
一种基于线网划分的并行FPGA布线算法
2014-06-02 06:43来金梅
计算机工程 2014年3期
朱 春,来金梅
一种基于线网划分的并行FPGA布线算法
朱 春,来金梅
(复旦大学专用集成电路与系统国家重点实验室,上海 201203)
针对在现场可编程门阵列(FPGA)软件系统中大规模电路设计布线时间较长的问题,提出一种基于线网引脚位置划分且具有平台独立性的多线程FPGA布线算法。对高扇出线网采用将单根线网拆分成子线网并同时布线的方法,对低扇出线网采用选择若干位置不相交叠的线网进行同时布线的方法,给出线网边界框图的数据结构来缩短选择若干低扇出线网的时间,采取负载平衡机制和同步措施,分别提高布线效率和保证布线结果的确定性。实验结果证明,在Intel 4核处理器平台上,与单线程VPR算法相比,该并行算法的平均布线效率提高了90%,平均布线质量下降不超过2.3%,并能够得到确定的布线结果,在EDA方面具有重要的理论与实用价值。
现场可编程门阵列;多线程;布线;高扇出线网;低扇出线网;边界框图;确定性
1 概述
由于集成电路工艺水平已进入纳米范畴以及可编程逻辑设计具有的高度灵活性,FPGA的容量和复杂度得以迅速提高以满足更广泛的应用需求。设计从行为级描述到最终的物理实现需要经历逻辑综合、映射、打包、布局、布线、位流生成以及编程下载等过程。应用于FPGA的大规模设计流程往往需要大量的时间,这其中布局布线占有相当的比例[1-2]。因此,提高编译效率、降低运行时间成为用户的迫切需求。另一方面,多核处理器已成为当代计算机的主流,为并行算法的研究提供了良好的基础和方向。
本文通过分析线网的引脚数量和位置信息来实现具有平台独立性的多线程布线算法。
2 相关背景
经典的单线程FPGA布线算法是基于拥挤度协商的算法,如PathFinder[3]、VPR(Versatile Place and Route)[4-5]、Directed A*[6]等。它们的执行效率按序逐步提高,然而单线程的特点使其均未充分利用多核处理器的潜在运算能力。文献[7]研究了FPGA并行布线算法,利用通过网络连接的分布式单核处理器作为实验平台,但没有同步处理器间的通信,导致每次运行中代价更新信号到达相应处理器的时间具有不确定性,每次运行的布线结果不相同,因此,不能够支持用户在软件平台上调试,无法应用于商业工具。基于多核处理器的多线程ASIC布线算法[8],对FPGA布线算法研究具有一定的指导意义,但是它并没有针对高扇出线网与低扇出线网分别进行处理,因为高扇出线网的布线时间过长一直是FPGA布线面临的难题。由于该算法是非迭代性算法,因此迭代性算法中降低线网选择时间的需求并不十分迫切。此外,ASIC算法应用于FPGA中的离散互联资源时无法解决收敛性问题。
