
可扩展的网页关键信息抽取研究
2015-04-25 08:23郭少华李海燕程学旗
中文信息学报 2015年1期
郭少华,郭 岩,李海燕,刘 悦,张 瑾,程学旗
(1. 中国科学院计算技术研究所,北京 100190;2. 中国科学院大学,北京 100049)
可扩展的网页关键信息抽取研究
郭少华1,2,郭 岩1,李海燕1,刘 悦1,张 瑾1,程学旗1
(1. 中国科学院计算技术研究所,北京 100190;2. 中国科学院大学,北京 100049)
该文提出了一种可扩展的网页关键信息抽取框架。该框架很好地融合了模板无关的全自动信息抽取算法和基于模板的信息抽取算法,从本质上提高抽取精度和抽取效率。该框架中的一些关键环节可根据需求进行替换,因此该框架具有很好的可扩展性。同时,该文还提出了模板的正交过滤算法。将该算法引入基于模板的抽取算法中,能够从本质上提高生成的模板的准确性。实验结果验证了上述结论。
关键信息;信息抽取;可扩展框架;正交过滤
1 引言
网页的关键信息是网页的最基本的信息,它体现了该网页和其他网页的差别。常见的关键信息有正文、作者、来源、发布时间等。在网络舆情监控、网络情报分析、搜索引擎等重大网络应用中,这些关键信息都是后期分析挖掘必不可少的基础数据。需要利用网络信息抽取技术[1-2]从网页中抽取出这些关键信息。从某种角度上讲,关键信息的抽取质量直接决定了网络应用服务的效果。因此,网页的关键信息抽取研究具有重大的应用价值。
随着网页规模呈指数级增长,在网络应用中,模板无关的全自动信息抽取算法和基于模板的信息抽取算法以其特有的优势成为信息抽取环节的主流算法。该算法通常针对特定需求,利用一些经验规则处理特定领域或特定格式的网页[3-5]。因为抽取过程无需人工干预,所以此类算法越来越多地应用于实际网络环境中。基于模板的信息抽取算法充分利用了动态网页的规律[6-7]: 网页是由同一个模板生成的,属于模板的符号不会变化,变化的只是模板中填充的数据。因此,该算法在对动态网页进行抽取时能够取得较高的精度。
但是,这两类抽取算法也存在着其固有的缺陷。模板无关的全自动抽取算法通常基于过强的假设。在处理多样性日益显著的网页时,常常因为某些网页不符合假设,而导致出现抽取精度不能满足需求的情况;并且由于使用过多规则,导致抽取效率低的情况。使用基于模板的信息抽取算法进行抽取时,需先针对某类网页学习出模板,后人工标注。面对日益增多的数据源,会导致网络应用的运维代价过大;同时日益复杂的网页使得模板的准确性下降,从而导致抽取精度下降。
针对上述模板无关的全自动信息抽取算法和基于模板的信息抽取算法的缺陷,本文进行了深入研究。本文的贡献主要有以下两点。
首先,提出了一种可扩展的网页关键信息抽取框架。该框架通过输入训练网页或其他算法的抽取结果,生成关键信息模板集。再通过模板的正交过滤算法,生成候选的关键信息模板。最后通过模板的特征过滤算法,生成最终的关键信息模板。利用该模板可快速、准确地从同类型网页中抽取关键信息。该框架很好地融合了模板无关的全自动信息抽取算法和基于模板的信息抽取算法,使得两类算法能够充分发挥各自的优点,并在缺点方面互相弥补。实验结果表明,该框架能够在抽取精度、抽取效率方面有本质上的提高。此外,该框架具有很好的可扩展性,框架中的一些关键环节可根据需求进行替换。
