
稀疏LSSVM在4-CBA软测量建模中的应用
2015-06-08 04:26李佳庆
仪表技术与传感器 2015年12期
戎 舟,李佳庆
(南京邮电大学自动化学院,江苏南京 210003)
稀疏LSSVM在4-CBA软测量建模中的应用
戎 舟,李佳庆
(南京邮电大学自动化学院,江苏南京 210003)
针对最小二乘支持向量机(LSSVM)缺失稀疏性问题,采用遗传算法对其模型进行稀疏化。算法思想如下:对LSSVM初始模型的核函数项进行二进制编码,采用遗传算法对二进制串进行寻优,将求得的最优个体解码,“1”代表选取该位置对应样本,“0”代表舍去该位置对应的样本,解码求得的样本集再次建模,重复上述稀疏过程,以每次测试样本相对误差的标准差为依据,当偏差率超过10%,则不再稀疏。将该算法应用于4-CBA(4-羟基苯甲醛)软测量建模过程,结果表明,采用遗传算法进行稀疏化的LSSVM模型,支持向量能稀疏70%左右,在保证预测精度的同时,大大提升了模型的效率。
LSSVM;稀疏化;遗传算法;软测量
0 引言
软测量技术[1-2]源于20世纪70年代Brosilow等提出的推断控制思想,发展至今,由于采用的理论工具和所针对的实际对象的不同,已形成多种软测量方法[3]。支持向量机[4](support vector machine,SVM)是20世纪90年代由Vapnik等提出的一种基于统计学习理论的学习方法,它采用结构风险最小化原则,具有小样本学习能力强、模型泛化性能好、能够处理高维数据的优点。最小二乘支持向量机[5](Least Squares Support Vector Machine,LSSVM)则是基于SVM的一种改进算法。与一般SVM不同的是,LSSVM采用最小二乘线性系统作为损失函数,将传统的SVM直接采用二次规划方法解决分类和函数估计问题转化为求解线性方程问题,降低了计算复杂性,提升了运算速度。作为SVM方法的一个改进型,LSSVM继承了SVM方法的许多优点,但同时也失去了稀疏性。
针对LSSVM的稀疏性问题,文献[6]提出通过修剪支持向量来实现对最小二乘支持向量的稀疏,但该方法必须先求出非稀疏解,解一系列线性方程组的根,增加了算法的复杂性。文献[7]提出了一种基于特征提取的方法,该方法是将分布在原有特征中的分类信息集中到较少数量的特征中,以达到降低样本维数,实现稀疏化的过程,然而,该方法过分依赖于训练样本集的选取,若所选子集并不能代表原始样本数据的特性,将会影响最终预测的效果。文献[8]提出通过在特征空间中寻找样本的最大无关组来解决解的稀疏性问题。该方法对LSSVM参数的选取有着较高的要求,选取不当,将会影响最大无关向量的数目,从而对函数的拟合能力造成影响。
