
一种基于内容分析的高性能反钓鱼识别引擎
2015-04-30 06:56王惟
软件导刊 2015年4期
关键词:网络安全
王惟
摘要摘要:网络钓鱼是一种伪装成一个可信站点,通过社会工程学技术,诱使用户输入敏感信息,从而骗取用户私人信息的攻击行为,是当今互联网交易中的重大安全威胁。针对这类安全问题,介绍了一种基于内容分析的高性能反钓鱼识别引擎。通过合理的架构与算法设计,使系统达到高于93%的准确度,同时保证92.4%的召回率及快速处理,有效地阻止了钓鱼攻击在网络上的传播。
关键词关键词:网络钓鱼;反钓鱼识别引擎;网络安全
DOIDOI:10.11907/rjdk.151303
中图分类号:TP309.5
文献标识码:A文章编号文章编号:16727800(2015)004013903
0引言
网络钓鱼攻击是当今互联网交易中威胁最大的攻击形式。钓鱼者常常构造一个钓鱼站点,将该站点页面伪造成为一个可信站点,并通过社会工程学技术,骗取用户信任,诱惑用户输入个人信息,从而得到用户的账号、密码等敏感数据进而盗取用户的财产。随着B2B、B2C等形式的电子商务日益普及,钓鱼攻击的危害也与日俱增。根据著名的反钓鱼组织APWG统计[1], 2009年下半年,该组织接到了超过126 697次钓鱼攻击举报,是上半年55 698次的两倍多。此外,钓鱼形式也呈现多样化趋势,新型钓鱼方式逐渐成为主流,如短信、飞信或者聊天软件弹出的中奖信息,甚至有的钓鱼者利用求职信息进行诈骗。因此,如何避免用户受骗,保护用户的交易安全成为当前互联网安全的首要任务。
虽然许多信息安全厂商、研究机构发布了多种技术来防止网络钓鱼的发生,但目前还没有能够完全解决这些问题的方案。文献[2]表明,只有少数工具能够保证在一个较低的误判率下识别超过60%的钓鱼攻击。
笔者提出了一种基于内容分析的新型反钓鱼识别引擎。有别于大部分的解决方案,本系统不是一款针对用户桌面浏览器的插件工具,也不是一款学术验证模型,而是可以部署在防火墙或者网关的阻断引擎系统。
该系统捕捉和分析每一个通过引擎的数据包并提取出网址,随后对该URL进行分析,当识别为钓鱼攻击时即进行阻断。为了提高识别效率,在该原型系统中,加入了一个白名单和一个实时维护的黑名单组件,在降低误判率的同时,大大缩短了引擎识别的处理时间。
系统功能如下:①实现了一种可以部署在防火墙或者网关的高速处理识别引擎,不仅仅针对用户桌面的浏览器,能更好地应对新型网络钓鱼的攻击;②实现了多国语言识别,特别是针对中文进行分析。
1相关工作
在现有的反钓鱼机制中,根据其实施策略大致可分为电子邮件级和用户桌面级两种。
1.1电子邮件级
一般意义上认为,传统的钓鱼攻击是通过伪造的电子邮件开始的。因此,一些方案试图通过识别并阻止伪造电子邮件进行反钓鱼拦截,这些方案往往采用反垃圾邮件的相关技术,通过类似于过滤器的方式进行识别[3]。然而,随着新型网络钓鱼的出现,特别是传播途径的多样化,越来越多的引诱信息通过聊天软件、聊天室或者手机短信进行传播,基于邮件的策略逐渐成为了被绕过的“马其诺防线”。
1.2用户桌面级
网络浏览器作为网站呈现的终端工具,一直扮演者重要的角色,因此,人们研究的视角放在了用户桌面。这些方案最终通过浏览器插件的形式实现各种识别算法,目前主要有两种方法。
(1)基于黑名单的过滤机制[4,5]。通过查询一个实时维护的黑名单并对名单上命中的记录进行拦截,从而实现对恶意钓鱼站点的阻断。该方法具有准确度高、处理速度快的优点,但是随着制作钓鱼站点成本的降低,钓鱼站点的平均寿命越来越短,同时新出现的速度也越来越快,而此时基于黑名单的过滤机制,因较差的扩展性以及黑名单更新的时效性,日益跟不上钓鱼网站更新的步伐。新出现的Rock-phish和fast flux钓鱼技术[1],使黑名单的编译也变得非常复杂[4]。
(2)通过机器学习算法进行启发式分类识别。有的方案是通过对URL的特点进行分析,例如,MA等人提出,网络钓鱼的URL存在较明显的特点[6],而Garera等人则利用回归模型对域名、网址、出现文字和网页排名等信息进行分类来识别钓鱼[7]。卡内基梅隆大学的一系列研究将分析对象放在页面,通过对页面特征进行提取,并配合搜索引擎对页面进行定位,从而识别目标页面是否为钓鱼[8]。这些方法虽然准确度较高,但流程上依赖于搜索引擎的结果,查询极为耗时,因此也仅仅能够应用于对效率不敏感的桌面浏览器,而不适合大数据量的情况。
本文将识别引擎放在终端用户以及网络服务器之间的通路上,创立了防火墙侧的解决方案。这样,识别引擎可以获取到终端用户获取不到的很多信息,能够更有效地拦截钓鱼攻击,减轻对用户的危害。