其次,本文提出了模板的正交过滤算法,该算法将训练网页或其他算法的抽取结果分成若干份,生成若干个模板,再通过模板的正交过滤算法,过滤掉模板中的噪音部分,得到候选模板。将该算法引入基于模板的抽取算法中,能够从本质上提高生成的模板的准确性,最后的实验结果也充分验证了这一结论。
本文的组织结构如下: 第1节介绍了本文提出的可扩展的网页关键信息抽取框架的背景及意义,并简单介绍该框架及核心算法。第2节介绍主要的相关工作。第3节详细介绍可扩展的网页关键信息抽取框架,重点介绍框架中的关键技术点。第4节介绍实验与结果分析。第5节对本文工作进行总结,并介绍未来工作。
2 相关工作
网页信息抽取是一种针对网络数据源和网页进行深度处理和加工的过程。由于网页的复杂性和多样性,使得网页信息抽取算法[1-2]也越来越多。常见的网页信息抽取算法主要可分为4类: 包装器语言、包装器归纳、基于模板的信息抽取和模板无关的全自动信息抽取。由于包装器语言和包装器归纳都需要过多的人工干预,所以在实际的工程应用中,基于模板的信息抽取算法和模板无关的全自动信息抽取算法以其较强的实用性占据了主流的位置。
基于模板的信息抽取通常基于这样的假设: 待抽取的网页是由同一个模板生成的,属于模板的符号不会变化,变化的只是模板中填充的数据。符合这种生成模型的网页都可以利用网页模板分析方法来抽取。互联网上大量存在的动态网页是由机器生成的(例如论坛)网页。基于模板的信息抽取的工作流程是: 1) 利用多个同类型网页中具有共性的不变的部分生成一个模板;2)根据模板对同类型网页进行抽取。因为此类算法过滤了网页中的大量模板,只留下了数据,同时自动还原出了数据的结构,使得用户在付出较小人工代价的同时,能够获得较为准确的关键信息。因此此类算法[6-7]一直都是网络应用中的主流算法。但是该类算法具有这样的缺陷: 首先需要针对同类型的网页生成一个模板。模板的准确性直接决定了后续信息抽取的精确度。随着网页复杂性以及同一类型网页的差异性的增大,生成的模板准确性随之降低。
模板无关的全自动信息抽取算法进一步提高了信息抽取的自动化程度。此类算法通常利用一些经验规则处理特定领域或特定格式的网页,例如,经典的全自动信息抽取算法MDR[8]。该算法的缺陷在于通常基于过强的假设。以网页正文抽取为例。网页的正文往往是各大网络应用都需要的关键信息,有不少针对正文抽取的模板无关的全自动抽取算法[3-5]。CoreEx[5]是通过计算DOM树中的链接文本比来确定正文所在的范围。CETR[4]是通过标签的密度来确定正文所在的范围。CETD[3]结合了二者优点。这些算法自动化程度高,通用性强,但是效率较低,且假设过强,精确度不如基于模板的算法。VIPS[9]是一种通用性较强的算法,但是它需要渲染网页。因此这种方法的效率较低。