针对上述问题,本文采用遗传算法(genetic algorithm,GA)来实现对LSSVM的稀疏化处理。算法在运行时,采用最优个体保存策略,以保护每代优良个体遗传到下一代时不被破坏[9]。
1 基于遗传算法的LSSVM稀疏化
1.1 遗传算法简介
遗传算法(Genetic Algorithm,GA)的思想最早是20世纪60年代由美国Michigan大学的Holland教授提出的[10]。基本遗传算法包括选择、交叉、变异三种遗传操作[11]。选择操作常用的方法是轮盘赌法,该方法核心思想是个体被选择概率与其适应度值成正比,个体在群体环境中的适应度值越大,则被选中的概率越大,其遗传基因就越容易在种群中扩大;交叉操作是遗传算法的核心,对两个不同个体相同位置上的基因进行交换,从而产生新的个体,交叉操作概率一般选在0.4~0.9之间,过小会让算法变得迟缓,过大则有可能会破坏优良个体;变异操作是让染色体上的某些基因按一定的变异概率发生变化,产生新的个体,变异概率一般选在0.001~0.1之间。
1.2 最小二乘支持向量机
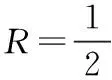
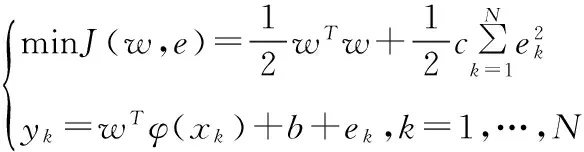
(1)
将拉格朗日法引入上述优化问题的求解,上述优化问题则可转化为如下的二次规划问题:
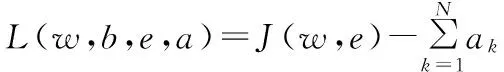
(2)
根据KKT条件可得:
(3)
根据推导方程(3),消去其中的w和e可得如下方程:
(4)
定义核函数K(xi,xj)=φ(xi)·φ(xj),本文采用的核函数是径向基核函数K(xi,xj)=exp{-||xi-xj||2/σ2},其中σ为核参数。根据上式方程,优化问题可转化为求解如下矩阵方程:
(5)
解上述矩阵方程,求得系数a与b,即可得如下LSSVM模型:

(6)
1.3 基于遗传算法的LSSVM稀疏优化过程
通过对GA算法以及对LSSVM稀疏性的分析,本文采用GA算法用于对LSSVM的多次稀疏化过程。对LSSVM模型中的核函数项进行二进制编码,通过选择、交叉、变异操作对种群中个体进行筛选,多次迭代后产生最佳个体,解码得出对应的支持向量,将此支持向量作为新的训练样本集,再次建立LSSVM模型。重复上述稀疏过程,直至测试样本相对误差标准差的偏差率超过10%。