文献[1]研究了基于现代多核处理器架构的并行布线算法,并分别提出了粗粒度与细粒度的2种方案。在粗粒度的方法中,线网集合被分配成若干子集,每个子集被分配给一个VPR实体[1]。在每个VPR实体内部线网按序进行布线,VPR实体之间的布线过程同时进行。一种称为work- counter的设计通过使用共享内存作为通信媒介来控制VPR实体之间的同步。此粗粒度方法使用多进程机制实现,在速度上取得了明显的改进,但进程间通信(Inter-process Communication, IPC)需要额外维护共享内存,系统的开销较大[9]。在细粒度方法中,布线算法中的波前扩展过程[10]被划分成若干个子过程,使用等量的线程承担单根线网布线中同一阶段的某一部分。细粒度方法在速度方面的改进收效甚微,且程序的性能取决于处理器中的存储架构。
本文提出的算法与文献[1]中的粗粒度算法相似,但存在以下2点不同:(1)根据线网的特征,即扇出数量,调整并行策略。高扇出线网与低扇出线网分别被分配到2个不同的子集,每个子集内线网布线的并行策略不同。因为在文献[1]中的粗粒度算法高扇出线网可能导致过长的等待时间,所以对高扇出线网进行特别处理以消除这种情况的发生;(2)使用多线程的方法,即线程间通信(Inter-thread Com- munication, ITC)的方式[9]。因为ITC的维护成本与系统开销相对于IPC轻得多。
文献[11]的实验结果表明:在VPR框架下,当高扇出线网的总数比率不到1%时,它们的布线时间占用约70%的总布线时间。巨大的线网边界框[9]和较多的待布线终端数是导致布线时间成指数时间增长的原因,其中,线网边界框指包含整个线网的最小矩形框。因此,有必要对高扇出线网和低扇出线网采用不同的布线策略。方法如下:
高扇出线网被分解成若干子线网,每个子线网具有较小的边界框和较少的终端数。通过平衡每个子线网的边界框面积与扇出数量的乘积来平衡线程间的负载,使得高扇出线网的布线时间降低为其中一个子线网的最大布线时间。子线网全部完成布线后,合并它们的布线结果作为此高扇出线网的布线结果。
低扇出线网本身的性质表明它们不适合被分割。通过计算布局后线网的位置判断2个低扇出线网的边界框是否有交叠。如果不交叠,这2根线网就可以同时进行布线。线网边界框图被设计用来简化选择低扇出线网的过程。
3 多线程布线算法
3.1 背景算法及多线程框架
使用VPR[5]中的布线算法作为基本算法。在基本串行算法中,线网按序依次进行布线,布线过程中允许线网之间桥接。在所有线网均完成初始布线后,每根线网的布线结果均为最佳方案。然后,桥接的布线资源节点面临拥挤代价惩罚[3-5],算法开始实施新一轮布线,布线过程中路径选择较多的线网会尽量避开拥挤的节点。重复如上步骤直到所有的桥接全部移除,这些工作全部由单一线程完成。在本文的算法中,线网的选择、划分、合并以及代价更新等工作由主线程完成,具体的布线工作由主线程和子线程共同完成。其中,主线程为整个布线程序的线程,子线程由主线程创建和回收。所有的子线程只被创建一次并在程序终结前由主线程回收。
