
基于Group MCP Logistic模型的个人信用评价分析
2015-08-10 14:35胡小宁何晓群马学俊
现代管理科学 2015年8期
胡小宁 何晓群 马学俊

摘要:在利用Logistic模型分析个人信用评价问题时,需要进行变量选择。Group MCP不仅可以将相关变量以组为单位进行变量选择,还可以对组内变量进行选择。文章根据个人信贷数据,建立了Group MCP Logistic模型,并与Group Lasso、Group Bridge所得的结果进行比较,综合考虑模型复杂度和预测正确率,发现根据Group MCP建立的模型效果是最优的。
关键词:Group MCP;Logistic模型;个人信用评价;变量选择
一、 引言
个人消费信贷在我国迅速发展,对拉动经济增长起到了一定的促进作用。但其中也隐藏着很大的潜在风险,即信贷资产不能及时有效地收回。因此,急需建立完善的个人信用评价体系,从而降低信贷风险。个人信用评价的核心是建立不同客户的信用评价模型,根据信用评价模型对信贷申请人进行评分,从而决定是否给予贷款。
个人信用评价分析中,应用最广泛的方法有统计分析和机器学习两类,前者在模型稳健性和可解释性上有很大的优势。统计分析方法中,学者最关注的是Logistic模型,其计算方法简单、预测准确率高、变量解释能力强。但当Logistic模型涉及的变量很多时,直接使用也存在多重共线性和计算复杂度等问题。因此,变量选择是个人信用评价问题的重点和难点。
传统的变量选择方法有最优子集法和逐步回归法,但这些方法计算量大,且不稳定,当数据有微小变化时,可能得到完全不同的模型,其结果往往是局部最优解,并非全局最优解,尤其当变量个数大于样本量时,方法失效。Lasso是目前应用广泛的变量选择方法,但在个人信用评价问题研究中,许多解释变量是定性变量,对其进行数量化后引入大量的虚拟变量。在利用最优子集、逐步回归或Lasso进行变量选择时,只能选择某个虚拟变量,而不是将相关的虚拟变量作为整体进行选择。