
基于GPU并行的生物序列局部比对算法
2015-04-18 05:44钟一文
福建农林大学学报(自然科学版) 2015年4期
林 敏, 钟一文, 林 娟
(福建农林大学计算机与信息学院,福建 福州 350002)
基于GPU并行的生物序列局部比对算法
林 敏, 钟一文, 林 娟
(福建农林大学计算机与信息学院,福建 福州 350002)
对Smith-Waterman算法的计算公式进行了改进以适应GPU并行的特点,并提出新的基于BLOCK分块的并行前缀扫描法;通过UP-DOWN步骤、BLOCK间调整、Eij微调等步骤在O(logn)时间内计算出行中每一个元素的前缀最大值;最后将回溯过程置于GPU端,避免了CPU与GPU间内存的拷贝.与传统的Smith-Waterman算法相比,该算法在低端的GPU平台性能提升90倍;与同样基于GPU的SWAT算法相比,性能也有较大的提升.
Smith-Waterman算法; 并行前缀扫描; 通用图形处理器; 序列比对
生物序列比对需在2个序列中查找相似序列,以便对基因或蛋白质所具备的功能做出分析[1].常见的比对算法有BLAST[2]、FASTA, Smith-Waterman[3]等算法.BLAST算法和FASTA算法运行效率较高,但其敏感度均不如Smith-Waterman算法.Smith-Waterman算法是一种局部比对算法,它具有匹配敏感度高的特点,但其运算效率为O(m*n).而在生物序列比对中,为了寻求更高的准确度和敏感性,常常又需要选用Smith-Waterman算法进行更精确的匹配.Zhao et al[4]选用Smith-Waterman算法进行生物序列比对.
Smith-Waterman算法被提出以来,研究者提出了各种改进的方案以提高其执行效率.Wozniak[5]提出了采用Wave Front方式计算动态规划矩阵(DP).这种方式是利用对角线元素可以并行计算的特性,但对角线的并行化程度受制于对角线的长度,只有当连接2个角的对角线时才能达到最大的并行,所以大部分情况下大量线程处于空闲状态.并且,根据GPU全局内存的合并访问原理,这种以对角线方式访问矩阵元素的方法,将被拆分成多次访问,不适合GPU的并行.
Farrar[6]提出了一种基于单指令多数据流(single instruction multiple data, SIMD)的加速方式,但是最多只有6倍的加速.Akoglu[7]提出了第1个基于统一计算设备架构(compute unified device architecture, CUDA)的加速方案,最快有20倍的加速,但在一般情况下只能达到8-10倍的加速.KHAJEH-SAEED[8]提出基于单GPU或GPU的并行加速方式,通过改造Smith-Waterman算法的计算方法,实现了并行计算F值;但其在计算E值时采用了并行前缀扫描[9-10]的策略,这种扫描算法并未考虑GPU存储器的特点,并行的效率未大幅提高.马海晨等[11]和Liu et al[12]提出了粗粒度的并行,将1条序列同时与多个序列组成的数据库序列进行比对,这种算法的本质还是双序列比对,有待于通过对双序列比对算法的优化进一步提高其性能.因此,本文结合GPU并行的特点,对Smith-Waterman的并行步骤做了改进,提出了新的GPU加速的Smith-Waterman方案.
