究基于该快速算法,实现了两种扩展指令集的AES算法硬件加速方案:(1)基于片内存储器存储快速算法查找表的方法;(2)用硬件逻辑电路实现S盒并计算出快速算法查找表对应元素的方法.文中在可配置处理器NiosII系统硬件环境下,实现了上述两种方案的扩展指令集硬件加速机制;其中,AES算法中的控制部分由运行在NiosII微处理器核上的应用软件完成,使用VHDL语言将计算密集的轮操作部分用硬件逻辑电路实现,并在基于EPS2C35芯片的硬件环境下进行了验证.
1 AES算法及其结构优化分析
AES算法建立在有限域GF(28)之上,属于对称密钥算法中的分组迭代密码算法,采用替代/置换(SP)网络结构.其中,非线性层为字节替换函数,其包含一个作用在状态字节上的S盒,用以完成多轮迭代后输出的高度混淆,S盒中元素的对应关系为对输入字节在有限域GF(28)上求逆,再加一个仿射变换,在软件算法中一般采用查表法实现;线性层由行位移函数和列混合函数组成,用以确保多轮迭代后的高度扩散,行位移函数按照预先定义好的偏移量对输入的状态矩阵进行循环移位,列混合函数是有限域GF(28)上的线性变换;轮密钥叠加函数实现了密钥与明文的结合,该函数将轮密钥和待加密数据行按位异或,起到子密钥的控制作用;轮密钥扩展模块通过对输入的密钥进行迭代,产生各轮所需的子密钥,密钥扩展中也用到了字节替换步骤.
AES算法中最复杂的步骤是列混合,该步骤执行了一个有限域GF(28)上的多项式乘法.其他所有的步骤都是替代、旋转、移位操作.以加密过程为例,AES快速软件算法在一次轮变换中,将输入矩阵中一列数值的4个轮函数操作步骤,合并成对1个前向查找表(FT)的4次查表操作和4个异或操作,每张FT由256个32位的表项组成,输入矩阵的4列数据需要4张FT.设加密过程中轮操作的128 b输入为以字节为单位排列成4×4的矩阵a,ai,j表示a中第i行第j列的元素,aj表示 a中第 j列,S(ai,j)为字节ai,j在S盒中得到的替换字节.FT0(aj)是a中第j列aj在前向查找表FT0中得到的替换值,则有

令e为128b的输出矩阵,ej为矩阵e的第j列,kj为本轮扩展密钥的第j列,则有
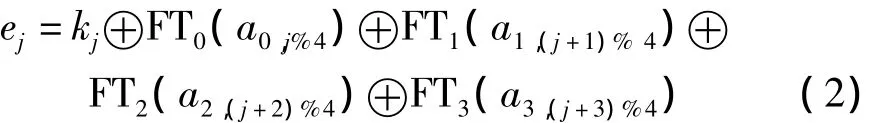
由于4张FT相互之间是旋转的关系,因此,可以将其他3张FT通过表FT0加上shift的逻辑电路来替代.则在每次轮操作的循环迭代中,只需要通过4次查表、4次异或、3次循环移位,就能得到输入矩阵a中1列元素的运算结果ej,即

在末轮操作中没有列混合函数,只需要查询S盒即可.而S盒可以通过FT的掩模得到,因此,优化后的AES算法只需要1张FT0,占用8kb的空间.
2 AES算法扩展指令集实现方案
首先,将AES快速软件算法的前向查找表存放在现场可编程门阵列(FPGA)片上内存实现的单口rom中,用12条扩展指令分别实现密钥扩展、轮变换和末轮变换的操作,FT需要占用1kB的片上存储空间,这对面积、成本比较敏感的嵌入式系统而言,仍存在进一步优化的空间.为了减少芯片面积消耗,文中对上述方案进行了改进,用硬件逻辑计算出输入元素在有限域GF(28)上的逆,即得到S盒中对应的替换值,然后推导出FT和S盒的逻辑关系,从而计算出输入元素对应的FT的表项值,省去了查表法所需要的存储空间,同时也消除了在内存中查找S盒的数据时可能发生的基于cache的侧信道攻击,并最大限度地降低了访问内存的指令所产生的能耗.
2.1 基于查表法的扩展指令集方案
由于应用程序在处理器上对扩展指令是串行调用的,因此,密钥扩展中的轮函数、数据加密流程中的轮函数及末轮操作可以共享一个FT和S盒.为了减少内存消耗,本方案在硬件逻辑中通过掩码,将输入字节对应的S盒值直接从FT中提取,从而可用一个FT来满足加密环节中所有的查表操作.解密流程用到的表可以通过同样的途径实现.
扩展指令的顶层设计图如图1所示,ft_rom是用altsyncram实现的单口rom,大小为256×32 b,用以存放FT的内容.在加密过程轮操作中,所有的查找表操作都是在一条用户指令中完成的,因此,查找表必须放到扩展指令的硬件逻辑中.末轮操作与前9轮操作类似,但其所需的S盒值通过硬件电路从ft_rom中掩模得到,并进行了额外的24个shift操作,因此需要定义针对末轮操作的扩展指令.同时,密钥扩展的操作与加密过程类似,但具体操作不同,也需要创建用于密钥扩展的扩展指令.精简指令集计算机(RISC)架构的NiosII处理器的扩展指令只有2个32b的输入和1个32b的输出,而AES算法中,每一个32b的输出都和128b的明文及128 b的密钥相关,要得到每个32b的输出,就需要4条扩展指令分别对128b明文及128b密钥的4个32b进行操作.其中,加密过程中轮变换需要4条扩展指令完成查表与对应的逻辑操作,数据加密的末轮操作和密钥扩展模块中的查表操作也各需要4条扩展指令.因此,实现加密过程共需要12条扩展指令.由于不同的操作使用了同一个FT,这些指令需要被集成到1个扩展的用户指令硬件逻辑中,由输入信号n来区别具体的指令.

