
基于知识库的藏文问答系统研究
2015-06-23 16:28孙浩蒸于洪志
西北民族大学学报(自然科学版) 2015年2期
孙浩蒸,于洪志,苏 敏
( 西北民族大学,中国民族信息技术研究院,甘肃兰州730030)
基于知识库的藏文问答系统研究
孙浩蒸,于洪志,苏 敏
( 西北民族大学,中国民族信息技术研究院,甘肃兰州730030)
随着数据信息的海量增长,人们迫切需要在海量的数据中精准获取有用信息,为了解决这个问题,问答系统应运而生.现今,英文问答系统及中文问答系统取得了显著成绩,但藏文问答系统却鲜有人问津.作为一个多民族的国家,伴随信息化的高速前行,藏文问答系统的研究势在必行.文章通过对现有藏文分词、信息检索等技术分析,借用中英文问答系统成熟的模式,结合藏语语法的特殊性质,对基于FAQ库的藏文问答系统的构建进行分析研究.
问答系统;藏文问答系统;藏文分词;信息检索;FAQ
0 引言
进入21世纪,数据信息已经呈海量态势发展,人们对于信息的获取需要更加精准的方式.问答系统能够有效地缓解数据骤增带来的获取信息效率低下问题.以英文为首的各语言问答系统不断更新发展.现今,英文、中文等语言的问答系统已经取得了显著的成绩,并且在实际的生活中得到了广泛的应用.但是对于藏文等民族语的问答系统却少有人问津,这与民族语言的特殊性有一定的关系.
近些年,随着计算机的普及,相关的藏文数据信息不断增加,藏族人民对信息获取的需要不断的增强,针对藏族语言的问答系统建设势在必行.本文在英文及中文问答系统的基础上,结合传统的藏文分词等技术,根据藏文特有的语法特征进行研究.
1 相关研究
英文问答系统出现时间较早,就在上世纪60年代人工智能研究初期,人们就提出利用自然语言来回答问题的设想,那便是问答系统的雏形.问答系统的快速发展主要取决于面对海量的数据信息,人们需要快速、准确获取信息.
中文问答系统较英文等问答系统发展较晚[1].相比而言,国内问答系统的研究无论是在技术水平上还是应用规模上都有不小的差距[2].但在国内,许多科研机构和单位都投入了相当大的精力,也开发出了一批成熟的中文问答系统.藏文问答系统的建立是文化发展的需要,是大数据信息时代发展的趋势,会成为藏族人民生活中重要的工具.由于藏文存在语法特殊性,藏文问答系统的研究将会是一个长期的过程,藏文问答系统作为民族语言处理领域中重要的一项技术,倍受关注并且有巨大的发展前景.
2 系统构建
现有的问答系统可以从形式上分为以下几类[3]:聊天机器人、问答式检索系统、基于自由文本的问答系统和基于知识库的问答系统.
聊天机器人能够让交互交流变得更加方便和人性化.但是聊天机器人基于设定好的程序,在交互过程中,完全依赖于简单的模式匹配、谈话技巧和聊天技巧进行交流[4].
问答检索系统[5]依据用户输入的问题,对文档或网页进行检索,把检索出的文档或网页返回.这类问答系统主要称作智能搜索引擎,不能称为严格意义上的问答系统.
基于自由文本的问答系统现已经在各语言的问答系统中得到广泛的应用,但对于藏文而言,现有的藏文文档集和藏文网站还相当有限,还不能完全为问答系统提供强大的数据支持.
基于知识库的问答系统通过一个或多个知识库提供数据源,知识库的建设可以面向受限领域.对于知识库范围内的问题,系统回答的准确率非常高.本文主要研究以知识库为基础的藏文问答系统.
