
一种SVM集成的图像分类方法研究
2012-06-29 01:37罗会兰杜连平
电视技术 2012年23期
罗会兰,杜连平
(江西理工大学信息工程学院,江西 赣州 341000)
责任编辑:哈宏疆
随着现代信息技术的发展,图像已经成为了一种重要的信息载体。信息量日益增大的同时,也带来了海量的图像数据,这就对如何快速而有效地进行图像数据分类提出了新的挑战。然而,由于位置、尺度、光照及背景噪声等的影响,也在一定程度上加大了图像分类的难度。现存的基于形状的模型化模型[1-2]试图定位不同的物体局部并确定它们在空间上的关系。尽管这些方法可能表示能力强,但是这种空间约束模型无法处理或识别较大的变形,比如大的但不在一个平面内的旋转和遮挡等。近年来,一些用于图像分类的主流方法是使用独立块的集合来表示图像,这些独立块由局部视觉描述子来描述[3-5]。其中较为典型的是词袋(Bag-of-Words,BOW)模型,它来源于文本分类中的“texton”模型[6],确定每类中特定的语素(texton)比例,而忽略它们之间的空间关系。尽管BOW模型没有显示形状模型化,学习到的模型对于形状不规则的物体或者高度结构化的物体类都是非常有效的[7]。在文献[8]中,首次将这种文本检索模型应用到视觉检索中,证实了这种模型的有效性。在检测到独立显著性区域块(或称为兴趣点)且为这些区域块计算描述子(也就是特征表示)之后,必须为训练和测试图像表示它们的分布。一种较为流行的表示显著性区域块分布的方法,也称为图像量化方法[9],是通过对特定训练图像集的描述子进行聚类得到一个视觉词汇本。然后图像表示成视觉单词标签的直方图。在这种情形下,文档就是图像,它们根据视觉词汇本来量化,然后用传统分类器来分类。
基于此,本文提出了一种支持向量机(Support Vector Machine,SVM)集成的图像分类方法。在BOW模型描述图像的基础上,首先,分析视觉单词数目对于分类性能的影响,从而获得最佳分类性能时的视觉单词数目;其次,考虑训练多少个不同SVM分类器,使得集成分类结果后能到达最好的分类性能。实验结果表明SVM集成的图像分类方法有效提高了分类精度,具有一定的稳健性。
1 SVM集成的图像分类方法
本文研究将集成学习的优势应用到图像分类中。图1是提出的SVM集成的图像分类方法的流程图。分类过程包括两个阶段:训练阶段和测试阶段。在训练阶段,可以得到图像不同的SIFT特征、不同的视觉词汇本、不同的BOW模型。利用这些不同的BOW模型可以训练得到不同的SVM分类器;在测试阶段,利用训练得到的不同的SVM分类器分别对测试图像进行分类,进而得到不同的分类结果,然后将这些分类结果进行集成作为最终的分类结果。