为了避免线程间出现死锁或者数据竞争等情况,在每个子线程的地址空间中拷贝一份主线程的布线资源图[10]。主线程控制每份拷贝之间的信息同步以确保布线结果的确定性。POSIX线程[9]被用来搭建整个多线程的环境。使用Pthread barriers[12]来同步线程间的布线过程以及控制布线资源图中关于拥挤信息的更新。barrier是控制若干线程同步的机制,当预设数量的线程均到达相应的barrier时才可以越过它继续执行,否则所有的线程都要休眠等待。本文采用了2道barrier:第1道barrier告知所有线程工作已经由主线程分配完成,允许执行布线;第2道barrier告知主线程所有的布线工作已经完成,统一所有布线结果,进行代价更新,重新为所有线程分配布线工作。显然,当并行环境设定为线程时,程序中存在1个主线程和-1个子线程。
线程的工作模型为对等工作模型[9],即主线程给子线程分配好工作以后依然还要和子线程一起承担布线的工作。多线程框架如图1所示。从图中可知,需要采用必要的措施来保证各线程在2道barrier之间的工作时间相近,这样程序在第2道barrier处等待的时间就会很短。理论情况下时间相同,所有线程同时到达第2道barrier,等待时间为0,效率最高。
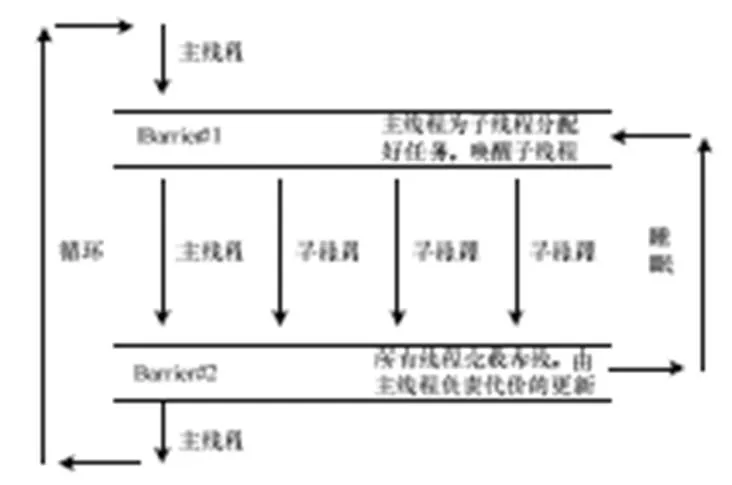
图1 对等线程模型及同步机制
3.2 高扇出线网并行算法
由于高扇出线网的布线任务被分解成若干子线网的布线,因此任意子线网都需要一份线网源端的拷贝,即所有子线网的数据结构中都存有相同的源端。另一方面,在VPR布线算法中,线网的边界框具有限制布线器搜索路径的范围以及节省布线资源的作用。为了不让任意2个子线网间的布线搜索工作存在重复,它们的线网边界框应不发生交叠。因此,本文以源端为基准对高扇出线网进行切割。具体的分割策略如图2所示。在VPR算法中影响布线时间的2个重要指标为:线网边界框的大小和终端数量[4]。边界框越大,布线时间越长;终端数量越多,布线时间越长。为了平衡线程的负载,给任意线网定义一个特征值=×,其中,代表子线网的终端数量;代表其边界框的面积;当一根线网的所有子线网间的值相近时,线程的布线时间相近,用于等待的时间就会缩短。在两线程环境下,线网按图2(a)和图2(b)的策略进行划分,为了保证程序加速性能的最大化即线程负载的平衡,需要对这2种策略进行一个选择。在每种策略下,定义:

其中,1和2指任意策略下分得的2根子线网的特征值。