在以往的文献中,较少看到将模板无关的全自动信息抽取算法和基于模板的信息抽取算法结合使用的相关研究。在本文提出的框架中,巧妙地将这两种算法有机地结合起来,使得二者能够取长补短,从本质上提高信息抽取的质量。
3 可扩展的网页关键信息抽取框架
3.1 框架概述
如图1所示,框架的输入是一批原始训练网页,或者其他信息抽取算法的抽取结果。需要说明的是,这些抽取结果带有HTML标签结构,如图2和图3所示。然后将这些训练网页或抽取结果随机平均分成k份,每一份均通过模板生成算法,生成关键信息模板集。再通过模板的正交过滤算法,生成候选的关键信息模板。接着通过模板的特征过滤算法,生成最终的关键信息模板。最后根据最终模板对同类型网页进行抽取。
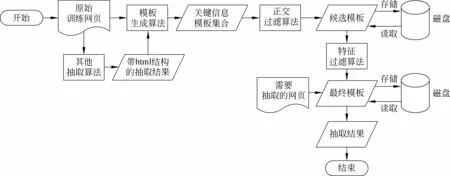
图1 可扩展的网页关键信息抽取框架的架构图

图2 HTML网页源码

图3 带HTML标签的抽取结果
该框架具有很好的扩展性,主要体现在以下几个方面。
(1) 关键信息模板集合生成算法的输入部分,是一批原始训练网页,或者其他信息抽取算法的抽取结果。这里的抽取算法一般是模板无关的全自动抽取算法。这些算法已经根据需求对原始网页进行了一次噪音过滤。因此,对于框架中的模板生成环节,把这些抽取结果作为训练数据输入,和把原始网页作为输入相比较,能够获得更精确的模板。另一方面,用模板无关的全自动抽取算法处理不符合算法假设的网页时,噪音过滤的效果不够好。对于这种情况,通过把抽取结果输入到框架中,经过后期一系列的模板生成、基于模板的抽取,能够进一步过滤掉噪音,从而增强了模板无关的全自动抽取算法的适应性。这两方面结论在第5节的实验结果将有展示。
(2) 特征过滤算法部分,可以根据要抽取的信息特征,替换相应的算法。
(3) 在模板生成过程中,框架将关键信息模板集、候选的关键信息模板等中间结果存入磁盘,当再次遇到同类型网页时,可以直接从磁盘上读取模板的中间结果。
(4) 基于模板的信息抽取算法的输入可以是框架中生成的模板,也可以是人工配置的模板。
框架中的关键技术点有模板的表示、关键信息模板集合的生成算法、模板的正交过滤算法、模板的特征过滤算法,以及基于模板的抽取算法。
3.2 关键技术点
3.2.1 模板的表示
模板T定义:
T是输入的网页所有关键信息的模板,它是由n个关键信息槽Sloti组成的。
i表示第i个关键信息,每个关键信息槽Sloti由信息槽名称Namei和m个节点组成。
每个节点Nodej是由可定位的相对路径XPath、标签Tag和关键信息的前后Label组成。例如,“
”,Xpath是“div/div[0]/span”,Tag是“span”,Label是“作者:”。3.2.2 关键信息的模板集合生成算法
单记录页面生成关键信息模板集合的算法如下:
首先建立DOM树。删除CSS、Script等节点。去掉br和p节点,将相邻的段落合并,即合并相邻的叶子节点。标签名和属性名、属性值一样的相邻节点,则将它们合并成一个节点。这样可以尽可能保证各关键信息不被分割。接着将M棵DOM树对齐并合并。