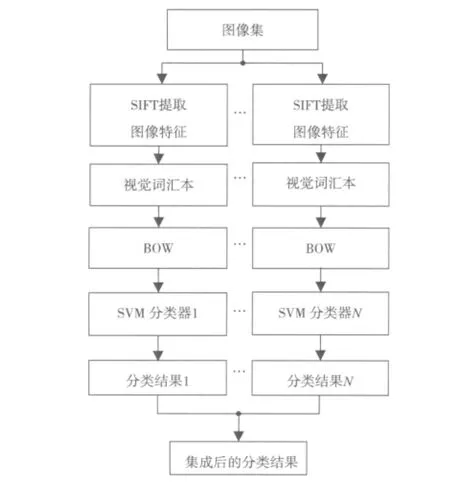
图1 SVM集成的图像分类流程图
1.1 相关知识
Bag-of-Words在自然语言理解中是用来表示文档的流行方法,这种方法忽略单词的顺序,比如,“a good book”和“book good a”在模型中是一样的。Bag-of-Words模型把每个文档看成是一个“bag”,所以顺序是不考虑的,“bag”中包含了来自于一个特定字典的词汇。计算机视觉研究领域使用同样的思想来表示图像,这里图像被当成文档,从图像中提取的特征相当于单词。
Lowe[10]提出了一种尺度不变特征转换描述子SIFT(Scale Invariant Feature Transform),它结合了一个尺度不变区域检测子和一个基于检测出的区域上的梯度分布的描述子。描述子表示成梯度和方向的三维直方图。在每个位置和方向组合中统计梯度大小。这种梯度位置和方向的量化使得SIFT描述子对于小的几何变形和小的错误更加稳健。
BOW模型的最后一步是将兴趣点对应的描述子矢量转换成视觉单词(类似于文本文档中的单词),这些视觉单词组成一个词汇本(类似于单词字典)。具体做法是采用K-means聚类算法对提取图像的SIFT特征进行聚类,每一个聚类中心看作是图像的一个视觉单词,就能把每一个从图像中提取的特征映射到与它最接近的图像视觉词汇本上,并且能把图像表示为一个视觉词汇本上的直方图特征。一个视觉单词可以认为是一些相似兴趣点的代表。一个简单的方法是在所有的矢量上运行聚类算法,然后视觉单词定义成学习得到的簇的中心。簇的个数就是词汇本的大小。在生成的视觉词汇本的基础之上,将每幅图像中的SIFT特征与视觉词汇本中的视觉单词进行比较。对于每幅图像,分别统计视觉单词出现的频率,从而构建每个图像的BOW描述的直方图特征。
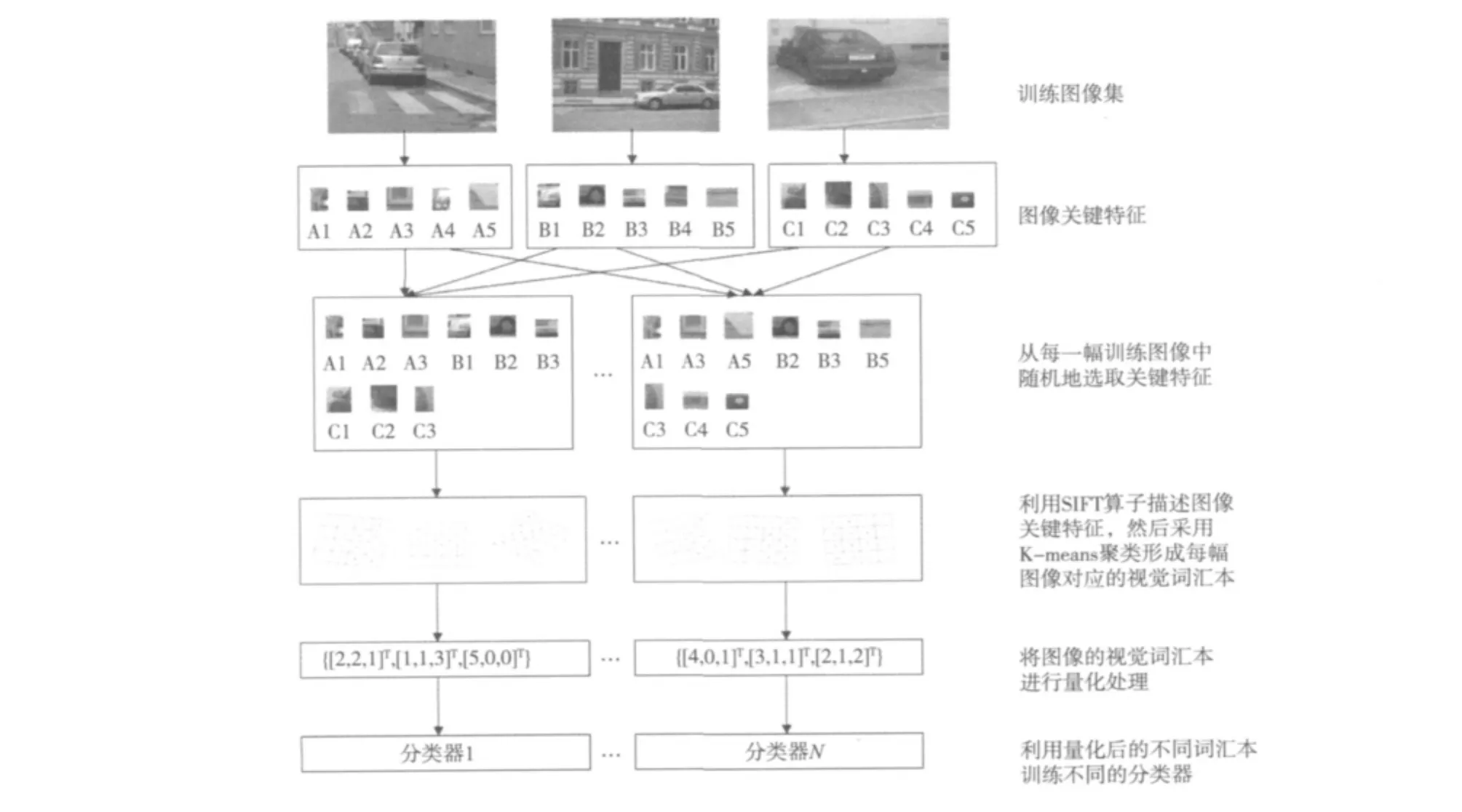
图2 图像量化及分类器训练