分别计算2种策略的Delta值,选取具有较小Delta值的策略。在三线程和四线程的环境下,线网预先被分解成 4根子线网,如图2(c)~图2(f)所示。如果是四线程,即将这4根子线网分配给这4个线程。如果是三线程,需要将这4根子线网中的任意2根进行合并,合并的规则仍然是最终的任意2根线网边界框间没有交叠,这样就会出现 图2(c)~图2(f)所示的4种情况,需要选择其中一个作为最终方案。

图2 高扇出线网划分策略
对任意一种策略定义:
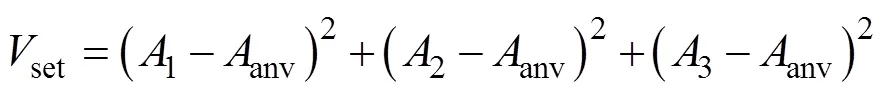
其中,anv指每种策略下所有子线网特征值的均值;set即代表所有子线网特征值的方差。选择具有最小set值的策略为最终结果。
所有高扇出线网在布线前进行有且仅有一次划分,在后续布线轮次中不会变更。它们在集合中按网表读入时的顺序存储,布线过程中不发生改变。布线流程如图3所示。

图3 高扇出线网布线流程
首先按序获取一根线网,清空上一轮的布线结果后更新所有布线资源图的拥挤代价,然后取出所有子线网按轮询策略[9]分配给所有线程的容器。当所有线程完成布线后,主线程合并布线结果并重新取下一根线网,子线程进入休眠状态等待被唤醒。
3.3 低扇出线网并行算法
低扇出线网的边界框规模要小很多,不适合分割。因此,如果2个低扇出线网在布局后的位置相距较远,如线网边界框没有发生交叠,就认为它们的布线过程不会产生布线资源的竞争,可以同时进行。
由于线网的数据结构中表征边界信息的是2个坐标:(min,min)和(max,max),计算2根线网边界框是否重叠需要对其中的2组坐标进行比较运算。假设计算任意2个线网边界框之间是否重叠的时间复杂度为(1),那么计算根线网中两两之间是否存在边界框重叠的时间复杂度即为(2)。每次从线网集合中选择根边界框互相不重叠的线网,最少需要(2)复杂度的时间,如设计中共存在根线网,那么一个布线轮次总耗费的时间复杂度为(/)×(2)。如果完成布线需要次布线迭代,选择线网时间最少为×(/)×(2)。
为了避免在每个布线轮次做重复性的选择工作,缩短选择的时间,提出线网边界框图的数据结构,使得低扇出线网的选择更加方便且高效。线网边界框图是无向图[13],图中节点代表线网,边代表2根线网的边界框发生交叠,如图4所示。
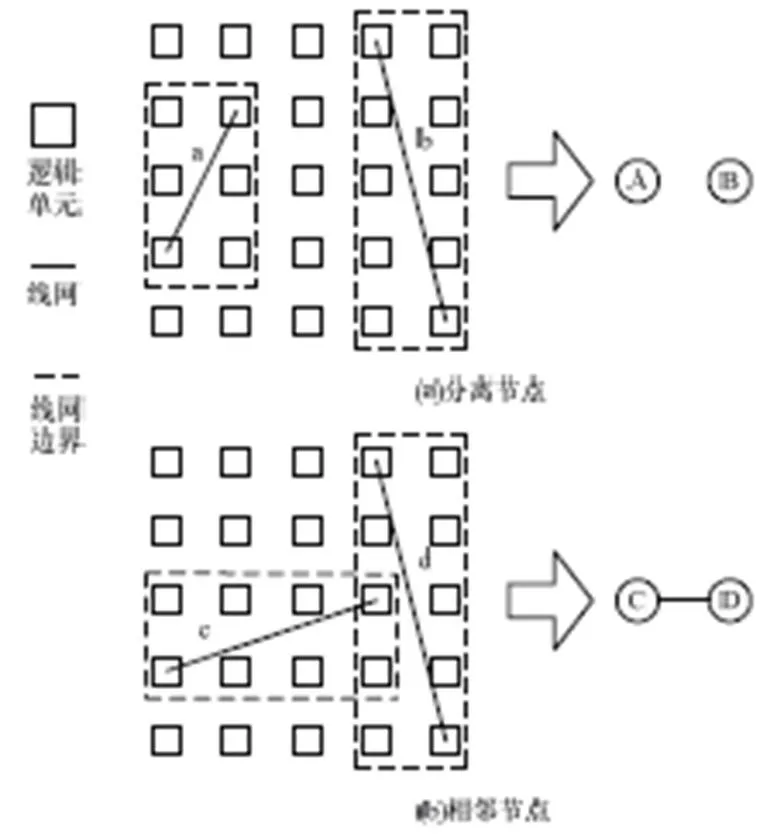
图4 线网边界框图
如果2根线网的边界框没有发生交叠,它们在图中对应的节点就是不相邻的,因而可以被选择来同时布线。终端数量多的线网往往边界框的面积较大,相邻的节点就越多,很难和其他线网同时被选中,这也是高扇出线网未采用这种方法的原因。在布线开始前,读入设计网表之后,程序有且仅有一次构建线网边界框图。为了尽量使规模相等或相近的线网能够优先被选择,对低扇出线网的集合做预处理。