将对齐后每一个位置对应的n个节点,有选择地插入到站点版块风格树SBSTree(site board style tree)中(图4中的数字代表该节点重复度dump,即该节点出现的次数): 如果全是标签节点,则将第一个标签节点插入到SBSTree中相应位置;如果全是文本叶子节点,则统计并记录每个文本叶子节点出现的次数,并将内容互不重复的文本叶子节点全部插入到SBSTree中相应位置 (同一个父节点下) ;如果部分是文本叶子节点部分是标签节点,则选择第一个标签节点插入到SBSTree中相应位置,统计并记录每个文本叶子节点出现的次数,并将内容互不重复的叶子节点也全部插入到SBSTree中相应位置 (同一个父节点下)。
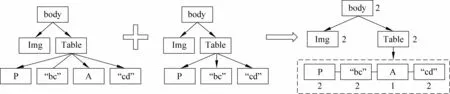
图4 DOM树合并
合并后的DOM树具有如下特征: 对于网页中公共的信息,例如,导航、网站声明,其对应的合并后的树中的叶子节点的重复度dump为M,并且该节点的父节点只有一个叶子节点。而各个网页的关键信息,由于不相同,因此它们的父节点的叶子节点个数小于M,并且大部分叶子节点的重复度为1。计算每个重复度大于1的叶子节点的平均重复度dump。最后将所有子节点含有重复度大于dump的叶子的节点转换成模板。
多记录页面生成所有关键信息模板算法如下:
首先,建立DOM树。删除CSS、Script等节点。其次将M棵DOM树中含有style和class属性,且所有属性名和属性值一样的节点各自聚类。横向比较每一类节点在M棵DOM树中的数量及其叶子内容的变化,并记录个数相关的节点类,它的节点个数随着记录个数的变化而变化。例如,跟帖的正文节点、跟帖的作者ID节点的数量和正文的节点数量是一致的。而那些非关键信息,有一部分节点个数和记录个数保持一致,但是内容基本不变,另一部分出现的次数和正文节点无关。最后对于每棵DOM树中,节点数量和内容都有变化的节点,认为是所有关键信息节点。将其转换成模板。
3.2.3 模板的正交过滤算法
一般的全自动模板生成算法,都是通过训练输入的所有网页,生成一个包含所有关键信息的模板集合。这种做法生成的模板精度较低,模板的结果受输入的训练网页的影响较大。在此我们提出了正交过滤算法,该算法对生成的关键信息模板集合进行正交过滤,以保证获得更加准确的候选模板。


图5 模板正交过滤算法
3.2.4 模板的特征过滤算法
对于候选的关键信息模板集合T,可能我们只需要部分关键信息的模板,因此在模板集合中找出我们所需要的模板至关重要。由于我们的框架具有很强的灵活性,因此能够很好地和已有的根据网页特征抽取关键信息的算法相结合。比如可以在用候选模板集合T抽取关键信息的过程中,利用关键信息的视觉特征,获得最可能的模板。最常见的关键信息一般是正文。因此这里以新闻和论坛的正文为例,我们根据它们的特征,计算出正文的最终模板。
a) 新闻正文的特征过滤算法:
先用模板集合(T1,T2,T3,…,Tm)去抽取输入的k个网页,抽取出结果。每个模板Ti都对应k个抽取结果。计算每个结果的重要度。
重要度定义:Importance(Ti)=D(Doci)×logm(E(Doci)+m)
Doci是模板Ti抽取出来的文本节点信息。D(Doci)是模板Ti抽取出的k个文本节点的方差,m是这棵树是该模板集合的模板个数,E(Doci)是Ti模板抽取出的k个文本节点的平均长度。取Importance(Ti)值最大的模板为新闻正文的模板。
b) 论坛正文的特征过滤算法:
论坛主帖和新闻类似,都属于单记录结构,因此它的模板与新闻正文的模板选择算法一样。论坛的跟帖属于多记录结构,其正文特征有别于单记录结构的正文特征。
先用模板集合T={T1,T2,T3,…,Tm}去抽取输入的k个网页,抽取出结果。每个模板Ti都对应k个抽取结果。由于是多记录结构,每个模板每个页面会抽取到Nfloor(Nfloor≥1)个结果。抽取的过程中,会得到该模板对应的节点之下的所有标签数量。计算每个结果的重要度。
分别计算每个关键信息节点及其style和class属性的子孙节点的重要度。

Doci是模板Ti抽取出来的文本节点信息。D(Doci)和E(Doci)分别是模板Ti抽取出的k个文本节点的方差和均值,m是这棵树是该模板集合的模板个数,Nfloori是模板Ti抽取出来的记录个数,NPi是模板Ti抽取出来的段落个数,Ntagi是模板Ti抽取时候遍历的HTML标签个数。取Importance(Ti)值最大的模板为论坛跟帖的模板。
3.2.5 基于模板的抽取算法
对于输入的网页,建DOM树后遍历DOM树,若是某一个节点与模板中的某个关键信息槽的相对路径、标签名和标签属性一致,将该节点下面的文本去掉Label,即为该关键信息槽对应的关键信息。
4 实验
为了验证本文提出的可扩展的网页关键信息抽取框架的有效性,我们以抽取新闻的正文为例在该框架上进行了实验。
CETD[3]是目前较新的全自动的网页正文抽取算法,文献[3]表明该算法能够获得较好的抽取效果。为了展示本框架能够增强模板无关的全自动抽取算法的适应性,我们使用算法CETD[3]作为对比算法,并将其作为框架中的模板无关的全自动抽取算法。
4.1 实验数据与环境
新闻的实验数据是来自10个新闻网站的国际频道的网页共2 000个。这些网站覆盖了各大主流的新闻网站,且网页在HTML结构方面也几乎覆盖了各种情况,因此,保证了实验数据的多样性。实验机器配置为Intel Q9300双核CPU,4GB内存,运行环境为ubuntu平台,程序由C++开发实现,编译器为gcc。
4.2 评价方法
通过人工标注,我们获得2 000个网页的正文作为参考结果。
假设a是参考结果,b是抽取结果,那么准确率P、召回率R和F值分别如式(1)、式(2)、式(3)所示。
LcsLength(a,b)为字符串a和字符串b的最大公共子串的长度,Length(a)为字符串a的长度,Length(b)为字符串b的长度。
4.3 实验结果与分析
为了检验本文提出的信息抽取框架的有效性,我们设计了4组实验,如表1所示。