图像分类的目标是根据它们包含的物体类别来分类。方法大致遵循传统视觉词汇本方法:先从图像中选择兴趣点,然后用局部视觉描述子特征化兴趣点,最后用学习得到的视觉词汇本对这些描述后的兴趣点置标签。和文本分类相似,通过计算每个标签出现的频率建立一个直方图,此直方图用来描述图像内容。直方图送入分类器来估计图像的类标签。视觉词汇本一般是由训练数据的描述子聚类得到。一个有n个兴趣点,它们的描述子分别是{r1,r2,…,rn}的图像,对于一个有L个单词的词汇本模型V={w1,w2,…,wL} ,传统的词汇量化此图像得到矢量x=[x1,x2,…,xL]T,其中
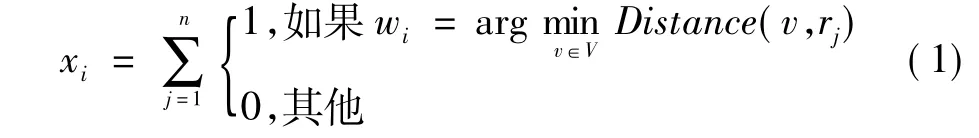
量化后的图像矢量输入到分类器训练、测试,如图2和图3所示。这里讨论的图像分类任务是给每个图像一个类标签。
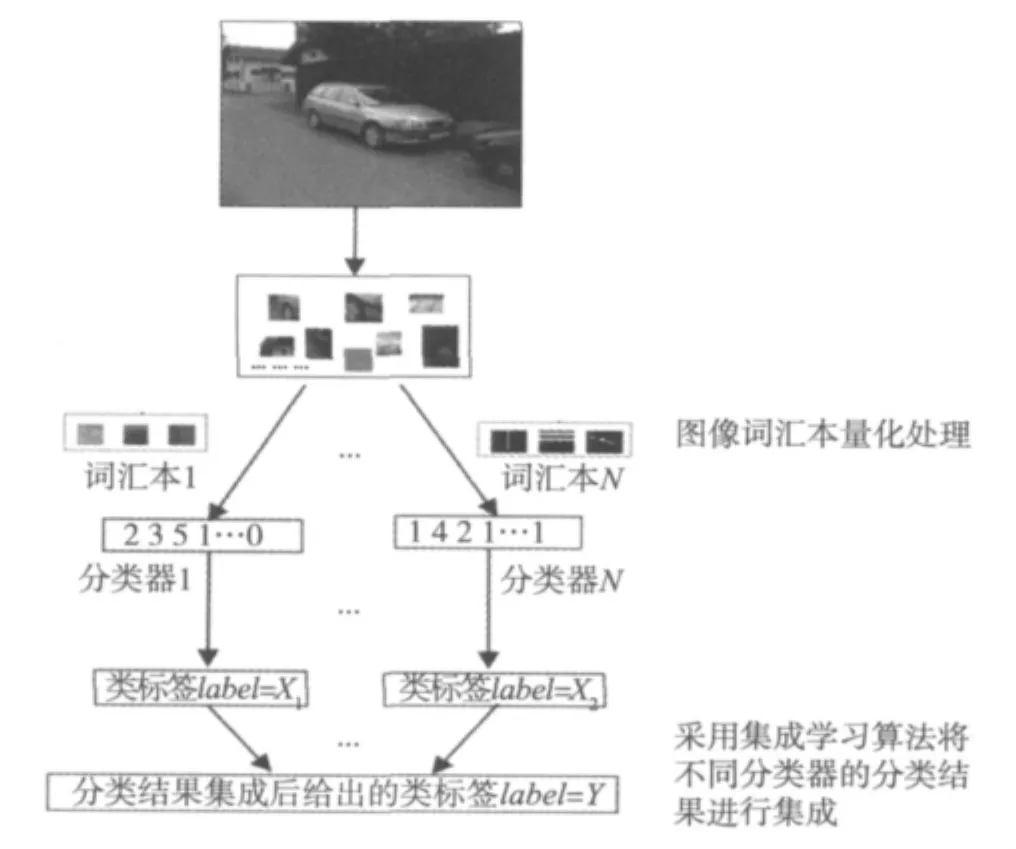
图3 测试图像量化及分类
1.2 分类器集成
分类器集成后能否比单个成员分类器性能更好,取决于各个成员分类器间的差异性。为了更好地理解这一点,假设有3个分类器f1,f2,和f3。有一个测试图像I分别输入到这3个分类器中,如果这3个分类器是相同的,则当f1分类错误时,f2和f3也会给出错误的答案。然而,当这些分类器是独立的,没有相互关系时,则当f1给出错误的答案时,f2和f3也许是正确的,所以在这种情况下,使用多数投票集成方法集成它们就能产生正确的结果,如图4所示。所以集体中成员间的差异性是公认的决定集成泛化能力的一个关键因素。结合多个从不同方面给出的结果的集成方法,是现存的最强的机器学习算法之一。本文的思想就是将集成方法的优势应用到图像分类中。
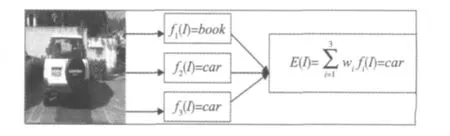
图4 虽然有错误的分类结果,但是集成分类器的分类结果可以得到正确的分类结果
1.3 SVM集成分类方法步骤
Step1利用尺度无关特征转换(SIFT)提取图像特征;
Step2对SIFT特征进行K-means聚类形成视觉词汇本;
Step3将所有图像的SIFT特征与词汇本进行比较,统计视觉单词出现的频率,从而构建图像的BOW模型描述;
Step4利用图像的BOW模型描述训练SVM分类器;
Step5利用Step4得到的SVM分类器对测试图像进行分类,得到相应的分类结果;
Step6重复Step1~Step5 N次,可以得到对测试图像的N个不同的分类结果;
Step7将Step6中得到的N个不同分类结果进行集成,并将集成结果作为最终分类结果,集成算法采用基于簇相似划分算法(CSPA)。
2 实验及实验结果分析