低扇出线网在集合中的初始存储顺序为网表读入时的顺序,在构建边界框图之前按照3.2节定义的特征值对线网在数据结构中的存储顺序进行从高到低的排序。本文分别对从高到低排序和从低到高排序进行实验,发现从高到低的排序比从低到高排序导致更短的运行时间和更好的布线质量。相应节点在边界框图中的存储顺序相同。规模相近的线网就会更容易在同一回合内被选中,线程间的负载就会因此得到平衡。另一方面,因为具有较高特征值的线网邻接点较多,它们被优先选择后图中剩余的连通分支[12]就会变多,搜索效率增高,进而提高速度。整个低扇出线网集合的布线流程如图5所示。初始布线轮次,如果为线程环境,每回合开始前主线程从边界框图中选择个互补相邻的节点,并将选中的节点打上标签。在本轮后续选择线网时,被打上标签的节点就会被过滤掉。根据选中的节点获取对应的线网分配给线程接口容器,线程接口容器为线程获取主线程为其分配线网的接口。当所有线程完成工作后主线程更新拥挤代价并检查收敛性。收敛性检查后主线程重复如上循环,子线程进入休眠状态等待被唤醒。初始布线轮次完成以后,在同一回合布线的线网被绑定为同一组并贴上组标签,在后续布线轮次中程序识别组标签而取线网,不要额外的计算或者比较,时间复杂度为(1)。

图5 低扇出线网布线流程
收敛性分析:由于物理上的一根互联线段的两端可能位于不同的线网边界框中,因此也不能完全保证2个边界框不交叠的线网在布线过程中没有资源竞争。内部实验证明,如果不采取措施解决此类问题,对某些测试用例来说程序可能无法结束,即算法不收敛。因此,为了解决收敛性问题,在每回合布线结束后分析所布的根线网之间有没有资源的冲突。如果某2根线网的布线结果存在资源冲突,即在边界框图中对应节点之间加上一条边使它们相邻,从而保证在以后的布线轮次中这2根线网不会在同一回合内布线。然后,撤销此组线网的组标签使它们处于自由状态。如果没有检测到收敛性问题,此回合内的线网依然会在下一个迭代轮次内同时布线。
在一轮布线完成后,程序将没有组标签的自由线网集中在一起,重新进行分组。这里没有组标签的线网来源包含以下2个方面:(1)在收敛性检测中被撤销组标签的线网,即具有资源冲突而不满足收敛性的线网;(2)初始轮次布线的最后几个回合中很难在边界框图中同时找到存在个互相不相邻且未参与布线的节点,这些节点在每轮布线后都参与重新分组。如果没有满足与线程数等数量的线网,多余的线程会空置并直接行进到第2道barrier。
3.4 算法实现
布线前,程序要做如下预处理工作。首先,解析硬件描述文件以构建布线资源图。其次,读入网表并依次计算线网的位置信息以及终端数量。根据终端数量将线网分为高扇出线网集合与低扇出线网集合。低扇出线网集合用作输入来构建线网边界框图。主线程创建-1个子线程,设定它们的竞争范围[9]为系统级并分别拷贝一份布线资源图。这样每个线程即为一个VPR实体,设定参数均相同。在每轮布线迭代中,所有的线网都要拆分重布而不只是布有冲突的线网以保证收敛性以及更良好的布线质量。低扇出线网集合优先于高扇出线网集合布线,实验证明这能达到更良好的布线质量。