1) 使用本框架生成的模板进行信息抽取的实验
2) 使用模板无关的全自动抽取算法(CETD)抽取
3) 使用模板无关的全自动抽取算法的抽取结果作为训练网页生成模板的实验
4) 使用本框架,但是没有对模板进行正交过滤
其中第1组和第3组的对比实验用于检验利用模板无关的全自动抽取结果作为训练样例生成模板的有效性。第1组和第4组的对比实验用于检验正交过滤算法的有效性。第2组和第3组的对比实验用于检验整个框架的有效性。
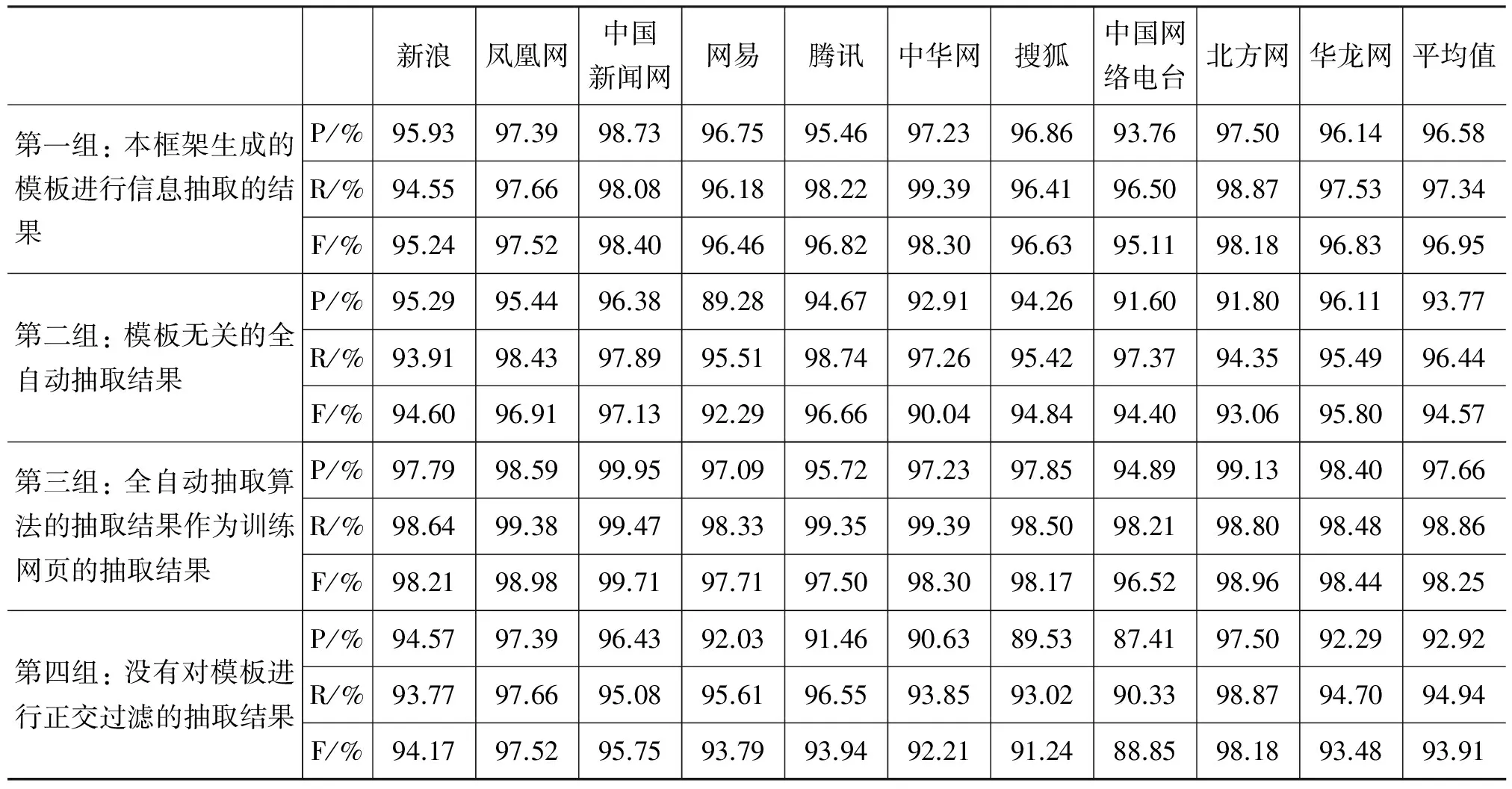
表1 四种方案的结果
从结果中,我们可以得出以下结论。
(1) 从第3组和第1组实验结果可以看出,使用模板无关的全自动抽取算法的抽取结果作为训练网页生成模板的抽取结果要好于直接用训练网页生成模板的抽取结果。
(2) 从第4组和第1组实验的结果可以看出,引入正交过滤算法后,生成的模板的抽取结果要好于没有对模板进行正交过滤的抽取结果。
(3) 从第1组和第2组实验的结果可以看出,该框架的整体抽取结果要好于模板无关的全自动抽取结果。
(4) 通过对抽取结果错误的网页进行分析发现,抽取错误的主要因素有如下3点: 1)有些 HTML 页面标签缺失,从而造成部分标签被当作正文抽取出来。2)有些网页的正文开头或结尾的作者、来源等噪音和正文是连在一起的。3)有些网页的副标题或者摘要仅通过换行标签和正文区分开来,和正文没有区别。
(5) 全自动抽取算法的抽取结果作为训练网页以及正交过滤算法对一小部分板块的网页抽取效果不明显,但是从十个板块的平均值上可以看出,这两种算法对结果的正确率和召回率都有一定的提高。
在运行效率方面,我们也做了实验。该框架生成的模板平均每个页面的处理时间为8.59ms, 而模板无关的全自动抽取算法平均每个页面的处理时间为24.72ms。可以得出这样的结论,在在线抽取过程中,用该框架生成的模板对网页进行抽取,比用模板无关的全自动抽取算法抽取的速度快近2倍。
5 结论与未来工作
本文提出了一种可扩展的网页关键信息抽取框架,该框架很好地融合模板无关的全自动信息抽取算法和基于模板的信息抽取算法。实验结果表明,该框架能够在抽取精度和效率方面有本质上的提高。该框架中一些关键环节可根据需求进行替换,因此该框架具有很好的可扩展性。同时,本文还提出了模板的正交过滤算法,将该算法引入基于模板的抽取算法中,能够从本质上提高生成的模板的准确性,最后的实验结果也充分验证了这一结论。
在未来工作中,我们将针对输入的训练网页进行聚类以及引入视觉特征,以改进关键信息模板集合的生成算法和模板的正交过滤算法,从而进一步提高生成的模板的精度。
[1] Laender A H F, et al. A brief survey of web data extraction tools[C]//Proceedings of the ACM Sigmod Record, 2002. 31(2): 84-93, ACM New York, NY, USA.