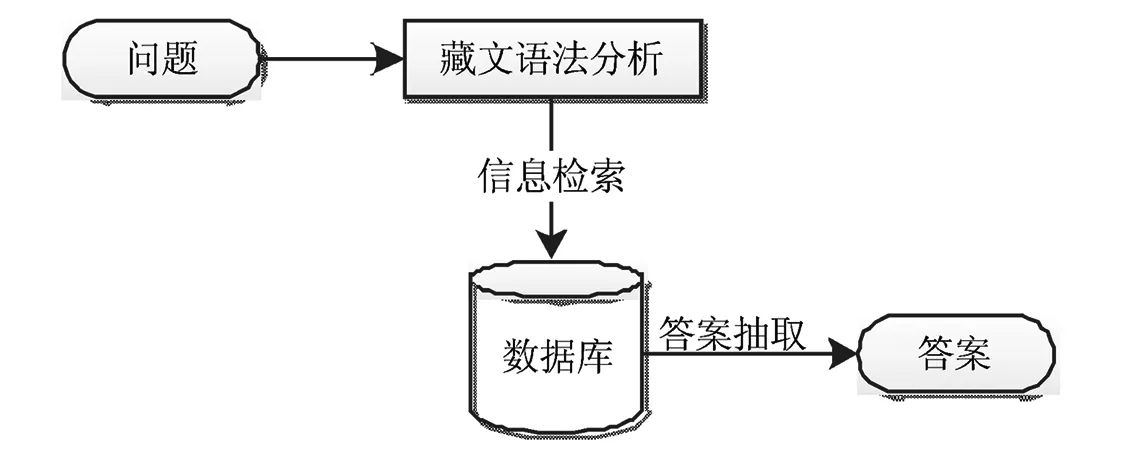
图1 问答系统体系结构
藏文问答系统可以借鉴英汉问答系统模式,分为三个核心部分,即藏文问题理解、藏文信息检索、藏文答案抽取.
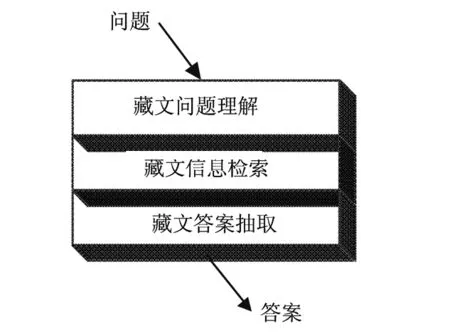
图2 问答系统核心模块
在系统构建过程中本文根据以上三个核心模块对系统进行建设.提供数据支持的知识库设定为受限领域的常用问题集.
2.1 问题理解
2.1.1 藏文分词
藏文是一种拼音文字,有30个辅音字母和4个元音字母组成音节,由音节构成词.藏文同中文同属汉藏语系,藏文分词同中文分词在自然语言处理领域具有相同的地位,他们在语句构成上并没有像英文那样以空格来切分词语.因此,中文和藏文的处理,首先要进行分词.藏文词汇存在口语话等特征也会对分词产生影响,这些因素决定了藏文分词的特殊性.本文采用西北民族大学祁坤钰教授研究的藏文分词法进行分词[6].
2.1.2 去停用词
藏文和中文一样,在自然语句中不乏大量的无实际意义的词或符号以及虚词、助词等.在成熟的中文问答系统中对停用词处理的方法一般基于停用词表进行去停用词.停用词表包含部分藏语停用词和借用中文的标点符号(如:. ! ? 《 》)以及部分虚词[7]、助词.通过对用户问句分词后查询停用词表,判断分词是否在停用词表中,进而决定分词的保留或丢弃.停用词在系统中也起到相当重要的作用,停用词的处理可以提升系统检索效率,提高系统返回的准确度.

图3 系统框架图
2.1.3 同义词扩展
藻饰词是一种藏文词汇的特殊的语言表达形式[8],有好几个词可选择用于表达一个概念,这就有可能把思想感情表达得更加确切、细致,并可避免用词重复[9],类似中文中的同义词.在中文问答系统中涉及到同义词的扩展,例如(计算机和电脑同义),藏文问答系统可以借鉴西北民族大学研究生扎西草[10]研究的藏语藻饰词信息库构建方法进行同义词库的建设.同义词的扩展有助于系统对信息的识别和提取.构造的同义词词库等辅助词库,或者是从语料库中提取的同义词,系统在检索时通过对同义或者意思相近的词处理,从而提高系统检索准确度和整体性能[11].
