
面向大数据系统的检测器快速筛选算法
2015-01-02 07:38倪晓蓉王伟生牛德姣
计算机工程 2015年9期
蔡 涛,倪晓蓉,王伟生,牛德姣
(江苏大学计算机科学与通信工程学院,江苏镇江212013)
1 概述
检测器生成算法是影响人工免疫系统(Artificial Immune System,AIS)检测性能和效率的重要因素之一。检测器生成算法的主要工作是从初始检测器中筛选成熟检测器,使用匹配算法检查初始检测器与自体是否匹配,选择与所有自体均不匹配的初始检测器作为成熟检测器。Forrest等研究者给出了经典的检测器生成算法,并不断有研究者进行各种改进。为保证所选择成熟检测器对非自体的覆盖率,需要计算全部初始检测器与自体的匹配度后进行筛选,这使得筛选检测器的时间和空间开销与初始检测器的数量密切相关,在初始检测器数量较少的情况下,检测器生成算法能较快地完成筛选检测器的工作。而将人工免疫算法用于大数据系统时,初始检测器的数量会达到几十万、甚至上亿的规模,筛选检测器所需的时间与空间开销将非常巨大,导致无法使用现有的人工免疫算法。在现有检测器生成算法的研究中,主要是针对如何提高对非自体的识别率、优化自体和检测器的匹配规则,缺乏针对海量初始检测器时可计算性的考虑。因此,在大数据系统中应用人工免疫算法时,如何提高筛选检测器的效率是急需解决的重要问题。
并行化是提高算法执行速度的常用手段,通过将复杂的计算过程分解为多个可以并行执行的部分,并分布到在多个处理核心上运行以提高执行的速度。但检测器生成算法中匹配规则的计算复杂度较低,传统并行计算方法所提高的计算效率很有限。而在初始检测器数量庞大时,影响筛选检测器时间和空间开销的主要因素是海量初始检测器所导致的巨大匹配检查次数,这是很典型的大数据应用。因此通过构建分布式的海量初始检测器存储系统,引入Map/Reduce模型设计新型的检测器快速筛选算法,利用分布存储节点的并行计算能力提高筛选海量初始检测器的效率是良好的选择。
本文分析初始检测器数量巨大时,影响检测器生成算法执行速度的因素,在此基础上构建混合式的海量初始检测器快速筛选架构,设计海量初始检测器分区检查策略和成熟检测器集优化策略,从而对海量初始检测器进行快速筛选。本文同时实现了面向大数据系统检测器快速筛选算法的原型系统,并使用通用数据集进行测试与分析。
2 相关工作
文献[1-2]给出了人工免疫系统中经典的否定选择算法、贪心检测器生成算法、r连续位匹配规则等;文献[3]引入多种群遗传算法,提高所生成检测器对非自体的覆盖率,虽然提高了非自体的覆盖率,但是随着问题规模的不断扩大和搜索空间的更加复杂,遗传算法在实际应用中有一定的局限性,不能表现出算法的优越性,易出现迭代次数多、收敛速度慢、易陷入局部最优值和过早收敛等问题;文献[4-5]给出了检测器克隆选择算法;文献[6]设计了动态的克隆选择算法,这些算法都能提高动态环境下克隆选择算法的适应能力,但未考虑检测器和自体数量对检测器生成效率的影响;文献[7-8]给出了抗独特型克隆选择算法,提高了生成检测器的效率;文献[9]引入聚类算法提高检测器的生成速度;文献[10]针对基于海明距离的匹配规则,给出了启发式检测器生成算法;文献[11]通过改变初始检测器的生成方法,提高了生成成熟监测器的效率及其检测非自体的效率和准确性。此外还有大量对现有检测器生成算法的改进,但均集中在提高识别非自体准确性和少量数据环境下提高效率等方面,没有考虑人工免疫算法用于大数据环境时会出现的问题以及相应的优化方法。
文献[12]设计了 Map/Reduce计算模型,用于解决分布式存储系统中海量数据的计算问题;文献[13]给出了大数据系统的特征,针对流式计算系统,分析了目前大数据流式计算在低延迟、高吞吐、持续可靠运行方面存在的技术挑战;文献[14-16]给出了大数据流式计算系统的架构,以及大数据流式计算与复杂事件处理的关键技术;文献[17]介绍了Map/Reduce和传统数据库技术的融合。当前主要利用Map/Reduce提高数据分析的效率、对大数据流进行处理、提高数据处理的准确度、以及与传统数据库技术的融合等方面,较少有关于利用MapReduce模型提高大数据环境下人工免疫系统检测器生成算法效率方面的研究。
