
基于微博交互信息的社交网络推荐算法
2015-04-30 13:19周磊覃俊刘晶
软件导刊 2015年4期
周磊 覃俊 刘晶
摘要摘要:微博作为近年来的热门社交网络平台,其用户行为、兴趣模型及个性化推荐深受国内外学者关注。针对微博社交网络的弱关系特点,结合用户实时交互信息与用户基本信息,提出一种综合考虑用户基本信息与用户交互信息的用户相似度计算方法;进而在UserCF算法的基础上,提出一种基于微博交互信息的推荐算法。该算法考虑了微博平台的弱连接关系特点,能有效针对微博类社交网络进行用户推荐。通过实际社交数据集实验证明,该算法具有良好的执行效率与推荐效果。
关键词关键词:社交网络;微博;弱关系;交互信息;推荐算法
DOIDOI:10.11907/rjdk.1431068
中图分类号:TP312
文献标识码:A文章编号文章编号:16727800(2015)004006304
0引言
近年来,随着网络技术的飞速发展,各种新媒体,尤其是社交媒体技术犹如雨后春笋般涌现,社交网络服务(Social Networks Services,SNS)逐渐走进人们的视线并为大家所熟知。以Twitter、新浪微博为代表的社交网络微博服务(Microblog)以其及时便捷、受众面广等传播优势而成为主要的社交网络形态。
微博,即微型博客的简称,是一个基于用户关系的信息分享、传播及获取的平台。用户可以利用无线网络、有线网络实现全方位通信,实现Web页面、手机、IM接受和信息发送[1]。信息分享的即时性作为微博的独特之处,在服务用户的同时也为用户带来了一定的影响。从实际角度来看,即时性是为了让人们尽可能快地展示生活中的点点滴滴。但随着微博的发展,微博用户和信息的爆炸式增长,导致信息泛滥成灾,在这些重复以及过载的信息中,微博用户很难找到自己感兴趣的用户,并定位感兴趣的信息。
面对海量信息,解决信息过载问题的推荐系统应运而生,因其显著的推荐效果被广泛应用于电子商务等领域,作为推荐系统核心组成部分的推荐算法,受到学者们的关注,各种推荐算法层出不穷。虽然通过互粉、联系人、手机通讯录等真实社交信息进行推荐的方法能达到很好的效果[2],但其为用户推荐的多为强关系链接的用户。经济社会学家马克·格兰诺维特提出:相对于强关系而言,弱关系有助于传递新信息。针对微博这种弱关系型社交网络,弱关系的推荐比强关系更有价值。
因此,研究基于微博平台的弱关系用户推荐算法尤为重要。从用户角度看,它可以帮助用户构建起新的社会关系,使用户扩大交际圈;从微博平台角度看,它增强了用户之间的交互性,提高了用户对平台的信任度与依赖度。
本文旨在解决微博社交网络平台用户进行用户推荐时能顾及到弱连接用户。对此,本文综合使用用户实时交互信息与用户基本信息来计算用户相似度,在UserCF算法基础上,提出一种基于用户交互的BOI(BaseonInteraction)算法。通过采集实际社交网络中的数据对其进行验证,同时分析各参数对推荐效果的影响。
1研究综述
目前,对于用户推荐的研究很多,研究方向主要有:基于内容的推荐方法、协同过滤推荐方法、聚类技术、关联技术、混合推荐等。
协同过滤算法是目前应用最广泛也是最受欢迎的推荐算法,它利用用户爱好之间的相似性来进行推荐[3],不依赖物品的内容,利用用户对物品的偏好信息,一般以打分的形式进行评价[4]。不过其并不能直接应用类似于微博这种弱关系社交网络的好友推荐,因为在微博类社交网络中,没有物品与评分的概念。此外,由于微博类社交网络的数据稀疏性,现有协同过滤算法的推荐效果并不理想。
关于利用用户的内容进行推荐方面,赵岩露[5]等结合微博数据集分析用户的个人特征,以此提高个性化推荐系统的质量。袁园等通过微博关注数据,挖掘用户关注对象的分布及对象间的关联性[6]。Shen D[7]和Zheng Y等[8]分析用户关注的blog或曾浏览的信息得出用户的兴趣模型,由模型计算得出用户兴趣相似度进而发现潜在好友。Wu Z等[9]提出了一种根据用户的长相来进行推荐的算法。于海群等[10]通过分析社交网络中用户的话题偏好提出了基于用户话题偏好的推荐算法。关于基于用户的交互推荐方面,Lo S等[11]提出了按照好友之间的互动次数衡量两者的亲密度,互动次数越多说明两者之间关系越好,如果两个用户对第三个用户亲密度都高则说明他们与第三个用户有很好的关系,这样他们就可能建立起新的好友关系。Chin A[12]根据任意两个用户之间的手机交互次数来进行推荐。
当前,社交网络有一个功能是“你可能认识的人”,它是基于“friend of friend”算法进行的推荐。该算法的思想是:如果A的很多好友是B的好友,那么A也可能会是B的好友。这种算法推荐效果很显著,但是只能帮用户寻找没有添加的强关系。
2BOI推荐算法
