
基于中文维基百科的词语语义相关度计算
2013-10-15 01:51万富强吴云芳
中文信息学报 2013年6期
万富强,吴云芳
(北京大学 计算语言学教育部重点实验室,北京,100871)
1 引言
语义相关度的计算在很多自然语言处理的应用中都扮演着重要的角色。信息检索[1]系统中使用相关度得分,对查询进行扩展。词义消歧[2]一直以来都是计算语言中一个比较难解的问题。利用词语之间的相关性能够协助计算机进行词义消歧。例如,“削苹果的刀”与“削苹果的皮”,两者都是“动词+名词+助词+名词”的结构,可以利用“苹果”与“刀”,“苹果”与“皮”的相关度对两者加以区分。此外,在文档自动文摘以及问答系统中常常使用相关度或相似度的得分,评估候选语句的精准程度。在拼写校正[3]中也会用到语义相关度的计算。研究如何更好地计算文本或者词汇之间的语义相关度是一个重要的课题。
本文研究基于Gabrilovich&Markovitch提出的基于维基百科的显性语义分析(Explicit Semantic Analysis,ESA)方法[4],对中文词语之间的语义相关度进行计算。将词表示为带权重的概念向量,计算目标词语之间的相关性就转化为比较相应的概念向量。本研究选取的概念由中文维基百科文章明确定义,即将指定的中文维基百科的一个页面作为一个概念,引入概念(页面)的先验概率,利用维基百科词条的词频信息和页面之间的链接信息对算法进行了多种改进。实验结果表明,引入页面先验概率因子,能够明显改善目标词对相关度计算的结果—斯皮尔曼等级相关系数从0.40提高到0.52。
本文组织结构如下:第2节介绍了前人的相关工作;第3节阐述显性语义分析方法的核心思想及基本方法;第4节介绍引入了页面先验概率的改进算法;第5节介绍中文维基百科概念的选取,实验采用的评测数据集以及评测的指标—斯皮尔曼等级相关系数;第6节展示本实验的结果及对结果的分析;第7节对本实验进行了总结。
2 相关工作
语义相关度的计算可以划分为3类方法:基于大规模语料库的方法、基于语义分类体系的方法和基于百科知识的方法。基于大规模语料库计算文本(或单词)的相似度或者相关度,主要有两种方法:一种方法是简单地使用词语共现信息。该方法假定同时出现在文档或者段落中的词在某种意义上相似或者相关,它将文档或者段落视为词的集合,忽略词与词之间的语法信息。另一种方法是对文档或者段落进行浅层的句法分析,得到词汇之间语法关系或者依存关系,在依存分析结果的基础上进行相似度计算。使用词共现信息更具有鲁棒性,不会涉及语句的句法分析,实现起来更加简单。目前有许多关于语义相关度和相似度的研究是基于前一种方法的[5-7]。
英语中基于语义分类体系计算语义相关度主要是依据WordNet[8],而汉语中主要是依据HowNet。前人基于WordNet的层次分类体系实现的词汇语义相似度度量方法有以下4种:1)边计数方法。如果该网络中的两个概念c1,c2之间的连接越多,两个概念之间的距离越短,那么它们就越相似。具体度量方法有:最短路径[9],带权重的链接[10]等。2)信息含量方法。两个概念的相似度与它们共享的信息相关,而共享信息是由在网络层次体系中涵括它们的高层的概念表征。如 Resnik[11],Lin[12]等工作。3)基于特征的度量方法。每一个词都由能表征它性质、特征的词的集合表示,如Tversky[13]。4)组合方法,如 Rodriguez et al.[14]。