3 海量初始检测器快速筛选算法
检测器生成算法中需要使用匹配规则检查每个自体和每个初始检测器,才能选择出成熟的检测器,因此筛选检测器的效率与初始检测器和自体数量密切相关,所需进行匹配检查的次数与初始检测器和自体数量之间呈指数级递增关系。在大数据环境下,必然出现海量的初始检测器或自体,现有检测器生成算法无法在有限时间内完成筛选初始检测器的任务。因此,在大数据环境下提高筛选检测器的效率是急需解决的关键问题。
在人工免疫算法中,自体与初始检测器是2个互补的集合,因此,在大数据环境下,当自体的数量较少时,初始检测器必然非常巨大,反之亦然。本文针对初始检测器数量巨大的情况,设计快速初始检查器筛选算法,利用多个节点的分布式计算能力提高与自体匹配检查的速度,再进行汇总,从而快速构建成熟监测器集。
本文首先给出海量初始检测器快速筛选算法的结构,再给出各阶段的具体流程。
3.1 混合式海量初始检测器快速筛选架构
本文针对大数据环境下海量初始检测器和有限自体的特点,根据初始检测器筛选算法的要求,通过初始检测器和自体的合理冗余与分布,构建适合快速筛选海量初始检测器的环境。首先改变现有检测器生成算法中集中存储初始检测器的方式,将海量初始检测器分散存储到Hadoop集群中的各个存储与计算节点中,为快速筛选初始检测器奠定基础。同时改变自体的存储方式,在每个存储与计算节点中均存储数量较小的自体集,为筛选初始检测器提供依据。由此本文设计的混合式的海量初始检测器快速筛选架构如图1所示。
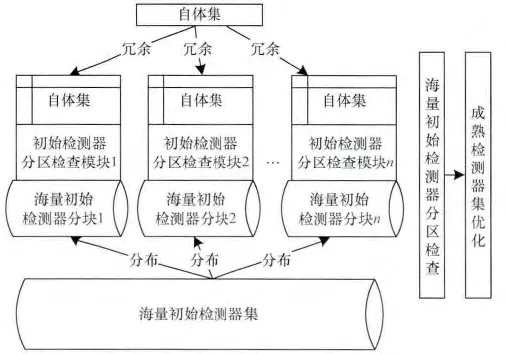
图1 混合式海量初始检测器快速筛选架构
在Hadoop集群中分散存储海量的初始检测器,能利用存储与计算节点的并行计算能力提高检查初始检测器与自体匹配的效率;而在各个存储与计算节点中冗余保存数量相对较少的自体,能使得各个存储与计算节点都能分担检查初始检测器的任务。
使用Map/Reduce模型,能将海量初始检测器筛选算法分为分区检查和汇总优化2个阶段,首先利用Hadoop集群中的存储与计算节点分布式检查海量初始检测器是否与自体匹配,并将相应结果提交给优化节点,优化节点再根据检查结果挑选最优的若干初始检测器构成成熟检测器集。
3.2 海量初始检测器分区检查策略
本文利用Map/Reduce模型中Map阶段在各存储与计算节点中分布式并发执行的特点,在将海量初始检测器子集保存到各存储与计算节点的基础上,设计海量初始检测器分区监测策略。
首先将数量有限的自体保存到存储与计算节点的内存中,依据匹配规则,与该存储与计算节点海量初始检测器子集中的检测器进行匹配检查,判断该海量初始检测器子集中的那些初始检测器能成为候选成熟检测器,同时将候选成熟检测器以及与自体之间的最大匹配值发送给优化节点,具体步骤如下述算法所示。其中,detector_subset表示某个存储与计算节点中保存的海量初始检测器子集;self_set表示自体集。
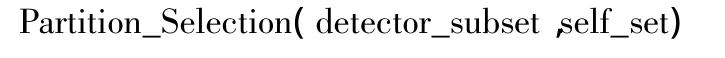

算法通过循环取出未检测的初始检测器对其进行初始设置,最大匹配度为0、候选成熟检测器的初始标志位1;然后循环与系统中未检测的自体进行匹配,如果匹配度小于系统设定的阈值且大于最大匹配度则设置该初始检测器的候选成熟标志为1,反之则设置非成熟标志为0;确定了检测器为候选的成熟的检测器之后,向优化节点输出该候选成熟检测器、以及与自体之间的最大匹配度max_match,进行下一步的优化;该算法的计算量主要依赖于该大数据系统中初始检测器的数量,随着初始检测器数量的增长呈线性增长趋势;算法的复杂度为小于O(n2)。
海量初始检测器分区检查策略利用了Map/Reduce模型中Map阶段分布式执行的特点,在将海量初始检测器分区分布存储到集群中不同存储与计算节点的基础上,每个存储与计算节点中分别检查对应分区中初始检测器是否能成为候选成熟检测器,能利用大量存储与计算节点的分布式并行计算能力提高检查初始检测器效率;同时各存储与计算节点仅将候选成熟检测器提交给优化节点,能有效减少网络通信量。
