
基于Indri的检索模型研究
2012-07-13 06:30王莉军
电子设计工程 2012年24期
王莉军
(渤海大学 辽宁 锦州 121013)
Indri是开源的信息检索工程Lemur的一个子项目。Indri是一个完整的搜索引擎,支持各种不同格式文本的索引创建,提出了优秀的文档检索模型,支持结构化查询语言,在研究和实际应用领域都有比较高的价值。Indri系统采用C++语言编写,提供了方便的API供使用者调用,由于项目本身开源,对于开发者而言,也可以方便的对其进行二次开发。
1 Indri检索模型
Indri结合了推理网络模型 (Inference net)和语言模型(language modeling)的优点,提出了一套检索模型,其利用推理网络模型的优势来支持比较复杂的结构化查询(结构化通常指查询语言中的用来表达检索文档中词与词之间联系的operators),又利用语言模型及平滑技术对推理网络中的一些节点进行有效的预估,从而使查询得到比较好的效果[1]。这之前,单纯的推理网络模型节点的预估采用的是规格化的tf.idf(这个值与词在文档中出现的频率称正比,与包含该词的文档数成反比)权重,而单纯的语言模型则无法支持结构化查询。所以Indri检索模型采用了两种模型相结合的方式[2]。
推理网络模型网络图如图1所示,实际上是一个贝叶斯网络(Bayesian networks)。贝叶斯网络是一个有向,无环图。
网络中每个节点代表一个事件,有一个连续或者离散的结果集。每个非根节点存储了一个条件概率表,这个条件概率表完全描述了与给定父节点的情况下该节点出现相关联的结果集的概率。每个与根节点相关联的结果集被指派了一个先验概率。这样在已知网络图,先验概率,条件概率表和节点代表的事件之后,就可以通过网络计算出检索文档中出现查询的概率,并按照这个概率值的大小进行排序输出。

图1 推理网络模型网络图Fig.1 Inference network network diagram
主要包含有以下几类节点[3]:
1)文档节点 D(Document Node);
2)平滑参数节点 alpha,beta(Smoothing parameter nodes);
3)模型节点 θ(Model nodes);
4)特征表示节点 r(Representation concept nodes);
5)查询节点 q(Belief nodes);
6)信息需求节点 I(Information need node)。
文档节点(Document Node):文档节点是文档表示的一个随机值。Indri采用二进制特征向量集对文档进行表示,而不是一般模型中单纯的term序列,文档的特征向量表示可以挖掘出更多的文本的信息,例如短语,是否是大写字母词等。文档中每个term的位置被一个特征向量表示,向量中的元素表示特征的有无。如此一来可以将文档看作一个多伯努利分布(Multiple-Bernoulli distribution)的抽样。
举一个文档表示很简单的例子,假设文档是由5个词组成的,则我们用下面12个特征组成的特征序列来表示文档,如下[4],
Document:A B C A B
假设特征序列是[A B C AA AB AC BA BB BC CA CB CC]

平滑参数节点:是为模型节点提供平滑参数。
模型节点Model nodes(M):模型节点代表所谓的特征语言模型。在Indri框架中,它们是平滑过的多伯努利分布,该分布是对文档表示的一个建模。网络中可能会有不止一个模型节点,与同一文档的不同表示相关联,如上图所示,模型节点包括title,body,h1等3个模型节点,分别为文档的title,body,h1部分的表示,这样就允许模型通过不同的文档表示来进行预估,合并。
这里需要计算 P(M|D),