随着维基百科的普及和盛行,近年来出现了一些基于百科知识的相关度计算方法。Michael Strube等提出使用Wikirelate!方法[15]计算词语之间的语义相关度,该方法首先将两个目标词t1,t2用以它们为标题的文章来表示,并提取文章的类别信息,然后使用基于文本覆盖的方法,或者利用维基百科的类别树,使用基于路径或信息含量的方法计算两篇文章的相关度,也即是两个目标词的相关度。Gabrilovichand Markovitch提出基于维基百科的显性语义分析方法(Explicit Semantic Analysis,ESA)[4]用于计算文本(或词)之间的语义相关度。孙琛琛等[6]利用英文维基百科结构信息计算语义关联度。李赟等[7]利用中文维基百科进行语义相关词的获取及其相关度分析。
还有研究者利用其他的资源进行语义相关性研究。如利用维基词典计算语义相关性[16],使用网络搜索引擎度量词语之间的相似度[17]等。Torsten et al.[18]的研究表明,基于 German WordNet的语义相似度度量方法比基于维基百科的语义相似度度量方法更接近人工判定的结果;然而,基于维基百科的语义相关度度量却比基于German WordNet的语义相关性度量方法要好。
3 语义相关度计算的基本方法
3.1 基本原理
分布相似在一定程度上能够反映语义相似以及语义相关,因此可以将词语之间的语义相关性度量转化为词语分布的相似性度量。显性语义分析(ESA),是将词表示为带权重的概念向量,计算词语之间的相关性就转化为比较相应的概念向量。本文选取的概念由中文维基百科文章明确定义,即将中文维基百科的页面作为概念。
令N表示中文维基百科的单词数(即词汇表L的大小),M表示选取的概念(页面)数。用wi,j表示词项ti与概念cj的关联程度。该值越大,表明词ti与该概念cj的关联程度越强;反之,则表明词ti与该概念cj的关联程度越弱。词—文档矩阵表示为式(1):
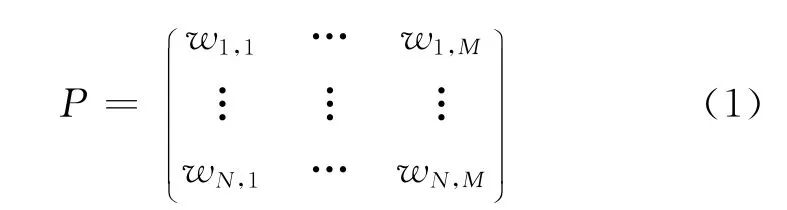
则词t的概念向量V可表示为式(2):

然后,根据概念向量V1和V2,使用cosine方法比较两个向量,计算目标词对<t1,t2>的相关度(当至少有一个目标词不在词表中时两者的相关度记为0),如式(3)所示。
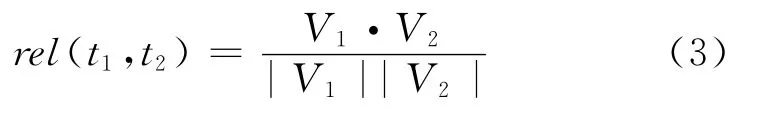
3.2 基本TFIDF方法
Gabrilovich等提出的基于维基百科的ESA方法[4]采用在信息检索中常用的TFIDF(即词项频率与逆文档频率的乘积)作为词与文档的关联程度的度量。使用数学公式表示为式(4):
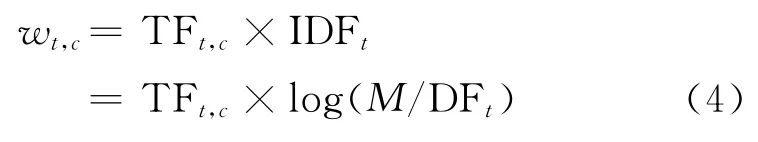
由于IDFt仅由词t决定,对于同一个t而言IDFt是相同的。使用余弦相似度方法比较词的概念向量时,对向量长度进行了归一化,因此事实上IDFt并没有真正参与到计算之中,结果仅由TFt,c决定。于是,可以将各个分量都含有的常量提出来,记为k。目标词t的概念向量可以简单的表示为式(5):

