
中医方剂数据库文本挖掘数据预处理的尝试
2015-09-09 20:49吴磊李舒
中国中医药图书情报 2015年3期
关键词:文本挖掘
吴磊+李舒

摘要:目的针对中医方剂数据挖掘需要提出一套以数据清洗为主的数据预处理方法,使数据规范、准确和有序,利于后续处理。方法通过检索技术,在方剂数据库中获取文本数据源,将非规范化的数据通过辅助词群行处理、正则表达式替换、异名处理等步骤进行清洗,改进数据质量。结果在中国方剂数据库共检索到1758条记录,在方剂现代应用数据库共检索到91条记录。源文本数据经预处理后共得到有效记录6913味药,可成功导入相关信息挖掘系统进行方剂名称和中药名词的信息抽取。结论本方法适用于基于中医方剂数据库的文本挖掘和知识发现,可成功对源文本数据实施清洗,得到标准统一、无噪声的数据,实现所需方药信息的有效抽取,可为中医方剂文本型数据信息分析与挖掘研究提供有益的借鉴。
关键词:中医方剂:方剂数据库:文本挖掘:数据预处理:数据清洗
doi:10.3969/j.issn.2095-5707.2015.03.003An Attempt on Data Preprocessing for Text Mining in TCM Prescription DatabaseWU Leil, LI Shu2(1. Information Engineering College, Liaoning University of TCM, Shenyang Liaoning 110847, China;2. Department of Medical Informatics, China Medical University, Shenyang Liaoning 110001, China)
Abstract: Objective To propose a set of data preprocessing method based on data cleaning for TCMprescription database; To make data more standard, accurate and orderly, and convenient for follow-up processing.Methods The text data source was retrieved from prescription databases by bibliographic searching techniques.Non-nonnalized data were processed through steps followed by auxiliary word group line processing, regularexpression substitution, and synonyms processing, with a purpose to unprove data quality. Results Totally 1758effective records were retrieved from TCM prescription database, and 91 records were retrieved from prescriptionmodern application database. 6913 effective Chinese herbal medicines were retrieved after preprocessing, whichcan be successfully imported into relevant information mining system, and information about prescription andherb names can be extracted. Conclusion This method is applicable for text mining and knowledge discovery in TCM prescription database. It can successfully implement data cleaning for source text data, get data with unifiedstandard and without noise, and finally realize the effective extraction of prescription information, which canprovide references for researches on analysis and mining ofTCM prescription text data.