3.3 成熟检测器集优化策略
人工免疫系统中一般仅使用一定数量的成熟检测器检测非自体,各存储与计算节点筛选的候选成熟检测器通常远多与检测非自体所需的成熟检测器,但各个候选成熟检测器在检测非自体能力等方面存在差异,因此,需要合理选择部分候选成熟检测器用于人工免疫系统检测非自体。
集群中各存储与计算节点在反馈候选成熟检测器的同时也反馈了与自体之间的最大匹配度,这反映了候选成熟检测器与自体之间的相识程度,而候选成熟检测器对非自体的覆盖能力则与之相反。本文设计成熟检测器优化策略,在优化节点中利用Reduce阶段对候选成熟检测器进行整理和优化,挑选最适合的候选成熟检测器用于检测非自体,具体步骤如下述算法所示。其中,detector_set表示候选成熟检测器集,保存全部存储与计算节点发送给优化节点的候选成熟检测器;detector_mature表示成熟检测器集,保存优化后用于检测非自体的成熟检测器。

算法对海量初始检测器分区监测策略的结果进行统计优化,对海量候选的成熟的检测器按照最大匹配度从小到大进行排序并构建集合,然后循环取出这些候选成熟的检测器并同时判断是否检测器数量达到系统的设定值,如果未达到则取出集合中第一个候选成熟检测器放入优化的集合中;该算法主要依赖于分区检查策略的产生的候选成熟检测器的数量,并且随着该数量的增长呈线性增长趋势;该算法的时间复杂度小于O(n)。
成熟检测器集优化策略能依据候选成熟检测器与自体的匹配度,优先选择与自体匹配度小的检测器构建成熟检测器集,从而提高所构建的成熟检测器集对非自体的检测率和检测效率;集群中各存储与计算节点使用海量初始检测器分区检查策略时仅将候选成熟检测器提交给了优化节点,因此,优化节点中所需处理的候选成熟检测器数量非常有限,保证了从候选成熟检测器集中选择成熟检测器时的效率。
4 原型系统的测试与分析
本文构建了拥有4个节点的Hadoop集群,采用二进制字符串的形式表示自体、初始检测器和成熟检测器,使用r连续位匹配规则判断初始检测器与自体是否匹配,在存储和计算节点增加海量初始检测器分区检查子模块,主控节点增加成熟检测器优化子模块构成优化节点,实现面向大数据系统检测器快速筛选算法的原型系统。在原型系统中,包括一个主控节点和3个存储和计算节点,配置如表1所示。

表1 原型系统的配置
使用用于E-mail安全检测的标准数据集CERT synthethic sendmail data作为测试数据集,通过抽取CERT synthethic sendmail data中的记录,解析成24位二进制字符串构建自体集。
4.1 生成检测器所需的时间开销
本文同时也实现了传统检测器生成算法的原型系统,用于比较。设置初始检测器的数量分别为5×104,10 × 104,2 × 105,5 × 105,1 × 106,自体数据为5 000,测试传统检测器生成算法和面向大数据系统检测器快速筛选算法的时间开销,结果如图2所示。
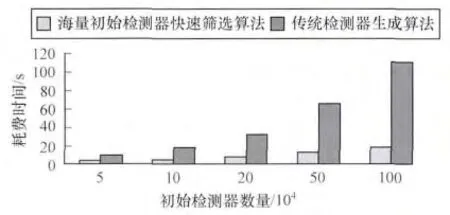
图2 不同检测器生成算法的时间开销
从图2可知,在初始检测器的数量分别从5×104增加到1×106,相比传统的检测器生成算法,面向大数据系统检测器快速筛选算法均能明显减少生成检测器所需的时间开销,所减少的时间开销在58.87% ~83.17%之间;同时随着初始检测器数量的大幅度增加,面向大数据系统检测器快速筛选算法所减少的时间开销呈现缓慢上升,这是由于存储和计算节点的数量没有增加,而每个存储和计算节点中需要处理的初始检测器数量上升,从而导致了总时间开销的增加;但相比传统检测器生成算法,时间开销的增加幅度明显减少;这验证了面向大数据系统检测器快速筛选算法具有显著减低生成检测器所需时间开销的能力。
4.2 初始检测器数量变化时分区检查的时间开销
设置初始检测器的数量分别为5×104,1×105,2 ×105,5 ×105,1 ×106,5 ×106,1 ×107,自体数据为5 000,测试海量初始检测器分区检查所需的时间开销,与面向大数据系统检测器快速筛选算法总时间开销进行比较,结果如图3所示。