BOI算法旨在根据弱关系社交网络中的用户交互信息,为用户推荐其可能感兴趣的关注对象。通过综合分析用户交互信息与用户基本信息,提高弱关系社交网络平台的推荐效果。
定义1:用户数据集User={u1,u2,u3…uN} ,ux为用户x的用户ID值。User表示原爬虫算法获取的新浪微博用户数据集(后简称原始数据集)中根据uid统计出的用户ID集。
(1)根据用户数据集User与用户微博集Tweet计算用户之间的兴趣度,得到用户兴趣度矩阵R。
(2)对于任意待推荐的用户u,根据用户兴趣度矩阵R计算其中非零元素对应的用户与带推荐用户u的相似度,得到用户交互相似度矩阵S。
(3)根据用户兴趣度矩阵R与用户交互相似度矩阵S计算推荐度,并对结果从高到低排序,去前N个数据,得到排序结果C。
(4)按照排序结果C产生最终的推荐结果列表L。(5)算法结束。
3实验及分析
3.1实验对象和实验数据
为验证本文算法的有效性,将真实的社交网络平台用户数据作为实验对象。该数据根据新浪微博平台的开放API接口,由微博爬虫以一组微博用户作为种子节点,根据雪球采集策略采集的微博用户个人数据,通过清理、整合、变化3个步骤对数据集进行处理,将处理后的30万条用户关注数据集以及近50万条微博内容,然后将其分为多组进行实验,最终实验结果为多组实验数据的平均值。每组约包含500个用户与近2万条微博内容。代码由Python和Java实现。实验代码运行于Lenovo Y460上,Python版本为Python 3.4.1,jdk版本1.7。
实验参照的算法有:①传统的Top-N相似的协同过滤算法(CF);②“Friend-of-Friend”算法;③Content-plus-Link ( CplusL )算法。其中,CF算法为基于用户的协同过滤(UserCF),用户相似度采用Jaccard公式进行计算,最终推荐结果采用Top-N推荐。
3.2实验评估指标
本文使用的评估指标为当前常用的3个评价推荐算法的指标:准确率(precision)、召回率(recall)和Fmeasure[13],及其算法运行效率。准确率和召回率是用来反映查询结果的两个重要指标。其中:准确率指检索的相关信息量占检索出的总信息量的百分比,用来衡量检索系统的信噪比;召回率指检索出的相关信息量占相关信息量的百分比,衡量检索系统的成功度;Fmeasure为准确率(precision)与召回率(recall)的调和平均值,该值越高说明其推荐的综合效果越好。
3.3实验结果与分析
3.3.1算法效率测试
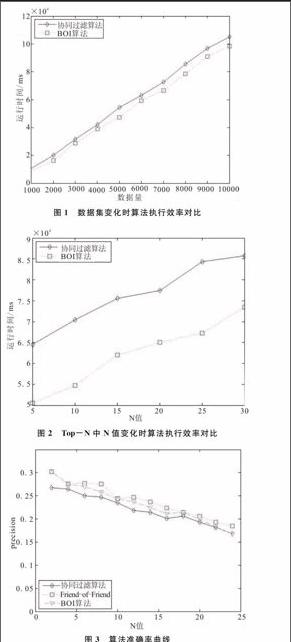
设置Top-N中N值为20,数据集分别用1 000、2 000、3 000、4 000、5 000、6 000、7 000、8 000、9 000和10 000条数据记录进行测试。比较传统的Top-N相似的协同过滤算法与本文的基于用户交互的BOI算法在不同数据集下运行的效率。算法运行效率如图1所示。当数据集选取6 000条记录,Top-N中N值为5、10、15、20、25和30时,其算法运行效率如图2所示。
从图1、图2可以看出,在不同大小的数据集以及在为用户推荐不同人数方面,本文基于用户交互的BOI算法所用时间均小于传统的Top-N相似的协同过滤算法,由此可见本算法具有着较好的时间性能。
3.3.2算法准确性测试
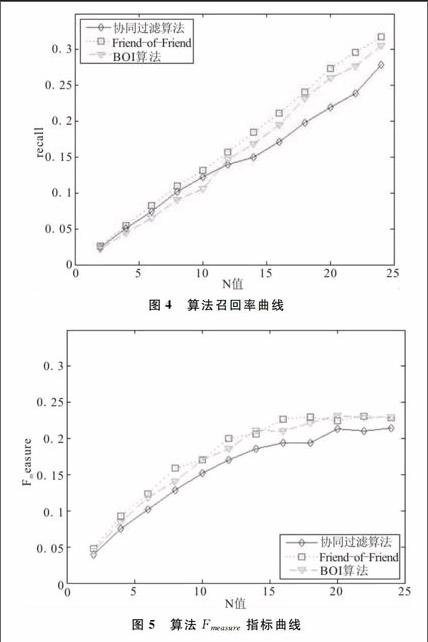
分别选取多个N值对传统的Top-N相似的协同过滤算法、 “Friend-of-Friend”算法以及本文基于用户交互的BOI算法进行对比实验。“Friend-of-Friend”算法的阈值设置为20,设置Top-N中N={2,4,6,8,10,12, 14, 16, 18, 20,22,24},测试结果如图3-图5所示。其中,图3为3个算法的准确率曲线,图4为3个算法的召回率曲线,图5为3个算法的Fmeasure指标曲线。
可以看出,本文基于用户交互的BOI算法在推荐准确性方面介于传统Top-N相似的协同过滤算法与“Friend-of-Friend”算法之间。如图5所示,本文算法与“Friend-of-Friend”算法的Fmeasure曲线走势十分接近且在数值上相差也较小,都具有着较好的准确度,但本文算法在为用户推荐潜在的弱关系好友方面较强。从人类现实社会学角度来看,为用户推荐出潜在的“志同道合”的好友,也有重大意义与价值。4结语
基于微博平台的弱关系用户推荐算法研究具有重要意义。从用户角度看,它可以帮助用户构建起新的社会关系,使用户扩大自己的交际圈;从微博平台角度看,它扩大、增强了用户之间的交互性,提高了用户对平台的信任度与依赖度。本文综合考虑用户实时交互信息与用户的基本信息来计算用户相似度。在UserCF算法的基础上,
