
基于CUDA的直方图问题并行优化
2015-09-26 05:18吴志辉徐小红朱同林
现代计算机 2015年19期
吴志辉,徐小红,朱同林
(1.华南农业大学信息与数学学院,广州 510642;2.华南农业大学图像图形研究中心,广州 510642)
基于CUDA的直方图问题并行优化
吴志辉1,2,徐小红2,朱同林1,2
(1.华南农业大学信息与数学学院,广州510642;2.华南农业大学图像图形研究中心,广州510642)
1 研究内容
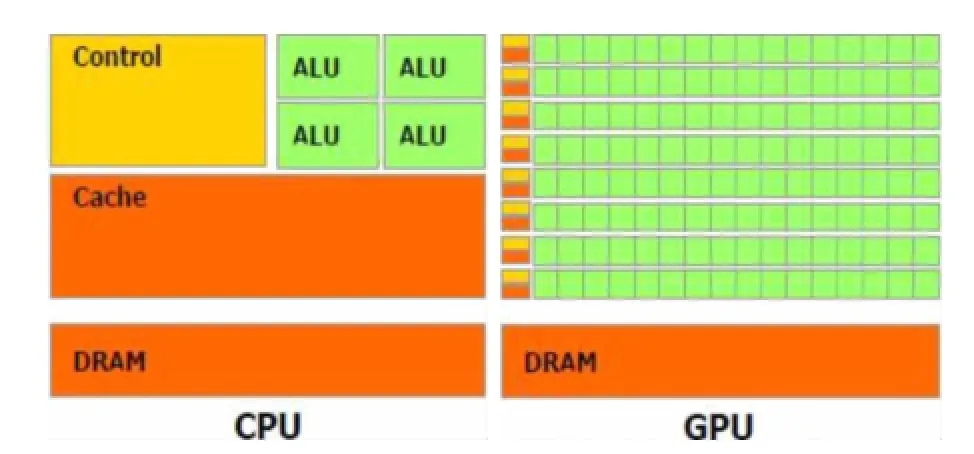
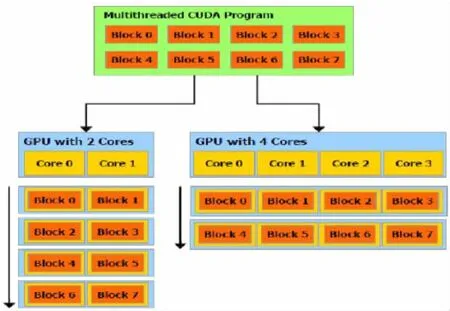
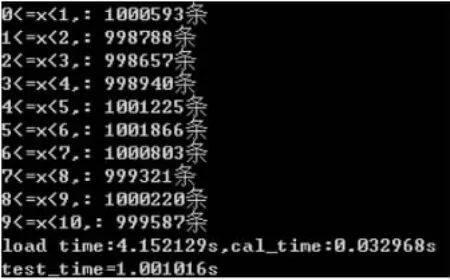
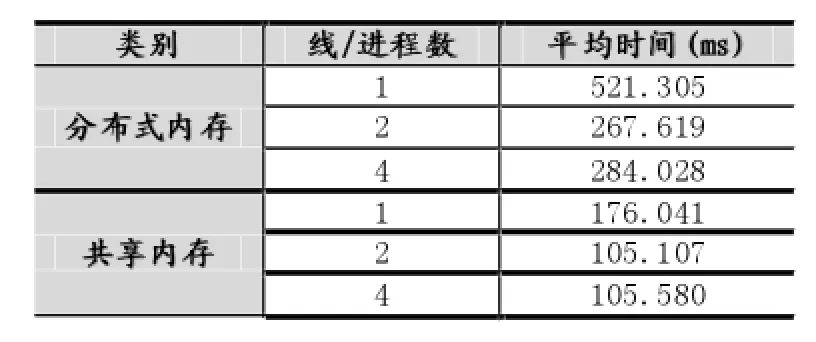
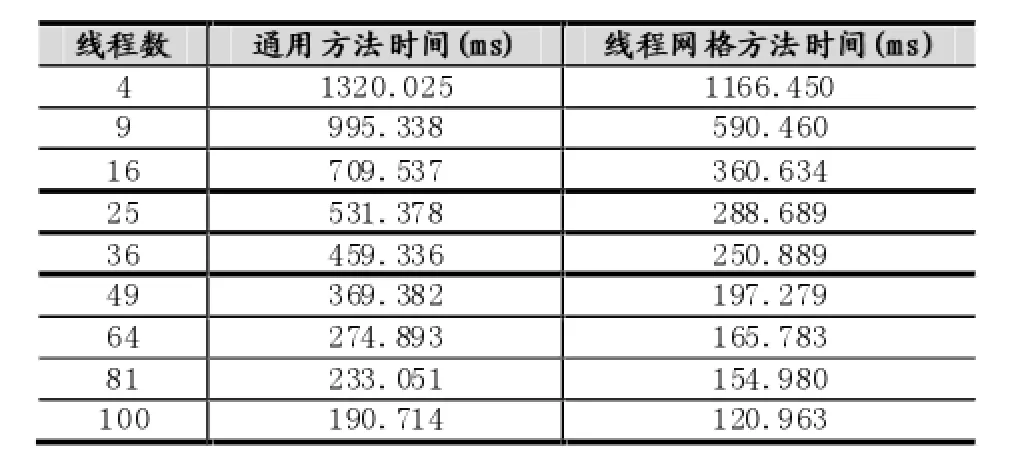
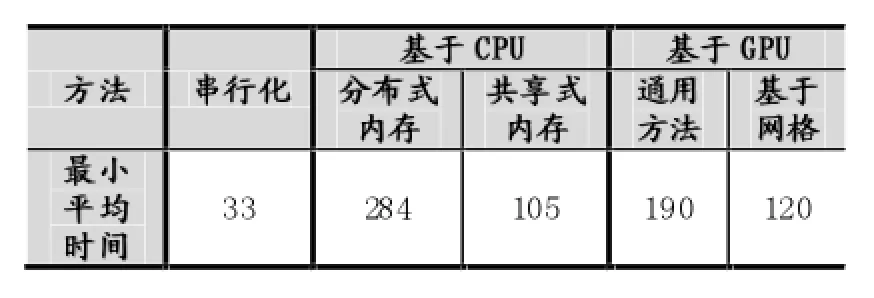
现有使用文件保存的输入数据集N条,其中数据为浮点数,取值范围为a≤x 直方图问题是一个经典的问题,要解决这个问题需要遍历所有的数据集中的数据,判断所在的区间分布。随着数据规模的增加,问题的规模也随着增大。而数据间并没有关联性,适合使用并行计算的方法来实现。因此本文以该问题为切入点,来研究基于CUDA (Compute Unified Device Architecture)即英伟达公司推出的通用并行计算架构的并行计算的特点和优劣。 串行化方法即使用单线程的方法,数据集采用文件的形式,保存一个拥有n行的浮点数,然后统计完结果直接输出到命令行中。串行化方法步骤如下: ①通过读取文件的形式读取出浮点数,由于后续的操作主要是查询操作,所以使用数组形式保存即可。建立一个大小为N的实数类型的数组Inp,并全部初始化为0。然后依次i=0,1,…,N-2,N-1读取数据到Inp[i]。 ②保存结果的投票箱同样使用数组,建立一个大小M的整数数组,其中M=b-a,并全部初始化为0。 ③使用基于正序的顺序遍历,下标从小到大取出数字对应的浮点数。判断浮点数属于哪个投票箱。使用以下的方法来简化,直接将浮点数转化为对应的整数,此时的整数刚好是投票箱的下标,这样就避免了重复比较,提高了效率。 ④直接将投票箱的内容输出到命令行,串行程序结束。 根据串行化的方法步骤,利用分布式内存并行系统的特点,不同的进程拥有相互不共享的内存,因此所有的数据的交换都要通过通信来实现,而通信的时间消耗非常大,所以要减少数据的交换。具体优化如下: 首先要确定串行程序那些步骤可以进行并行化。串行化程序中,其中时间消耗最大的就是遍历数组所有的浮点数,统计范围的分布。因此并行化该步骤,将数组根据进程数N平均分为n份,每个进程即处理N/n个。 其次确定不同进程哪些数据需要进行数据交换。串行程序中主要涉及到的数据包括:①输入浮点数数组,大小为N;②投票箱数组,大小为M。由于数据通信是非常大的时间消耗,为了缩短时间,浮点数数组的数据来自数据集文件,而一个进程读取文件与多个进程读取文件的时间相当,因此采用每个进程均读取文件的方法来减少数据通信。而对于投票箱数组,则每个进程建立一个投票箱副本,然后再利用数据通信汇总。 