
K-means算法研究
2014-03-26 07:32胡朝清
长春工业大学学报 2014年2期
胡朝清
(德宏师范高等专科学校,云南德宏 678400)
1 应用程序设计
K-means算法首先接受输入量k;然后将n个数据对象划分为k个聚类,以便使得所获得的聚类满足:同一聚类中的对象相似度较高;而不同聚类中的对象相似度较小。聚类相似度是利用各聚类中对象的均值所获得一个“中心对象”(引力中心)来进行计算的[1]。依据K-means聚类的原理,在做应用程序设计时,一般将程序分为主程序、命令行解析模块、数据文件读取模块和聚类分析模块4大部分,各部分关系如图1所示。
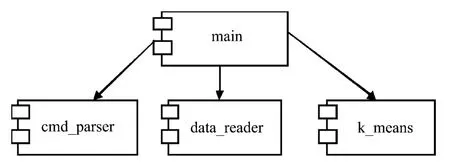
图1 程序构件图
主程序通过命令行解析模块获取用户输入参数,创建聚类分析模块和数据读取模块,通过数据读取模块将输入文件读取到聚类分析模块中,然后调用聚类分析模块将数据进行分类并直接输出。
1.1 命令行解析模块(cmd_parser)
命令行解析模块为程序实现一个简单易用且功能强大的用户交互界面,通过命令行的方式获取用户需要的参数,包括数据文件路径、数据集名称所在列、将数据集分割成为聚类的个数、判断浮点数是互相等的阈值等[2]。使用命令行作为交互界面不仅使用方便,而且便于通过脚本实现自动货批量处理,为该程序与其它程序整合和集成提供了方便。该模块通过调用GNU getopt模块实现命令行的解析,接受以下参数:

1.2 数据文件读取模块(data_reader)
由于在数据挖掘和数据分析中,经常需要进行数据读取操作,因此为了让程序能够尽量通用,方便以后的扩展,组织文件读取模块和数据分析模块,其使用方式如图2所示。
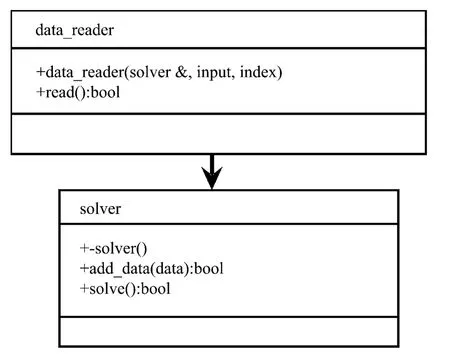
图2 通用的数据读取框架
