
LTE-A系统多点协作传输技术研究
2012-06-25 07:03陈耕雨余建国孙向涛
电视技术 2012年9期
陈耕雨,余建国,孙向涛
(1.北京北方烽火有限公司,北京 100085;2.武汉邮电科学研究院,湖北 武汉 430000)
目前LTE-Advanced考虑的峰值速率(下行4×4天线,上行2×4天线)为下行1 Gbit/s,上行500 Mbit/s。以LTE的峰值频谱效率,只要简单扩充系统带宽即可实现。和峰值速率、峰值频谱效率相比,更有实际意义的指标是提高小区平均频谱效率及小区边缘频谱效率[1]。而多点协作传输(Coordinated Multiple Point Transmission,CoMP)正是为了满足这种要求提出的。CoMP的首要问题便是协作节点的选择,边缘用户的CoMP收益很大程度上取决于合适的协作节点。目前各类CoMP集合的划分已经确定下来[2],并提出了几种协作节点的选择方案[3],但是其中对于最大协作数并没有确定下来,考虑到过度的协作会造成系统开销过大并导致系统性能下降,本文研究了预设差值门限的协作节点选择方法,通过仿真不同预设差值门限下协作用户的比例以及各协作节点数的用户概率分布,得到一个合理的最大协作节点数。针对传统的正比公平(Proportional Fairness,PF)调度[4]在 CoMP 中的缺陷,提出了适用于CoMP系统的归一化PF调度算法,最后通过仿真平均小区吞吐量和小区边缘用户吞吐量,说明不同预设差值对系统性能的影响以及归一化PF在CoMP上的优势。
根据用户数据信息和信道状态信息共享程度的不同,可以将多点协作传输分为联合处理(Joint Processing,JP)和协作调度/波束赋形(Coordinated Scheduling/Beamforming,CS/CB)两大类[2]。如图1所示,可以看出多点协作在消除小区间干扰,提高边缘用户吞吐量方面有着有效的作用。本论文主要讨论的是联合处理的下行联合传输,对于调度/波束赋形不于分析。

图1 传统系统与两种CoMP系统的区别
1 协作节点的选择
在CoMP系统中,引入了由CoMP协作节点组成的协作集合、传输集合以及报告集合的概念。协作集合是由直接或者间接参与用户数据传输的协作节点组成的集合。传输集合是由正在向用户传输数据的协作节点组成的集合。对于联合传输的CoMP来说传输集合即为协作集合。报告集指用户需要向服务小区(Serving eNB)反馈报告集合中的节点到用户的信道状态[2]。这几个集合的相互关系如图2所示。因此,当CoMP的协作集合没有包含潜在的传输节点的时候,用户的CoMP收益就会受到限制。为了研究协作节点的选择对CoMP收益的影响,并且更加贴近实际,在这里采用基站侧静态配置用户的报告集合,然后通过用户的反馈,选择每个用户的协作集合[3]。

图2 各种CoMP集合之间的关系
在系统初始化的时候,根据用户所在的位置读取默认配置的CoMP报告集合,然后测量该用户对应集合中每个协作节点的参考信号接收功率(Reference Signal Received Power,RSRP)。将测量到的用户u的RSRP按照递减的顺序排列,即≥≥ …,其中把对应的节点作为该用户的Serving eNB。当第i个协作节点对应地满足
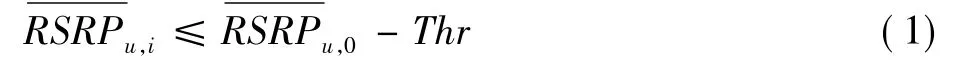
则该协作节点被添加到此用户的协作集合中。其中Thr为预设的差值门限。同时为了防止过度的协作给协作节点带来过多的负担,同样设置MAXnum为协作集合内协作节点的最大数目,当协作集合内的协作节点达到此数目时,将不再添加协作节点。当一个用户对应的协作集合中的协作节点个数大于1时,则称这个用户为CoMP用户;否则这个用户便为非CoMP用户[5]。
2 下行多用户CoMP的系统模型
在获得了不同的协作集合后,便可以选择协作集合内的协作节点进行组网的方式,在此不考虑这些协作节点间的通信时延。设每个协作节点配置nT个发射天线,每个用户配置nR个接收天线,每个协作集合中的协作节点数为N,每个协作集合服务的用户数为M,第m个用户支持的独立数据流为rm,其中1≤rm≤nR。那么每个协作集合和其对应的用户的联合传输CoMP就形成了一个NnT×MnR的虚拟MIMO系统,如图3所示,其中每个用户接收的流数不能大于其接收天线的数目,同时配对用户组可以接收的流数总和不能大于协作集合中所有节点的发射天线数目。