根据串行化的方法步骤,利用共享式内存并行系统的特点,不同的线程共享同一个内存系统,所以数据交换方便,但容易出现数据出错以及死锁等问题,所以并行化时尽量多地防止数据出现的错误。 首先要确定串行化哪些步骤可以并行化,而其他的步骤直接使用串行即可。串行化时间销售最大的就是遍历数组所有浮点数,统计范围分布了。因此,采用与分布式内存并行系统类似的方法。将数组根据线程数n,平均分为n份,每个线程处理个N/n。 其次,要确定是否出现死锁、数据错误等问题。程序涉及到的数据包括:①输入浮点数数组,大小为N;②投票箱数组,大小为M。其中对于浮点数数组,所有的线程均只进行读操作,所以不存在问题。而对于投票箱数组,则会出现多线程同时写入的问题,因此解决方案为,首先各线程先建立投票箱副本,然后针对汇总投票箱时增加锁,使得汇总时只能有一个线程操作投票箱。这样就实现了防止数据错误的问题。 市场对实时、高清晰度的三维图形具有无法满足的需求,由于这种需求的推动,可编程图形处理器(GPU)已经演化成高并行度、多线程、拥有强大计算能力和极高存储器带宽的多核处理器[1]。 GPU和CPU的浮点计算能力差异的原因是:GPU是特别为计算密集、高并行度计算(如同图像渲染)设计的,因此将更多的晶体管用于数据处理而不是数据缓存和流控,如图1所示。 基于这样的原因,2006年11月,英伟达推出了CUDA,一种基于新的并行编程模型和指令集架构的通用计算架构,CUDA能够利用英伟达GPU的并行计算引擎比CPU更高效地解决许多复杂计算任务。 图1 CPU与GPU CUDA核心包含三个重点抽象:线程组层次、共享存储器和栅栏同步,这些被作为一个最小的语言扩展集简单呈现(expose)给程序员。这些抽象提供了细粒度数据并行度和线程并行度,嵌套在粗粒度数据并行和任务并行中。它们引导程序员将问题划分为可以被多个块内线程独立并行处理的粗粒度子问题,而每个子问题又被分为可以被一个块内线程并行协作处理的更小的片段。这种分解通过在处理子问题的时候允许线程协作保持了语言的表达性,同时保证了自动可扩展性。事实上,每个块可被调度到可用处理器核心的任意一个上,以任何顺序,并行或者串行执行,这使得已编译好的CUDA程序能够在任意核心的GPU上执行。 图2 系统可扩展性 基于CUDA的GPU程序同样支持类似于在CPU下的并行优化方法,完全可以简单地将原来针对多核CPU下的共享式内存并行系统程序移植到基于CUDA 的GPU程序下。而所不同的就在于GPU下有自己的存储系统,所以要利用CUDA使用GPU进行计算,要将数据传输到GPU上。 首先要确定基于共享内存式并行系统有没有存在基于CUDA的GPU程序下无法实现的情况。基于共享式内存并行系统的程序主要的并行步骤为遍历数组的所有数据,统计分布。此步骤只涉及到读操作,同样适用于基于CUDA的GPU程序,因此直接移植即可。 其次要确定主机(即CPU)与GPU之间的数据传输。主要数据包括:①输入浮点数数组,大小为N;②投票箱数组。其中,浮点数数组是并行计算的主要数据来源,因此此数据需要从主机传输到GPU。而投票箱数组是保存结果的主要来源,针对各线程,同样需要将数据从GPU传输到主机中。 最后要根据GPU的不同,确定可使用GPU线程数。与CPU针对超过核心的线程数并行串行化不同,基于CUDA的GPU程序对超过核心数的线程很敏感,申请超过核心的线程非常容易导致程序出错,因此无法超出核心数的使用线程。