
激励函数可学习神经网络
2015-06-06 10:46杨少明王雅琳王美蕴何海明李勇刚
服装学报 2015年6期
杨少明,王雅琳,王美蕴,何海明,李勇刚
(中南大学信息科学与工程学院,湖南长沙 410083)
激励函数可学习神经网络
杨少明,王雅琳*,王美蕴,何海明,李勇刚
(中南大学信息科学与工程学院,湖南长沙 410083)
提出了一种激励函数可学习神经网络,其神经元函数不固定,通常是任何线性无关的基函数的线性组合,通过调整神经元中基函数的系数即可达到网络学习的目的。为了结构优化方便,将神经元输出的多维空间映射为一维空间后输入给下层神经元。根据网络的特点,提出了两种无需迭代的网络参数快速学习算法实现网络训练。通过3个实例进行仿真实验,结果表明所设计神经网络的逼近能力强,参数学习速度极快。
神经网络;激励函数;快速学习方法
神经网络尤其是BP神经网络由于其结构简单、并行处理能力强、非线性逼近能力好等特点,已经广泛应用于各种领域。但是,BP算法是采用非线性规划的快速下降法,即沿着误差函数的负梯度方向修改权值,因此存在学习效率低、收敛速度过慢和容易陷入局部最优等问题。针对BP神经网络算法的缺陷,许多研究人员在学习率的改进[1-3];网络初始权值选取的改进[4-5];网络模型结构的优化[6-8];进化算法优化网络参数和结构[9-11]以及其他方面[12-16]做了大量的研究工作。
泛函网络[17-18]是Enrique Castillo于1998年提出的一种网络,是对标准神经网络的推广。泛函网络是基于泛函方程的,并且是一种参数化建模方法。泛函网络的建立需要根据专业领域的知识去衍生各种泛函方程,从而对泛函网络的模型进行有根据的假设。泛函网络处理的是一般泛函模型,神经元之间无权值连接,神经元函数可以是多元的,通常是给定基函数簇的线性组合,且神经元函数不是固定的,是可学习的。泛函网络已经成功应用于线性与非线性回归、非线性系统辨识、微分、差分方程的求解等问题。泛函网络不仅可以解决神经网络可以解决的问题,还能处理神经网络无法解决的问题,泛函网络在某些方面是优于神经网络的[18]。
泛函网络在黑箱建模时,与神经网络一样,存在着网络结构确定困难的问题。在绝大部分情况下,初始给定的网络结构都不是最合理的,需要在网络完全学习或是部分学习之后优化网络的结构。如果网络结构有冗余或者是达不到预期的精度,那么在结构优化时需要根据网络的学习情况适度删减或者增加神经元的个数等。对于一般的泛函网络而言,其神经元函数的输入参数是一个多维向量,这就表明,它的网络结构在删减时势必会出现一些不可避免的问题。如上一层神经元的删除,会直接影响下一层神经元的输入向量的维数,造成与神经元函数不匹配,给网络运行造成困难。
针对这个问题,文中提出了一种激励函数可学习神经网络(简称可学习神经网络),把泛函神经元输出的多维空间映射至一维空间后输入给下一层的神经元,并采用带偏置的线性组合形式表示这种映射关系。针对新设计的网络,文中给出了两种网络参数学习算法,并通过实例验证了网络的可行性与有效性。其中,学习算法二引用黄广斌等[14]提出的极限学习机(ELM)算法[13-16],不同的是,ELM算法中隐层激励函数单一固定,而文中提出的可学习神经网络,隐层激励函数的种类和数量都不固定,可学习调整。经实验仿真,所提网络与ELM相比学习速度相近,拟合效果更好。
1 激励函数可学习神经网络
1.1 神经元模型
激励函数可学习神经网络的神经元函数是任意线性无关的基函数簇的线性组合,每个神经元的输入都是上一层网络神经元(或者输入节点)所有输出的线性累加和,每个神经元(或者输入节点)的输出都是下一层神经元的输入(或者是网络模型的输出)。其神经元模型如图1所示。
X=[x1,x2,…,xn]是神经元的输入,y是神经元的输出:

神经元函数f可以是任意非线性相关基函数的线性组合:
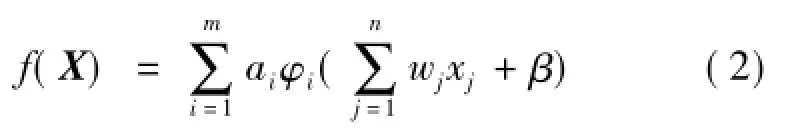
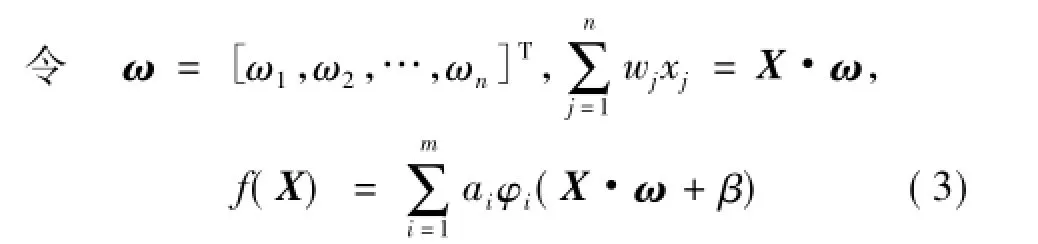
其中,ω和β为随机选择的神经元参数,无需调整; {φ1,φ2,…,φm}为任意的基函数簇,如三角函数簇{sin(x),sin(2x),sin(3x),…},对数函数簇{ln|x|+1,ln|x|+2,ln|x|+3,…},多项式函数簇{1,x,x2,x3,…}等,也可以是混合函数簇,如{sin(x),cos(x),ex,ln(|x|+1),sinh(x),…}。通常是根据实际问题选择合适的函数簇,并在网络学习的过程中,根据学习情况,不断进行调整。ai(i= 1,2,…,m)为网络的参数,主要是通过对它们的学习实现对网络的逼近,达到期望的精度。

图1 激励函数可学习神经网络神经元模型Fig.1 Neuron model of the active function learning neural network
1.2 网络的一般模型
激励函数可学习神经网络的一般网络模型如图2所示。

图2 激励函数可学习神经网络一般模型Fig.2 Generalmodel of the active function learning neural netw ork
该网络模型由k个输入,h个输出,一个输入层,d个隐层,一个输出层。输入层k个节点,节点的主要功能是输入信息;隐层和输出层神经元都是任意线性无关基函数的线性组合。
模型输入为X=[x1,x2,…,xk],输出为Y=[y1,y2,…,yh],隐层i(i=d+1时表示输出层)的神经元个数是pi,第j个神经元的函数为fi,j,输入为xi,j,输出为zi,j,基函数个数为mi,权值矩阵为ωi,j,偏置为βi,j。
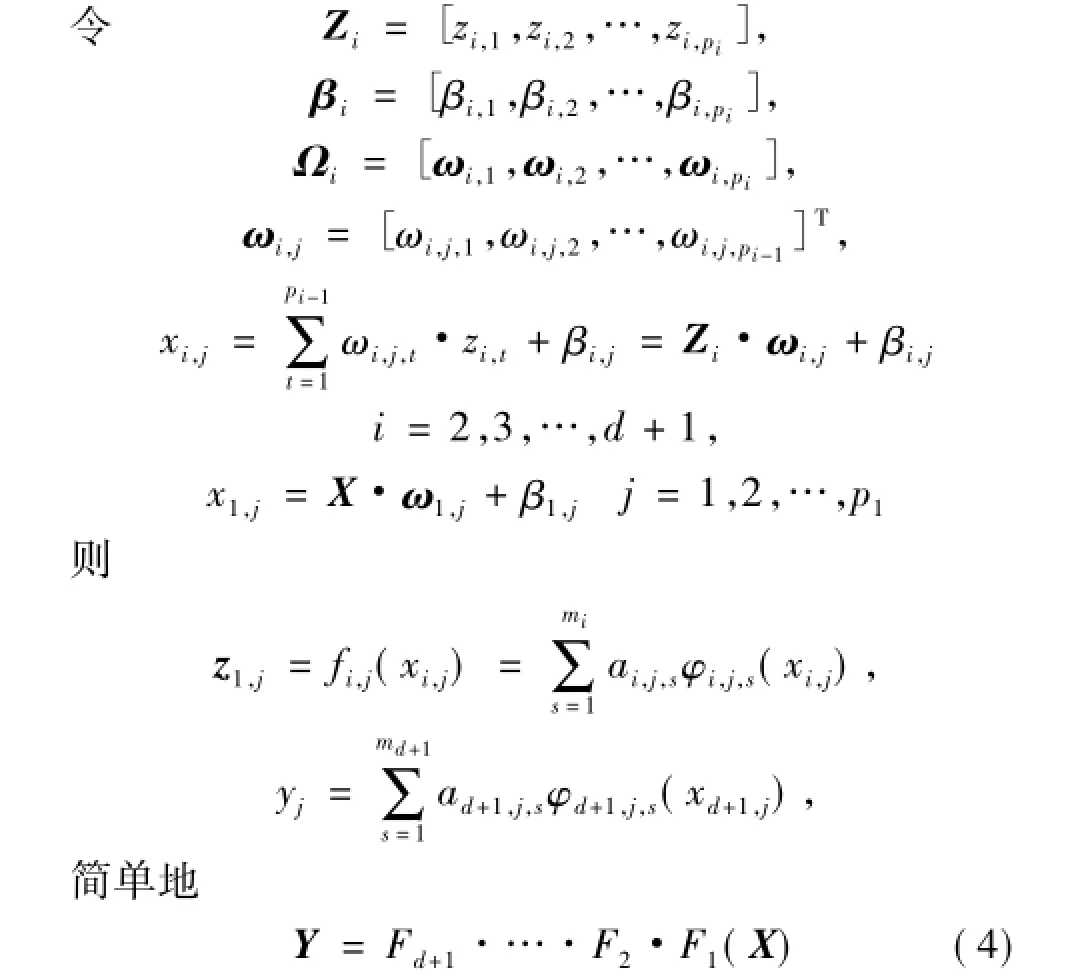
1.3 网络的学习算法
以输入为X=[x1,x2,…,xk],输出为y的多输入单输出单隐层激励函数可学习神经网络为例,网络模型如图3所示。