图1 扩展指令的顶层设计图Fig.1 Design of top level of extension instruction
顶层设计的硬件逻辑中,将一个查FT操作、一个shift操作和一个XOR操作结合在一起,即从扩展指令硬件逻辑的dataa端口输入一个32 b的数据,硬件逻辑先进行shift操作,然后执行查找表操作,查找表返回的结果与扩展指令datab端口输入的32b数据进行XOR操作,最后通过扩展指令硬件逻辑的result端口输出.
图1中的硬件逻辑块RoundFunc是一个有2个状态的有限状态机.在第1个状态中,读取32b的dataa,并通过输入信号 n(1..0)决定 dataa的哪8个b通过addr信号输入,即n(1..0)选择了第一个shift操作,也决定了在查找表输出上执行哪一个rotation操作.在第2个状态中,从rom中读取查找表对应的值,n(3..2)决定了是哪一类查表操作,并将查找表的结果与datab进行XOR操作,并输出到result端口.
2.2 用硬件逻辑实现有限域分解
AES算法的S盒是通过一个有限域GF(28)求逆和一个仿射变换两种变换构造而成:S(ai,j)=f(g(ai,j)),其中,g(ai,j)表示元素 ai,j在有限域GF(28)上的求逆的求逆运算可采用复合域分解的方法实现,复合域用GF((2P)Q)表示,称复合域GF((2P)Q)与GF(2k)(k=P×Q)是同构的,复合域可由低阶子域迭代构造而成,即将有限域 GF(2k)求逆运算转换成GF((2P)Q)下的求逆操作.利用同构的复合域方法可用结构简单的逻辑电路实现复合域算法.GF(28)域求逆运算的硬件逻辑实现是S盒设计的关键,文中采用了刘政林等[14]提出的方法.
由式(1)可知,FT与S盒之间是基于GF(28)的一个变量与一个常量的乘法关系.用xtime(x)表示GF(28)上乘以02的乘法,硬件电路中xtime可以用移位运算和条件异或运算来实现.xtime(x)在硬件描述语言VHDL中的函数实现代码如下所示:


由于GF(28)中的每一个元素都能够写成02的不同幂次的和,因此,乘以任何常数的乘法都能够通过重复调用xtime来实现.式(1)易转化为

从而,在用硬件电路计算出输入列元素aj所对应的S盒值S(aj)后,可以通过上式得到元素aj所对应的FT0值,而对应输入矩阵第2/3/4列的FT1/2/3可通过对FT0中元素的shift操作得到.
2.3 NiosII用户定制指令接口的实现
当处理器用一系列复杂的标准指令序列来完成一个操作时,可以设计一个专用的硬件逻辑完成该项操作,专用的硬件逻辑被集成到处理器的算术逻辑单元中,对应一条或多条用户定制指令,即扩展指令.目前有多种支持可扩展指令集的可配置处理器,如Tensilica的Xtensa、Altera的NiosII等.NiosII处理器的扩展指令逻辑[15]集成在流水线结构中.
NiosII处理器提供两种用户定制指令的调用接口方式:(1)利用GCC编译工具的built-in内建函数功能(共提供了52种内建函数的类型),为应用程序提供函数接口定义;(2)直接调用汇编形式的定制指令.built-in内建函数接口仅能满足部分定制指令接口定义的需求;直接调用汇编形式的定制指令方式可使设计人员在程序中通过内联汇编指令,直接调用定制逻辑所对应的定制指令.
用户定制指令的汇编指令语法为