为了便于表述,将此方法记作TFIDF。
4 语义相关度计算的改进方法
利用显性语义分析(ESA)方法,使用TFIDF作为权值度量,计算汉语语义相关度的结果并不理想。本文引入页面的先验概率,提出了以下的改进方法。
在信息检索中使用查询似然模型,将文档按照其与查询相关的似然P(d|q)排序。查询似然模型是信息检索中最早使用也是最基本的语言模型。P(d|q)度量了d与q的相关性程度。利用贝叶斯公式有P(d|q)=P(q|d)P(d)/P(q)。将词t与q对应,概念c与d对应,我们得到词项t与c关联程度,如式(6)所示。
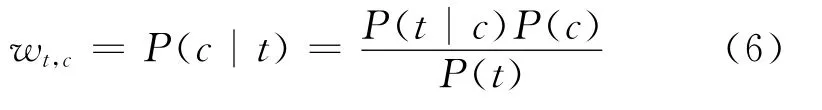
对P(t|c)使用最大似然估计,如式(7)所示。
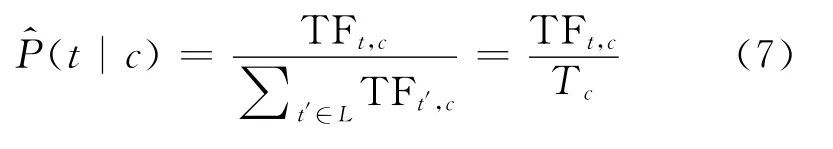
对于给定的t,P(t)是一个常数,于是有式(8)。
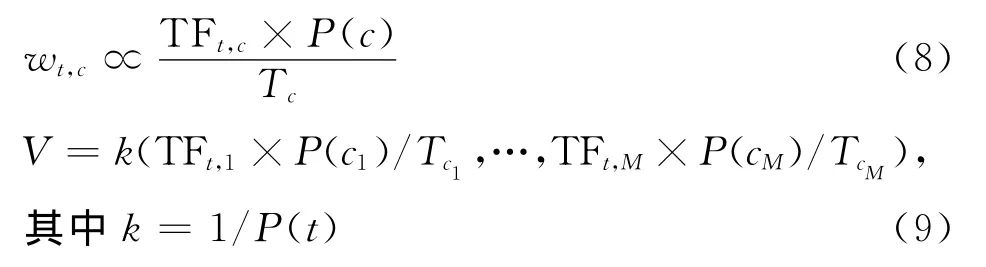
TFt,c以及Tc通过对中文维基百科数据进行分词以及词频统计便可得到,因此为了得到词t与概念c的相关程度wt,c,只需对先验概率P(c)进行估计。比较式(5)和式(9),基本的TFIDF方法,等价于取c的先验概率正比于词条数目的模型。然而,仅使用文档词条数目作为文档先验概率的估计因子有失偏颇,本文提出以下方法对页面(概念)的先验概率进行估计。
4.1 NORM_TF方法
对P(c)进行估计最简单的方法便是,所有概念c出现的概率相同。即对于任意的c,P(c)是一个定值(此处取为1/M)。同样由于使用cosine方法比较词与词的概念向量,因此,词项t的概念向量V可以简单记为:

该向量与TFIDF基本方法得到的概念向量差别在于,它对词项频率(TF)进行了归一化。为了表述的方便,将此方法记为NORM_TF。
4.2 INLK方法
前文提及在进行Wikiprep处理的同时得到了页面之间的链接信息。维基百科页面之间的链接与普通网页链接有所不同。普通网页链出的数目较少,而维基百科页面的链出很多。维基百科的链接是这样生成的:如果在一个页面中出现了某个词(或词组),而这个词(或词组)正好又是维基百科的一个词条,那么该页面就有一条指向词条对应页面的链接。如页面“阿波罗计划”中出现了词‘苏联’,而锚文本“苏联”又正好是维基百科的一个词条,对应了维基百科的一个页面,因此从页面“阿波罗计划”到页面“苏联”有一条链接。
由于维基百科页面的链接信息在一定程度上能够反映页面被访问的频率。考虑到维基百科链接构造的特殊性,可以认为越频繁出现的词条,其对应页面的入度越大,页面被访问的频率越高。基于这个假设,记页面(概念)c的入度为INLKc,则可以对P(c)进行估计。由于选取的概念入度差别非常大,因此直接使用入度进行计算会使得页面入度大的P(c)非常大,因此可以对入度采用取对数的方法,此时概念c的先验概率P(c)表示为:
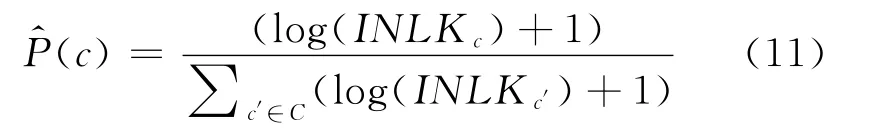
同样,为了便于表述,将此方法记为INLK.
