
一种Q学习的量子粒子群优化方法
2014-09-12 11:17盛歆漪孙俊周頔须文波
计算机工程与应用 2014年21期
盛歆漪,孙俊,周頔,须文波
1.江南大学数字媒体学院,江苏无锡 214021
2.江南大学物联网学院,江苏无锡 214021
一种Q学习的量子粒子群优化方法
盛歆漪1,孙俊2,周頔1,须文波2
1.江南大学数字媒体学院,江苏无锡 214021
2.江南大学物联网学院,江苏无锡 214021
分析了量子行为粒子群优化算法,着重研究了算法中的收缩扩张参数及其控制方法,针对不同的参数控制策略对算法性能的影响特点,提出将Q学习方法用于算法的参数控制策略,在算法搜索过程中能够自适应调整选择参数,提高算法的整体优化性能;并将改进后的Q学习量子粒子群算法与固定参数选择策略,线性下降参数控制策略和非线性下降参数控制策略方法通过CEC2005 benchmark测试函数进行了比较,对结果进行了分析。
粒子群算法;Q学习;参数选择;量子行为
粒子群优化算法(Particle Swarm Optimization,PSO)是Kennedy等人受鸟群觅食行为的启发,提出的一种群体优化算法[1]。自提出以来,PSO算法因其方法简单、收敛速度快得到了广泛的应用;但从算法本身来讲,PSO并不是一种全局优化算法[2],许多学者对此提出了许多改进方法,取得了一定的改进效果[3-4]。Sun等人在分析粒子群优化算法的基础上,深入研究了智能群体进化过程,将量子理论引入了PSO算法,提出了具有全局搜索能力的量子行为粒子群优化算法(Quantum-behaved Particle Swarm Optimization,QPSO)[5-6]。QPSO算法自提出以来,由于计算简单、编程易于实现、控制参数少等特点,引起了国内外相关领域众多学者的关注和研究[7-9],也在一些实际问题中得到了应用[10-13]。针对QPSO算法中的唯一参数(收缩扩张因子),Sun等人使用的是固定参数控制策略,后来Fang提出了随着进化代数的增加,采用线性减小和非线性减小的参数控制方法,仿真结果表明,在大部分测试函数中都取得了较好的改进效果[14];Xi等人针对QPSO算法中的粒子贡献度的差别,提出了权重系数控制算法搜索过程的改进方法,也取得了一定的效果[15]。
在QPSO算法中,算法性能严重依赖于收缩扩张因子参数,在进化过程中采用单一的参数控制策略,使粒子缺乏灵活性,这些参数控制方法并不能在进化迭代的每一步中都有效。如果将QPSO算法中的多种参数控制策略同时应用于进化过程中的参数控制,并根据多步进化(向前考察几步)的效果来选择其中一种最合适的参数选择策略作为当前粒子进化的参数,则更有利于算法的整个进化过程。基于这种思想,同时受文献[16-17]中提到的强化学习启发,本文提出了一种基于强化学习的量子粒子群优化算法(Reinforcement Learning QPSO,RLQPSO),改善算法的整体性能。
1 量子粒子群优化算法
在粒子群优化算法的群体中,个体(粒子)通过搜索多维问题解空间,在每一轮进化迭代中评价自身的位置信息(适应值);在整个群体搜索过程中,粒子共享它们“最优”位置信息,然后使用它们的记忆调整它们自己的速度和位置,不断比较和追随候选的问题空间解,最终发现最优解或者局部最优解。
基本粒子群算法的进化方程为:
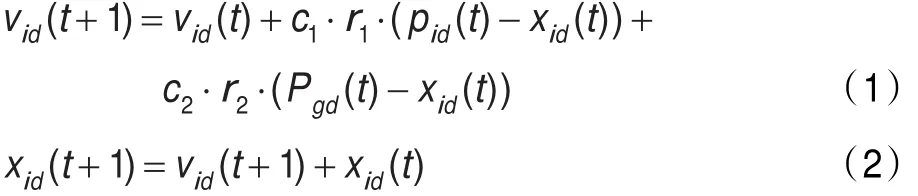
由粒子搜索路径分析可知,为了保证粒子群算法的收敛性,在粒子搜索过程中,粒子不断趋近于它们的局部吸引子pi=(pi,1,pi,2,…,pi,n),方程定义为:
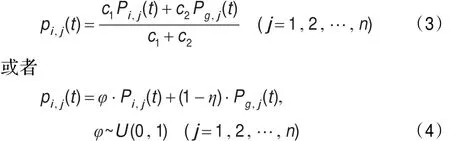
Jun Sun等[5-6]认为在这种搜索机制下,粒子的随机性就很有限,算法只能描述低智能的动物群体,而不能准确描述思维随机性很强的人类群体,并且发现人类的智能行为与量子空间中粒子行为极为相似,因此在算法中引入了量子态粒子行为,则对粒子的每一维可以得到概率密度方程Q和分布函数F,方程定义如下:
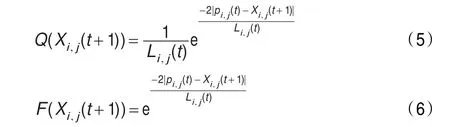