其中:N对应图1中的用户指令索引信号n(3..0);vC 为 result[31..0];vA 为 dataa [31..0];vB 为datab[31..0];v可取为 r或 c,为 r时,表示该条指令访问的是NiosII处理器内部的寄存器文件,当v取为c时,表示该指令访问扩展指令内部的寄存器文件.
完成扩展指令的硬件逻辑电路设计并完成编译、仿真后,需在上层应用的头文件中定义扩展指令的调用接口,包括参数的数据类型、个数以及区分扩展指令的操作码.本方案采用了built-in接口方式,下面给出了用于加密流程轮变换的FT查表指令及其操作码的定义,每条指令具有2个32b输入和1个32b输出.

应用程序中调用包含扩展指令的轮变换的形式如下所示:

3 实验结果与分析
本研究所采用的硬件平台为基于Altera CycloneII EP2C35F672C8芯片的FPGA开发板,在所有的测试方案中都统一采用NiosII/s标准型内核.采用电子密码本(ECB)模式的AES算法.测试用例中的测试向量统一采用 KAT(Known Answer Test)模型[16],采用一次一密的方式,即每一次加密都生成新的密钥.对KAT中的128组长度为128 b的明文密钥向量组进行加密,并在测试用例中对加密出的结果与KAT给出的密文向量进行对比验证.
为了全面体现扩展指令集方案的特点,共完成了5种AES算法实现方案.基准算法方案为AES算法在NiosII处理器上的C代码实现,其运行环境的硬件平台配置及性能数据为其他方案的对比基准点,字节替换函数采用了查表法,轮操作中的每个函数用单独的函数体实现;快速算法方案为AES快速算法在NiosII处理器上的C代码实现,该方案用以说明针对嵌入式处理器进行应用程序的结构优化,可对嵌入式应用软件的性能产生重大影响;扩展指令(CI)查表和有限域(GF)分解方案为文中描述的两种扩展指令集实现方案;协处理器方案是将AES算法整体用硬件逻辑实现后作为协处理器集成进NiosII处理器系统.
在Quartus9.1环境下,通过性能分析工具,记录、分析了各方案中AES算法所占用的时间百分比、单次调用所消耗的时钟周期数、加速比,及硬件逻辑所占用的LE(Logic Element)资源数、片上内存数等数据.各方案的上述性能数据如表1所示,各方案的时钟周期数、LE资源数和加速比如图2所示.