4.3 PRANK方法
既然提及页面之间的链接,自然就会想到PageRank[19]。记网页数量为K,根据 Web图的邻接矩阵A(K×K),并记A第i行1的个数为Ni,可以推导出该马尔科夫链的概率转移矩阵P(K×K):

对中文维基百科的概念使用上述方法(取α=0.1),可以得到各个概念被访问的频率,使用它对P(c)进行估计。与INLK方法一样vc的差距很大,但不能像INLK方法那样先取对数再加1,因为直接取对数得到的是负值。于是将vc乘以10 M(M为选取的概念的个数),使得其值大于等于1。再对该结果取对数加1。P(c)的估计值为(将此方法记为PRANK)如式(13)所示。
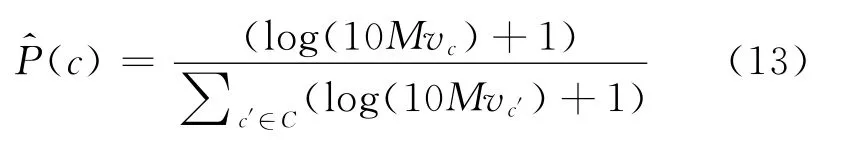
4.4 TDF方法
维基百科词条有着对其页面内容的充分概括性,页面内容都是对该词条的阐述。因此可以使用页面的标题在整个数据集中出现的频率(CF)或者文档频率(DF)来度量概念的先验概率P(c),使用TCF表示概念标题(词条)的CF,TDF表示概念标题的DF,并采用对数平滑方法,则对P(c)的估计分别为式(14)和式(15)。同样为了表述方便,将两种对估计P(c)计算词与词之间相似度的方法分别记为TCF,TDF。
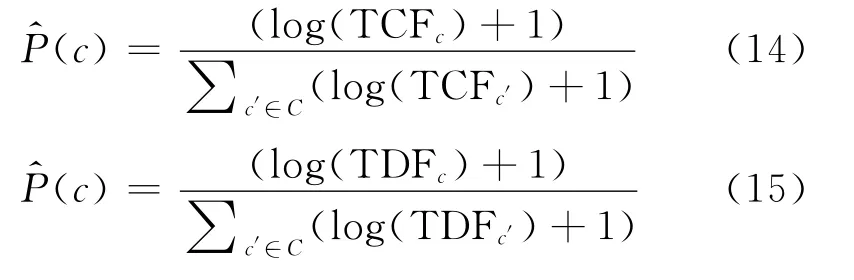
4.5 COMB方法
前文已使用了多种方法对P(c)的值进行估计,如INLK,TDF等。考虑到他们的组合实在是太多,但都是基于维基百科链接或者维基百科页面的标题,因此仅仅选取他们两两组合中的其中一种,即TDF+PRANK(记为COMB),前者基于标题词频,后者基于链接,并且使用最简单的线性组合的方式将两者对概念的先验概率的估计加以组合,即式(16)所示。
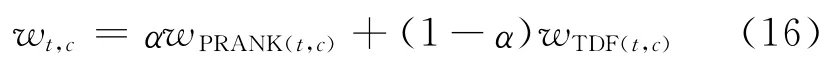
其中,wPRANK(t,c)以及wTDF(t,c)分别表示使用PRANK和TDF方法得到的权重。
5 评测
5.1 概念选取
从中文维基百科网站(http://zh.wikipedia.org/)下载中文版维基百科的XML转储数据 (zhwiki-20101029-pages-meta-current.xml.bz2),数据解压后使用 Wikiprep①从 http://search.cpan.org/~triddle/Parse-MediaWiki-Dump-1.0.4下载。原始代码用于处理英文维基百科数据,修改部分代码之后即可用于处理中文维基百科的数据。处理,去掉模板页面、重定向页面、类别页面等以及页面中无关的域(仅保留页面标题、页面ID以及文本域)。进行Wikiprep处理的同时会得到页面的链接信息以及类别信息等。由于中文维基百科页面中包含简体和繁体中文,我们使用中文繁简转换工具,统一将所有的繁体字转换为简体字。得到1G的文本文件,共有324 216个页面。