这里,Li,j(t)决定了每个粒子的搜索范围,使用Monte Carlo方法,可以得到粒子的位置方程:
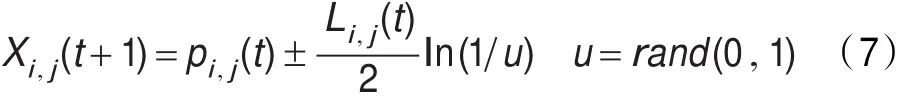
这里u是在(0,1)之间的随机数。
为了模拟人类群体行为的大众思维(Main Thoughts),在QPSO算法中引入了最优平均位置值概念,方程定义为:
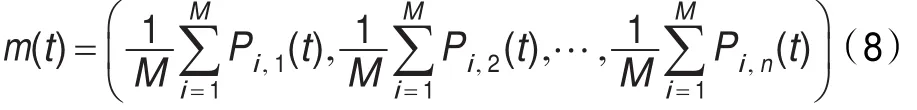
这里M是算法粒子群体的大小,Pi是粒子i的局部最优值,Li,j(t)和粒子的位置量就由以下的方程计算:
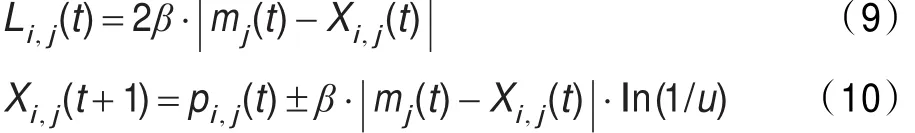
这里,参数β是QPSO算法中的唯一控制参数,称作扩张收缩系数,调节它可以控制算法的收敛速度。则式(4)(8)(10)组成了具有量子行为粒子群算法的迭代方程组。量子粒子群算法在函数测试[4]、滤波器设计[10]、多阶段金融规划[11]、神经网络优化[12]和H∞控制[13]等应用中显示了其优越性。
2 QPSO算法中的参数控制策略
在QPSO算法中,收缩扩张系数β用来调节算法的收敛速度,通过大量的仿真测试,β≤1.781时能够保证算法收敛[8],在基本QPSO中,通过仿真测试,固定取值策略条件中,β=0.8在大多数的测试函数条件下能够取得较好的测试结果。
为了改善QPSO算法的性能,方伟[14]提出了线性递减的参数调整策略和非线性递减的参数调整策略,即
(1)线性递减策略

文献[14]中的大量仿真测试表明,对于不同的测试函数,以上参数控制策略(包括固定值参数)各有优势,各自能够在不同的问题中取得优于其他参数控制策略的仿真结果。那么,对于一个未知问题,如何选择参数的控制策略才能取得更好的寻优结果,因此,受强化学习思路的启发,将参数不同的选择策略视为行动(action),在群体粒子进化过程的每一个迭代步,选择一个合适的行动(参数)来控制粒子的搜索过程。并且,在作出行动决策之前,对行动的选择多向前考虑几步,则参数最终选择结果正确的概率更高,更能提高算法的整体性能。因此,在粒子选择行动时,可以通过粒子多步进化的效果评价各种行动(参数选择策略)的优劣。
3 Q学习的量子粒子群优化算法(QLQPSO)
3.1 Q学习方法
Q学习是一种与问题模型无关的增强学习方法,通过选择最大化代理带折扣的累积收益的行动,学习到代理的最优行动策略。在QPSO算法中,若把个体进化过程中的参数选择策略看成行动,这样个体选择最优参数策略就转化为代理选择最优行动。
假设代理的状态设为s,行动设为a;则代理在任何状态下可选择的行动集合均为A={a1,a2,…,an},即代理在每个状态都有n个可供选择的行动。则代理的最大折扣回报基本形式为:
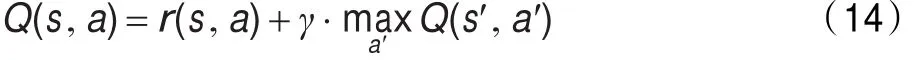
其中r(s,a)为代理在状态s下选择行动a后的立即收益;a′为代理在下一个状态s′情况下可选择的行动;表示代理在下一个状态s′选择不同行动所能得到的最大回报值;γ(0≤γ<1)为折扣因子,γ决定滞后收益对最优行动策略选择的影响。根据式(14),如果向前看m+1步,个体开始选择的参数策略为a,那么在忽略状态变量的情况下,代理选择行动a时的收益为:
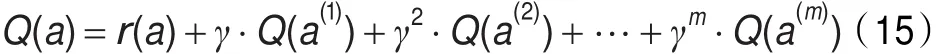
其中,m表示向前看的步数;a,a(i)∈A,且1≤i≤m。由式(15)可知,当γ=0,Q值的计算值降为只向前看一步,γ接近于1时,滞后收益对最后参数选择策略的影响将变得越来越大。
3.2 QLQPSO算法原理
根据Q学习方法,在QPSO算法中将群体中的粒子看作代理,扩张收缩系数β的选择策略看作代理行动的集合,则可以实现量子粒子群优化算法和Q学习方法之间的映射。定义fp(a)为群体中父代个体对应的适应度函数值,fo(a)为采用参数选择策略a后个体对应的适应度函数值,那么个体的立即收益可以定义为r(a)= fp(a)-fo(a)。如果本例中粒子可选行动(参数选择策略)个数为n,粒子一次进化后共产生n个后代,每个后代采用n个策略进化,二次进化后的后代个数为n2,同理m次进化后,产生的后代共有nm个,要确定一次参数选择策略,需要进行指数级运算,计算量非常巨大,不适用。为此将问题简化,粒子第一次进化后产生n个新粒子;该n粒子再次进化,每个个体又产生n个新粒子,通过计算每个个体产生的新粒子的立即收益,采用Boltzmann分布计算这组再次生成的新粒子被保留下来的概率。