Key words: TCM prescriptions; prescription database; text mining; data preprocessing; data cleaning
近年来中医药信息化发展迅速,已构建及完善了大量的中医方剂数据库,中医方剂数据挖掘和文本挖掘方兴未艾。虽然方剂数据库是经过一定校对勘误后的结构化数据库,但库中原始数据通常因年代跨度大,并保留了不同时期原方的信息特点,对方剂、药物信息的表述准确性及规范统一方面存在一些问题,存在错误的、冗余的、无效的和不一致的噪声数据。因而直接抽取原生信息无法满足数据挖掘和知识发现的具体要求,需要对数据进行必要的预处理,使之规范、准确和有序,实现数据的正确表达和合理组织,达到数据挖掘的基本条件。
数据预处理是数据挖掘中极为重要的方面。数据挖掘过程的大部分工作都在数据预处理环节。根据统计,在一个完整的数据挖掘过程中,数据预处理占用约60%的时间,而后的挖掘工作仅占总工作量的10%左右。数据清洗( data cleaning)是解决问题数据的主要预处理过程,对确保数据质量具有重要作用。本文以中医治疗中风病方剂数据挖掘为例,探讨一种以数据清洗为主的数据预处理方法,为后续配伍规律知识发现研究提供数据支持。
资料与方法
数据来源
由于本研究主要针对方剂名称和药物名称进行预处理,因此选用了两个具备方剂和药物名称的数据库,即中国方剂数据库和方剂现代应用数据库,均隶属于中国中医科学院中医药信息研究所自1984年开始进行建设的中医药学大型数据库群。
在中医药在线(http://www.cintcm.com/)的中医药多库融合平台( http://cowork.cint cm.com/engine/windex.jsp)中,选择方剂类数据库中的中国方剂数据库和方剂现代应用数据库,字段选择均用“主治”,模糊检索,输入“中风”,年代不限,检索时间为2013年11月27日。
研究方法与工具
基于辅助词群的行处理工具 文本行抽取和处理是文本数据预处理中的常用方法,而基于辅助词群的方法可有效提升其灵活度。该方法是基于预先建立的包含辅助词群的辅助文件,可对源文件实现抽取或去除包含辅助文件中词群的行输出;并可按给定的批量行号提取行。
本研究中的行处理由数字人文研究内容挖掘系统ROST CM实现。
正则表达式文本处理工具正则表达式是一种可以用于模式匹配和替换的规范,一个正则表达式就是由普通的字符以及特殊字符组成的文字模式,它用以描述在查找文字主体时待匹配的一个或多个字符串。在很多文本编辑器或其他工具里,正则表达式通常被用来检索和/或替换那些符合某个模式的文本内容。
正则表达式可用来验证字符串是否符合指定特征并用来查找字符串,比查找固定字符串更加灵活方便;可以用来替换,比普通的替换更强大。例如表达式“ab+”描述的特征是一个“a”和任意个“b”,那么“ab”“abb”“abbbbbbbbbb”都符合这个特征。
本研究中的正则表达式处理由文本处理工具Textpro实现。
纳入和排除标准
纳入标准:以方剂主治病证中明确出现中风、半身不遂、偏枯、瘫痪、神识昏蒙、言语蹇涩或不语、口眼歪斜及其同义词或近义词为主症,筛选出主治这些主症的方剂或其主治内容所包含的信息与已知的中风病病因病机符合的方剂。
排除标准:排除方剂所治症状可明确为其他因素(非中风)所引起的偏枯、偏瘫、口眼歪斜等,无主症或主症不符合,及属于治疗外感表证和类中风(中寒、中暑、中湿、痰厥等致半身不遂、偏枯瘫痪)的中风方剂,如风痹;外风、风湿/类风湿型产后中风、小儿中风;风寒/伤寒中风,破伤中风,心肺中风,脾胃中风,肝脏中风,中毒等。2结果与分析
中国方剂数据库共检索到1758条记录,在方剂现代应用数据库共检索到91条记录。以“一般模板”进行套录,保存为HTML格式;再将源文件的HTML格式转为ANSI编码的TXT格式;最后来自两个数据库的两组文本合并。之后经标准过滤并整理去重后,共得到有效记录648条,重新编号后形成待处理源文本,其中取自中国方剂数据库1号源文件的部分文本数据如图1所示。