有些中文维基百科页面的正文太短,包含的信息量很少,编辑的内容质量不高。如果将所有的页面都作为最终的概念,那么得到的词的概念向量的维度很大,在很多维度上噪音很大,对词相关度的计算造成不利的影响。因此需要在这些页面中选出一个子集C作为最终概念集合。由于页面入度和词数在一定程度上能够反映页面的质量,因此在实验中去掉了入度过小(小于3)或者词数过少(少于70)的页面,剩下的页面(127 936个)即作为最终的概念集合C,用于词语之间相关度的计算。
为了统计页面的词条数,本实验使用了中文停用词表①总共有 1 208 个停用词,可从 http://www.hicode.cn/download/view-software-13784.html下载,对概念集合C中所有的页面进行自动分词。维基百科页面标题通常是人名、地名、专有名词等,因此为了将它们作为一个词(或词组)保留下来,实验时将页面标题作为一个词条。由于这些词条数目众多,不可能人工对其进行词性标注,而缺少词性标注会对分词结果造成影响。为了降低这种不良影响,采取了以下措施:首先使用中文分词器②中国科学院计算技术研究所开发的ICTCLAS汉语分词系统,http://ictclas.org/ictclas_download.aspx下载对这些词条进行分词,将分词器不能识别的词条(分词器会将其切分开)加入到用户词典,再次使用分词器对维基百科数据进行分词。对概念集合进行解析,统计词条(token)数目Tc的同时,得到了以下数据:(1)词汇表L;(2)词项t在多少个概念中出现DFt;(3)词项t在概念c中出现的频次 TFt,c;(4)词项t在所有概念中出现的频次CFt。
5.2 评测数据
本实验的评测数据基于英文 WordSimilarity-353数据集,这是英语语义相似度研究中广泛应用的一个评测标准。根据 WordSimilarity-353③http://www.cs.technion.ac.il/~gabr/resources/data/wordsim353/得到中文词相关度测试的数据集(为了便于表述,将此数据集记为ZH-SIM-353),具体做法如下。
首先,两个计算语言学研究生独立地对数据集WordSimilarity-353进行人工翻译,将英语单词对翻译为汉语词语对,然后让第三者对前两者翻译不一致的词对进行修改。只有当词对中的两个词都翻译得完全相同时才称为一致。WordSimilarity-353总共有353个词对,其中两人翻译一致的词对数为169,占总数的48%。两人翻译不一致时,再进行如下处理。
1.单字词和双字词。两个翻译者在单字词和双字词的使用上显现出差异,如表1所示。解决方法:让翻译结果音节一致;不一致时,倾向于双音节。例如,在表1中,得到的翻译正确结果为{<虎,猫>,<老虎,老虎>,<药物,滥用>}。
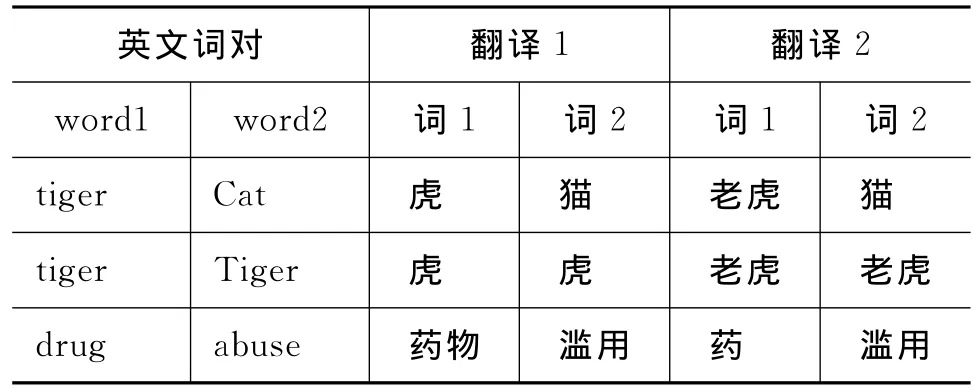
表1 单字词VS双字词