表1 各方案的性能数据Table 1 Performance data of each schemes

图2 AES加密算法各实现方案性能数据对比Fig.2 Performance data comparison of schemes of AES algorithm
由表1、图2所示结果可见:文中实现的第2种扩展指令集方案,通过计算有限域上元素的逆的方法来替代S盒查表法,可取消查表法所需的片上内存,并且比第1种方案的加速比略有提高,LE资源数略有下降;该方案相比于未经优化的纯软件AES算法可加速241倍,相比于经过结构优化的纯软件快速AES算法可加速1.47倍.在不考虑任务粒度划分以及芯片面积不是主要约束条件的情况下,用协处理器方式实现AES算法所达到的加速比远远超过扩展指令集的方案.
4 结语
利用硬件加速机制来提升处理器针对特定应用的性能,可显著提高计算密集型任务的执行效率.文中结合了AES算法的结构优化和用逻辑电路实现字节替换操作中有限域元素求逆两个层面的措施,用扩展指令集的方法实现了AES算法的硬件加速,显著减少了面积消耗,提高了算法实现的加速比.由于AES算法的关键步骤(如S盒替换、移位、异或等操作),普遍应用在各种加密算法中,文中针对AES的硬件加速实现方案对各种分组加密算法的硬件加速实现都具有参考价值.与协处理器的硬件加速机制对比,扩展指令集机制更适用于面积受限条件下细粒度任务的加速.在面向复杂应用时,按照任务粒度及具体环境,采用扩展指令集和协处理器两种加速机制的混合加速机制,以兼顾系统的性能和灵活性,将是一个高效的、具有广阔发展前景的方法.
[1] 何德彪,陈建华,胡进.高速椭圆曲线密码协处理器的设计与实现[J].华南理工大学学报:自然科学版,2010,38(5):90-94.He De-biao,Chen Jian-hua,Hu Jin.Design and implementation of high-speed coprocessor for elliptic curve cryptography[J].Journal of South China University of Technology:Natural Science Edition,2010,38(5):90-94.
[2] Algredo-Badillo I,Feregrino-Uribe C,Cumplido R,et al.FPGA implementation cost and performance evaluation of the IEEE 802.16e and IEEE 802.11i security architectures based on AES-CCM[C]∥5th International Conference on Electrical Engineering,Computing Science and Automatic Control.Mexico:IEEE ComputerSociety,2008:304-309.
[3] Li Zhen-rong,Zhuang Yi-qi,Zhang Chao,et al.Low-power and area-optimized VLSI implementation of AES coprocessor for Zigbee system [J].The Journal of China Universities of Posts and Telecommunications,2009,16(3):89-94.
[4] Arshad A,Nassar I.An FPGA-based AES-CCM crypto core for IEEE802.11i architecture [J].International Journal of Network Security,2007,5(2):224-232.
[5] Soliman M I,Abozaid G Y.Performance evaluation of a high throughput crypto coprocessor using VHDL[C]∥International Conference on Computer Engineering and Systems(ICCES).Cairo:IEEE Computer Society,2010:231-237.
[6] 徐志军,周顺,谢波.AES_Rijndael算法协处理器设计与实现 [J].电路与系统学报,2007,12(4):37-40.Xu Zhi-jun,Zhou Shun,Xie Bo.Design and implementation of AES/Rijndael algorithm coprocessor[J].Journal of Circuits and Systems,2007,12(4):37-40.
[7] Arif I,Vishnu P N,Mohamed K H.An AES tightly coupled hardware accelerator in an FPGA-based embedded processor core[C]∥International Conference on Computer Engineering and Technology.Singapore:IEEE Com-puter Society,2009:521-526.
[8] Heinrich E,Staamann S,Joost R,et al.Comparison of FPGA-based implementation alternatives for complex algorithms in networked embedded systems the encryption example[C]∥13th IEEE International Conference on Emerging Technologies and Factory Automation.Hamburg:IEEE Computer Society,2008:1449-1456.
[9] Stefan Tillich,Johann Großschädl.Instruction set extensions for efficient AES implementation on 32-bit processors[C]∥Cryptographic Hardware and Embeded Systems-CHES 2006.volume 4249 of Lecture Notes in Computer Science.BerLin:Springer,2006:270-284.
[10] Elbirt A J.Fast and efficient implementation of AES via instruction set extensions[C]∥21st International Conference on Advanced Information Networking and Applications Workshops.Niagara Falls:IEEE Computer Society,2007:396-403.
[11] 夏辉,贾智平,张峰,等.AES专用指令处理器的研究与实现[J].计算机研究与发展,2011,48(8):1554-1563.Xia Hui,Jia Zhi-ping,Zhang Feng,et al.The research and application of a specific instruction processor for AES[J].Journal of Computer Research and Development,2011,48(8):1554-1563.
[12] Bertoni G M,Breveglieri L,Roberto F,et al.Speeding up AES by extending a 32 bit processor instruction set[C]∥Application-Specific Systems,Architectures and Processors.Steamboat:IEEE Computer Society,2006:275-282.
[13] Daemen J,Rijmen V.The Design of Rijndael:AES--the advanced encryption standard [M].Berlin:Springer,2002.
[14] 刘政林,曾永红,邹雪城,等.复合域算法的AES S盒电路实现[J].应用科学学报,2008,26(6):622-626.Liu Zheng-lin,Zeng Yong-hong,Zou Xue-cheng,et al.AES S-box circuit implementation based on composite field arithmetic [J].Journal of Applied Sciences Electronics and Information Engineering,2008,26(6):622-626.
[15] Altera Corporation.Nios II custom instruction user guide[Z].San Jose:Altera Corporation,2008.
[16] National Institute of Standards and Technology(NIST).Description of known answer tests and Monte Carlo test for advanced encryption standard(AES)candidate algorithm submission [EB/OL].(2011-04-22)[2011-11-20].http:∥csrc.nist.gov/groups/STM/cavp/.
猜你喜欢
计算机系统应用(2022年9期)2022-09-20
电脑报(2021年49期)2021-01-06
北京电子科技学院学报(2020年2期)2020-11-20
测控技术(2018年5期)2018-12-09
小型微型计算机系统(2018年9期)2018-10-26
信息安全研究(2018年1期)2018-02-07
电信科学(2016年10期)2016-11-23
电测与仪表(2016年21期)2016-04-11
科技传播(2015年20期)2015-03-25
中国信息化周报(2014年19期)2014-07-22