在此,将数据分析模块定义为一个抽象类solver,提供add_data和solve两个抽象方法。当数据读取模块成功地从输入流中获取一行数据时,调用solver的add_data方法,将数据添加到solver的sovle方法对数据进行处理。当使用不同的算法分析数据时,只需要继承solver类,在子类中实现自己的solve方法即可,无须再考虑数据读取和文件格式解析的问题。
1.3 聚类分析模块(k_means)[3-4]
数据读取完毕后,程序通过k_means类对数据进行处理。k_means类继承自solver类,将解题过程分为“初始化”、“迭代计算”和“输出结果”3个步骤进行,如图3所示。
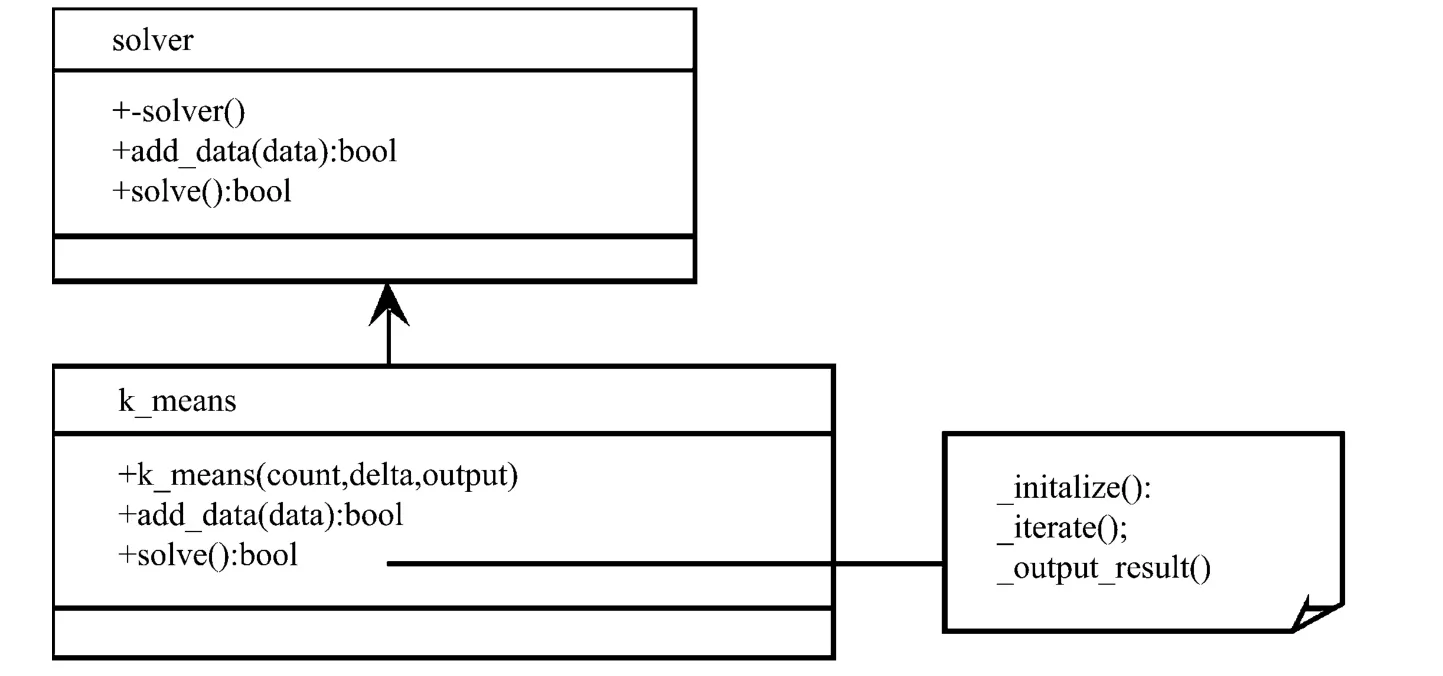
图3 K-means算法实现类图
2 算法实现[5-6]
程序主要基于STL来实现,下面分别从数据结构和算法实现两方面进行分析。
2.1 数据结构
在输入数据上使用一个vector保存,每个元素为一个结构体,包括元组名称和数据两部分,如图4所示。
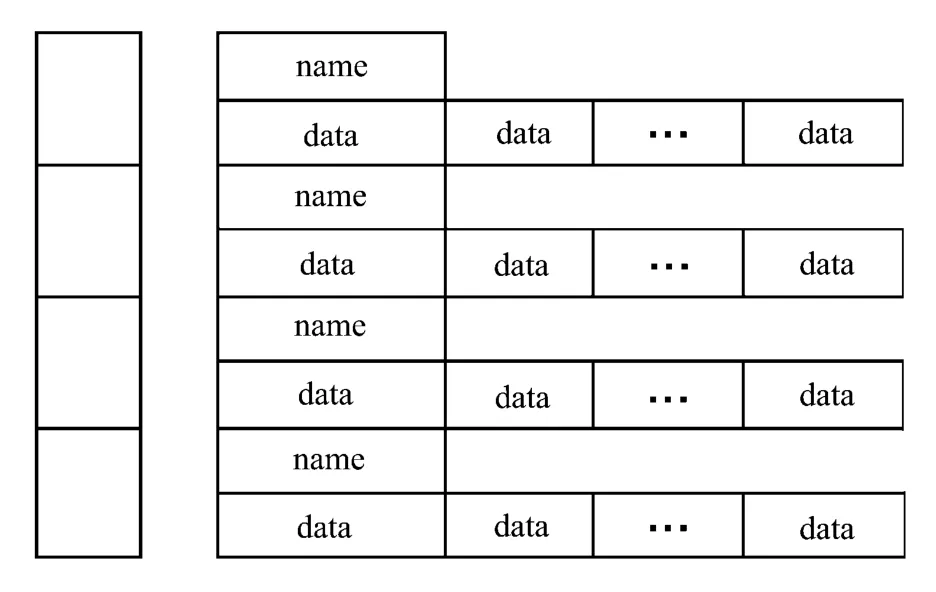
图4 输入数据存储
虽然在迭代过程中只对数据集进行顺序操作,不进行随机访问,但使用list会造成读取效率降低。虽然vector在初始化数据集的时候空间增长时有一些额外开销,但读取完毕之后就不再存在这样的内存占用,因此是比较值得的。而读取完毕后就不再对该数据进行任何写操作,因此,也不必考虑vector的内存失效问题。
由于聚类中心数据量不大,在聚类过程中又需要频繁读写,因此使用vector保存数据。聚类中心结构保存如图5所示。

图5 聚类中心位置
聚类结果仅进行“尾部添加”操作,无须随机访问,似乎比较适合使用list。但是由于每次迭代完毕后,都需要将结果集清空重新进行下一轮迭代,而list的销毁需要消耗线性时间复杂度,因此,仍然使用vector保存聚类结果,如图6所示。
图6 聚类结果
虽然vector在增长过程中可能会消耗一些额外时间,但由于每轮迭代后并不释放vector占用的空间,这类额外开锁会非常小,可以忽略不计。
