
Hadoop集群中作业调度研究
2015-04-30 12:53燕明磊
软件导刊 2015年4期
燕明磊
摘要摘要:Hadoop是目前应用最广泛的分布式框架,作业调度是其重要环节,它直接关系到集群的性能与资源利用率。研究了作业调度流程、作业调度策略模式,对Hadoop自带的3种调度器的设计要点与配置方法进行了探讨。
关键词关键词:Hadoop; 作业调度; 调度器
DOIDOI:10.11907/rjdk.1431066
中图分类号:TP301
文献标识码:A文章编号文章编号:16727800(2015)004000102
0引言
随着云计算的兴起和大数据[1]时代的到来,传统的数据处理方法在系统扩展性、复杂应用适用性、海量数据处理速度与存储等方面均遇到了很大的瓶颈问题,已经越来越难以适应新应用的要求,而这些瓶颈问题正是分布式系统所擅长的。Apache Hadoop[2]是一个开源、高效的分布式平台,它运用一切可以利用的资源,以“云”的形式解决大型复杂计算问题,同时还可以满足每个用户的需求。Hadoop是基于Java语言的分布式密集数据处理和数据分析软件框架,是一种低成本处理的大数据平台。
1Hadoop平台
Hadoop有两大核心框架:分布式文件系统HDFS和分布式计算框架Map/Reduce。HDFS是一个高可靠、透明、支持并发与容错的文件系统,基于主从结构设计,由NameNode和DataNode共同完成,其中数据以数据块(block)的形式存储,NameNode主要负责数据块元数据的存储及数据块的动态信息,DataNode负责数据块的存储。HDFS是Map/Reduce的存储基础。Map/Reduce[3]是并行处理大数据的计算框架,简单说就是任务的合成与分解。Hadoop的Map/Reduce也是一种主从结构设计,由JobTracker和TaskTracker两部分组成。JobTracker是主服务节点,其任务之一是负责作业的切分与任务的调度分配;TaskTracker是从节点,主要负责任务的执行。
2Hadoop作业调度
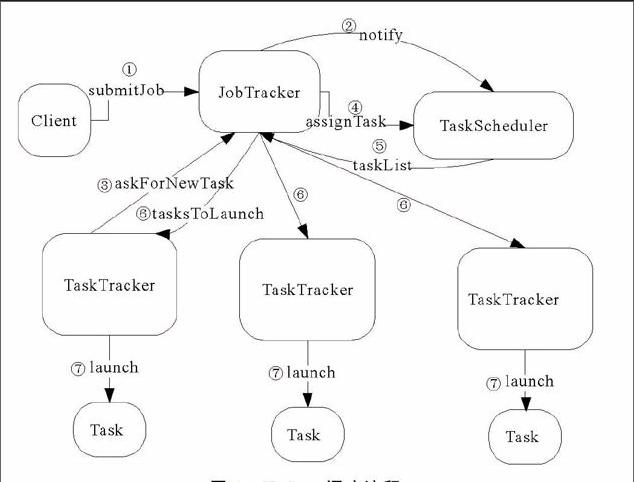
JobTracker服务于整个Map/Reduce计算框架,负责整个集群的作业控制和资源管理。作业控制主要是监控作业的状态,在任务调度时提供调度依据。作业调度是影响Hadoop集群性能的重要方面,直接决定了作业执行效率和集群资源利用率。作业调度由JobTracker节点上任务调度模块完成,调度流程见图1。
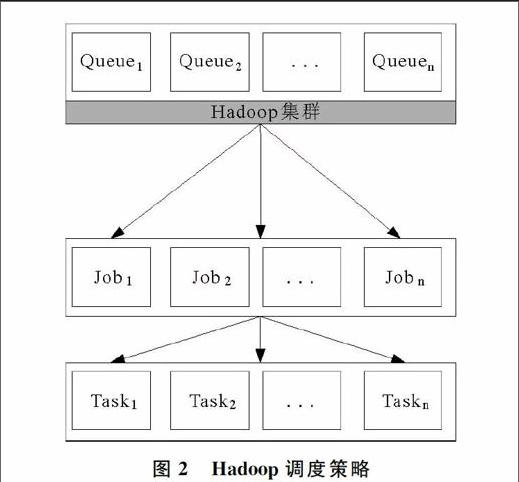
Hadoop作业调度采用三级策略模式[4]。Hadoop将作业执行过程分为Map阶段和Reduce阶段,分别对应Map任务和Reduce任务。这些任务被分配在集群节点的任务槽(slot)上执行,任务槽是节点资源的一种简化表示形式,每个节点根据计算资源配置有一系列的Map槽和Reduce槽,典型的配置是节点的每个CPU配置一个槽,调度器的功能就是为任何空闲的slot分配任务。所有调度器采用三级策略,即为空闲的slot依次选取队列、作业、任务。
3Hadoop调度方法
Hadoop有3种调度器:批处理调度器FIFO及两个多用户调度器Fair Scheduler和Capacity Scheduler,本文重点研究这3种调度器。
3.1FIFO调度
FIFO是默认的调度方式,该调度将所有作业都提交到JobQueue队列, JobTracker先按照作业优先级高低,再按照提交时间的先后顺序执行作业。Hadoop中只有一个作业队列,被提交的作业按照先后顺序在作业队列中排队,新来的作业排在队尾。一个作业运行完后,总是从队首进行下一个作业。这种调度策略的优点是简单、易于实现,减轻了Jobtracker的负担。缺点是对所有作业都一视同仁,没有考虑到作业的紧迫程度,因而对小作业的运行不利。