单次稀疏过程是将当前训练样本建立LSSVM模型,对其预测模型中的核函数项进行随机二进制编码,产生初代种群,种群中的任一个个体即为一组核函数项K(x,xk)的随机组合,其中,“1”代表选取该位置对应样本,“0”代表舍弃。采用遗传算法对种群进行寻优,取测试样本误差平方和的倒数作为适应度函数,将求得的最优个体解码,取得新的训练样本集。将新的训练样本集再次进行LSSVM建模,算取测试样本相对误差的标准差,判断是否再次稀疏。
LSSVM模型有两个参数:正则化参数c和核参数σ,它们的选取对模型有着极大的影响,因此在每次产生新的支持向量后都要对其进行寻优处理。本文采用的是网格搜索算法[13],首先,c和σ在[2-7,29]范围上以步进为1进行粗搜,采用K-fold交叉验证方法评价各网点的性能,得到性能最好的两个参数组合bestc0和bestσ0;然后c和σ分别在[bestc0/2,bestc0×2]及[bestσ0/2,bestσ0×2]范围上以步进为0.1再进行细搜,最终最佳参数组合[bestc,bestσ]。
GA-LSSVM算法实现的具体步骤如下:
(1)采集所需样本数据,确定训练样本集和测试样本集;
(2)调用寻优算法对正则化参数c和核参数σ进行参数寻优;
(3)将训练样本集进行LSSVM建模,求出测试样本相对误差的标准差;
(4)对模型中的核函数项K(x,xk)进行二进制编码,产生初始种群,采用GA算法,通过选择、交叉、变异操作对种群中个体进行筛选,多次迭代后得出最优个体;
(5)将(4)中得到的最优个体对照原训练样本解码,选取位置为“1”所对应样本,组成新的训练样本;
(6)将新的训练样本调用寻优算法进行参数寻优,然后对其再次建模得到新模型,用此模型对测试样本集进行预测,算出相对误差的标准差;
(7)求取相对误差标准差的偏差率。若偏差率超过10%,稀疏过程终止,取上一次稀疏结果作为最终的LSSVM模型;否则返回步骤(4);
(8)用最终稀疏后的LSSVM模型对新样本进行预测和分析。
2 实际应用
本文以某化纤厂PTA生产工艺为研究对象,对其中间产物4-CBA(4-羟基苯甲醛)的浓度建立LSSVM预测模型。4-CBA是PTA生产工艺中的主要有色副产物,也是PTA产品的重要质量指标。根据文献[14]对PTA生产工艺的研究,4-CBA含量过低会增加PX(对二甲苯)的单耗,因此,为了节约能耗,必须保证其含量在某一特定范围内。但在实际的生产过程中,由于4-CBA无法在线实时分析,离线分析存在滞后时间,无法满足控制要求,因此,需要对4-CBA的浓度建立较精确的软测量预测模型。