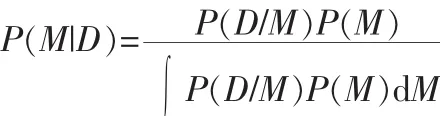
特征表示节点Representation concept nodes(r):特征表示节点是与上述文档表示中提到的特征向量直接相关的二进制随机值。这里,同样的特征节点可能会在网络中出现多次,因为每个相同的特征节点可能会有一个不同的父节点。
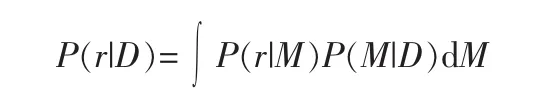
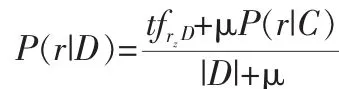
查询节点Belief nodes(q):查询节点是用来合并特征节点或者其他查询节点的二进制随机值。每个查询节点关联到不同的条件概率表,允许节点以多种不同的方式合并。查询节点是根据Indri的结构化查询动态的添加到网络中,因此网络拓扑是随着每次查询改变的。这使得网络很强大,根据不同的查询式,使用不同的打分方法。
信息需求节点Information need node(I):信息需求节点可以看作一个简单的查询节点,将所有的查询节点合并到一个节点,这个节点作为rank的基础[5]。
也就是说 rank的依据是 P(I=1|D,alpha,beta)。
例如一个查询:#weight(2.0#or(#1(north korea)iraq )1.0 policy),查询的意思大概是 “包含韩国或者伊朗以及policy的文档,并且包含north korea或者iraq所占的比重系数为2.0,而包含policy的比重系统为1.0”。推理网络如图2所示。
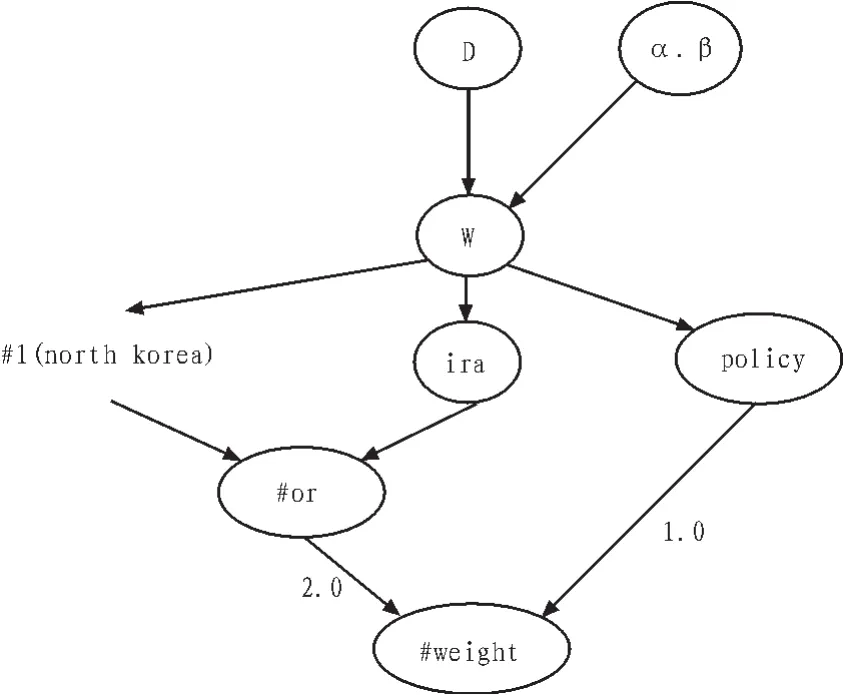
图2 推理网络Fig.2 Inference network
再例如一个查询:#combine( #uw8( hurricane wind ).(title)damage),这个查询的大概意思是“文档题目域中包含一个8个词的窗口,窗口中可以无序的包含hurricane和wind两个词,并且文档中包含damage这个词”。推理网络如图3所示。

图3 推理网络Fig.3 Inference network
2 Indri查询语言
为了充分利用上面提到的检索模型,Indri提供了一套查询语言可以表达复杂的概念。Indri查询语言是一种结构化查询语言,是由一些operation组成的,每个operation代表了推理网络中的一个查询节点(即q节点)[6]。
Operation可以分为以下几类:
1)Basic operation
第三,时间和空间延展性的变化带来的影响。互联网上没有时间和空间的限制,企业只需花费较少的成本就可以加入到全球信息网络和贸易网络中,与消费者进行沟通,将产品的信息传递到消费者中去。网络商城的空间可以无限扩张,可以陈列无限多的商品,消费者通过互联网可以用很低的价格选购商品,所看到的商品比任何一间大商场的产品都多,方便消费者进行商品的比较和择优。
Indri查询语言的基本操作是继承Inquery结构化查询语言的,举一些简单的例子:
#uwN(t1 t2…)包含N个单词的无序窗口
#odN(t1 t2…)包含N个单词的有序窗口
#combine(q1 q2…) 合并查询q1和q2
#weight(w1q1 w1q2…) 合并查询q1和q2并且设置了每个查询的权重
#filrej(c s) 当c不满足的情况下计算表达式s
2)Field operation
这类操作符是为了支持结构化文档设计的。最简单的形式,比如term.field,意思是term只有出现在field时才是与查询相关的。
域可以是文档中的任何打了标签的信息。例如可以是文档的一大段(如一个章节),一小段(如一个自然段),或者只有几个句子(如名词短语等)。一个域也可以多次出现在文档中。