3.2Fair调度
Fair调度适用于多用户情形。算法设计思想是当集群中多个用户提交作业时,为了保证公平性,调度器为每个用户或组分配一个资源池,资源池里的每个作业都会按照其作业权重分配最小的资源共享量,以保证每个作业都能得到执行。当集群中的某个节点出现空闲的slot时,则选择已获得的资源量和理论上应获得的资源量的差值最大的作业来执行,以保证公平。与FIFO相比,它支持多用户多队列、资源公平共享、保证最小共享量、支持时间片抢占、限制作业并发量、防止中间数据塞满硬盘、动态调整各个资源池的资源量等,以保证调度的公平。
3.3Capacity调度
Capacity调度同样支持多用户。其设计思想是支持多个队列,每个队列可配置一定的资源量,采用FIFO调度策略。为了防止同一用户的作业独占队列资源,该调度器会对同一用户提交的作业所占资源量进行限定。调度时,首先计算每个队列中正在运行的任务数与其应该分得的计算资源比值,选择该比值最小的队列;然后按照作业优先级和提交时间顺序选择,同时考虑用户资源量限制和内存限制。该调度器的特点是保证计算能力、资源分配灵活、支持优先级、支持多重租赁、支持资源密集型作业,允许作业使用的资源量高于默认值。
4Hadoop调度器设计
随着各种应用需求的提升,已有的调度器已很难适应需求的变化,因此调度器设计也要升级。Hadoop中任务调度器被设计成一个可插拔的模块,设计从三方面考虑:①编写JobInProgressListener;②编写调度器类,继承抽象类TaskScheduler;③配置并启用Hadoop调度器。
编写JobInProgressListener抽象类:
abstract Class JobInProgressListener throws IOException {
public abstract void JobAdded(JobInProgress job);
public abstract void JobRemoved (JobInProgress job);
public abstract void JobUpdated(JobChangeEvent event);
}
配置并启用Hadoop调度器:
5结语
Hadoop作业调度的研究对于集群性能的提升具有重要意义。由于Hadoop使用了单JobTracker进行作业调度,对于Hadoop MapReduce计算架构而言,提交的大量作业以及大规模的TaskTracker分布必将给JobTracker带来巨大的工作压力,因此运行的调度算法一定不能过于复杂。此外单JobTracker直接影响了Hadoop集群的可用性,一旦JobTracker失效或者宕机,那么整个集群将崩溃。因此,今后的Hadoop集群作业调度可能由多个JobTracker协同完成,相关的JobTracker分布式作业调度和资源管理算法将是下一个研究重点。
参考文献参考文献:
[1]王珊,王会举,覃雄派,等. 架构大数据:挑战、现状与展望[J]. 计算机学报 2011,34(10):17411752.
[2]APACHE HADOOP.Hadoop[EB/OL]. http://hadoop.apache.org.
[3]李建江,崔健,王聃,等. MapReduce并行编程模型研究综述[J].电子学报, 2011,39(11):26352642.
[4][美]TOM WHITE. Hadoop权威指南[M].第2版. 北京:清华大学出版社,2011.
责任编辑(责任编辑:杜能钢)