根据计算出的概率,选择其中一个新个体保留下来,被保留的后代再采用同样的方式产生n个后代,并保留其中的一个后代。通过这种简化后,则m次进化后,一个粒子累计产生的个体数为n+(m-1)·n2,用于计算Q值需要保留的个体数为m×n,那么问题时间复杂度降为多项式级。
将立即收益带入式(15),并化简后可得:
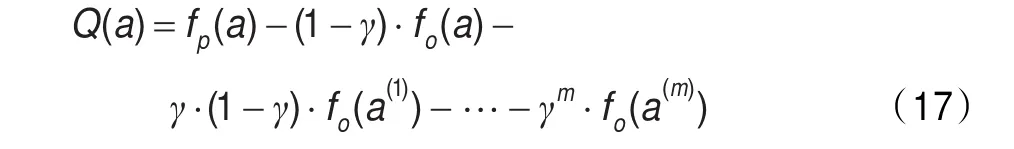
QLQPSO算法设计如下:
(1)初始化参数设置:包括群体个数;扩张收缩系数β取值范围;算法迭代次数;折扣因子γ。计算Q值所需向前看的步数m;随机产生的初始解x(i),并设置pbest(i)=x(i),并计算全局最优值gbest。
(2)根据式(5)计算局部吸引子p(i)。(3)根据式(8)计算平均最优值mbest。(4)根据QPSO算法迭代方程(9)(10)更新各个粒子的新位置。
(5)按照Q学习方法选择最优参数策略β:
①对于每个新粒子,使用给定的n个参数选择策略产生n个新的后代粒子,并设定t=1;
②Do Whilet<m
每个后代使用式(9)产生n个新后代,根据式(16)选择其中一个保留,令t++;
③计算每个参数选择策略对应的Q值,选择使Q最大化的参数选择策略所对应的β值为当前β值,同时舍弃其他n-1个β值。
(6)每个粒子按照式(8)~(10)更新位置值,并生成新的群体。
(7)回到(4)直至循环条件结束。
3.3 QLQPSO算法分析
张化祥等人[17]对基于Q学习的适应性进化规划算法(QEP)的收敛性进行了证明,QLQPSO算法收敛性的证明过程与此类似,本文在此不再对其收敛性进行证明。根据Q学习方法的原理,可以知道在QLQPSO算法执行初期,在Boltzmann分布中,温度T处于较大值,粒子在参数选择进化策略空间进行探索;随着进化步数的增加,T越来越小,粒子探索的成分逐步减小,越来越趋向于选择适应度函数值大的参数进化策略(本例中为最小化问题,因此为最优化函数值小),此时粒子选择最优参数策略的概率逐步增加。
4 QLQPSO算法仿真分析
4.1 仿真设置
为了测试和比较Q学习的QPSO算法性能,本文和固定系数QPSO(BQPSO)算法、系数线性下降的QPSO算法(LDQPSO)、系数开口向上的非线性递减QPSO算法(UPQPSO)和系数开口向下的非线性递减QPSO算法(DNQPSO)进行了测试比较,测试函数使用CEC2005 benchmark测试函数[18],其中F1到F6为单峰函数,F7到F12为多峰函数。优化问题分别设置为:BQPSO算法的β值为0.8,LDQPSO算法、UPQPSO算法、DNQPSO算法的β从1.0下降到0.5,QLQPSO算法的参数选择行动策略为上述四种算法的参数选择方法,滞后因子γ为0.5,T的初始温度为100℃。问题维数为30,算法对应的最大迭代次数为5 000,粒子数为40;每个问题的求解都应用算法随机独立运行50次。
4.2 仿真结果与讨论
表1给出了五种算法对各测试函数在不同粒子数、不同维数及不同迭代次数的情况下得到的50次仿真结果的目标函数值的平均值和标准方差。图1中给出了不同算法在40个粒子30维的情况下50次仿真的平均收敛曲线。从表1中各种算法的仿真结果看,QLQPSO在12个测试函数中,9个取得了最好的结果,LDQPSO、UPQPSO、DNQPSO各取得了一次最优值。在QLQPSO取得的8次最优的情况下,对于Shifted Schwefel’s Problem 1.2函数(F2)、Shifted Rotated High Conditioned Elliptic函数(F3)、Shifted Schwefel’s Problem 1.2 with Noise in Fitness(F4)、Shifted Rastrigin’s函数(F9)、Shifted Rotated Weierstrass函数(F11),QLQPSO取得了明显的优势。