例如wash.np就可以用来实现这样的查询,“查找出现在名词短语中的wash”。
3)Extent retrieval
Indri也支持用域来在某一区域中打分。例如查询#combine[field](q1,…qn),在 field 指定的区域中对(q1,…qn)进行打分和排序。这样可以方便地支持类似段落查询或者语句查询等这样的需求。
4)Date and numeric retrieval
Indri来识别数字相关的性质,包括日期等。为了查询数字相关的性质,Indri提供了#less,#greater和 #equal等操作。对 于 日 期 的 查 询 ,Indri提 供 了 #date:before,#date:before 和#date:before 等操作。
一些相关操作符的计算如下[5]:
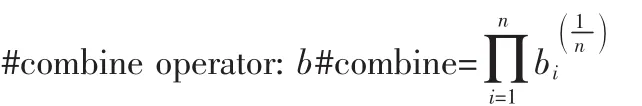

3 结 论
Indri的检索模型合并了推理网络模型和语言模型,可以比较好的支持结构化查询和推理网络节点的预估,里面还涉及了多伯努利分布,贝叶斯方法等数学行比较强的推导过程,从测试结果来看,查询效果比较好,具有较大的参考实用价值。
[1]Strohman T,Metzler D,Turtle H,et al.Indri.A language model-based serach engine for complex queries,IA 2005[C]//Proceedings of the 2nd International Conference on Intelligence Analysis (to appear),2005:5-10.
[2]Strohman T.Dynamic collections in Indri[C]//Technical Report IR-426, University of Massachusetts Amherst,2005:124-125.
[3]Strohman T.Low Latency Index Maintenance in Indri[C]//IR-503, University of Massachusetts Amherst,2006:54-58.
[4]Metzler D,Croft W B.Combining the language model and inference network approaches to retrieval[C]//Info.Proc.and Mgt,2004,40(5):735-750.
[5]Metzler D,Lavrenko V,Croft W B.Formal multiple Bernoulli models for language modeling[C]//2004:540-541.
[6]Zhai C,Lafferty J.A study of smoothing methods for language models applied to information retrieval ACM Trans.Inf.Syst[C]//2004:179-214.
猜你喜欢
九江职业技术学院学报(2022年1期)2022-12-02
客联(2022年3期)2022-05-31
保定学院学报(2022年2期)2022-04-07
中国新闻周刊(2021年26期)2021-07-27
河北理科教学研究(2021年4期)2021-04-19
计算机教育(2020年5期)2020-07-24
福建基础教育研究(2020年3期)2020-05-28
许昌学院学报(2018年4期)2018-05-02
中华建设(2017年1期)2017-06-07
信息安全研究(2016年4期)2016-12-01