1 GPU并行的Smith-Waterman算法
1.1 Smith-Waterman计算公式的改进
Smith-Waterman算法是基于局部联配的动态规划算法,DP中每一元素的得分由其对角线、列和行方向的得分决定,建立的步骤如式(1)所示:
(1)
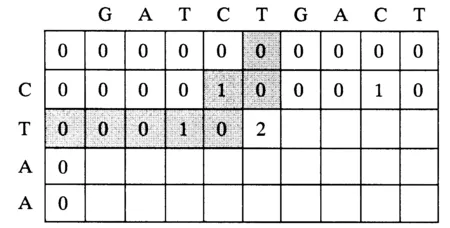
图1 构造DPFig.1 Creating DP
式中,Hij表示DP中第i行第j列的得分,Sij表示第i行第j列碱基的比对得分,Gs表示开放空位得分,Ge表示扩展空位得分.根据比对的第1个步骤建立DP,建立DP的步骤就是序列比对的过程,DP中每一元素由3个方向的值决定.第2个步骤通过DP寻找最长相似子序列,先在DP中查找最大值,由最大值元素位置开始回溯,直到得分为0为止,其回溯所经历的路径就是其比对结果.比对过程中需要加入空位罚分、错配罚分、空位扩展罚分,以使匹配结果更接近生物特性.图1为构造DP矩阵的过程;图2表示回溯的过程.
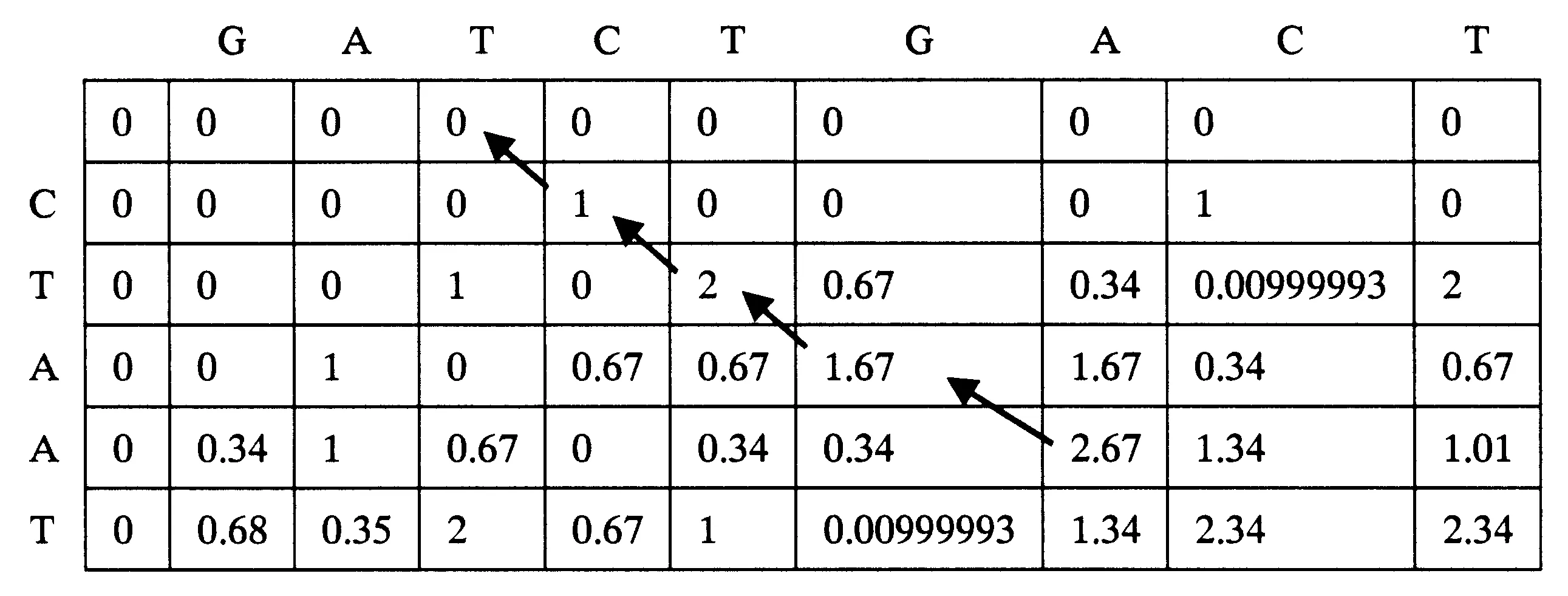
图2 回溯的过程
式(1)中的计算步骤不适合GPU的并行,Khajeh-saeed et al[8]对式(1)进行了重新设计,使GPU的线程可以并行计算DP矩阵的每列或每行,其计算步骤如下:
通过式(2)、式(3)先求每一列的最大值,采用式(4)计算行最大值,最后通过式(5)计算Hij.