图3 初始检测器数量变化时的时间开销
从图3中可知,海量初始检测器分区检查所需的时间开销随着初始检测器数量的增加而上升,上升幅度与面向大数据系统检测器快速筛选算法总的时间开销基本一致;同时海量初始检测器分区检查所需的时间开销占据了生成检测器总时间开销的75%以上;因此海量初始检测器的分区检查是影响面向大数据系统检测器筛选算法效率的主要因素。当前Hadoop集群中仅有3个节点执行海量初始检测器分区检查子模块,在增加节点数量后可有效的减低海量初始检测器分区检查所需的时间开销,进而提高面向大数据系统检测器快速筛选算法的效率。
4.3 节点数量变化时分区检查的时间开销
设置初始检测器的数量为100万,增加集群中存储和计算节点的数量,分别为3个、4个、5个和6个,测试海量初始检测器分区检查的时间开销,并与检测器快速筛选算法的总时间开销进行比较。结果如图4所示。
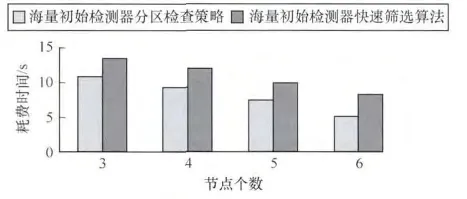
图4 存储和计算节点数量变化时的时间开销
从图4中可以发现,通过增加集群的存储和计算节点数量,海量初始检测器分区检查所需的时间开销明显减少,当节点数从3增加到6后时间开销减少了接近一半,同时面向大数据系统检测器快速筛选算法的时间开销也呈现明显下降趋势;这是由于增加存储和计算节点,能有效地减少每个存储和计算节点需要检查的初始检测器数量,从而减少了检查海量初始检测器所需的时间开销。以上结论验证了:虽然海量初始检测器分区检查所需的时间开销占生成检测器总时间开销的75%以上,但通过增加集群节点数量能明显减少所需的时间开销,从而在初始检测器数量不断增加时,仍然能快速生成检测器。
4.4 优化成熟检测器集的时间开销
采用同样的设置参数,测试成熟检测器集优化所需的时间开销,并与面向大数据系统检测器快速筛选算法总时间开销进行比较,结果如图5所示。
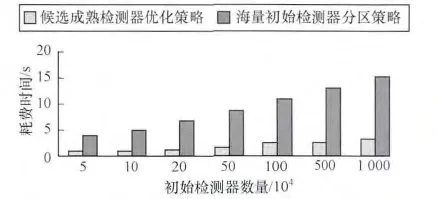
图5 分区检查阶段和成熟检测器优化阶段的时间开销
从图5中可以发现,优化成熟检测器集所需的时间开销同样也随着初始检测器数量的增加而上升,但增加幅度明显小于初始检测器数量增加的幅度,这是由于海量初始检测器分区检查之后所产生的候选成熟检测器数量已非常有限;同时优化成熟检测器集所需的时间开销仅占生成检测器总时间开销的25%以内,对面向大数据系统检测器筛选算法效率的影响很小;因此,集群中一个节点足以完成优化成熟检测器集的任务。
5 结束语
检测器生成算法是人工免疫系统的重要组成部分,也是决定人工免疫系统准确性和效率的关键因素。在大数据环境下,现有检测器生成算法难以在有限的时间内完成对数量庞大的初始检测器的筛选。本文针对初始检测器数量庞大的情况,给出了混合式的初始检测器快速筛选架构,通过将海量初始检测器分布存储,为快速筛选检测器奠定基础。设计了海量初始检测器分区检查策略和成熟检测器集优化策略,利用 Map/Reduce模型中 Map和Reduce阶段的不同特性,提高筛选初始检测器的效率,优化成熟检测器;并在Hadoop集群中实现了原型系统,使用CERT synthethic sendmail data数据集进行了测试与分析,结果表明,面向大数据系统的检测器快速筛选算法能减少58.87%的时间开销,并能在初始检测器数量不断增加时保持时间开销的稳定。
目前面向大数据系统的检测器快速筛选算法的研究主要是针对如何提高筛选成熟检测器时效率和保证算法在大数据环境下的可用性方面。下一步将针对大数据环境特点,对检测器表示方法、匹配规则、检测率和对非自体的覆盖率等方面展开研究。
[1] Forrest S,Helman P.An ImmunologicalApproach to Change Detection:Algorithms,Analysis,and Implications[C]//Proceedings of IEEE Symposium on Computer Security and Privacy.Washington D.C.,USA:IEEE Press,1996:192-211.