为了证实本文方法的有效性,选取以下6类图像进行MATLAB仿真实验。该图像数据集主要来自Caltech datasets,包括 Airplane,Background,Bike,Car,Face,Motorbike。每一类图像由200~1000幅图像组成。综合考虑实现的效率,每幅图像能提取的最大兴趣点数为100,K-means最大迭代次数为50。
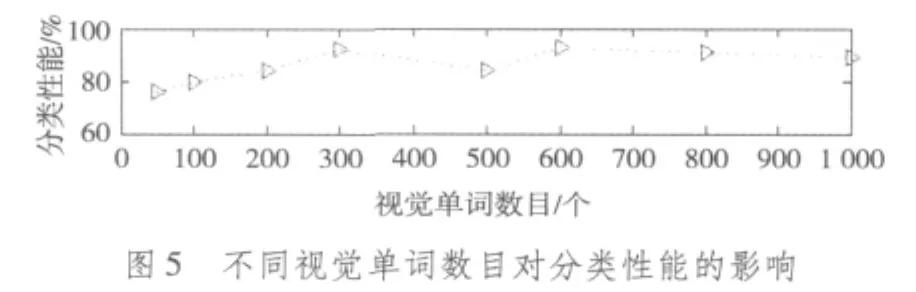
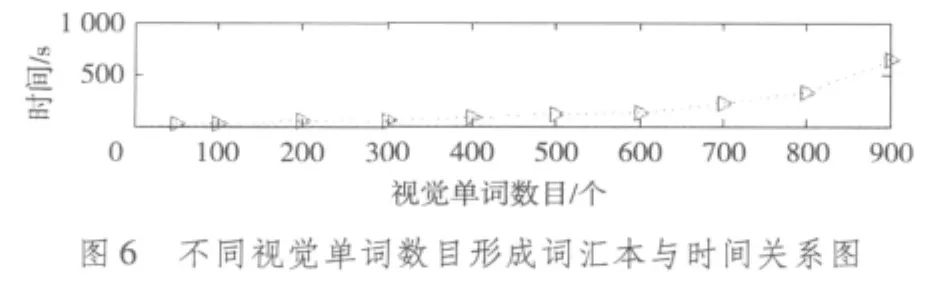
首先,分析视觉单词数目对于分类性能的影响。这里采用8 种不同大小的视觉单词 50,100,200,300,500,600,800,1000,它们分类性能(正确分类图像所占的百分比)的比较情况如图5所示。从图5不难看出,当视觉单词数目过小时,容易忽略图像的某些重要的视觉特征,导致分类性能相对较低;但是当视觉单词数目大于一定值之后,视觉单词的数目继续增加,提升图像分类的性能不是很明显,而且产生的视觉单词数目越多,形成词汇本时所花费的实验时间也就越长,如图6所示。综合考虑分类性能和时间复杂度,在后续实验中选择分类性能相对较高的视觉单词数目600。
其次,考虑到将不同的SVM分类器分类结果集成后得到的最终分类结果不同。在不同的BOW模型的基础上训练并构建数目 N 分别为5,10,15,20,25,30 个不同的SVM分类器,并分别对它们的分类结果进行集成。经过多次试验总结了不同数目的不同SVM分类器的分类结果集成后对分类性能的影响见图7所示。从图7中数据可以看出当不同分类器数目N为10时,集成后的分类性能已经相对较好,虽然随着分类器数目的增多,集成分类性能提升的不是很明显,而且需要花费更多的实验时间。兼顾分类性能和时间复杂度的要求,本实验中对Step1~Step5重复10次,训练产生10个不同的SVM分类器并对测试图像的分类结果进行集成,完成分类实验。

最后,分别用本文提出的方法(即SVM集成分类结果的方法)、文献[11]和文献[12]所提出的方法进行分类实验。其中,文献[11]和文献[12]是没有采用集成学习技术对SVM的分类结果进行集成的。分别比较文献[11]、文献[12]使用方法的分类精度和本文方法的分类精度,见表1。从表1实验数据可以看出,采用本文的分类方法明显提高了分类精度。
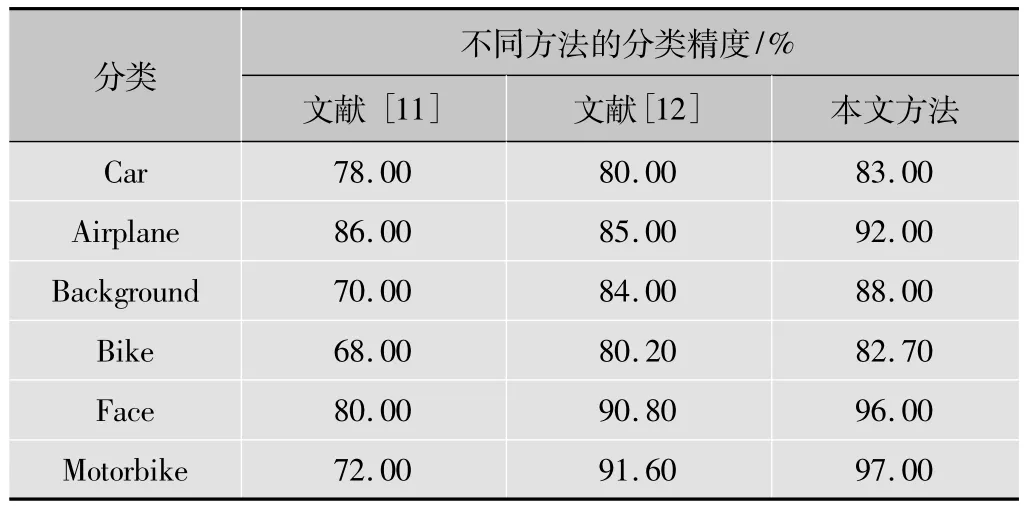
表1 本文方法与其他方法分类精度的比较
3 结束语