表1 停用词表
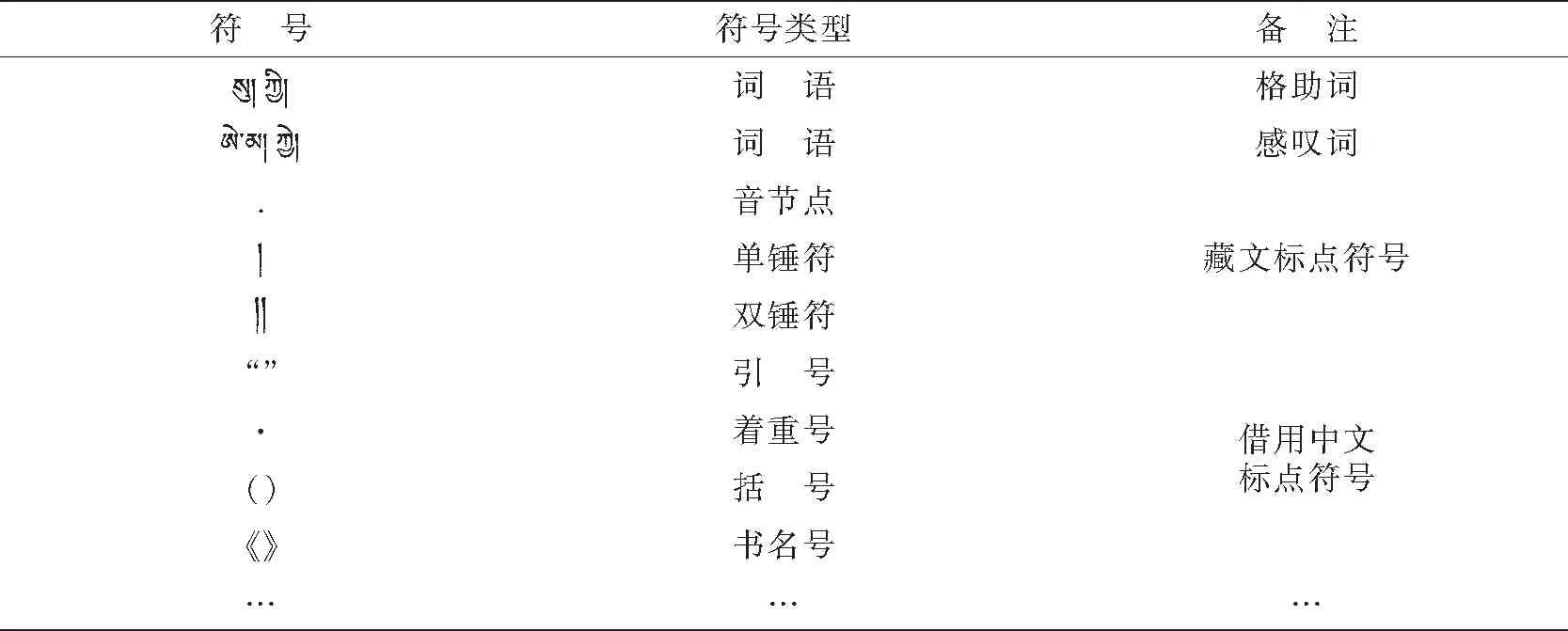
2.1.4 问句类型分析

表2 扩展词示例


表3 常用疑问词
2.2 信息检索
对于信息检索部分, 最简单的方法是去掉问题中的停用词和问句相关的词(如疑问词)生成查询,然后利用已有的检索模型进行检索, 把返回的结果作为答案提取部分的输入[14].
信息检索主要基于检索模型,常用的信息检索模型一般分为四类:布尔模型、模糊逻辑模型、向量模型及概率模型.实验发现在文档检索中, 简单的布尔模型、概率模型与改进的向量空间模型的效果相当[12~13].
本文将采用向量模型[14]对藏文问答系统进行研究.
向量空间模型的基本思想是以词为特征项,用向量来代表文本.如果库中句子包含所有的词为w1,w2,…wn,则库中每一个句子都可用一个n维向量T=

(公式1)
公式所求相似度为两个问句向量的余弦夹角.本方法只要考虑词语在问句中出现的次数,不需要对文本内容做深层理解.
2.3 答案抽取
在选取候选答案中挑选出与目标最相似的问句返回给用户.候选答案相似度的计算基于语义框架匹配,词汇语义相似度计算采用计算语义相似度的计算方法[15],对于两个词U、V,如果U有a个词义U1…Ua,V有b个词义V1…Vb.U和V的相似度是每个词义之间相似度的最大值:
(公式2)
通过计算得到相似度值最大的候选答案,把此答案作为最优答案返回给用户.
2.4 数据库建设
本文系统的设计是基于受限领域知识库的问答系统,所以检索和抽取都依赖于知识库来完成.构建过程中数据的提供通常有多个数据库完成,如:历史问题库、常用词库、领域知识库.
表4 藏文问答系统中数据库分类

历史问题库的建立是为了避免同样的问题进行重复的问答检索,对已经问过的问题放入历史问题库.用户进行问题输入后,首先会在历史问题库中进行模糊匹配,如果有相符记录则返回答案,如果没有相符记录则进行知识库检索.
常用词库分别存放藏文停用词表、扩展词表、常用疑问词表.在问题理解模块对通用库进行调用.