图3 多输入单输出网络模型Fig.3 Mu ltip le input single output network model
隐层有p个神经元,第i个神经元函数是fi,fi是可以学习的,通常表示为一系列基函数的线性组合:

其中:m为神经元基函数的个数,
si=X·ωi+βi,ωi=[ωi,1,ωi,2,…,ωi,k]T。
输出神经元的函数存在逆函数时也可以表示为基函数的线性组合:

则模型的输出为

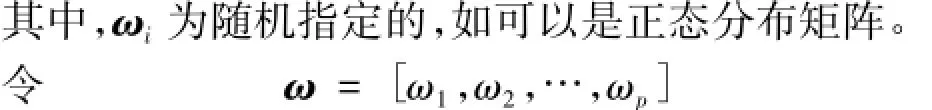


容易知道,在输出神经元函数给定且存在逆函数时,其隐层参数矩阵A可以通过求解隐层神经元输出矩阵的广义逆得到。这种学习算法具有简单、无需迭代、精度好等特点。
2 应用实例
2.1 实例1
Hénon混沌系统为

用图5所示的网络(模型隐层神经元个数为p)对100组Hénon序列进行学习,学习结束后再用100组序列做预测。网络隐层权值和偏置是按正态分布随机选择的,神经元函数的选择、训练误差和测试误差见表1(文中误差均指均方根误差)。
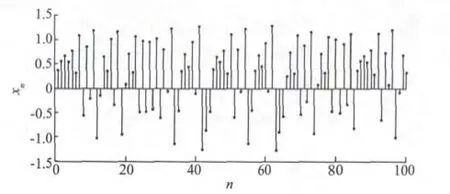
图4 Hénon混沌序列Fig.4 Hénon Chaotic sequence

图5 Hénon序列的网络学习Fig.5 Learning on the Hénon sequence

表1 对Hénon序列学习的网络模型参数和学习情况Tab.1 Netw ork model param eters and learning on the Hénon sequence
由表1可知,文所提出的激励函数可学习神经网络神经元基函数序列不同时对样本的学习能力是不同的,可以通过改变神经元的基函数类型提高网络的精度。神经元基函数序列选取合适的话,网络的逼近效果会提高很多。
2.2 实例2
对于函数

在自变量x∈[-20,20]范围内,随机选取1 000个样本点,其中500个作为训练数据,另外500个作为测试数据。用图5所示的激励函数可学习神经网络逼近sinc函数,结果见表2。