2.别名的使用。例如,potato一者翻译为“土豆”,另一者翻译为“马铃薯”。解决方法:使用更通用的称说,此处选择“土豆”作为potato的中文翻译。
3.去掉翻译为汉语时有明显歧义的5个词对,它们分别是<stock,egg>,<stock,live>,<brother,monk>,<crane,implement>以及<life,term>。将剩下的348个中文词对以及它们的得分,作为最终的评测集。
5.3 评测指标
本实验采用斯皮尔曼等级相关系数对目标词对的相关度计算的结果与人工标注评测集ZH-SIM-353的一致性进行评价。斯皮尔曼等级相关系数是反映两组变量之间联系的密切程度,它和相关系数r一样,取值在-1到+1之间。斯皮尔曼等级相关系数的计算公式如式(17)所示。

其中n为样本容量,RX为变量X的等级数,RY为变量Y的等级数。
6 实验结果与分析
6.1 相关性系数
使用各种向量的权值计算方法对目标词对之间的相关度进行计算,然后按照相关度值降序排列得到词对的等级数,其结果与人工判断标准的斯皮尔曼等级相关系数见表2。
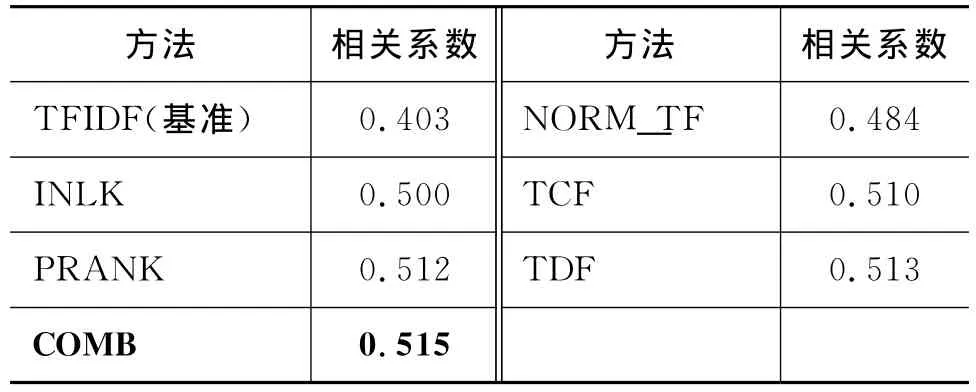
表2 不同方法的斯皮尔曼等级相关系数
从表2中可以看出,本文提出的改进方法NORM_TF,INLK,PRANK、TCF,TDF以及集成方法COMB均比基本方法TFIDF有显著提高。即对词与词之间相关性的度量与人工判定的结果更一致,在评测集 ZH-SIM-353上明显优于基本方法——TFIDF方法。结果表明:明确地引入概念(页面)的先验概率,利用维基百科页面链接信息,修正词向量元素的值可以提高相关度计算的结果。
6.2 概念数量的影响
前文已经提到由于有些页面正文太短,页面的质量可能较低,重要性不够,有些页面的入度很小,即没有指向它的链接或指向它的链接很少,因此在实验中去掉了入度过小或者词数过少的页面,将剩余的页面作为最终的概念。我们探究了作为概念的页面入度的下界a,以及词数的下界b对计算词—词之间的相关度的影响。
为了选择较好的概念集合,采用实验结果较好的PRANK方法和TDF方法,对参数a以及b进行调节。不同a,b对应不同的概念集合,采用不同的概念集合计算词与词之间的相关度的结果会有所不同,表3列出了概念数目以及实验结果的斯皮尔曼等级相关系数随a,b变化的情况。为了更好地观察实验结果随a,b变化的趋势将上表转化为曲线图,如图1所示(其中实线和虚线分别代表采用PRANK方法和TDF方法对目标词对的相关度计算结果与ZH-SIM-353人工标注结果的斯皮尔曼等级相关系数的变化)。

表3 概念的选取
从图1可以看出,当a,b变化时,目标词对相关性计算的结果也随着变化,但是结果与ZH-SIM-353的一致程度并没多大变化,仅仅有细微的波动。因此在一定范围内a,b的取值对相关度计算的结果几乎没有影响。TDF和PRANK方法对概念集合的选取具有较强的鲁棒性。
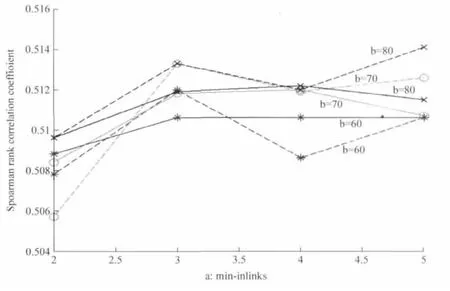