本文从BOW模型理论和实验的基础上针对SVM集成的图像分类方法进行了研究。实验结果表明采用集成学习技术的SVM集成的图像分类方法能很好地实现图像的分类,提高了分类精度,具有一定的稳健性。当然,本文研究的方法也存在着一些不足,需要继续完善和探索。如何在训练集上训练KNN、SVM等多种分类器,然后对它们的分类结果进行集成,以提高对图像分类的精度是下一步要研究的内容。
[1]FERGUS R.Object class recognition by unsupervised scale-invariant learning[C]//Proc.IEEE Computer Society Conference on Computer Vision and Pattern Recognition,2003.[S.l.]:IEEE Press,2003:264-271.
[2]LI Feifei.A bayesian approach to unsupervised one-shot learning of object categories[C]//Proc.the Ninth IEEE International Conference on Computer Vision:Volume 2.[S.l.]:IEEE Press,2004:1134-1141.
[3]何友松,吴炜,陈默,等.基于Bag of Features算法的车辆图像识别研究[J]. 电视技术,2009,33(12):104-107.
[4]AGARWAL A,TRIGGS B.Hyperfeatures-multilevel local coding for visual recognition[C]//Proc.IEEE ECCV,2006. [S.l.]:IEEE Press,2006:30-43.
[5]YUEN P C,MAN C H.Human face image searching system using sketches[J].IEEE Trans.Systems,Man and Cybernetics:Part A,2007,37(4):493-504.
[6]VARMA M,ZISSERMAN A.A statistical approach to texture classification from single images[EB/OL].[2012-04-10].http://www.robots.ox.ac.uk/~vgg/research/texclass/papers/varma05.pdf.