基于辅助词群的文本行处理
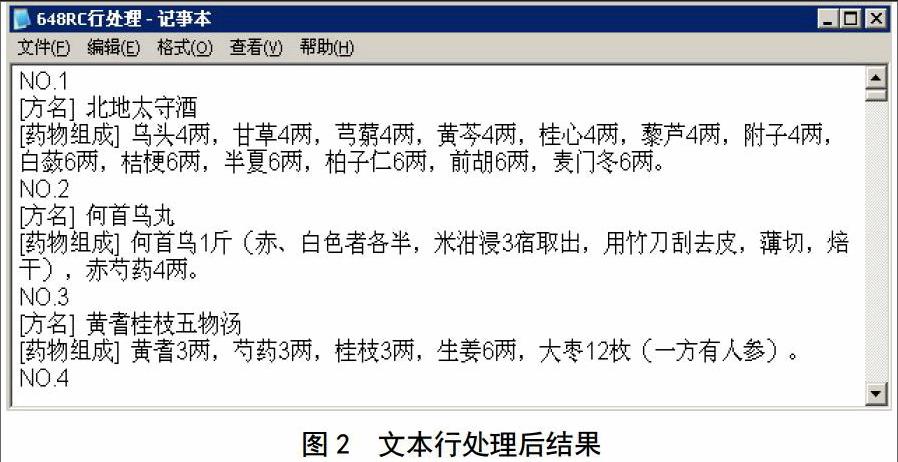
为提取源数据中主要关注的方药信息,使用ROSTCM的基于辅助词群的行抽取与处理方法对信息进行清理,“方名”和“药物组成”两字段除外。辅助词群设置为[别名][处方来源][剂型][功效][加减][主治][制备方法][用法用量][用药禁忌][用法用量][各家论述][临床应用][备注][药理作用]。经过文本行处理后,源文件内容转为如下形式,如图2所示。
基于正则表达式的文本处理
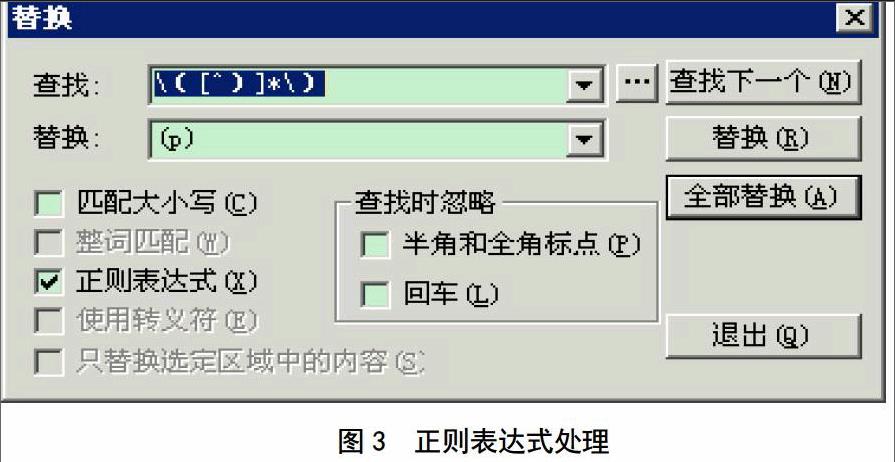
本研究中,因特殊制法和剂量信息暂不考虑,这些信息需要被屏蔽。文本源数据的特殊制法部分都采用了中文括号表示,故使用正则表达式替换操作,表达式设置为“\([^)]冰\)”(意为从一个开括号到最近的闭括号)。该操作在支持REGEX的Textpro工具中进行,如图3所示。
如“何首乌1斤(赤、白色者各半,米泔浸3宿取出,用竹刀刮去皮,薄切,焙干)”,处理完形后,为“何首乌1斤(p)”。
对于剂量信息,首先删除药名后的“等”和“各等分”字符,如“川芎等”、“当归各等分”,去掉后为“川芎”“当归”;再使用自定义替换功能将中文剂量字符统一转换为数字字符,如将“半两”转为“0.5两”;最后再清除剂量和制法信息。具体做法为:使用正则表达式“\d[^:]冰\:”(意为从一个数字字符到最近的英文分号),将其替换为英文分号,可将剂量信息去除。
药物名称不一致处理
源文本中的“药物组成”字段为长文本类型,包括各种中草药的名称,是非规范化的数据,存在不一致问题。中药品种众多,名称复杂,因时代、地域不同而有别,常根据药物的形态、产地、颜色、功效等特征来命名。因此源文本数据中同药异名、同名异药的现象十分普遍。例如僵蚕处方名有天虫、僵虫、白僵虫等多种名称,但均实属同一药物,应都规范为僵蚕。
本研究的中药异名问题,主要参考《中药学》教材及《中药大辞典》进行规范化处理。原则上将长名转为短名,如:明天麻转为天麻,甘菊花转为菊花等,如反之,则会出现如“甘甘菊花”的无效结果;但有些药确要将短名化长名,则需确认源文本中药名前后皆以英文分号结尾(无剂量等信息):如将“芎”化为“川芎”,“白附”化为“白附子”。
依据参考书建立药名转换规范对照表,使用Textpro的自定义替换功能载入该表,对源文本数据批量处理,规范化药名,如表1所示。
对于“芎?”这类特殊字符构成形式,在部分系统处理完毕后出现未能匹配成功替换情况,可使用单独替换功能重新处理一遍。 此外,源数据中某些药物与现代中药存在差别,有一些药名≥2个中药合并起来的简称,为了统一药名,需要将其拆分开来,如将苍白术拆分为苍术、白术。
源文本数据经预处理后共得到有效记录6913味药,部分结果如图4所示。
本研究表明,该预处理方法可成功地对源文本数据实施清洗,得到标准统一、无噪声的数据,因此是有效的。结果数据可导入书目信息共现挖掘系统(BICOMB)进行方剂名称和中药名词的信息抽取,为进一步进行知识发现提供了有力的数据支撑。
小结
数据清洗就是通过各种措施,从准确性、一致性、无冗余、符合应用的需求等方面提高数据的质量,实质是消除数据中的错误和不一致。目前,中医药信息处理与分析中的数据预处理方法种类繁多,本文试用一种定制的以数据清洗为主的数据预处理方法对非规范的原始数据进行了有效的处理,是中医药数据挖掘和文本领域的一次有益尝试,希望对后续研究起到抛砖引玉的作用,并推广至其他中医方剂类文本型数据库数据挖掘的数据预处理中,为中医方剂数据挖掘和文本挖掘研究提供新方法和技术手段。
猜你喜欢
科技资讯(2017年5期)2017-04-12
课程教育研究·新教师教学(2016年15期)2017-04-12
电脑知识与技术(2016年33期)2017-03-21
商情(2016年32期)2017-03-04
软件导刊(2016年12期)2017-01-21
电子技术与软件工程(2016年22期)2016-12-26
商(2016年34期)2016-11-24
中国远程教育(2016年9期)2016-11-19
中国中医药图书情报(2016年4期)2016-10-20
湖南师范大学学报·自然科学版(2016年3期)2016-06-25