Group Lasso将相关虚拟变量作为整体进行选择,使其能够整体剔除或保留在模型中,但并不能实现对群组内变量的选择。Group Bridge既可以实现选择重要的组,也可以选择这些组里面的重要变量,但其惩罚函数在某些点不可微。Group MCP(Group Minimax Concavepenalty)解决了Group Bridge不可微的问题。
本文将建立基于Group MCP的Logistic模型,对个人信用评价的影响因素进行选择和分析,并将其与基于Group Lasso、Group Bridge所得的结果进行比较。
二、 Group MCP Logistic模型
三、 实例分析
1. 数据来源。本文数据选用的是德国某银行的个人信贷数据集合。该数据集中有1 000条记录,包括21个字段,其中前20个字段为信贷申请人的个人特征描述,最后1个字段是银行对客户信用级别的定义:0为“差客户”,1为“好客户”。
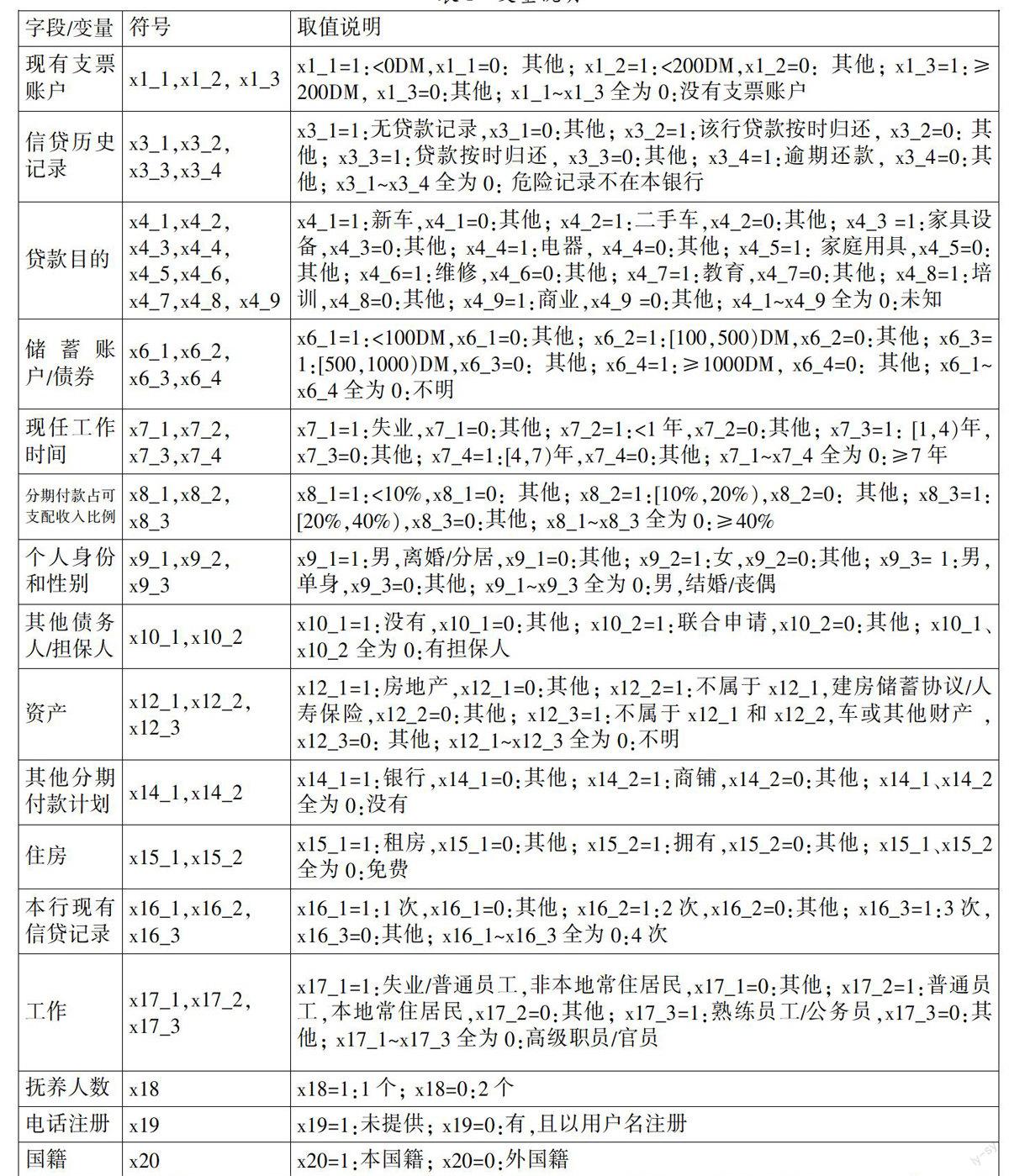
本文所用数据包括21个字段,将其进行处理、编码后的结果(解释变量20组共52个,因变量1个)见表1。
原始数据中,信贷期限(x2)、贷款金额(x5)、当前居住地居住时间(x11)、年龄(x13)为连续型数据,为克服量纲的影响,将其标准化处理后再进行分析。
本文所用数据集中,包括700条信用“好客户”和300条信用“差客户”,分别从中随机抽取80%用作训练集,剩余20%用作测试集。训练集中信用“差客户”与“好客户”的数量比为3:7,数据不平衡比较明显,为了降低数据不平衡对分析结果造成的影响。采用Random Oversampling方法在信用差客户中生成120条记录参与建立模型。
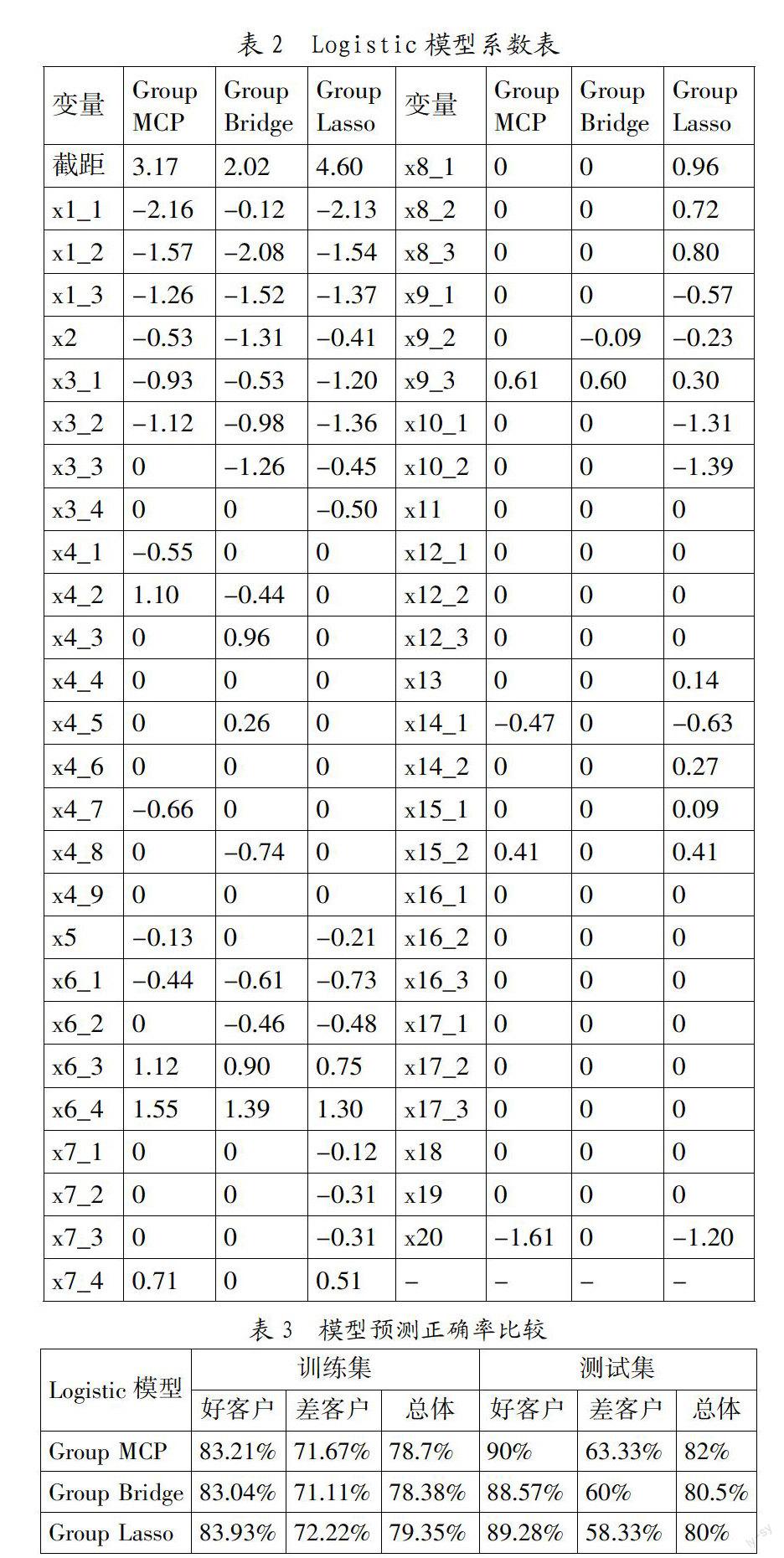
2. Group MCP Logistic模型的建立。本文数据分析通过R软件的grpreg程序包完成,得到非零解释变量11组共18个,系数压缩为零的解释变量9组共34个,见表2。