[7]WINN J,CRIMINISI A,MINKA T.Object categorization by learned universal visual dictionary[C]//Proc.the 10th IEEE International Conference on Computer Vision:Volume 2.[S.l.]:IEEE Press,2005:1800-1807.
[8]ZHANG J.Local features and kernels for classification of texture and object categories:a comprehensive study[C]//Proc.2006 IEEE CVPR.[S.l.]:IEEE Press,2006:17-22.
[9]MAREE R.Random subwindows for robust image classification[C]//Proc.2005 IEEE CVPR.[S.l.]:IEEE Press,2005:34-40.
[10]LOWE D G.Distinctive image features from scale-invariant keypoints[C]//Proc.2004 IEEE IJCV.[S.l.]:IEEE Press,2004:91-110.
[11]刘硕研,须德,冯松鹤,等.一种基于上下文语义信息的图像块视觉单词生成算法[J].电子学报,2010,38(5):1156-1161.
[12]陈凯,肖国强,潘珍,等.单尺度词袋模型图像分类方法[J].计算机应用研究,2011,28(10):3986-3988.
猜你喜欢
中华胰腺病杂志(2021年1期)2021-02-26
山东医药(2020年34期)2020-12-09
阅读(快乐英语高年级)(2020年8期)2020-01-08
中华胰腺病杂志(2019年4期)2019-08-29
智慧少年·故事叮当(2018年11期)2018-05-14
计算机应用(2017年4期)2017-06-27
意林(绘英语)(2017年5期)2017-05-15
光学精密工程(2016年4期)2016-11-07
光学精密工程(2016年3期)2016-11-07
电测与仪表(2014年15期)2014-04-04