[2] Chang C H, et al. A survey of web information extraction systems[J]. Knowledge and Data Engineering, IEEE Transactions, 2006, 18(10): 1411-1428.
[3] Fei S, Dandan S, Lejian L. DOM Based Content Extraction via Text Density[C]//Proceedings of the 34th international ACM SIGIR conference on Research and development in Information Retrieval, ACM New York, NY, USA 2011: 245-254.
[4] Tim W, William H, Jiawei H. CETR-Content Extraction via Tag Ratios[C]//Proceedings of the 19th international conference on World wide web, New York, NY, USA 2010: 971-980.
[5] Jyotika P, Andreas P. CoreEx: Content Extraction from Online News Articles[C]//Proceedings of the 17th ACM conference on Information and knowledge management, ACM New York, NY, USA 2008: 1391-1392.
[6] Valter C, Giansalvatore M, Paolo M. RoadRunner: Towards Automatic Data Extraction from Large Web Sites[C]//Proceedings of the 27th International Conference on Very Large Data Bases, Morgan Kaufmann Publishers Inc. San Francisco, CA, USA 2001: 109-118.
[7] Yang S, Lin H, Han Y. Automatic data extraction from template-generated Web pages[J]. Journal of Software, 2008,19(2):209-223.
[8] Bing L, Robert G, Yanhong Z. Mining data records in Web pages[C]//Proceedings of the ninth ACM SIGKDD international conference on Knowledge discovery and data mining, ACM New York, NY, USA 2003:601-606.
[9] Deng C, Shipeng Y, Jirong W, et al. Extracting content structure for web pages based on visual representation[C]//Proceedings of the 5th Asia-Pacific web conference on Web technologies and applications, Springer-Verlag Berlin, Heidelberg 2003: 406-417.
Research on Extensible Web Key Information Extraction
GUO Shaohua1,2, GUO Yan1, LI Haiyan1, LIU Yue1, ZHANG Jin1, CHENG Xueqi1
(1. Institute of Computing Technology, Chinese Academy of Sciences, Beijing 100190, China;2. University of Chinese Academy of Sciences, Beijing 100049, China)
An extensible framework of web key information extraction is presented in this paper. This framework combine automatic information extraction algorithms and template detection algorithms, essentially improving the precision and efficiency of extraction. Some key parts of this framework can be replaced as required, therefore it has excellent extensibility. Furthermore, this paper also describes an orthogonal filter algorithm, which improves the precision of template generation. And the experiments provide positive results for this method.
key information;information extraction;extensible framework;orthogonal filter

郭少华(1984—),硕士研究生,主要研究领域为信息抽取、网络数据挖掘。E⁃mail:guoshaohua@software.ict.ac.cn郭岩(1974—),博士,助理研究员,主要研究领域为信息抽取、网络数据挖掘。E⁃mail:guoy@ict.ac.cn李海燕(1985—),硕士,助理工程师,主要研究领域为数据挖掘和信息抽取。E⁃mail:lhytiancai@163.com
1003-0077(2015)01-0097-07
2013-03-20 定稿日期: 2013-06-18
国家自然科学基金(61100083);国家863计划基金(2012AA011003)
TP391
A
猜你喜欢
科学养鱼(2021年6期)2021-11-30
快乐语文(2021年15期)2021-06-15
成都信息工程大学学报(2021年6期)2021-02-12
童话世界(2020年13期)2020-06-15
模具制造(2019年7期)2019-09-25
故事大王(2019年4期)2019-05-14
电子制作(2018年10期)2018-08-04
魅力中国(2018年5期)2018-07-30
电子制作(2017年2期)2017-05-17
爆笑show(2015年5期)2015-07-09