4 实验结果与分析
4.1 实验平台
本文的实验基于以下2种平台:(1)Intel Core 2 Quad Q8400处理器,Windows XP系统,4 GB主存;(2)Intel Core i5-2400处理器,Windows 7系统,4 GB主存。测试电路选自于MCNC基准电路以及opencore平台上经过FPGA验证后的电路。打包和布局采用的工具是赛灵思(Xilinx) ISE 10.1,使用的FPGA架构为赛灵思XC2V500,重复单元内互联结构包含水平和竖直方向各40根两倍线、120根6倍线以及24根长线。打包后测试电路的资源情况如表1所示。其中,H-nets代表高扇出线网;L-nets代表低扇出线网。在本文中,如果一根线网的终端数量达到或者超过40[11],则将其定义为高扇出线网。

表1 测试电路资源情况
4.2 布线质量
为了比较布线质量,统计布线成功后总共实际使用的互联资源长度,即将电路中每根线网实际使用到的互联线段长度加总。因为一个最终的设计使用的互联资源总长度越少说明布线的质量越高,即布线在满足连通所有线网的前提下尽量节省资源的使用量。实验结果表明,在2种不同平台上得到的布线质量统计结果完全相同,而不同数量线程环境下的布线质量如表2所示。百分比的计算均基于均值。其中,对于特定数量的线程,所有的电路都经过至少5次的重复运行实验。结果表明,对特定电路,不同平台运行的结果均相同,进而表明了本文的算法具有平台独立性和确定性。从最后一行的结果看,布线质量恶化最高只有2.3%,属于设计可以接受的范围。
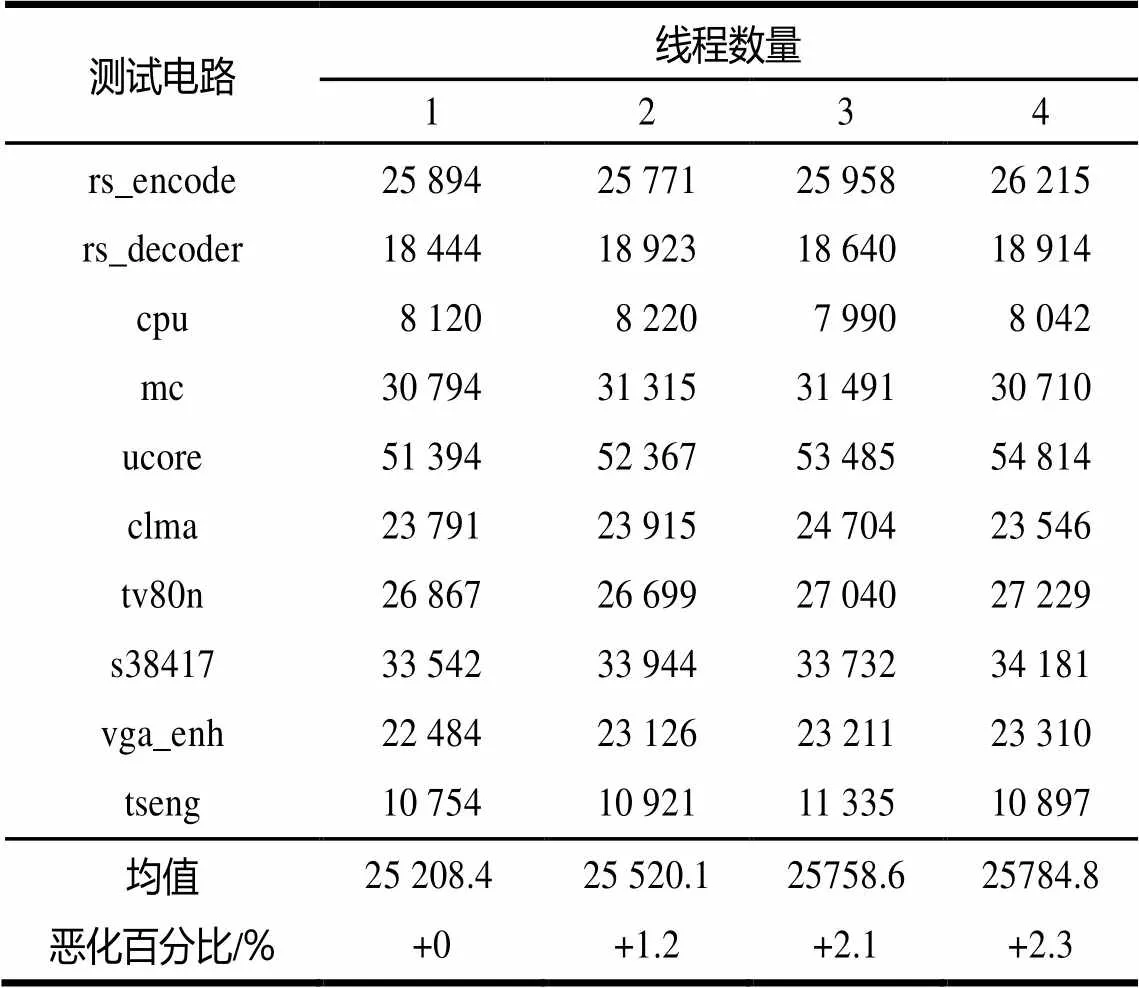
表2 2种平台的布线质量
4.3 布线时间
布线时间包括构建布线资源图、边界框图以及对所有线网进行布线的时间。对于所有的测试电路,不同平台以及不同数量的线程环境下的布线时间、平均值以及加速比如表3~表8所示。加速比的计算均基于均值。
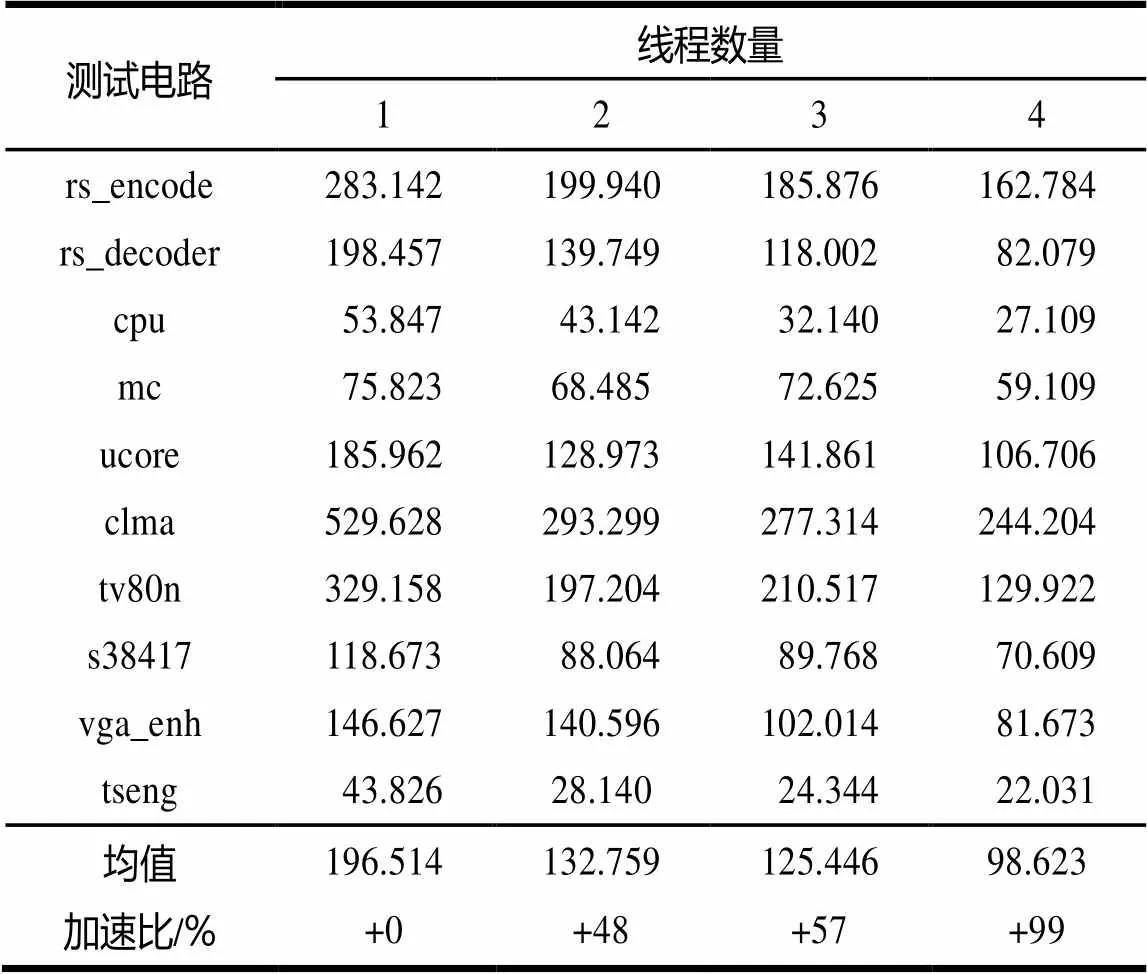
表3 Q8400平台高扇出线网布线时间 ms

表4 i5-2400平台高扇出线网布线时间 ms

表5 Q8400平台低扇出线网布线时间 ms

表6 i5-2400平台低扇出线网布线时间 ms
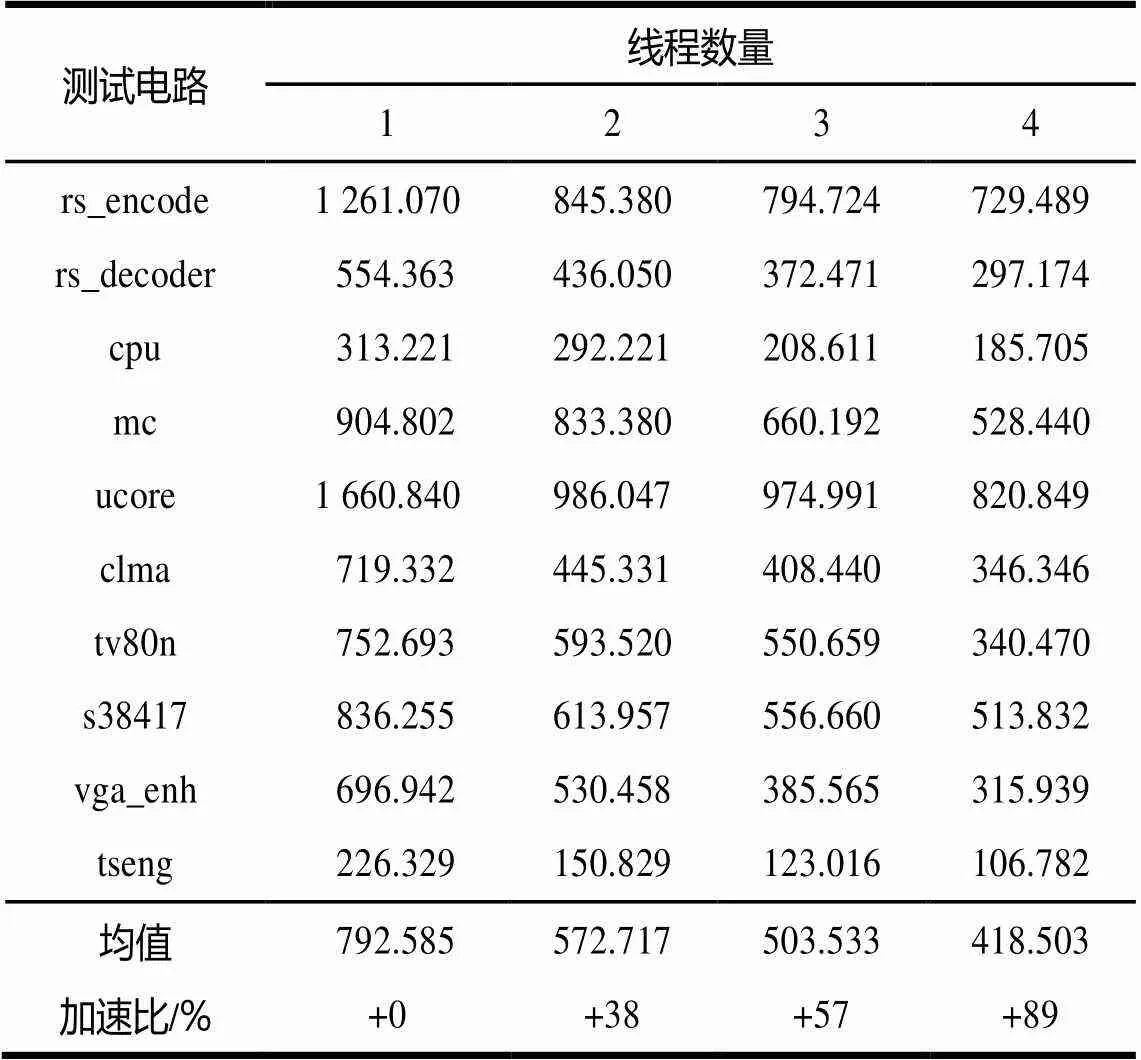
表7 Q8400平台总布线时间 ms

表8 i5-2400平台总布线时间 ms
表3、表4展示了算法对于高扇出线网集合的布线加速能力,表5、表6展示了算法对于低扇出线网集合的布线加速能力,表7、表8展示了算法对于整个线网集合的加速 能力。