本文根据现场经验和过程机理选择4-CBA软测量建模的输入变量分别为:反应器液位、反应器温度、反应器尾氧含量、反应生成的CO2含量、反应生成的CO含量、混合罐进料流量、反应氧化器进料流量、催化剂浓度、第一结晶器温度约束、第一结晶器的尾氧含量、第三冷凝器排出水量、第四冷凝器排出水量。
样本的采集时间从2002年的9月到12月,选择其中的200组数据作为初始样本数据。将其中的前100组作为训练样本,后100组作为测试样本。采集2003年的100组数据,用于最终稀疏后模型的分析。遗传算法中的参数设置如下,其中,进化的代数maxgen=20,种群的规模sizepop=100,交叉概率pcross=0.4,变异概率pmutation=0.1。
首先对100组初始训练样本集建立LSSVM模型,采用径向基核函数,通过网格搜索算法[15]确定最优的模型参数为c=256,σ=12.125 7。然后通过matlab编程对训练样本集和测试样本集分别进行拟合和预测的仿真,拟合和预测图如图1所示。
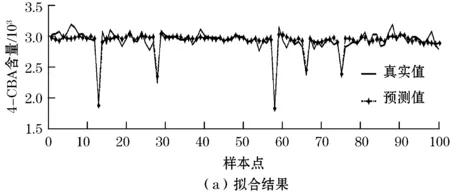

图1 原始样本的真实值与输出值之间比较
下面对初始模型的核函数项采用遗传算法进行稀疏处理。以每次稀疏后测试样本预测相对误差标准差的偏差率为判定依据,来确定模型稀疏的次数。
第一次稀疏优化得到的最优个体bestchrom=[1011101101111010001010000110111101011111001101111011100011001001011001010101011110001011100001110111],其中,“0”项有42项,占原核函数项的42%。第二次稀疏优化后得到的最优个体bestchrom=[110110010010010000001110111010001001111111001111011000101],其中,“0”项有28项,占核函数项的48.3%。第三次稀疏优化后得到的最优个体bestchrom=[001010011011100000001010100000],其中,“0”项有20项,占核函数项的66.7%,由于第三次稀疏后,测试样本估计值相对误差的标准差的偏差率超过10%,算法终止,为了保证模型的预测精度,稀疏次数选取为两次,这样原来的100项初始训练样本最终可以优化为30项,稀疏率为70%。算法优化过程中,每次稀疏后测试样本估计值相对误差的标准差变化趋势图如图2所示。