Fij=Max(Fi-1,j,Hi-1,j-Gs)-Ge
(2)
Uij=Max(Hi-1,j-1+Sij,Fij,0)
(3)
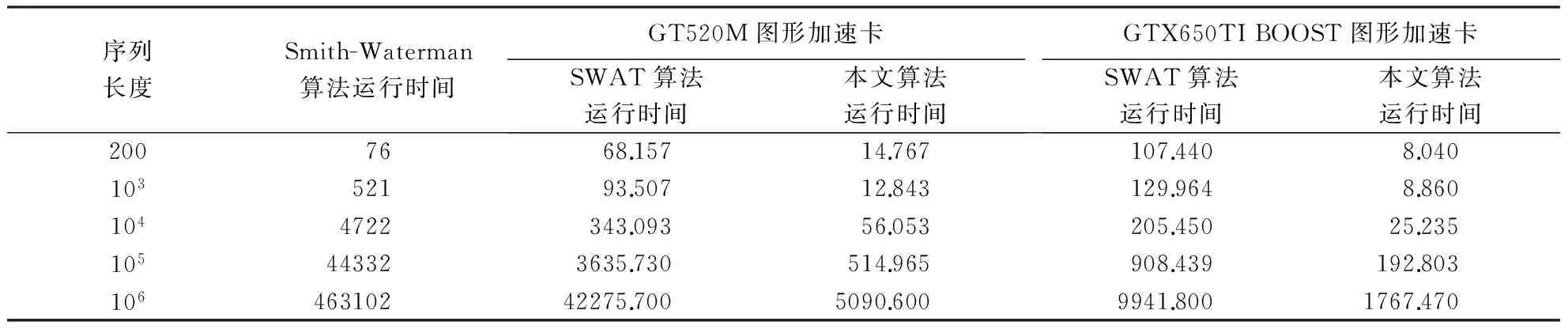
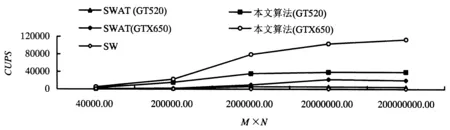
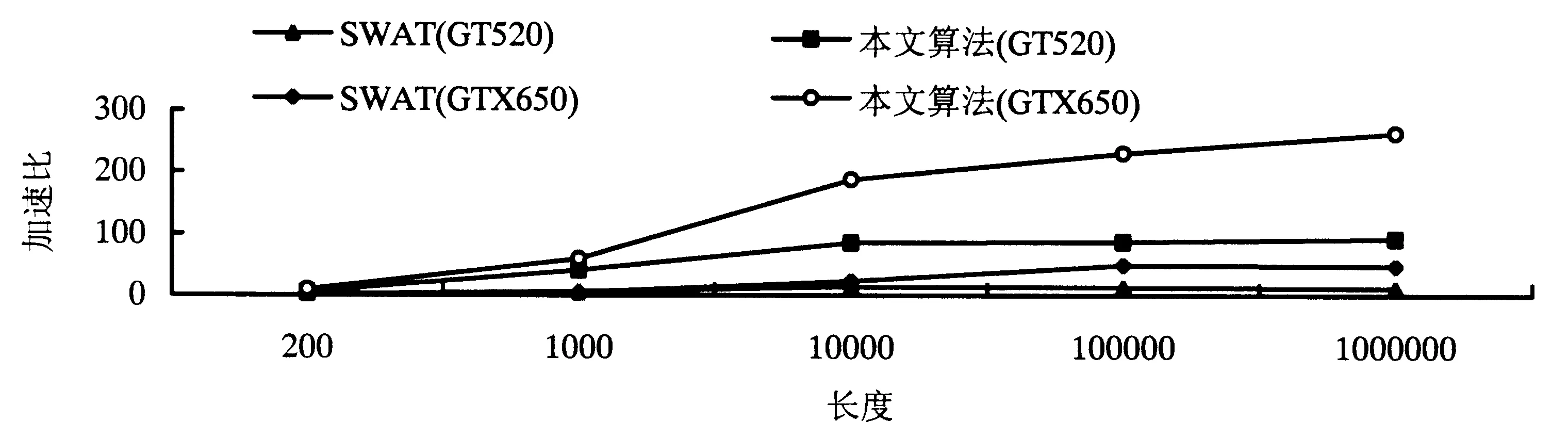
Eij=Max1≤k (4) Hij=Max(Eij-Gs,Uij) (5) Fij和Eij分别表示列和行最大值,Hij为DP矩阵,Sij为比对得分,Gs和Ge分别表示空位罚分和空位扩展罚分.本文中的算法是根据GPU全局内存合并访问的特点,采用了列并行的方式.同时为了采用GPU并行前缀扫描算法计算Eij,将式(3)、式(4)重新设计成式(6)、式(7),无需再保存Uij变量,需要的存储空间更少. Eij=Max(Hi-1,j-1+Sij,Fij,0)-(n-j)Ge (6) (7) 1.2GPU并行Smith-Waterman算法的实现 1.2.1GPU并行计算架构平台 本文的GPU并行算法是基于CUDA架构的,而CUDA是一种通用并行计算架构,它包含了指令集架构以及GPU内部的并行计算引擎,该架构使GPU能够解决复杂的计算问题.CUDA采用单指令多线程(SIMT)的执行模型,它同时能产生大量的线程,通过大量线程的并行计算来隐藏存储器访问延迟,而不必使用较大的数据缓存[11]. 运行在CUDA中的程序称为Kernel,每个Kernel相当于1个计算网格Grid,每个Grid由一维、二维或三维线程块(BLOCK)组成,而每个BLOCK被组织成一维、二维或三维的线程网格.BLOCK内的所有线程能共同使用共享存储器,且其中的所有线程同步执行,而BLOCK间的线程共享全局存储器不能直接同步,只能通过重新启动Kernel以达到同步的效果. 1.2.2 算法的主要结构 算法的核心部分是并行计算DP矩阵中每行的F值和E值,然后最终计算出H值.为了计算F值,将DP矩阵以一维数组方式存储在GPU端,以较长序列作为矩阵的行,以较短序列作为矩阵的列.采用列并行的方式计算的F值刚好满足合并访问(图3)的要求,并且每次无需记录所有行的F值,仅保留上一次计算的F值即可.而E值的计算则较为复杂,本文提出了一种基于BLOCK的并行前缀扫描算法,可快速计算出每行的E值,整个算法的执行步骤如算法1所描述. 图3 合并内存访问(实线部分为可以1次合并访问,虚线部分则要分2次完成) 算法1:主程序 begin 载入序列,将序列二值化压缩存储; 在GPU端为Hij,Fij,Eij分配存储空间; 计算blocknum=ceil(较长序列长度/256); for i=1 to较短序列长度{ cacl_Fij<< 并行前缀扫描算法计算Eij;} 回溯算法寻找最长相似子序列; 输出比对结果; end 算法1中每次计算Fij和Eij时将重新启动新的内核,因为在GPU中要实现所有线程在某个代码处同步,只能通过在该位置结束内核的运行,并启动新的内核执行下一步代码. 1.3 基于BLOCK分块的并行前缀扫描算法 算法1中E值的计算是一种典型的并行扫描算法,这种算法仅需要O(logn)次计算就能找出所有元素的前缀最大值.但随着扫描的进行,同一个线程束内的线程所访问的元素将无法保持在同一个128byte段内,即原来的并行访问将变成n次串行访问.并且为了保证线程间数据的同步,扫描的每一步都要启动一次内核,这也将影响扫描算法的效率. 