通过观察表3、表4可以发现,2种平台在2~4线程环境下算法对于高扇出线网的布线加速百分比分别为48%、57%、99%以及55%、58%、100%。表5、表6表明, 2种平台在2~4线程环境下算法对于低扇出线网的布线加速百分比分别为35%、58%、86%以及52%、65%、88%。对于整个电路,表7、表8表明,2种平台在2~4线程环境下算法的布线加速百分比分别为38%、57%、89%以及53%、64%、91%。
通过对以上2组平台的测试数据观察得知,算法的加速百分比随着线程数量的增加而明显增加,因而算法具有良好的加速扩展性。2种平台实验数据相近,从另一方面说明了算法具有平台独立性。Intel Core i5-2400平台上的布线时间相对于Intel Core 2 Qaud平台较短是因为前者相对于后者的处理能力更高,它具有更高的时钟频率和更高级的缓存设计。计算表7、表8中同等数量线程下的加速百分比差值,2~4线程分别为15%、7%、2%,呈逐渐减小的趋势,预示算法的加速性能随着线程数量的增加会遇到瓶颈。
最后,将本文提出的算法与其他并行FPGA布线算法进行比较。文献[7]的研究成果显示出了良好的加速扩展性,但是该平台是基于网络连接的分布式处理器,而不是现代多核处理器。另一方面,该算法不保证结果的确定性。文献[1]第1个发布了基于现代多核处理器平台的FPGA并行布线算法研究,提出了粗粒度与细粒度2种方法,粗粒度方法具有良好的加速扩展性,而细粒度方法的加速扩展性较差且依赖于平台。粗粒度方法在2~4线程环境下的加速百分比为51%、64%、92%(Intel Core i5平台)和49%、72%、111%(Intel Core 2平台)。本文提出的算法与粗粒度算法的加速扩展性相近,但是子线程通过主线程的地址空间进行通信,无需维护共享内存的通信机制。此外,线程的上下文切换成本较进程的上下文切换成本较低[9],系统开销较小,具有较高的实用性。
5 结束语
本文提出了对FPGA布线进行加速的多线程布线算法,针对不同扇出类型的线网采用不同的并行策略。测试表明此算法具有良好的加速扩展性、平台独立性以及能够提供确定的布线结果,系统开销较小,与其他算法相比具有良好的实用性。在此基础上,将进一步开发基于时序驱动的并行布线算法,拟降低工业界比较常用的时序驱动布线时间较长的问题。
[1] Gort M, Anderson J H. Deterministic Multi-core Parallel Routing for FPGAs[C]//Proc. of International Conference on FieldProgrammable Technology. Toronto, Canada: ACM Press, 2010: 78-86.