表2 对sinc函数学习的网络模型参数和学习情况Tab.2 Network m odel parameters and learning on the sinc function
由表2可知,文中所提的激励函数可学习神经网络对sinc函数的学习精度很高,完全可以满足精度要求,且不同基函数序列对sinc函数的学习情况也是有很大差别的。
在中国综合国力日益强大、海外投资逐年增长的大趋势下,中国不应当担心赋予公司双重国籍可能引起的更多外交保护压力。若中国仍持上述保守立场,会阻碍中国向开拓国际市场的中国公司实施外交保护。
分别用文中单隐层激励函数可学习神经网络和基于ELM算法的单隐层神经网络逼近sinc函数。其中,两种网络的隐层神经元的权值和阈值均是随机选取且相等的。
1)可学习神经网络神经元基函数序列取
{sin(x+1),sin(2x+2),sin(3x+3)},基于ELM方法的单隐层神经网络的激励函数取Sigmoid函数

网络学习情况见表3。

表3 两种网络模型对sinc函数学习情况1Tab.3 First learning of two d ifferent netw orks on the sinc function
2)可学习神经网络神经元基函数序列取
{(1+e-0.25x)-1,(1+e-0.5x)-1,(1+e-0.75x)-1},基于ELM方法的单隐层神经网络的激励函数取Sigmoid函数

学习情况见表4所示。

表4 两种网络模型对sinc函数学习情况2Tab.4 Second learning of two different networks on the sinc function
2.3 实例3
分别比较了两种网络在两个实际问题数据集的表现(被比较的两个网络隐层权值和偏置均是随机选取的且相等)。
2.3.1 对Abalone问题的学习
1)可学习神经网络的激励函数序列为

ELM网络的激励函数取Sigmoid函数

学习情况如表5所示。

表5 两种网络模型的对Abalone问题的学习情况1Tab.5 First learning of two different networks on the Abalone p roblem
2)可学习神经网络的激励函数序列为

学习情况如表6所示。
2.3.2 对Machine CPU问题的学习
1)可学习神经网络的激励函数序列为
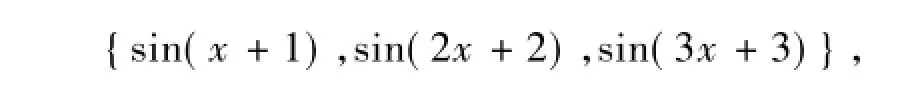
ELM网络的激励函数取Sigmoid函数
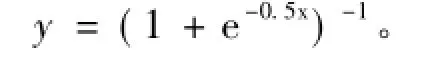
学习情况见表7。

表6 两种网络模型对Abalone问题的学习情况2Tab.6 Second learning of two differen t networks on the Abalone p rob lem

表7 两种网络模型的对M achine CPU问题的学习情况1Tab.7 First learning of tw o d ifferent networks on the M achine CPU p roblem
2)可学习神经网络的激励函数序列为

ELM网络的激励函数取Sigmoid函数

学习情况见表8。由表3~表8可知,在网络固定参数(隐层神经元个数、权值和偏置)随机选取且相等的情况下,与ELM一样,参数学习都不需要迭代,速度非常快,但是学习精度要比ELM高。

