
Web数据挖掘及常用技术浅析
2012-10-21 14:55邓红梅
卷宗 2012年5期
摘要:Web挖掘是通过挖掘Web日志记录来发现客户访问Web页面的模式。用户在面对大量的网上信息束手无策时,Web挖掘技术为用户提供了方便快捷的解决方案。
关键词:Web 挖掘;数据挖掘
引 言
近年来,Internet在不断地普及,WWW在迅速地发展,人们可以通过网络方便地得到自己需要的信息,但是网上信息的大量涌现使得用户经常感到束手无策,甚至常常不知道如何查找自己所需要的信息,用户为此苦恼万分。Web数据挖掘技术提供一个很好的解决方法,它不但可以为访问用户提供方便,而且对提高站点效率、吸引客户等都有很大的帮助。
在现实当中人们常常将Web挖掘与Web信息检索或信息抽取等同起来。实际上它们不是等同的,并且是有区别的:一、信息检索只能以关键词去查找与关键字匹配的简单目标,如果用户给出的不是关键字,而是信息样本,这时信息检索就无法满足用户的要求,但是挖掘系统是可以满足用户要求的,它能够从文本中提取出目标信息的特征,然后根据目标特征在网络中有目的地进行搜索,最后将搜索结果返给用户。二、信息检索实际上是在一定的领域内对特定的信息进行查找和检索,在某种程度上可以看作是Web挖掘中文档分类的一种特殊情况。三、信息检索只是一部分使用到了数据挖掘技术,正是因为这样,在信息检索中在一般情况下是很难发现隐式的数据联系,而Web挖掘却不同,它能从大量看似无关的数据中发现数据联系和知识,并对于决策给予支持。
1 Web挖掘
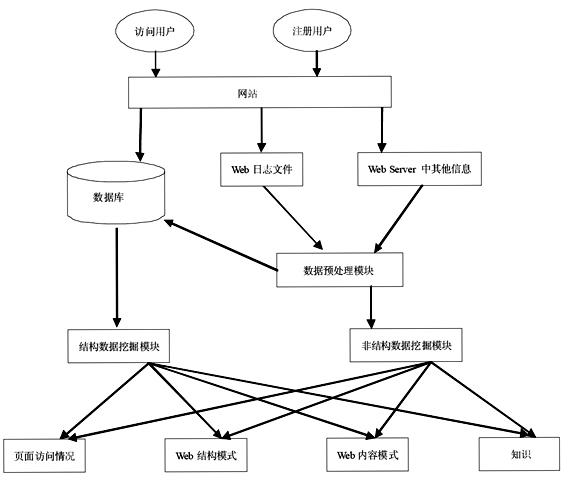
Web挖掘是利用数据挖掘技术从Web页面内容、页面之间的关系与结构、用户的访问记录等Web数据中提取满足用户目标的有用知识、有用信息,以便为Web用户的访问提供方便或为网站经营者改善站点结构提供决策支持等[1]。Web挖掘不是一个单一的技术,涉及互联网技术、统计学、信息学等多个领域[2]。Web挖掘过程可分为多个处理阶段:确定挖掘目标、准备源数据、数据选择及数据预处理、数据挖掘及模式识别、分析评价等阶段。
传统数据库中的数据都是结构化的数据,而Web上的数据是半结构化的,半结构化是相对于数据库中的结构化数据而言的。由于Web的异构性、动态性与开放性等特点,要从这些分散的、没有统一管理的、异构的大量数据中准确、迅速地获取信息是Web挖掘要解决的问题,这也决定了在进行Web挖掘时不能完全依赖于数据库的挖掘技术。面向Web的数据挖掘比面向数据库的数据挖掘要复杂很多,进行Web挖掘要考虑很多问题[3]。
1.数据来源分析。进行Web挖掘时所需要的数据主要来自于三个方面:Web服务器上记录的访问日志、Web服务器上的页面所包含的信息以及客户的相关资料信息。用户访问Web 站点时,站点会记录其访问记录。借助一些工具可以处理和分析Web服务器上的日志文件从而得到有意义、有价值的信息。Web服务器还可以记录用户其他的访问信息,例如:Cookie和用户提交的查询信息等。与此同时,服务器也记录文件的相关属性,例如文件的创建者、修改时间等。而注册用户的资料信息存储在资料数据库中,内容如:客户的姓名、年龄,对于产品的看法,顾客的个人偏好等。Web挖掘的一个难点就是如何从非结构化数据信息中进行有效地信息和数据挖掘。
2.异构数据库环境。从数据库角度来看,Web网站上的信息也可以被当作一种特殊的、复杂的数据库。互联网上的任何站点都是数据源,而且都是异构的数据源,因而站点之间的信息和组织都是有差别的,这就构成了一个巨大的异构数据库环境。如果想在这个巨大的异构数据库上进行数据挖掘必须解决几个问题。第一,必须要想办法把这些分布的数据集成起来,只有将这些不同站点的数据都集成在一起,提供给用户一个统一的视图,才有可能从巨大的数据资源中获取所需的信息或知识。第二,还要解决Web上的数据查询问题,如果不能快速、准确地查找这些数据,就不能对这些数据进行分析、集成和处理。
3.半结构化的数据结构。数据库中的数据和Web上的数据有着很大的不同,数据库中的数据都是根据一定的数据模型来进行具体描述的。而Web上的数据则不同,它没有特定的数据模型来描述,各Web站点的数据是独立设计出来的,之间的差异很大,并且在自述性和动态性上也表现得相当的大的差异。因而,Web上的数据的结构性不是很强,只能说有一定的结构性,同时因自述层次的存在,Web上的数据是一种非完全结构化的或者是半结构化数据。半结构化是Web上数据的最大特点。