[2] Betz V, Ludwin A, Padalia K. High-quality, Deterministic Parallel Placement for FPGAs on Commodity Hardware[C]// Proc. ofthe 16th International Symposium on Field Programmable Gate Arrays. New York, USA: ACM Press, 2008: 14-23.
[3] McMurchie L, Ebeling C. PathFinder: A Negotiation-based Performance-driven Router for FPGAs[C]//Proc. ofthe 3rd International Symposium on Field Programmable Gate Arrays.[S. l.]: IEEE Press, 1995: 111-117.
[4] Betz V, Rose J. VPR: A New Packing, Placement and Routing Tool for FPGA Research[C]//Proc. of the 7th InternationalWorkshop on FieldProgrammable Logic and Applications.London, UK: Springer-Verlag, 1997: 213-222.
[5] Luu J, Kuon I, Jamieson P, et al. VPR5.0: FPGA CAD and Architecture Exploration Tools with Single-driver Routing, Heterogeneity and Process Scaling[J]. ACM Transactions on Reconfigurable Technology and Systems, 2011, 4(4): 133-142.
[6] Tessier R. Negotiated A* Routing for FPGAs[C]//Proc. of the 5th Canadian Workshop on Field Programmable Devices. [S. l.]: IEEE Press, 1998: 139-144.
[7] Chan P, Schlag M. New Parallelization and Convergence Results for NC: A Negotiation-based FPGA Router[C]//Proc. ofthe 8th International Symposium on Field Programmable Gate Arrays. New York, USA: ACM Press, 2000: 165-174.
[8]Chiang C, Kawa J, Wen Y. Routing in Multithread Environ- ment[C]//Proc. of the 5th International Conference on ASIC. [S. l.]: IEEE Press, 2003: 203-207.
[9] Hughes C, Hughes T. Professional Multicore Programming: Design and Implementation for C++ Developers[M].[S. l.]: Wiley, 2008.
[10] Betz V,Rose J, Marquardt A. Architecture and CAD for Deep-submicron FPGAs[M]. Norwell, USA: Kluwer Academic Publishers, 1999.
[11] Chen Xun, Zhu Jianwen. Timing-driven Routing of High Fanout Nets[C]//Proc. of International Conference on Field Programmable Logic and Applications. [S. l.]: IEEE Press, 2011: 423-428.
[12]Lewi B, Berg D J. Pthreads Primer: A Guide to Multithreaded Programming[M]. [S. l.]: SunSoft Press, 1996.
[13]屈婉玲,耿素云,张立昂. 离散数学[M]. 北京:高等教育出版社, 2008.
编辑 顾逸斐
A Parallel FPGA Wiring Algorithm Based on Nets Partition
ZHU Chun, LAI Jin-mei
(State Key Laboratory of ASIC & System, Fudan University, Shanghai 201203, China)
A platform-independent multi-thread routing method for FPGA is proposed to reduce long compiling times of large design in Field Programmable Gate Array(FPGA) software system. Specifically, the proposed method includes two aspects for maximal paralleli- zation. For high fanout nets, each is partitioned into several subnets to be routed in parallel. Low fanout nets with non-overlapping boundary diagrams are identified and routed in parallel. A new graph, named boundary diagram, is constructed to facilitate the process of selecting low fanout nets to be routed concurrently. In addition, load balancing strategies and synchronization mechanisms are introduced to promote routing efficiency and ensure deterministic results. Experimental results on Intel quad-core processor platforms show that, this technique improves the average routing efficiency by 90% with routing quality degrading by no more than 2.3% and provides deterministic results, which has great theoretical and practical value in EDA field.
Field Programmable Gate Array(FPGA); multi-thread; wiring; high fanout nets; low fanout nets; boundary diagram; deterministic
1000-3428(2014)03-0287-07
A
TP301.6
国家“863”计划基金资助项目(2012AA012001)。
朱 春(1987-),男,硕士研究生,主研方向:FPGA布线算法;来金梅,教授、博士生导师。
2013-03-05
2013-03-28 E-mail:10212020063@fudan.edu.cn
10.3969/j.issn.1000-3428.2014.03.061
猜你喜欢
铁道通信信号(2020年5期)2020-09-21
汽车维修技师(2019年7期)2020-01-16
铁道通信信号(2019年12期)2019-05-21
铁道通信信号(2019年2期)2019-03-26
电子制作(2018年12期)2018-08-01
汽车维修技师(2018年11期)2018-05-11
中学生数理化·高一版(2017年1期)2017-04-25
新高考·高一物理(2014年4期)2014-09-17
都市快轨交通(2014年6期)2014-02-27
都市快轨交通(2014年3期)2014-02-27