本文提出了一种基于BLOCK分块的并行前缀扫描算法,将每行的Eij以256为单位划分成1个BLOCK,不足256的加0补足到256,计算时将相应BLOCK的Eij元素加载到Share Memory中,分别经过UP-DOWN步骤、BLOCK间调整、Eij微调3个步骤最终计算出Eij.算法中以256作为划分单位的原因:一是每个BLOCK内256个线程是比较适中的值,同时又解决了合并访问的问题;二是减少了计算的复杂度,在块内可以使用移位指令来加速算法的执行.Eij的计算分别经历了3个步骤,这3个步骤的具体执行过程分别描述如下. 1.3.1 UP-DOWN步骤 采用UP-DOWN步骤计算出每个BLOCK内Eij元素的前缀最大值.图4、5以8个Eij元素划分为1个BLOCK,分析了其算法过程,图中虚线部分为直接赋值,实线部分为取两者的较大值. 图4 UP步骤 图5 DOWN步骤 算法2:UP步骤 begin tx=块内线程号; 将Eij从全局内存加载到共享内存 shareEij中; 块内线程并行 ford=0 to { if(tx<(256>>d+1)) { e1=tx*(1<<(d+1))+(1< e2=(tx+1)*(1<<(d+1))-1; if(shareEij[e2] shareEij[e2]=shareEij[e1]; } __syncthreads();//块内同步} End 算法3:DOWN步骤 begin 将每个BLOCK内最后一个元素的Eij值存储到 BLOCKEij变量中,以便进行块间调整; shareEij[255]=极小值; 块内线程并行:ford=7 to 0 { if(tx<(1<<7-d)) { e1=tx*(1<<(d+1))+(1< e2=(tx+1)*(1<<(d+1))-1; temp=shareEij[e1]; shareEij[e1]=shareEij[e2]; if(shareEij[e2] shareEij[e2]=temp; } __syncthreads();} 将共享内存shareEij写回Eij; end 图6 每个分块的前缀最大值调整Fig.6 Adjustment of prefix max value of each block 1.3.2 BLOCK间调整 采用UP-DOWN步骤得到的前缀最大值,是基于每个BLOCK的,为了得到全局的前缀最大值,还必须从第2个BLOCK开始对Eij值进行调整.即将第i个BLOCK的每个Eij与第i-1个BLOCK的最后一个元素进行比较,取其较大值作为新的Eij值,其伪代码见算法4,运行过程如图6所示. 算法4:调整BLOCK间Eij begin 256个线程并行执行:fori=2 to最后一个BLOCK{ Eij[i*256+tx]=max(blockEij[i-1], Eij[i*256+tx],Eij[i*256-1]); __syncthreads(); } end 1.3.3Eij微调 经过前述步骤计算得到的Eij多计算了n-i个空位得分Ge,所以将Eij加上(n-i)*Ge得到最终的Eij值,具体过程如算法5所描述. 算法5:Eij微调 begin for 并行:{ 计算线程号tid Eij[tid]=Eij[tid]+(n-tid-1)*Ge-Gs; score[i*(n+1)+tid] =Max(Hij[tid],Eij[tid]); Eij[tid]=0; } end 1.4 Smith-Waterman回溯算法的改进 回溯算法需要先扫描整个DP矩阵以寻找最大值,算法中得到的DP矩阵存储在GPU端,直接在GPU端并行查找最大值,避免了GPU与CPU之间的内存传输.