2系统结构
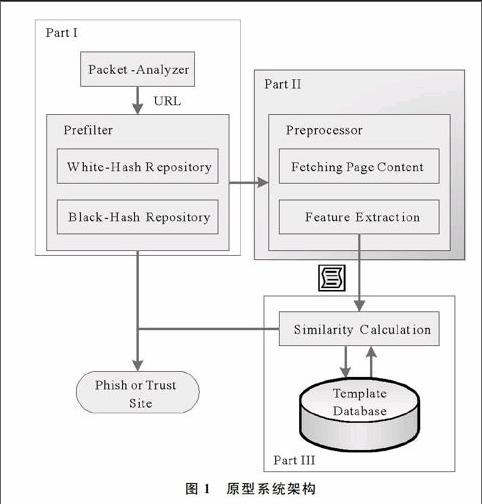
作为一个能够高速处理大数据量的防火墙侧方案,系统部署在用户浏览器与Web服务器的交互路径中。为了保证其处理速度,系统可以不依赖任何搜索引擎的查询结果。图1是该原型系统架构。
(1)预处理。系统通过包分析器对流量进行拆分,捕获每个Get包中的网址信息,提取出去重后的URL。为了提高处理速度并节省资源,建立一个白名单库用于排除掉已知的安全站点从而降低误判;同时还建立一个黑名单库,将已经识别并确定了的URL直接过滤,避免重复识别,从而提高系统的处理性能。
(2)页面分析。经过预过滤之后的URL既不是有名的官方网站,也不是之前已经判断过的钓鱼URL,因此需要对其进行下载并对页面进行分析。考虑到钓鱼网页的大小平均约为1.5K,为了保证处理速度,对过大或者过小的页面下载进行了限制。这样,一方面保证了足够的带宽,另一方面保证了处理速度。同时,为了实现多国语言特别是对中文的支持,将下载后的页面统一进行UTF-8格式的网页编码。编码转换之后,分析页面并提取页面的特征值,组成一个特征向量集合。虽然系统可以将页面的所有文字作为特征向量提取出来,但是这将大大增加分类的复杂度,使系统负载过高。为了保证引擎的处理速度,使用了TF-IDF算法。TF-IDF算法在文本挖掘和数据检索中应用很广,是一种常用的衡量权重的方法,具体来说,它描述了一个词的词频与逆向文档频率的关系,即这个词对于区分该文档的重要程度。其词频定义如下:
TF(wi,P)=ni∑knk(1)
在该系统中,将页面的停用词、干扰词之外的有效词语进行出现次数的统计,词的出现次数作为分子,而分母是所有出现在页面的词的总数。因此该页面的词频描述了这个词在这个页面中出现的次数,即这个词在该页面中的重要程度。而逆向文档频率则描述的是这个词最一般的重要程度。使用本文维护的一个因特网词频库进行计算,定义如下:
IDF(wi)=log|N|1+|d:wi∈d|(2)
|N|是所有文档的数目,|d:wi∈d|是包含词wi的文档数目,这里为了避免分母为0而没有意义,将|d:wi∈d|进行了加1处理。因此,每个单词的权重即TF-IDF分数为:
STF-IDF(wi,P)=TF(wi,P)·IDF(wi)(3)
在计算完每个词的分数后,按照TF-IDF的权值进行排序,提取最高的100个词作为该页面的特征,并与库中的模板进行比对。
(3)相似度计算。首先通过对已知的钓鱼站点,使用同样的算法对页面进行分析并提取特征后,对该特征建立起不同的模板文件,随后将分析页面与模板文件进行比对,计算相似度,找出最相似的模板。如果大于某个阈值,则说明该页面的URL极为可能是钓鱼站点。计算两个特征向量相似度的算法很多,而余弦定理是比较成熟的一种,因此本文采用余弦定理。待分析页面的特征向量p与模板文件的特征向量t的相似度sim(p,t)由下式给出:
sim(p,t)=cos(p,t)=p·tpt(4)
其中“·”表示两个向量的点积。两组特征向量之间的角度不会大于90度,相似度范围在0~1之间,sim(p,t)=1的时候说明两组特征向量完全重合。在本系统中,将阈值设为0.8,相似度大于0.8的URL,识别引擎判定为钓鱼URL。
3实验结果与分析
笔者收集了大量的钓鱼站点样本以及合法站点的样本作为实验的数据集。其中,英文钓鱼站点样本来自于著名的反钓鱼知识库phishtank.com以及APWG,中文样本由APAC提供。同时,通过自己的爬虫抓取了互联网中涉及金融、教育、社交网络、政府等多个领域的合法网站作为数据集中的反向样本。其中,选取2011年1月1日~31日时间段内的数据样本进行测试。为了保证爬虫采集的合法网站以及由第三方数据源收集到的钓鱼站点记录的准确性,我们使用人工校验,将不符合的URL以及已经跳转到正常站点的URL排除,确定最终样本。其中,钓鱼站点5 910条,合法站点1 000条。将总共6 910条测试用例随机混合,使用引擎进行匹配,以检测引擎的识别效率与准确度。
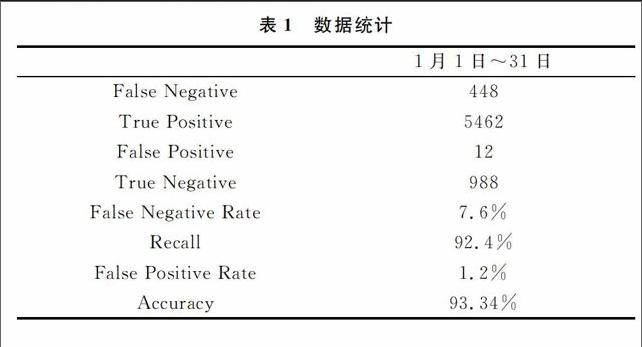
下载之前需要先对URL进行DNS解析,将域名解析成IP才能下载,而该识别引擎在正式运行的时候获取的是现网中的GET数据包,GET包中带有IP,因此在性能测试过程中要忽略DNS的解析时间。在四核至强 E5430,4G内存、Linux服务器运行该引擎,大约每秒处理200个URL,速度性能达到设计要求;正确性试验中,6 910条测试记录,命中6 450条,错误460条。其中,误判12,漏判448,具体数据如表1。