图1 概念集合对结果的影响
从表3可以看出,当<a,b>=<2,50>时概念数量比a,b取其他值时多,但是相关度计算的结果却比其他很多时候都差一点,这说明并不是概念的数量越多越好,当然也不是越少越好(从<a,b>=<4,70>以及<a,b>=<5,80>可以看出)。在a,b变化时,两种方法计算相关性的结果仍然非常接近,可以说明两者在对概念(concept)的先验概率的估计上是比较一致的。这种一致性很大程度上是由中文维基百科页面之间链接的特殊性决定的。
6.3 集成方法中参数的选择
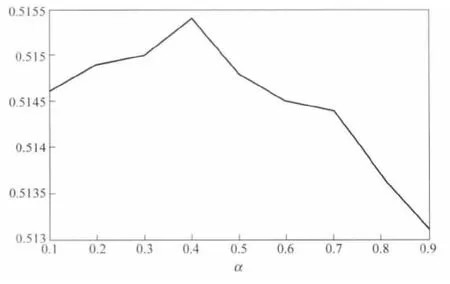
图2 组合方法参数选取
为了探究COMB方法中参数α的取值变化对词-词相关度计算实验结果的影响,我们针对不同的参数α,得到目标词对相关度与人工标注的ZHSIM-353数据的斯皮尔曼等级相关系数(图2)。
从图2可以看出参数α的变化会使得实验结果的斯皮尔曼等级相关系数有些微的变化,当α取0.4时,在测试集ZH-SIM-353上表现得最好。但是随着参数α的变化,实验结果并没有显著的变化,斯皮尔曼等级相关系数波动幅度非常小(不到0.003),这也说明了TDF方法和PRANK方法对概念c的先验概率P(c)的估计很一致,两种方法计算词与词之间的相关度的结果也比较一致。
7 结语
本文研究采用显性语义分析方法,基于中文维基百科实现了汉语词与词之间的相关度计算。基本方法是,将词表示为带权重的由中文维基百科文章定义的概念向量,将词之间的相关度计算转化为比较相应的概念向量,然后,使用余弦方法比较两个向量,得到词之间的相关度。本文改进方法中,利用概率模型,引入概念的先验概率,利用维基百科文章标题的文档频率、文档集频率以及页面之间的链接结构信息对概念的先验概率进行估计。实验结果表明,本文的改进方法显著提高了相关度计算性能,斯皮尔曼等级相关系数从0.40提高到0.52。文章进一步比较分析了各种方法的特点,并指出在一定范围内,概念集合的选取对词语之间相关度计算结果的影响甚小,组合方法参数的选取对相关度计算的结果也几乎没有影响,我们提出的改进方法具有较强的鲁棒性。
本文研究的测试集是从英文测试集翻译而来。然而,中英文词之间并没有一一对应的关系。为了检验本文提出的改进方法是否与本研究采用的测试集有关,它是否也同样适用于英文,未来的工作有两个方面:其一,在其他的中文相关度测试集上对本文的方法进行测试,观察评测结果是否与本文的结果一致;其二,使用英文维基百科在英文的测试集上检验该改进方法是否同样适合于英文。
[1]Finkelstein L,E Gabrilovich,Y Matias,et al.Placing search in context:The concept revisited[J].ACM Transactions on Information Systems,2002,20(1):116-131.