由表2可以看出:现有支票账户(x1组)额度越高的客户,违约的概率越小(x1_13. 模型比较。本文还建立了基于Group Lasso和GroupBridge的Logistic模型,其参数估计的结果见表3。
从模型复杂度上来比较:Group Lasso保留了13组共31个变量;Group Bridge保留了7组共17个解释变量;Group MCP保留了11组共18个变量。Group MCP与Group Lasso相比,保留变量的组数差不多,但变量个数前者比后者大大减少,Group MCP在组内选择变量的优势得到体现。Group MCP与Group Bridge相比,保留的变量个数只差1个,但前者比后者保留的组数多了4个,表明Group MCP保留了更多的组信息。
从模型预测正确率上来比较,表3说明,基于Group MCP建立的Logistic模型,在训练集和测试集上的预测正确率要优于Group Bridge;在训练集上预测的正确率,Group Lasso要高于Group MCP和Group Bridge,而测试集上的预测正确率,Group MCP要优于Group Lasso,尤其是“差客户”的预测正确率上提升很大,这可能是由于Group Lasso没有进行组内变量选择,从而保留了过多的解释变量,有一定的过拟合现象。因此,综合考虑,Group MCP的Logistic模型效果最好。
四、 结论
建立Logistic模型是个人信用评价分析中应用最为广泛的方法。当解释变量尤其是虚拟变量过多时,需要进行以组为单位的变量选择。Group Lasso可以解决组变量的选择问题,将相关的变量作为组进行整体剔除或保留在模型中,但在组内,不能够进行变量选择。Group MCP改进了Group Lasso算法,不仅仅能够进行组变量选择,也能在组内淘汰掉不显著的解释变量。
本文利用具体的个人信贷数据,建立了Group MCP Logistic模型,与Group Lasso和Group Bridge方法进行比较,综合考虑模型复杂度和预测正确率,发现Group MCP方法是最优的。