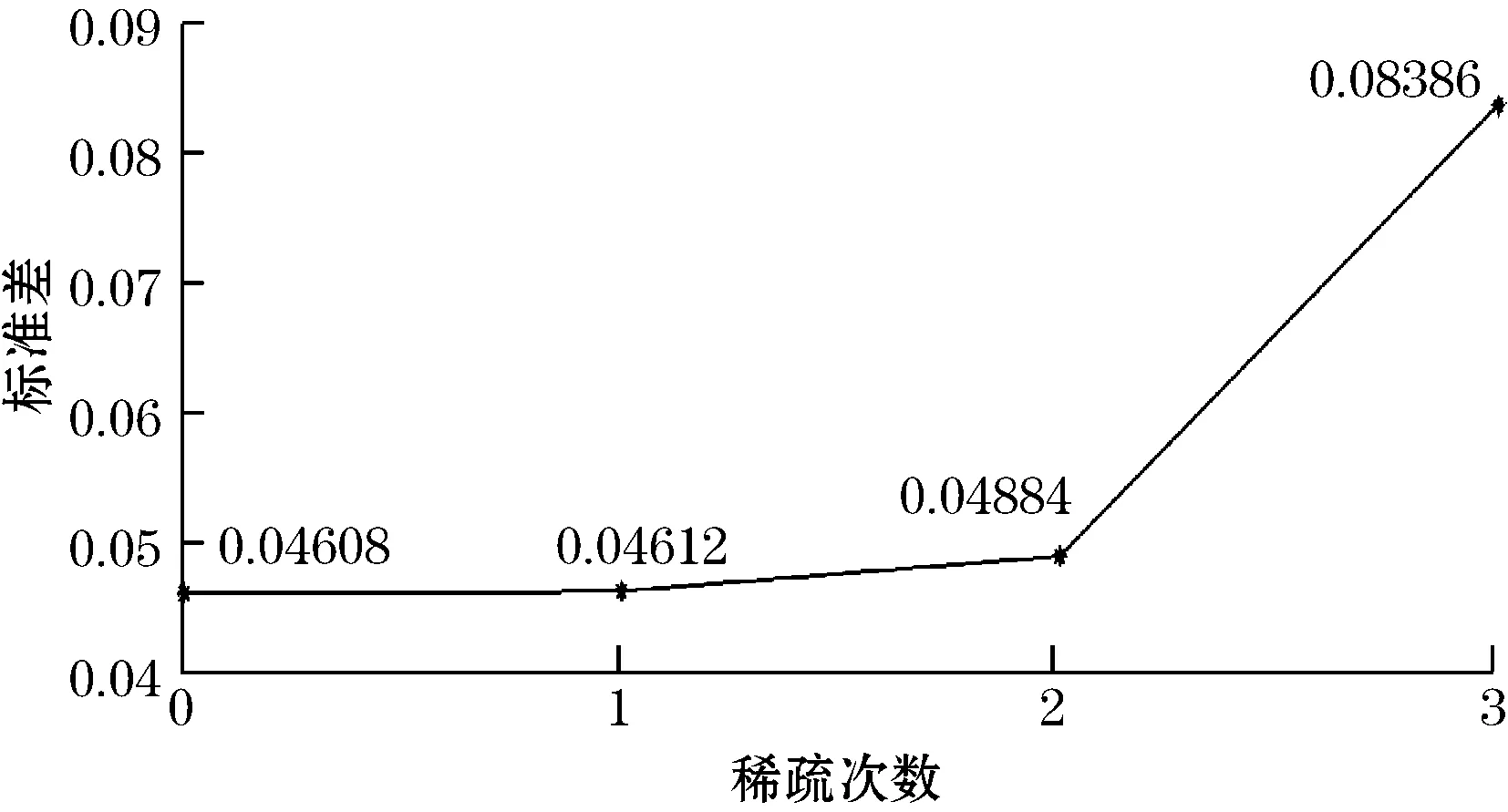
图2 测试样本相对误差标准差的变化趋势
算法优化过程中,将每次稀疏后测试样本预测结果的参数值统计,如表1所示。
表1 稀疏过程测试样本预测结果的参数值比较
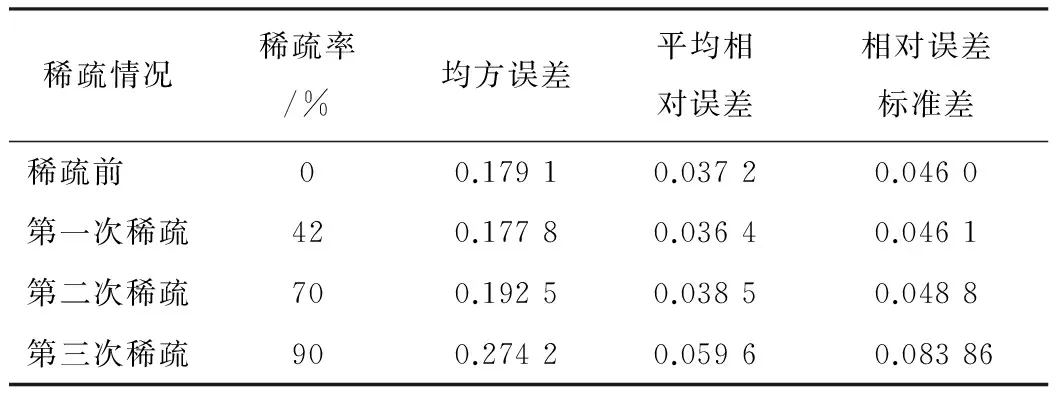
稀疏情况稀疏率/%均方误差平均相对误差相对误差标准差稀疏前 00.17910.03720.0460第一次稀疏420.17780.03640.0461第二次稀疏700.19250.03850.0488第三次稀疏900.27420.05960.08386
从表1可以看出,和稀疏前相比较,不管是均方误差、平均相对误差,还是相对误差标准差,第三次稀疏后的结果变化都很大,而前两次变化不大,预测效果效果也较好。因此,综合考虑,为了保证预测的精度,稀疏次数选取为2次,稀疏率为70%。
选取2003年的100组数据作为新样本,用稀疏化后的新模型对其进行预测分析,并与原始模型比较。通过matlab编程分别用原始模型和优化后的模型对新样本进行预测仿真,预测图如图3所示。
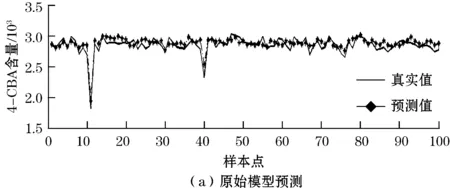
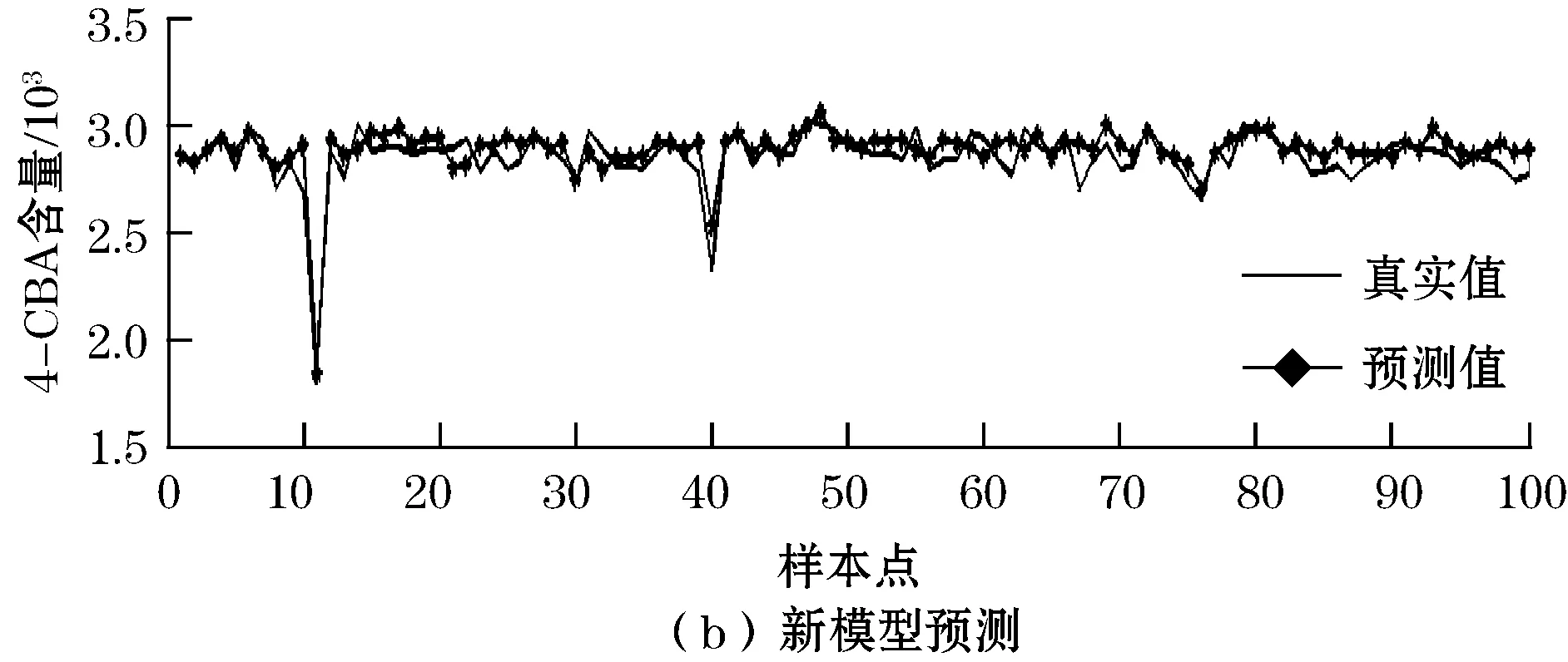
图3 分别针对原始模型和新模型的预测
从图3可以看出,分别针对初始样本点的原始模型和30个样本点的新模型对新样本点的预测都达到了很好的预测效果,而且两次模型的预测结果很接近,均方误差和平均相对误差都很小。上述实验结果表明,采用遗传算法进行稀疏化的最小二乘支持向量机模型,在保证预测精度的同时,支持向量能稀疏70%左右,可以大大提升模型的效率,且稀疏后的模型对新样本点的预测效果很好。因此,GA-LSSVM稀疏算法是可行的。
3 结论
本文针对LSSVM缺失稀疏性的问题,使用了一种基于最优个体保存策略的遗传算法。首先详细地介绍了GA-LSSVM算法实现的原理,然后通过实际应用验证和分析了该算法的可行性。实验结果表明,该算法对LSSVM支持向量的稀疏率可以达到70%左右,优化后的模型对新样本点的预测效果很好。为了同时兼顾稀疏率和预测效果,适应度函数可以同时将这两个因素加进去,本文只考虑了预测精度,这也是今后要研究的方向。
[1] 刘瑞兰,戎舟.工业PX氧化过程4-CBA含量的软测量.信息与控制,2014,43(3):339-343.