[2]Patwardhan S,S Banerjee&T.Pedersen.SenseRelate:TargetWord-Ageneralized framework for word sense disambiguation [C]//Proceeding of AAAI-05,2005.
[3]Budanitsky,A.& G.Hirst.Evaluating WordNet-based Measures of Lexical Semantic Relatedness[J].Computational Linguistics,2006,32(1):13-47.
[4]Gabrilovich E,S Markovitch.Computing semantic relatedness using Wikipedia-based explicit semantic analysis[C]//Proceedings of IJCAI,2007:1606-1611.
[5]石静,吴云芳,邱立坤,等.基于大规模语料库的汉语词义相似度计算方法[J].中文信息学报,2012(1):1-6.
[6]孙琛琛,申德荣,等.WSR:一种基于维基百科结构信息的语义关联度计算算法[J].计算机学报,2012(11):2361-2370.
[7]李赟,黄开妍,等.维基百科的中文语义相关词获取及相关度分析计算[J].北京邮电大学学报,2009(3):109-112.
[8]Fellbaum,Christiane(editor).WordNet:An Electronic Lexical Database[M].Cambridge,Massachusetts:MIT Press,1998.
[9]R.Rada,H.Mili,E.Bicknell,M.Blettner.Development and Application of aMetric on Semantic Nets[J].IEEE Transactions on Systems,Man,and Cybernetics,January/February 1989,19,1,17-30.
[10]R.Richardson,A.Smeaton,J.Murphy.Using WordNet as a KnowledgeBase for Measuring Semantic Similarity BetweenWords[R].Technical Report-Working paper CA-1294,School of Computer Applications,Dublin City University,Dublin,Ireland,1994.
[11]O.Resnik.Semantic Similarity in a Taxonomy:An Information-Based Measureand its Application to Problems of Ambiguity and Natural Language [J].Journal of Artificial Intelligence Research,11:95-130,1999.
[12]D.Lin.Principle-Based Parsing Without Over generation[C]//Proceedings of the31st Annual Meeting of the Association for Computational Linguistics(ACL'93):112-120,Columbus,Ohio,1993.
[13]A.Tversky.Features of Similarity[M].Psychological Review,84(4):327-352,1977.
[14]M.A.Rodriguez and M.J.Egenhofer.Determining Semantic Similarity AmongEntity Classes from Different Ontologies[J].IEEE Transactions on Knowledge andData Engineering,15(2):442-456,March/April 2003.
[15]Michael Strube,Simon Paolo Ponzetto.WikiRelate!Computing semantic relatedness using Wikipedia[C]//Proceedings of AAAI'06:1419-1224,Boston,MA,2006.
[16]Zesch,T.,M ller,C.,Gurevych,I.:Using Wiktionary for Computing Semantic Relatedness [C]//Proceedings of the Twenty-Third AAAI Conference on Artificial Intelligence,AAAI 2008,Chicago,Illinois,USA,pp.861 867(2008).
[17]D.Bollegala,Y.Matsuo,M.Ishizuka.Measuring semantic similarity between words using Web search engines[C]//Proceedings of WWW,2007.
[18]TorstenZesch,IrynaGurevych, Max Muhlhauser.2007b.Comparing Wikipedia and German Wordnet by Evaluating Semantic Relatedness on MultipleDatasets[C]//Proceedings of NAACL-HLT.Rochester,New York:205-208.
[19]L.Page,S.Brin,R.Motwani,T.Winograd,The-PRANK Citation Ranking:Bringing Order to the Web[C]//Proceedings of Stanford Digital Libraries Working Paper,199.
猜你喜欢
保健医苑(2022年1期)2022-08-30
英语文摘(2021年8期)2021-11-02
动漫界·幼教365(中班)(2021年4期)2021-05-23
电脑爱好者(2020年17期)2020-09-14
电脑知识与技术·经验技巧(2020年3期)2020-05-07
读者·原创版(2015年11期)2015-03-01
意林(2014年2期)2014-02-11
互联网天地(2012年12期)2012-11-18