同时在回溯过程中并行查找最大值,然后启动一线程从最大值开始回溯. 2.1 各个算法的运行时间 硬件环境如下:i3-2310处理器,8G内存,GPU分别为GT520M和GTX650TI BOOST.在相同的试验环境下,Khajeh-saeed et al[8]提出的GPU并行算法(SWAT)的运行时间与本文改进的并行算法相比较,选取的序列长度分别为200、103、104、105、106.从表1可以看出,本文提出的算法的性能大大优于SW算法,运算时间只有SWAT算法的十分之一,而在GTX650TI BOOST上运行的效率则进一步提高. 表1 各算法的运行时间 2.2 各算法CUPS性能的比较 在序列比对中,一般采用CUPS衡量算法性能,CUPS越高表示算法的性能越好,计算公式为(M×N)/T,M和N分别代表2个序列的长度,T表示比对时间.图7比较了传统的Smith-Waterman算法、SWAT算法及本文提出的算法在GT520及GTX650TI BOOST上的CUPS.从图7可以看出,在GTX650平台上本文的算法最优,且在GT520平台上也展示了较好的性能,均优于SWAT算法在GT520和GTX650平台上的结果;而SW算法性能最差. 图7 各算法的CUPS与M×N的关系 2.3 各种算法的加速比分析 为了进一步比较算法的性能,比较了SWAT算法与本文算法的加速比.加速比公式为TACC=TCPU/TGPU,TCPU代表在CPU平台上的运行时间,TGPU表示在GPU上的运行时间.图8展示了序列长度和加速比的关系,可以看到本文算法的加速比随着序列的增长迅速增长,在GT520平台上达到90倍左右后逐渐达到饱和.当序列长度达到一定时,加速比逐渐达到缓和,而在GTX650平台上则加速比随着序列的增长而增加,最多达到250倍左右;而SWAT算法在GT520和GTX650平台上分别最多只能达到10倍和50倍. 图8 各算法的序列长度与加速比的关系 本文在GPU-CPU异构体上提出了GPU并行的Smith-Waterman算法,通过改进算法求解公式,采用按列并行的方式,并且提出基于BLOCK的并行前缀扫描算法.该并行前缀扫描算法经过3个步骤得到E值.这3个步骤分别是UP-DOWN步骤、BLOCK间调整、Eij微调.算法在GT520和GTX650TI BOOST上进行运行,序列长度分别为200、103、104、105、106;并在此环境下同时比较了传统的Smith-Waterman算法、SWAT算法和本文算法. 结果表明:本文算法在保证原有算法敏感度的基础上,在低端显卡GT520M上最快达到90倍的加速比;而在GTX650TI BOOST中端显卡上最快有262倍的加速比,而同样基于GPU并行的SWAT算法[8]最多只有100倍的加速比,大大优于传统的Smith-Waterman算法.从各算法的CUPS性能指标上看,本文算法的CUPS增长最快,其次是SWAT算法;并且随着序列长度的增加,本文算法的CUPS增长性能随之加快,而SWAT算法增长缓慢.从各算法的具体执行时间来看,采用本文算法比对较短序列的性能,与传统的Smith-Waterman算法比较接近,略优于SWAT算法;但在比对较长序列时,本文算法的运行时间大大低于其他2种算法. [1] 陈华,蔡铁城,张冲,等.花生叶全长cDNA文库的构建和部分表达序列标签分析[J].