图3 下行CoMP系统模型
协作集合中第i个用户的接收信号表示为

式中:Xi为ri×1维矩阵,为用户i的信号向量;Hi为nR×NnT维矩阵,Bi为NnT×ri维矩阵,为对应协作集合到用户的信道矩阵和预编码矩阵;Ni为nR×1维矩阵,表示加性高斯白噪声向量;等式右第2项为该协作集合中其他用户的干扰,第3项为其他协作集合的干扰。
为了抑制协作用户之间的干扰,联合传输的下行CoMP采用协作集合中的所有协作节点进行联合预编码的处理。为了处理方便,将式(2)整理为更紧凑的模式。在此定义所有用户的收发向量为Y=[,…,]T,X=[,…,]T。全局信道矩阵为 H = [,,…,]T,全 局 与 编 码 矩 阵 为 B = [,,…,]T,噪声向量为 N=[,…]T。多用户的CoMP系统模型可以表示为

按照迫零算法可以得到全局预编码矩阵为[6]

式中:β是为了保证发射信号的总功率满足基站的发射功率的要求,带入式(3)得

式中:E为单位矩阵。
由此,可以发现完全消除了用户间的干扰,并且也抑制了多流间干扰。在忽略掉这些后,用户接收信号向量为

由此可以估算出该用户接收信号的信干噪比为

3 调度机制分析
考虑到系统的吞吐量和用户之间的公平性,在这里采用正比公平算法,在这两个相互对立的方面进行折中。但是普通的PF调度算法,在这里也有一定的局限性。因为协作用户同时享用了多个小区的频谱资源,在一定程度上影响了整个小区的容量。为了降低这种影响,本文提出归一化的PF调度算法。首先,通过PF调度算法得到每个用户的调度因子,然后分别选出小区CoMP用户的调度因子,用该CoMP用户的协作节点数对其进行归一化处理。归一化后的调度因子可以表示为

式中:(C/I)i(t)指第i个用户在t时刻的载干比;n为其协作节点数;λi(t)指第i个用户在以t为结尾的时间窗内的吞吐量。在调度过程中,CoMP用户便使用归一化后的PF调度因子,来减小对系统吞吐量的影响。
由第一节所述的协作节点的选择方法可知,同一个协作节点可能分属不同的协作集合。为了合理安排协作节点所属不同的协作集合、对应的不同小区CoMP用户和此协作节点的非CoMP用户之间的调度关系,笔者将根据不同的用户数和其调度因子将协作节点的传输频段进行划分:一部分用于不同协作集合对其CoMP用户进行协作传输,一部分用于该节点的非CoMP用户的独立传输[7]。频带的划分模型如图4所示。

图4 频谱划分图
在频带划分之前,先通过归一化的PF调度算法,得到各用户调度因子k。则该协作节点所属的协作集合A所占传输频段的比例由下式决定

式中:i为协作集合A中所有协作用户数,j为协作集合A中所有协作节点所服务的总用户数。因此每个协作集合中所有协作节点都有共同的频段对其CoMP用户进行协作传输。同理可得该协作节点所属的协作集合B所占的频段,剩下的频段则为此协作节点的非CoMP用户频段。
对于每个协作节点的独立传输频段,各节点各自对其非CoMP用户进行调度,其调度过程为LTE传统的调度过程不变,在此不再复述[8]。下面以协作集合A为例讨论协作用户的调度。设协作集合A中共有N个用户,每次协同传输的用户数为M。通过归一化的PF算法得到其调度因子,并按降序进行排列。按照优先级的顺序依次选出和M个用户,从后选出的M个用户中拿出个用户与之前选出的 M/2 个用户进行配对,列出所有的可能性,依次用迫零算法计算它们的预编码矩阵,通过MIMO的信道容量公式,以系统容量最大化为目标选出最优的协作用户组,即为协作集合A协作用户的调度结果。协作集合A中的协作节点便可以在共同的传输频段内对这个用户组进行预编码协作传输。这种调度算法,既保证了优先级的原则,又能够在一定程度上提升系统和边缘用户的吞吐量。
4 仿真及结果分析
为了研究协作节点选择对CoMP系统收益的影响,本节中以LTE系统下的MU-MIMO为参考,重点仿真了LTE-A中不同的差值门限Thr下CoMP用户能够选择的协作节点数和CoMP用户的比例,通过分析数据得出1个合适的最大节点数MAXnum。并在此基础上仿真采用PF调度和归一化PF调度的多用户CoMP对应的平均小区吞吐量和小区边缘用户的吞吐量,通过对比分析便可得到归一化PF在CoMP中的优势。本文使用LTE系统级的仿真平台,在原有的系统功能上加入了CoMP的功能,并进行了一定的改进和优化。仿真的具体参数如表1所示。