2.2 算法实现
程序初始化时,在聚类中心数组中填充数据集中的前n组数据,然后开始迭代:将数据集中的每个数据与聚类中心点的距离进行比较,将数据焦距的数据添加到与之最近的中心点所对应的结果集里,在添加过程中直接累加各结果集的向量和,为一次迭代完成后重新计算聚类中心提供方便,提高程序运行的效率。当一次迭代和前一次迭代之间聚类中心没有再移动时,认为迭代已经完成,进入输入聚类结果阶段[7-8]。
3 实验结果
测试数据集在不同聚类数目下的聚类结果正确率如图7所示。
3.1 iris.data
该数据集中包含3种数据,一共4维。从图7中可以看出,当聚类个数小于3时,聚类正确类较低,当聚类个数大于等于数据集中包含数据类型时,聚类正确率较高。
3.2 wine.data
该数据焦距包含3种数据,一共13维。从图7中可以看出,当聚类个数小于3时,聚类正确类较低,当聚类个数大于等于数据集中包含数据类型时,聚类正确率较高。
3.3 glass.data
该数据集中包含6种数据,一共9维。从图7中可以看出,当聚类个数小于6时,聚类正确率较低,当聚类个数大于等于数据集中包含数据类型时,聚类正确率较高。
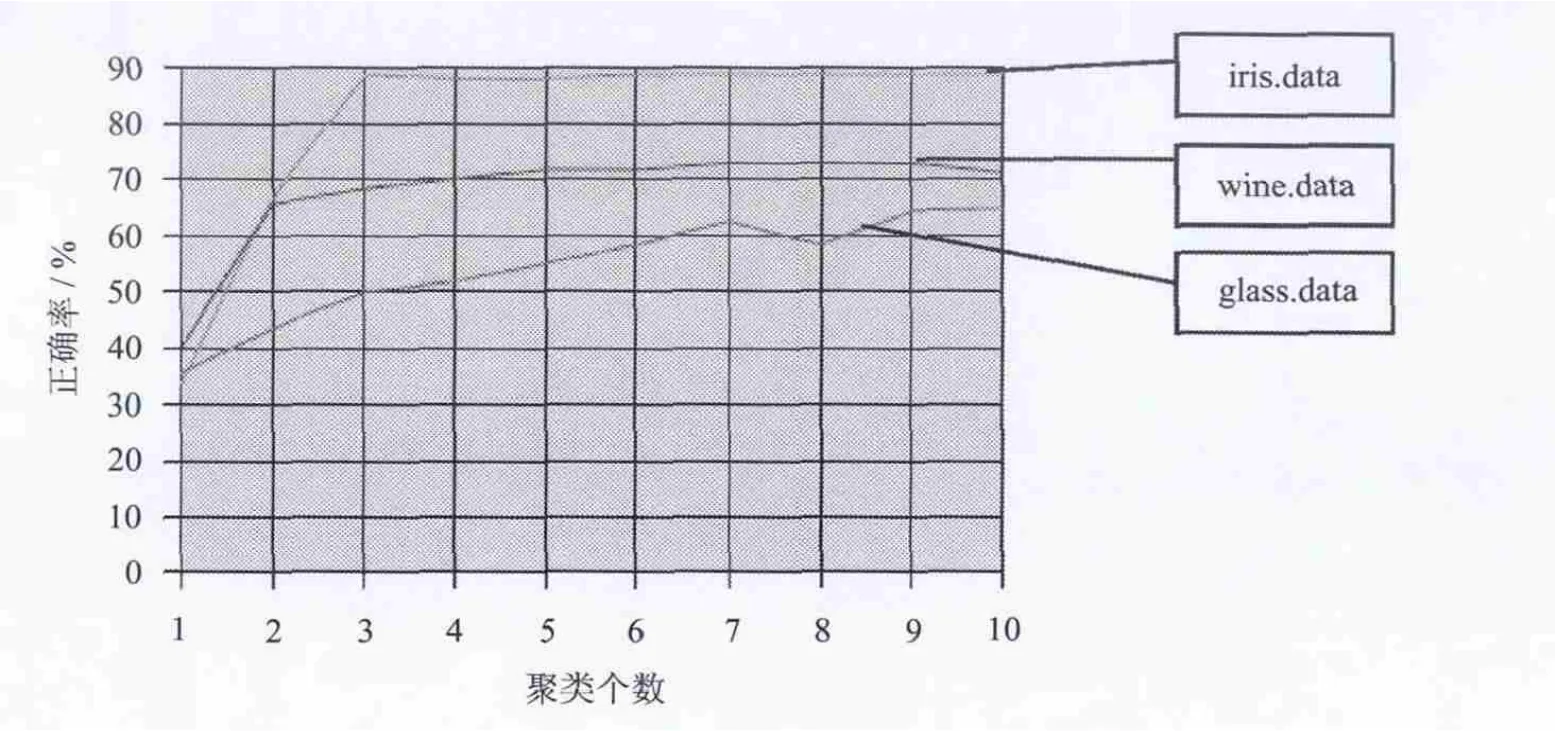
图7 聚类结果正确率分析
4 实验分析
4.1 初始数据点对聚类的影响
当数据集各类型数据之间距离比较远,而聚类内部距离比较近时,如果聚类个数与类型数相符时,聚类初始数据点不会影响到聚类结果。如果聚类个数与类型数不等时,初始数据点会影响到聚类结果。如果数据集各类型数据之间不能保持相对聚集的特性时,聚类结果对初始数据点位置高度敏感。
4.2 如何确定类别个数
通过测定每一个聚类的边界,然后计算每个聚类之间边界的距离。如果类别个数增加到一定数量后,继续增加时,没有出现两个距离较远的聚类,而是出现两个紧贴的聚类时,说明聚类个数已经大于类别个数,通过这样的方式可以判断出应该划分的类别个数。
4.3 递增式聚类