4结语
本文提出并实现了一种高效的基于页面特征的反钓鱼识别引擎方案,通过原型系统实现并验证了匹配算法。实验表明,该系统具有较高的正确率以及较低的误判率和漏判率,在追求高精度的同时保证了运行高效率。克服了单纯依靠黑名单机制的被动识别,也避免了之前反钓鱼方案仅仅关注用户桌面的问题,可以有效识别出大部分钓鱼站点,正确率超过90%,基本达到了预期设计要求。
参考文献参考文献:
[1]APWG.Phishing activity trends report 4th quarter 2009[EB/OL].http://www.anti-phishing.com/reports/APWG_GlobalPhishingSurvey2H2009.pdf.
[2]L CRANOR,S EGELMAN,J HONG,et al.Phinding phish: evaluating antiphishing tools[J].Proceedings of The 14th Annual Network and Distributed System Security Symposium (NDSS '07),San Diego,CA,28 February2 March,2007.
[3]A BERGHOLZ,J H CHANG,G PAA,et al.Improved phishing detection using modelbased features[J].Proceedings of the Conference on Email and AntiSpam (CEAS),Mountain View,CA,USA,2008.
[4]GOOGLE INC.Google safe browsing for firefox[EB/OL].http://www.google.com/tools/firefox/safebrowsing/2010.
[5]N CHOU,R LEDESMA,Y TERAGUCHI,et al.Clientside defense against webbased identity theft[J].Proceedings of The 11th Annual Network and Distributed System Security Symposium (NDSS '04),San Diego,CA February,2004.
[6]J MA,L K SAUL,S SAVAGE,et al.Beyond blacklists: learning to detect malicious web sites from suspicious URLs[J].KDD'09: Proceedings of the 15th ACM SIGKDD international conference on Knowledge discovery and data mining,JuneJuly 2009:12451254.
[7]S GARERA,N PROVOS,M CHEW,et al.A framework for detection and measurement of phishing attacks[J].Proceedings of the 2007 ACM Workshop on Recurring Malcode,2007:18.
[8]G XIANG,J I HONG.A Hybrid phish detection approach by identity discovery and keywords retrieval[J].Proceedings of the 18th international conference on World Wide Web(WWW '09),New York,NY,USA,2009:571580.
责任编辑(责任编辑:杜能钢)
猜你喜欢
工会博览(2023年27期)2023-10-24
中国特种设备安全(2022年2期)2022-07-08
科学大众(中学)(2019年2期)2019-04-08
中国生殖健康(2019年10期)2019-01-07
信息安全研究(2018年12期)2018-12-29
小学生必读(中年级版)(2018年4期)2018-07-05
湖北警官学院学报(2017年3期)2017-06-21
信息安全与通信保密(2016年3期)2016-08-23
互联网天地(2016年2期)2016-05-04
互联网天地(2016年1期)2016-05-04