因此,基于Group MCP方法建立的Logistic模型,能够很好地应用在个人信用评价问题研究中。银行可以结合自己积累的数据,运用Group MCP Logistic模型,选择出对信用评分影响显著的变量,对信贷申请人进行信用评分后再决定是否给予贷款,可以很大程度上降低个人信贷风险。
参考文献:
[1] 方匡南,章贵军,张惠颖.基于Lasso-logistic模型的个人信用风险预警方法[J].数量经济技术经济研究, 2014,(2):125-136.
[2] 朱晓明,刘治国.信用评分模型综述[J].统计与决策, 2007,(1):103-105.
[3] 石庆焱.一个基于神经网络-logistic回归的混合两阶段个人信用评分模型研究[J].统计研究,2005,22(5):45-49.
[4] 胡心瀚,叶五一,缪柏其.上市公司信用风险分析模型中的变量选择[J].数理统计与管理,2012,31(6): 1117-1124.
[5] 何晓群,刘文卿.应用回归分析(第三版)[M].北京:中国人民大学出版社,2011.
[6] 张景肖,刘燕平.函数性广义线性模型曲线选择的正则化方法[J].统计研究,2012,29(9):95-102.
[7] 庞素琳,巩吉璋.C5.0分类算法及在银行个人信用评级中的应用[J].系统工程理论与实践,2009,29(12): 94-104.
基金项目:国家社科基金项目“个人信用评级的统计建模研究与应用”(项目号:13BTJ004)。
作者简介:何晓群(1954-),男,汉族,陕西省西安市人,中国人民大学应用统计科学研究中心、中国人民大学统计学院教授、博士生导师,研究方向为统计模型、六西格玛管理;胡小宁(1986-),男,汉族,河南省濮阳市人,中国人民大学统计学院博士生,研究方向为应用数理统计;马学俊(1986-),男,汉族,安徽省颍上县人,中国人民大学统计学院博士生,研究方向为应用数理统计。
收稿日期:2015-06-16。