另外从图1的收敛曲线可以得知,对于Shifted Sphere函数(F1)、Shifted Rotated Griewank’s Function without Bounds函数(F7)和Shifted Rotated Ackley’s函数(F8),QLQPSO算法取得了最优值,虽然结果和其他算法比较接近,但算法表现出初期的收敛速度远高于其他算法;对于Schwefel’s Problem 2.6 with Global Optimum on the Bounds函数(F5)、Shifted Rosenbrock函数(F6)、Shifted Rotated Rastrigin’s(F10)和Schewefel’s Problem 2.13函数(F12),LDQPSO算法和UPQPSO分别取得了最优值,但是QLQPSO的结果和它们很接近,但是在初期(1 000次迭代)的收敛速度是最快的。以上说明,提出的Q学习QPSO算法大大提高了算法的收敛速度,并且在大多数测试函数中表现了优异的性能。
5 结束语
分析了QPSO算法的进化方程,并研究了算法中的控制参数选择方式对参数性能的影响,不同的参数选择方式针对不同电费优化问题有各自的优化特点,这对控制参数选择提出了更高的要求。针对算法参数选择上的限制,提出了引入Q学习的思想来根据优化问题自适应调整参数的选择,并给出了改进后的算法执行过程。最后应用CEC2005测试函数对改进后的算法和其他几种不同的控制参数选择策略进行了仿真比较,仿真结果显示改进后的算法在大部分测试函数上能够取得更优的结果,其他函数也能够取得和其他方法相近的结果,因此改进后的算法能够提高QPSO算法的整体性能。

表1 不同算法运行50轮后的平均最优值及方差

图1 五种算法优化不同标准测试函数的目标函数值的收敛曲线比较
[1]Kennedy J,Eberhart R.Particle Swarm Optimization[C]// Proceedings of IEEE International Conference on Neural Network,1995:1942-1948.
[2]van den Bergh F.An analysis of Particle Swarm Optimizers[D].University of Pretoria,2001.
[3]Zheng Yongling,Ma Longhua,Zhang Liyan.Empirical study of particle swarm optimizer with an increasing inertiaweight[C]//Proceedings of IEEE Congress on Evolutionary Computation 2003(CEC 2003),Canbella,Australia,2003:221-226.
[4]Clerc M.Discrete Particle Swarm Optimization[M]//New Optimization Techniques in Engineering.[S.l.]:Springer-Verlag,2004.
[5]Sun J,Feng B,Xu W.Particle Swarm Optimization with particles having quantum behavior[C]//IEEE Proc of Congress on Evolutionary Computation,2004:325-331.
[6]Sun J,Xu W,Feng B.A global search strategy of quantum-behaved Particle Swarm Optimization[C]//Cybernetics and Intelligent Systems,Proceedings of the 2004 IEEE Conference,2004:111-116.