表1 仿真具体参数
首先,笔者仿真LTE-A中不同的差值门限Thr下CoMP用户能够选择的协作节点数和CoMP用户的比例。在此设置协作集合内协作节点的最大数目MAXnum为10。图5a给出了不同预设门限Thr下,不同用户对应的协作集合内的协作节点数的概率分布。从图中可以看出,当Thr=3 dB时,只有2%的用户对应的协作集合中有3个协作节点,并且没有UE的协作集合中有超过3个协作节点。当Thr=7 dB时,有7%的用户对应的协作集合中有3个协作节点,只有1.2%的用户对应的协作集合中有超过3个协作节点。因此,考虑到过多的协作节点数造成的系统负担,设置协作集合内最多的协作节点数MAXnum为3,就能保证大多数用户的潜在协作收益。图5b给出了不同的Thr增大而不断增加,Thr下CoMP用户的比例。当Thr=0 dB时,用户只有Serving eNB作为它的传输节点,那么CoMP用户的比例便为0。随着Thr增大,更多的用户有多个协作节点,便成了CoMP用户。从图中可以看出,当Thr=3 dB时,有13%的用户为CoMP用户,随着Thr=7 dB时,CoMP用户的数目增加到了28%。

图5 协作节点数的概率分布图和CoMP比例图
在得到了合适的最多协作节点数MAXnum后,通过仿真平均小区吞吐量和小区边缘用户的吞吐量来比较PF调度算法和归一化PF调度算法的性能。如图6所示,当采用PF调度算法时,小区边缘用户的吞吐量随着Thr增大而不断增加,这是因为Thr增大时,更多的用户变成了CoMP用户。当Thr=7 dB时,边缘用户的吞吐量增加了18%。但是同时小区的平均吞吐量有了一些下降,这是因为随着CoMP用户的增加,更多的频谱资源被用于协作传输,留给非CoMP用户的频谱资源变少,从而影响了整个小区的吞吐量。

图6 不同差值门限下的平均小区吞吐量和边缘用户吞吐量
在采用了归一化的PF调度算法后,小区边缘用户的吞吐量随着Thr增大而不断增加,但是当超过3 dB时,收益则会缓慢下降。这是因为虽然Thr增大使得CoMP用户增加,可是由于后增加的CoMP用户对应的协作节点的参考信号接收功率差值较大,其多点协作的收益是有限的,并且归一化后PF调度因子下降较快,使得边缘用户的吞吐量略有下降。但是采用这种算法后,小区的平均吞吐量不再下降而且略微有一定的提升,只有在Thr很大的时候才有一定的下降,说明归一化的PF调度算法在抑制平均小区吞吐量的下降上有着良好的作用。
5 小结
本文在LTE-A系统上对多点协作传输技术进行建模,并在系统仿真平台上进行了评估。首先重点仿真分析了不同的差值门限下CoMP用户的比例以及协作节点的数目,得到了合理的最大协作节点数,既保证了潜在的CoMP收益,又不会造成系统的过多负担。针对PF调度算法在CoMP中会导致平均小区吞吐量大幅下降的缺陷,提出适用于CoMP的归一化PF调度算法,在保证边缘用户性能提升的同时,抑制了CoMP带来的平均小区吞吐量的下降。并通过仿真平均小区吞吐量和小区边缘用户吞吐量说明了归一化PF调度算法的优势。在实际的应用中,可以根据情况来选择合适的预设差值以及调度算法。虽然CoMP因为实现的时候还有很多现实的问题,导致迟迟没有标准化,但是由于其在提升边缘用户吞吐量上有着显著的作用,随着以后用户对于高速数据要求的增加,CoMP技术会得到更多的关注和发展。
[1]3GPP REV-080003,Views for the LTE-advanced requirements[S].2009.
[2]3GPP TR 36.814,Further advancements for E-UTRA physical layer aspects[S].2009.
[3]3GPP.CoMP cell set configuration[EB/OL].[2011-10-10].http://www.3gpp.org/ftp/tsg_ran/WG2_RL2/TSGR2_66/docs/R2-093075.zip.
[4]王映民,孙韶辉.TD-LTE技术原理与系统设计[M].北京:人民邮电出版社,2010.
[5]3GPP.Selection threshold and maximum size of CoMP cooperating set[EB/OL].[2011-10-10].http://www.3gpp.org/ftp/tsg_ran/WG1_RL1/TSGR1_58/Docs/R1-093572.zip.
[6]张健,刘元安,谢刚,等.多用户MIMO下行系统迭代迫零预编码[J].北京邮电大学学报,2010,33(4):104-108.
[7]3GPP.Further discussion of frequency plan scheme on CoMP-SU-MIMO[EB/OL].[2011-10-10].http://www.3gpp.org/ftp/tsg_ran/WG1_RL1/TSGR1_56b/Docs/R1-091415.zip.
[8]3GPP.Views of schemes for CoMP[EB/OL].[2011-10-10].http://www.3gpp.org/ftp/tsg_ran/WG1_RL1/TSGR1_63b/Docs/R1-110551.zip.
猜你喜欢
作文成功之路·小学版(2019年8期)2019-09-18
读者(2017年14期)2017-06-27
集装箱化(2017年4期)2017-05-17
集装箱化(2016年11期)2017-03-29
集装箱化(2016年12期)2017-03-20
通信产业报(2016年44期)2017-03-13
读写算(下)(2016年9期)2016-02-27
电子工业专用设备(2015年4期)2015-05-26
集装箱化(2014年2期)2014-03-15
雕塑(1999年2期)1999-06-28