提出一种基于用户交互的BOI(BaseonInteraction)算法。
通过真实的实验数据集,验证了其具有较高的准确度与效率,通过调整各项参数分析了其对推荐结果的影响。
后续研究需引入更具智能与有效的反馈机制,通过用户的反馈对推荐结果进行动态优化。同时,希望能引进更多的用户信息,并且能做到分布式并行化处理,以减少单一系统的负载,同时提高其算法执行效率。
参考文献参考文献:
[1]文瑞.微博之识[J]. 软件工程师,2009(12):1020.
[2]CHEN J, GEYER W, DUGAN C,et al.Proceedings of the 27th International Conference on Human Foctors in Computing Sysrems[C]. New York, NK. USA, 2009: 201210.
[3]SARWAR BM, KARYPIS G, KONSTAN J A.Analysis of recommendation algorithms for Proceedings of the 2nd ACM Conference on Electronic Commerce ( EC00)[C]. Minneapolis, MN, USA, 2000:158167.
[4]LINDEN GREG, SMITH BRENT, YORK JEREMY.AMAZON.com recommendations:item to item collaborative filtering[J]. IEEE Internet Computing, 2003, 7(1): 7680.
[5]赵岩露,王晶,沈奇威. 基于特征分析的微博用户兴趣发现算法[J].电信工程技术与标准化,2012,25(11): 7983.
[6]袁园,孙霄凌,朱庆华. 微博用户关注兴趣的社会网络分析[J]. 现代图书情报技术,2012(2): 6875.
[7]SHEN D, SUN J T, YANG Q, et al.Latent friend mining from blog data[C].Data Mining, 2006.ICDM'06. Sixth International Conference on. IEEE, 2006: 552561.
[8]ZHENG Y, CHEN Y, XIE X,et al.GeoLife2.0:a locationbased social networking service[C].Mobile Data Management: Systems, Services and Middleware, 2009. MDMf09. Tenth International Conference on. IEEE, 2009: 357358.
[9]WU Z, JIANG S, HUANG Q. Friend recommendation according to appearances on photos[C].Proceedings of the 17th ACM international conference on Multimedia. ACM, 2009:987988.
[10]于海群,刘万军,邱云飞.基于用户话题偏好的社会网络二级人脉推荐[J].计算机应用,2012,32(5): 13661370.
[11]LO S,LIN C. WmrA graphbased algorithm for friend recommendation[C].Proceedings of the 2006 IEEEAVIC/ACM International Conference on Web Intelligence. IEEE Computer Society, 2006:121128.
[12]CHIN A.Finding cohesive subgroups and relevant members in the nokia friend view mobile social network[C].Computational Science and Engineering,2009.CSEf09. International Conference on. IEEE, 2009(4):278283.
[13]陈克韩,韩盼盼,吴健.基于用户聚类的易购社交网络推荐算法[J].计算机学报,2013,36(2): 349359.
责任编辑(责任编辑:陈福时)
猜你喜欢
教育传媒研究(2023年6期)2023-11-23
人间(2016年26期)2016-11-03
人民论坛(2016年27期)2016-10-14