福建农林大学学报:自然科学版,2014,43(6):596-601. [2] ALTSCHUL S F, GISH W, MILLER W, et al. Basic local alignment search tool[J]. Journal of Molecular Biology, 1990,215(3):403-410. [3] SMITH T F, WATERMAN M S. Identification of common molecular subsequences[J]. Journal of Molecular Biology, 1981,147(1):195-197. [4] ZHAO X, LI H, BAO T. Analysis on the interaction between post-spliced introns and corresponding protein coding sequences in ribosomal protein genes[J]. Journal of Theoretical Biology, 2013,328:33-42. [5] WOZNIAK A. Using video-oriented instructions to speed up sequence comparison[J]. Computer Applications in the Biosciences: CABIOS, 1997,13(2):145-150. [6] FARRAR M. Striped Smith-Waterman speeds database searches six times over other SIMD implementations[J]. Bioinformatics, 2007,23(2):156-161. [7] AKOGLU A, STRIEMER G M. Scalable and highly parallel implementation of Smith-Waterman on graphics processing unit using CUDA[J]. Cluster Computing, 2009,12(3):341-352. [8] KHAJEH-SAEED A, POOLE S, BLAIR PEROT J. Acceleration of the Smith-Waterman algorithm using single and multiple graphics processors[J]. Journal of Computational Physics, 2010,229(11):4247-4258. [9] HARRIS M, SENGUPTA S, OWENS J D. Parallel prefix sum (scan) with CUDA[J]. GPU Gems, 2007,3(39):851-876. [10] ZHANG Y, OWENS J D, SENGUPTA S, et al. Scan primitives for GPU computing [J]. Graphics Hardware, 2007(3):97-106. [11] 马海晨,韦刚,吴百峰.基于GPGPU的生物序列快速比对[J].