[2] Forrest S,Perelson A S,Allen S,et al.Self-nonself Discrimination in a Computer[C]//Proceedings of IEEE Symposium on Research in Security and Privacy.Washington D.C.,USA:IEEE Press,1994:202-212.
[3] 杨东勇,陈晋因.基于多种群遗传算法的检测器生成算法研究[J].自动化学报,2009,35(4):425-432.
[4] de Castro L N,von Zuben F J.The Clonal Selection Algorithm with Engineering Applications[C]//Proceedings of GECCO’00.San Francisco,USA:Morgan Kaufmann Publishers,2000:36-37.
[5] de Castro L N,von Zuben F J.Learning and Optimization Using the Clonal Selection Principle[J].IEEE Transactions on Evolutionary Computation,2002,6(3):239-251.
[6] Kim J,Bentley P J.Towards an Artificial Immune System for Network Intrusion Detection:An Investigation of Clonal Selection with a Negative Selection Operator[C]//Proceedings ofCongress on Evolutionary Computation.Piscataway,USA:IEEE Press,2001:1244-1252.
[7] 焦李成,杜海峰,刘 芳,等.免疫优化计算、学习与识别[M].北京:科学出版社,2006.
[8] 张立宁,公茂果,焦李成,等.抗独特型克隆选择算法[J].软件学报,2009,20(5):1269-1281.
[9] Agrawal R,Srikant R.Fast Algorithms for Mining Association Rules[C]//Proceedings of the 20th VLDB Conference.Santiago,USA:Morgan Kaufmann,1994:487-499.
[10] Luo Wenjian,Zhang Zeming,Wang Xufa.A Heuristic Detector Generation Algorithm for Negative Selection Algorithm with Hamming Distance Partial Matching Rule[C]//Proceedings of the 5th International Conference on Artificial Immune Systems.Oeiras,Portugal:[s.n.],2006:229-243.
[11] Jiang Hua,Wang Xin,Fan Xiaofeng.Research on Linear Time Detector Generating Algorithm Based on Negative Selection Model[C]//Proceedings of CCDC’09.Washington D.C.,USA:IEEE Press,2009:3058-3061.
[12] Dean J,GhemawatS.MapReduce:Simplified Data Processing on Large Clusters[J].Communications of the ACM,2008,51(1):107-113.
[13] 孙大为,张广艳,郑纬民.大数据流式计算:关键技术及系统实例[J].软件学报,2014,25(4):839-862.
[14] Scalosub G,Marbach P,Liebeherr J.Buffer Management for Aggregated Streaming Data with Packet Depen-dencies[J].IEEE Transactions on Parallel and Distributed Systems,2013,24(3):439-449.
[15] Malensek M,Pallickara S L,Pallickara S.Exploiting Geospatial and ChronologicalCharacteristicsin Data Streams to Enable Efficient Storage and Retrievals[J].Future Generation Computer Systems,2013,29(4):1049-1061.
[16] Cugola G,Margara A.Processing Flows of Information:From Data Stream to Complex Event Processing[J].ACM Computing Surveys,2012,44(3):151-162.
[17] 覃雄派,王会举,杜小勇,等.大数据分析——RDBMS与MapReduce的竞争与共生[J].软件学报,2012,23(1):32-45.
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
当代陕西(2019年14期)2019-08-26
中国交通信息化(2019年2期)2019-03-25
中国设备工程(2019年8期)2019-01-17
中国交通信息化(2017年9期)2017-06-06
自动化学报(2017年5期)2017-05-14
中学数学杂志(初中版)(2016年5期)2016-11-01
工业设计(2016年11期)2016-04-16
河南科技(2014年22期)2014-02-27
测绘科学与工程(2014年2期)2014-02-27