而相比CPU的核心,GPU拥有非常多的核心,例如本文实验所用的GPU英伟达GT 540m就有多达96个核。 基于CUDA的GPU程序不仅提供了基于多线程的方法,还提供了线程网格的方法。有3个组件的向量,所以线程可以使用一维、二维、三维索引标识,形成相对应的线程块。这提供了一种自然的方式来调用作用在域内元素上的计算,如向量、矩阵、体元(volume)。线程块被组织成一维、二维或三维的线程网格。所以使用线程网格。通过构建线程网格,可以专门针对CUDA 做GPU的程序并行优化,这个是GPU相比CPU独有的。 因此,在申请GPU的线程时,可以构建从一维到二维,乃至最高维的线程网格。对提供线程的效率也有帮助。由于数组为二维矩阵,因此采用二维网格优化。建立一个n×n的二维网格线程,将数组根据线程数k= n×n,平均分为k份,每个线程处理N/k。 实验的平台如下: 硬件方面:使用华硕A43SV系列笔记本作为测试平台.其配置为:Intel Core i5-2410M CPU@2.30 GHz(即双核四线程,主频2.3GHz),NVIDIA GeForce GT540M CUDA.1GB(即显存1G,支持CUDA的显卡),4.00G内存。搭载64bits Windows 7操作系统。 软件方面:使用VS 2008为基本平台,基于分布式内存使用MPICH软件;基于共享式内存系统使用OpenMP库作为基础;基于CUDA的GPU使用CUDA 4.0作为基础。 实验的数据: 数据集的大小取10,000,000,其中数据为浮点数,取值范围为0≤x<10。 串行程序使用C++语言进行编写,分别使用Query PerformanceFrequency和 QueryPerformanceCoun-ter这两个函数统计时间消耗,单独计算统计的耗时,时间稳定在33毫秒左右。 图3 串行化方法实验结果 针对通用方法的并行化程序,利用VMWare虚拟机软件模拟了一个双核的平台。时间与前面串行的程序没有对比性,因此单独在此平台下利用串行程序测试了一遍,时间稳定在0.17秒左右。 针对分布式内存并行系统,本文采用了单机MPICH2软件来实现,测试了进程数为1,2,4的时间消耗。 针对共享式内存并行系统,本文利用OpenMP库作为现实的载体,测试了线程数为1,2,4的时间消耗。 表1 基于CPU并行化程序实验结果 针对基于CUDA的GPU程序实验结果,包括两个内容:①基于CUDA的通用方法的并行优化的结果;②基于CUDA的线程网格的并行优化的结果。 表2 基于CUDA的并行优化实验结果 实验的最终每种方法的最小平均时间结果如表3所示: 表3 实验结果比较 本文使用将基于CUDA的GPU程序与普通的串行以及传统的CPU的相关并行方法做了比较。从实验的结果可以看出,在本文举例的直方图中,采用GPU来进行并行计算更具有优势。表现在以下: (1)GPU的基于计算密集,高并行度计算设计的。采用多核心的流式结构,本身就更适合用于做并行计算。本文所采用的CPU和GPU,论主频来说CPU是拥有更快的速度,但是在具体实验中,GPU利用多核的优势达到了和CPU差不多的效率。 (2)基于CUDA的GPU程序开发提供相比针对CPU的并行更多的功能。例如:本文使用的基于线程网格的优化,比使用传统CPU并行计算方法提升了效率,减少了时间的消耗。 因此,在可以预见的未来,基于GPU的并行计算会发挥重要的作用。