4.半结构化的数据源问题的解决。由于数据源的特殊性,要进行Web数据挖掘第一步就建立半结构化数据源模型和半结构化数据模型,解决其中的集成和查询难题。这就必须要建立一个模型来来对Web上的数据进行描述。Web上的半结构化的数据需要定义一个半结构化的数据模型和模型的抽取技术来对现有数据自动地的抽取半结构化模型。面向Web数据挖掘的前提条件就是半结构化模型和半结构化数据模型抽取技术这种技术。
Web挖掘的基本构架如下图所示:
2 Web数据挖掘中的常用技术
常用的Web数据挖掘中技术包括:路径分析技术,关联规则挖掘技术、序列模式挖掘技术和聚类分类技术等[3]。下面对它们进行简单的分析:
1.路径分析技术
对Web数据挖掘时,路径分析技术比较常用的是运用图的方法。因为我们可以用一个有向图来表示Web站点,即:G=(P,I),P代表了页面的集合,每一个顶点就是一个页面,I表示的事页面之间的超连接的集合,有向图中的边被定义为页面之间的超链接。以顶点v为头的边来表示对v的引用,以顶点v为尾的边定义为v引用了其他的页面值,这样形成网站结构图[4]。
2.关联规则挖掘技术
数据挖掘中最常用、最易被人们所接受的研究方法就是关联规则挖掘。使用关联规则技术可以从Web访问事务中找到有价值的知识,这些有价值的知识是隐藏在数据集中的,是事先未知的,不是简单通过数据库的逻辑操作可以推出的,需要经过仔细分析才能得到。例如:75%的用戶在访问页面A的同时也访问了页面B,A与B之间的关联性就属于隐式的知识。最常用的是用APRIOR算法,从事务数据库中挖掘出最大频繁访问项集,它就是挖掘出来的用户访问模式。
3.序列模式挖掘技术
序列模式是指在时间有序的事务集上找出那些时间上有先后次序的数据项,也就是寻找那些形如“一些项跟在另一些项后面”的内部事务模式。例如:访问过页面A的客户中有60%的人在上一礼拜内也访问过与页面A相似的页面B。发现序列模式可以预测用户的访问兴趣。
4.聚类分类技术[4]
分类规则可以挖掘出识别特殊群体的公共特性的描述,这个特性可以用来对数据库里的新数据项进行分类。分类算法的研究比较多,常用的算法有:CART 、C4.5、 ID3等。聚类是将物理的或抽象的对象分为几个组或群体,每个组内的对象很相似,不同组内的对象不相似,与分类最大的不同是事先并不知道类结构及每个对象所属的类。聚类技术则是对符合某一规律特征访问的用户进行用户特征挖掘。最后进行模式分析,挖掘出人们可理解的知识的模式解释。
3 结语
随着互联网应用业务的不断展开,互联网已经发展成为商业、政府等机构从事业务和信息传播的重要渠道。建立互联网动态应用模型,已经成为互联网应用中最活跃的研究领域之一。Web挖掘是利用数据挖掘技术从Web页面内容、页面之间的关系与结构、用户的访问记录等Web数据中提取来满足用户目标的有用知识、有用信息的。通过分析和探究Web日志记录中的规律,可识别网站的潜在客户,增强对最终客户的国际网络信息服务品质,并改进Web站点的结构、运营形式、Web服务器系统的性能和结构。
参考文献
[1] Perkowitz M, Etzioni 0.Adaptive sites: automatically learning from user access patterns.6th Int. World Wide Web Conf.SantaClara, Califormia, 1997
[2] Hahn U,Schnattinger K.Deep Knowledge discovery from natural language texts.In Proc Of the 3rd Intl Conf on Knowledge Discovery and Data Mining.New port Beach,1997,pp.175-178
[3] Tan P N,Steinbach M,Kumar V.《數据挖掘导论》.范明等译.北京:人民邮电出版社,2006年第95页
[4] 王欣如:《基于关联规则的Web日志挖掘技术研究》[D],《重庆大学硕士学位论文》,2007年。
作者简介:
邓红梅(1977-),女(汉),广东省轻工业高级技工学校教师,研究方向:计算机科学与技术。
猜你喜欢
保健医苑(2022年1期)2022-08-30
河北理科教学研究(2021年4期)2021-04-19
计算机教育(2020年5期)2020-07-24
计算机与生活(2018年3期)2018-03-12
中国科技期刊研究(2017年2期)2017-05-14
计算机工程(2015年8期)2015-07-03
浙江大学学报(工学版)(2015年2期)2015-05-30
华东理工大学学报(自然科学版)(2014年5期)2014-02-27
土木建筑工程信息技术(2013年4期)2013-10-17
网络安全技术与应用(2011年3期)2011-03-14