计算机工程,2012,38(4):241-244. [12] LIU W, SCHMIDT B, VOSS G, et al. Streaming algorithms for biological sequence alignment on GPUs[J]. IEEE Transactions on Parallel & Distributed Systems, 2007, 18(9):1270-1281. (责任编辑:叶济蓉) Parallel Smith-Waterman algorithm based on GPU LIN Min, ZHONG Yi-wen, LIN Juan (College of Computer and Information, Fujian Agriculture and Forestry University, Fuzhou, Fujian 350002, China) The formulae of Smith-Waterman algorithm was improved to make it adapt to the parallel characteristics of GPU, and a novel strategy of parallel prefix scan was proposed. The prefix maximum of each element in the row within O (logn) time was caculated through UP-DOWN steps and the adjustment between blocks andEijfine tuning. At last, the backtrack procudure ran at GPU side to avoid the memory copies between GPU and CPU. Compared with traditional Smith-Waterman algorithm, this algorithm performance increased 90 times on the lower-end GPU platform, and also had larger ascension in comparison with SWAT algorithm. Smith-Waterman algorithm; parallel prefix scan; graphics processing unit; sequences alignment 2014-08-28 2015-02-15 福建省自然科学基金资助项目(2013J01216、2014J01219). 林敏(1981-),男,讲师,硕士.研究方向:智能信息处理、并行计算及生物信息学.Email:jsjxy_lm@126.com.通讯作者钟一文(1968-),男, 教授,博士.研究方向:智能计算.Email:yiwzhong@fafu.edu.cn. TP391 A 1671-5470(2015)04-0442-07 10.13323/j.cnki.j.fafu(nat.sci.).2015.04.019
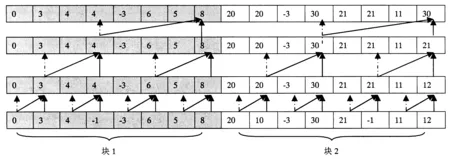
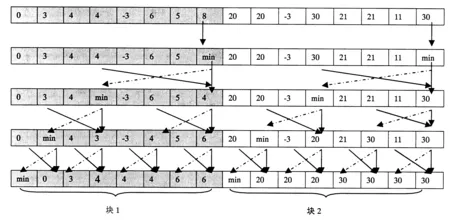
2 结果与分析
3 小结
猜你喜欢
高技术通讯(2021年5期)2021-07-16网络安全技术与应用(2020年1期)2020-01-07当代陕西(2019年13期)2019-08-20陶瓷学报(2019年5期)2019-01-12环球市场(2017年36期)2017-03-09读者欣赏(2014年6期)2014-07-03计算机与网络(2014年6期)2014-05-25语文知识(2014年2期)2014-02-28测绘科学与工程(2014年5期)2014-02-27杭州电子科技大学学报(自然科学版)(2010年5期)2010-01-08