知识库建立过程中,主要内容是面向受限领域的问题集.领域知识库的建立好坏直接影响系统性能的好坏.所以在知识库构建时要做到分类清晰、层次分明.
3 评价指标
通常问答系统需要一个评价机制来衡量它的性能,目前国际上对英文问答系统已有统一的评测机制,中文问答系统还没有既定的标准,民族语问答系统在这方面更是欠缺.为了准确地评价系统的性能,本文采用召回率(R)、准确率(P)、F1值三个参数进行性能评测,评测结果F1值越大代表系统性能越好.公式如下:
(公式3)
(公式4)
(公式5)
4 结论
目前,藏文问答系统研究还处于初级阶段,没有成熟的民族语问答系统模式可以借鉴,只能借鉴成熟的中英文等问答系统模式.由于藏文本身所具有的特殊性,在藏文问答系统的构建不能完全地搬用成熟的中英文自然语言处理模式,所以对藏文问答系统的研究将会是一个长期的过程.
藏文信息处理过程中缺乏语言处理资源,知识库的构建将会是一个重要的工作.由于现在还没有成熟的知识库可以借用,知识库的搭建是一个长期的过程.本文主要是从基于FAQ库的藏文问答系统的框架构建方式进行分析,下一步将会对相应的知识库进行构建,并通过数据分析对系统构建方案进行评估.
问答系统作为目前最热门的研究之一,众多的企业和科研机构加入了研究的行列,在社会生活中也得到了一定的应用.伴随信息化浪潮的推进,问答系统将会有更广阔的前景.藏文问答系统虽然起步较晚,但是藏文问答系统有很多值得研究的地方,也将会有很好的前景.
[1] 张丹.受限领域问答系统的研究与设计[D].内蒙古大学,2012.
[2] 吴友政,赵军, 段湘煜, 等. 问答式检索技术及评测研究综述 [J]. 中文信息学报, 2005, 19(3): 1-13.
[3] 杨建武.智能问答(QA)技术[R].北京大学计算机科学技术研究所,2007,8-13.
[4] Quarteroni, S. and S. Manandhar. A Chatbot-Based Interactive Question Answering System[J].In DECALOG'07, 2007.
[5] 王树西.问答系统:核心技术、发展趋势[J].计算机工程与应用,2005,41(18).
[6] 祁坤钰.信息处理用藏文自动分词研究[J].西北民族大学学报(哲学社会科学版),2006,(4):92-97.
[7] 才让三智.藏语虚词知识库构建研究[D].西北民族大学硕士研究生学位论文,2012.
[8] 张同玲,多杰卓玛.藻饰词语义网络的构建研究[J]. 电脑开发与应用,2011,(24):25-27.
[9] 高丙辰.藏文藻饰词浅说[J].民族语文,1980,44-52.
[10] 扎西草.藏文藻饰词信息库构建研究[D].西北民族大学,2014.
[11] 张兴华. 智能搜索引擎的机理,实现技术及发展趋势[J].现代情报, 2003,12,66-67.
[12] Moldovan D, Pasca M, Harabagiu S, et al. Performance issues and error analysis in an open-domain question an-swering system[J].ACM Transactions on Information Systems, 2003, 21(2): 133-154.
[13] Tellex S, Katz B, Lin J, et al. Quantitative evaluation of passage retrieval algorithms for question answering[C]//Proceedings of the 26th Annual International ACM SIGIRConference on Research and Development in InformationRetrieval (SIGIR ’03). New York, NY, USA: ACM, 2003,41-47.
[14] XinLi, Dan Roth. The Role of Semantic Information in Learning Question Classifiers. In First International Conference on Natural Language Processing[J].Sanyacity,Hainan Island,China,2004,451-458.
[15] 蔡刚山,叶俊,周曼丽.基于多级检索的自动问答系统研究[J].科学技术与工程,2007,7(4):501-505.
2015-05-20
西北民族大学研究生科研创新项目(Yxm2014040).
孙浩蒸(1986—),男,山东枣庄人,硕士研究生,主要从事自然语言处理方面的研究.
TP391.1
A
1009-2102(2015)02-0045-06
猜你喜欢
西藏研究(2021年1期)2021-06-09
校园英语·月末(2021年13期)2021-03-15
布达拉(2020年3期)2020-04-13
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
制造技术与机床(2019年6期)2019-06-25
西夏学(2019年1期)2019-02-10
西藏大学学报(自然科学版)(2016年1期)2016-11-15
中国交通信息化(2016年9期)2016-06-06
图书馆研究(2015年5期)2015-12-07