当把新的数据点加入已经聚合好的聚类时,可以直接使用迭代算法重新调整聚类划分。由于绝大部分点在这个过程中都不会出现大范围调整,因此可以在比较小的运算量下完成该计算。
[1] 吴夙慧,成颖,郑彦宁,等.K-means算法研究综述[J].现代图书情报技术,2011(5):28-35.
[2] 冯超.K-means聚类算法的研究[D]:[硕士学位论文].大连:大连理工大学,2007.
[3] 周爱武,于亚飞.K-means聚类算法的研究[J].计算机技术与发展,2011(2):62-65.
[4] 吴夙慧,成颖,郑彦宁,等.文本聚类中文本表示和相似度计算研究综述[J].情报科学,2012,30(4):623-627.
[5] 周丽娟.改进粒子群算法和蚁群算法混合应用于文本聚类[J].长春工业大学学报:自然科学版,2009,30(3):341-346.
[6] 袁方,周志勇,宋鑫.初始聚类中心优化的K-means算法[J].计算机工程,2007,33(3):65-66.
[7] 李钰,孟祥萍.基于Gabor滤波器的图像纹理特征提[J].长春工业大学学报:自然科学版,2008,29(1):78-81.
[8] 石云平.聚类K-means算法的应用研究[J].国外电子测量技术,2009,29(8):28-31.
猜你喜欢
小学生学习指导(低年级)(2021年9期)2021-10-14
中学生数理化·高一版(2021年4期)2021-07-19
中华养生保健(2020年7期)2020-11-16
中学生数理化·七年级数学人教版(2019年10期)2019-11-25
小学生学习指导(低年级)(2019年9期)2019-09-25
小学生学习指导(低年级)(2018年9期)2018-09-26
语文世界(小学版)(2018年3期)2018-03-22
商周刊(2017年12期)2017-06-22
家教世界·创新阅读(2016年11期)2016-12-27
福建中学数学(2016年7期)2016-12-03