表8 两种网络模型的对M achine CPU问题的学习情况2Tab.8 Second learning of two d ifferen t networks on the M achine CPU p roblem
3 结语
文中在分析了神经网络和泛函网络各自的特点基础上,提出了一种激励函数可学习的神经网络,通过改变神经元函数,使网络参数学习快、结构优化方便。由仿真结果可知,所提网络的逼近能力强,且由于参数学习无需迭代,大大节省了网络学习的时间。另外,在神经元个数相同且隐层参数均随机选择且相等的情况下,所提激励函数可学习神经网络与ELM相比,参数学习速度相近,但是逼近能力更强。
值得提出的是,文中提出这个网络模型是为了方便模型结构的优化,后续研究将进一步探讨如何实现激励函数可学习神经网络的修剪式结构优化。
[1]Sin-Chun Ng,Chi-Chung Cheung,Shu-hung Leung.Magnified gradient function with deterministic weightmodification in adaptive learning[J].IEEE Transactions on Neural Networks,2004,15(6):1411-1423.
[2]Zweiri Y H,Whidborne J F,Althoefer K,et al.A new three-term backpropagation algorithm with convergence analysis[C]// Proceedings of ICRA'02.IEEE International Conference on Robotics and Automation.Washington DC:IEEE,2002,4:3882-3887.
[3]Zweiri Y H,Seneviratne L D,Althoefer K.Stability analysis of a three-term backpropagation algorithm[J].Neural Networks,2005,18(10):1341-1347.
[4]Jim Y F Yam,Tommy W SChow.A weight initialization method for improving training speed in feedforward neural network[J].Neurocomputing,2000,30(1):219-232.
[5]Yat-Fung Yam,Chi-Tat Leung,Peter K S Tam,et al.An independent component analysis based weight initialization method for multilayer perceptrons[J].Neurocomputing,2002,48(1):807-818.
[6]Castellano G,Fanelli A M,Pelillo M.An iterative pruning algorithm for feedforward neural networks[J].IEEE Transactions on Neural Networks,1997,8(3):519-531.
[7]Scott Fahlman,Christian Lebiere.The cascade-correlation learning architecture[J].Advances in Neural Information Processing Systems,1991,2:524-532.
[8]Lauret P,Fock E,Mara T A.A node pruning algorithm based on a Fourier amplitude sensitivity test method[J].IEEE Transactions on Neural Networks,2006,17(2):273-293.
[9]Zhihong Yaoa,Minrui Feia,Kang Lic,et al.Recognition of blue-green algae in lakes using distributive genetic algorithm-based neural networks[J].Neurocomputing,2007,70(4):641-647.
[10]Leung F H F,Lam H K,Ling SH,et al.Tuning of the structure and parameters of a neural network using an improved genetic algorithm[J].IEEE Transactions on Neural Networks,2003,14(1):79-88.
[11]Ehsan Valian,Shahram Mohanna,Saeed Tavakoli.Improved cuckoo search algorithm for feedforward neural network training[J].International Journal of Artificial Intelligence and Applications,2011,2(3):36-43.
[12]Packianather M S,Drake P R,Rowland S H.Optimizing the parameters of multilayered feedforward neural networks through Taguchidesign of experiments[J].Quality and Reliability Engineering International,2000,16(6):461-473.
[13]G B H,Qin-Yu Z,Chee-K S.Extreme learningmachine:theory and applications[J].Neurocomputing,2006,70(1):489-501.
[14]HUANG Guangbin,ZHU Qinyu,Siew C K.Extreme learning machine:a new learning scheme of feedforward neural networks[C]//Proceedings of 2004 IEEE International Joint Conference on Neural Networks.Budapest,Hungary:IEEE,2004,2: 985-990.
[15]YUAN Lan,Yeng Chai Soh,HUANG Guangbin.Constructive hidden nodes selection of extreme learningmachinefor regression[J].Neurocomputing,2010,73(16/18):3193-3199.
[16]WANG Yuguang,CAN Feilong,YUAN Yubo.A study on effectiveness of extreme learningmachine[J].Neuro-Computing,2011,74(16):2483-2490.
[17]Castillo E.Functional networks[J].Neural Processing Letters,1998,7(3):151-159.
[18]Castillo E,Cobo A,Gómez-Nesterkin R,et al.A general framework for functional networks[J].Networks,2000,35(1):70-82.
(责任编辑:邢宝妹)
Active Functions Learning Neural Netw ork
YANG Shaoming,WANG Yalin*,WANG Meiyun,HE Haiming,LIYonggang
(School of Information Science and Engineering,Central South University,Changsha 410083,China)
In this paper,a novel neural network is proposed,whose active functions can be learned.Its active functions are not given and cannot be changed,but can be learned by the problems and could be the linear combination of any linear independent basis functions.The networks could be learned by tuning the coefficients of the basis functions.For the convenience of structure optimization,the input vectors of neurons are alwaysmapped to be scalar variables.In this paper,two quick learning algorithms are proposed for this network which does not need iterative procedures.The results show that this network has good function approximation capacity and fast learning speed.
neural network,active function,quick learning algorithms
TP 183
A
1671-7147(2015)06-0689-06
2015-07-25;
2015-09-28。
国家自然科学基金项目(61273187);国家自然科学基金创新研究群体科学基金项目(61321003)。
杨少明(1990—),男,河南三门峡人,控制科学与工程专业硕士研究生。
*通信作者:王雅琳(1973—),女,广东惠州人,教授,博士生导师。主要从事复杂过程建模、优化与控制研究。Email:ylwang@csu.edu.cn
猜你喜欢
自然杂志(2021年6期)2021-12-23
电子制作(2019年19期)2019-11-23
人民珠江(2019年4期)2019-04-20
现代装饰(2018年5期)2018-05-26
重型机械(2016年1期)2016-03-01
大连工业大学学报(2015年4期)2015-12-11
电源技术(2015年5期)2015-08-22
弹箭与制导学报(2015年1期)2015-03-11
海军航空大学学报(2015年4期)2015-02-27
计算机工程(2014年9期)2014-06-06