[7]Sun J,Wu X,Palade V,et al.Convergence analysis and improvements of quantum-behaved particle swarm optimization[J].Information Sciences,2012,193:81-103.
[8]Sun J,Fang W,Wu X,et al.Quantum-behaved particle swarm optimization analysis of individual particle behavior and parameter selection[J].Evolutionary Computation,2012,20(3).
[9]Omranpour H,Ebadzadeh M,Shiry S,et al.Dynamic Particle Swarm Optimization for multimodal function[J].International Journal of Artificial Intelligence,2012,1(1):1-10.
[10]Chen W,Sun J,Ding Y R.Clustering of gene expression data with Quantum-behaved Particle Swarm Optimization[C]//IEA/AIE.Zurich:Springer-Verlag,2008:388-396.
[11]Chai Zhilei,Sun Jun,Cai Rui,et al.Implementing Quantum-behaved Particle Swarm Optimization algorithm in FPGA for embedded real-time applications[C]//2009 Fourth International Conference on Computer Sciences and Convergence Information Technology,2009:886-890.
[12]Omkar S N,Khandelwal R,Ananth T V S,et al.Quantum behaved Particle Swarm Optimization(QPSO)for multi-objective design optimization of composite structures[J].Expert Systems with Applications,2009,36(8):11312-11322.
[13]Goh C K,Tan K C,Liu D S,et al.A competitive and cooperative co-evolutionary approach to multi-objective particle swarm optimization algorithm design[J].European Journal of Operational Research,2010,202:42-54.
[14]Fang W.Swarm intelligence and its application in the optimal design of digital filters[D].2008.
[15]Xi M,Sun J,Xu W.An improved quantum-behaved particle swarm optimization algorithm with weighted mean best position[J].Applied Mathematics and Computation,2008,205(2).
[16]Sutton R S,Barto A G.Reinforcement learning:an introduction[M].Cambridge:MIT Press,1998.
[17]张化祥,陆晶.基于Q学习的适应性进化规划算法[J].自动化学报,2008,34(7):819-822.
[18]Suganthan P,Hansen N,Liang J J,et al.Problem definitions and evaluation criteria for the CEC 2005 special session on real-parameter optimization[R].Singapore:Nanyang Technological University,2005.
SHENG Xinyi1,SUN Jun2,ZHOU Di1,XU Wenbo2
1.School of Digital Media,Jiangnan University,Wuxi,Jiangsu 214021,China
2.School of Internet of Things,Jiangnan University,Wuxi,Jiangsu 214021,China
Quantum-behaved Particle Swarm Optimization algorithm is analyzed;contraction-expansion coefficient and its control method are studied.To the different performance characteristics with different coefficients control strategies,a control method of coefficient with Q-learning is proposed.The proposed method can tune the coefficient adaptively and the whole optimization performance is increased.The comparison and analysis of results with the proposed method,constant coefficient control method,linear decreased coefficient control method and non-linear decreased coefficient control method based on CEC2005 benchmark function is given.
Particle Swarm Optimization(PSO)algorithm;Q-learning;parameter selection;quantum behavior
A
TP301
10.3778/j.issn.1002-8331.1402-0206
SHENG Xinyi,SUN Jun,ZHOU Di,et al.Quantum-behaved particle swarm optimization method based on Q-learning. Computer Engineering and Applications,2014,50(21):8-13.
国家自然科学基金(No.61170119,No.60973094);江苏省自然科学基金(No.BK20130160)。
盛歆漪(1975—),女,博士研究生,讲师,主要研究方向:智能控制,优化算法,交互设计;孙俊(1973—),男,博士,副教授,主要研究方向:优化算法,机器学习;周頔(1983—),女,博士,副教授,主要研究方向:优化算法,图像识别;须文波(1944—),男,教授,博导,主要研究方向:智能控制,先进算法。E-mail:sheng-xy@163.com
2014-02-20
2014-05-04
1002-8331(2014)21-0008-06
CNKI出版日期:2014-05-22,http://www.cnki.net/kcms/doi/10.3778/j.issn.1002-8331.1402-0206.html
猜你喜欢
量子电子学报(2022年1期)2022-02-25
计算机工程与设计(2020年4期)2020-04-23
小学科学(学生版)(2020年1期)2020-01-19
山东冶金(2019年3期)2019-07-10
科学大众(中学)(2019年2期)2019-04-08
消费导刊(2018年10期)2018-08-20
物联网技术(2017年5期)2017-06-03
西安工程大学学报(2016年6期)2017-01-15
上海理工大学学报(2016年2期)2016-06-02
通信电源技术(2016年1期)2016-04-16