[2] PENG X J,WANG Y F.A geometric method for model selection in support vector machine.Expert Systems With Applications,2008 (3).
[3] 王昕.软测量技术及其在工业聚丙烯生产过程中的应用:[学位论文].杭州:浙江大学,2006.
[4] 马勇,黄德先,金以慧.基于支持向量机的软测量建模方法.信息与控制,2004,33(4):417-421.
[5] SUYKENS J A K,VANDEWALLE J.Least squares support vector machine classifiers.Neural Processing Letters,1999(3):293-300.
[6] SUYKENS J A K,LUKAS L,VANDEWALLE J.Sparse approximation using least squares support vector machines.Geneva,2000:11757-11760.
[7] 吴德会.LS-SVM的非线性特征提取新方法及与PCA的关系研究.小型微型计算机系统,2008,29(7):1296-1300.
[8] 甘良志,孙宗海,孙优贤.稀疏最小二乘支持向量机.浙江大学学报(工学版),2007,41(2):245-248.
[9] 孟丽,许峰.基于基因库的最优个体保存遗传算法.软件导刊,2009,8 (7):45-47.
[10] 陈根社,陈新海.遗传算法的研究与进展.信息与控制,1994,23(4):215-222.
[11] 吴宁川.遗传算法和神经网络在常减压蒸馏装置监控中的应用:[学位论文].北京:北京化工大学,2002.
[12] 阎威武,朱宏栋,助惠鹤.基于最小二乘SVM的软测量建模.系统仿真学报,2003:1494-1496.
[13] 王健峰.基于改进网格搜索法SVM参数优化的说话人识别研究:[学位论文].哈尔滨:哈尔滨工程大学,2012.
[14] 王丽军,张宏建,李希.PTA生产中4-CBA浓度的影响因素分析和软测量.合成纤维工业,2005(6):1-4.
[15] 刘瑞兰.软测量技术的若干问题的研究及工业应用:[学位论文].杭州:浙江大学,2004.
Application of Sparse LSSVM in Soft Sensor Modeling of 4-CBA
RONG Zhou,LI Jia-qing
(College of Automation, Nanjing University of Posts and Telecommunications, Nanjing 210023,China)
For the least squares support vector machine (LSSVM) missing sparsity problem, the genetic algorithm (GA) was used for sparse model. Idea was as follows: use binary coding method to code the kernals of initial LSSVM model. Then, GA was used to screen the binary strings. Decode the best individual. “1” represents selecting corresponding position’s sample and "0"represents truncating. Model again by the new sample. Repeat the above process . The algorithm is based on the standard of testing sample’s relative error. When deviation rate of that is more than 10%, sparse operations end. The algorithm can be applied in soft sensor modeling of 4-CBA. The actual application result indicates that the sparse rate of support vectors of LSSVM model can reach about 70 percents. The algorithm improves the efficiency of model greatly without lowering the prediction precision.
LSSVM; sparse; GA; soft sensor
国家自然科学基金资助项目(61203213,11202107)
2015-02-11 收修改稿日期:2015-07-05
TP18
A
1002-1841(2015)12-0088-04
戎舟(1970—),副教授,硕士生导师,研究领域为无线传感器网络,虚拟仪器及网络化测控技术、通信协议一致性测试技术等。
猜你喜欢
计算机技术与发展(2020年9期)2020-11-26
科技创新与应用(2020年6期)2020-02-29
电子制作(2019年24期)2019-02-23
中国神经免疫学和神经病学杂志(2018年6期)2018-01-15
中央民族大学学报(自然科学版)(2017年1期)2017-06-11
现代电子技术(2016年23期)2017-01-12
北京理工大学学报(2016年6期)2016-11-22
智能系统学报(2015年4期)2015-12-27
汽车科技(2015年1期)2015-02-28
医学理论与实践(2012年4期)2012-12-09