而针对GPU的CUDA架构也将大有用处。 [1]卢风顺,宋君强,银福康,张理论.CPU/GPU协同并行计算研究综述[J].重庆:计算机科学,2011,03:5-9. Histogram;Serialization;Distributed Memory;Shared Memory;CUDA Parallel Optimization of Histogram Problem Based on CUDA WU Zhi-hui1,2,XU Xiao-hong2,ZHU Tong-lin1,2 1007-1423(2015)19-0058-05 10.3969/j.issn.1007-1423.2015.19.015 吴志辉(1989-),男,广东揭阳人,在读硕士研究生,研究方向为数字图像处理 朱同林(1963-),男,江西南康人,博士,教授,博士生导师,研究方向为计算机图形学及数字图像处理 2015-05-12 2015-06-25 直方图问题是一个经典的问题,以该问题为切入点,比较基于CUDA的GPU(图形处理器)程序,与串行和传统的基于CPU(中央处理器)的并行程序的比较,从而找出基于CUDA的GPU程序的特点与优势。 直方图;串行化;分布式内存;共享内存;CUDA 高等学校博士学科点专项科研基金联合资助课题(No.20124404110018:2013.1-2015.12) 徐小红(1975-),女,湖南宁乡人,博士,讲师,研究方向为生物统计、计算机视觉和图像处理 Histogram program is a classic problem,takes the the problem as starting point,compares the GPU program based on comparison CUDA with the serial and traditions based on the CPU comparison of parallel programs,in order to identify the features and advantages of GPU program based on CUDA.2 直方图问题的串行化方法
3 基于CPU的并行化方法

4 基于CUDA的并行优化算法

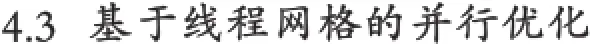
5 实验结果
6 结语
(1.College of Mathematics and Information,South China Agricultural University,Guangzhou 510642;2.Research Center of Image&Graphics,South China Agricultural University,Guangzhou 510642)
猜你喜欢
湘潭大学自然科学学报(2022年2期)2022-07-28
电脑报(2022年13期)2022-04-12
山西电子技术(2021年3期)2021-06-28
安徽电子信息职业技术学院学报(2020年5期)2020-11-13
电脑报(2020年24期)2020-07-15
网络安全技术与应用(2020年1期)2020-01-07
通信技术(2019年9期)2019-10-09
摄影之友(影像视觉)(2018年12期)2019-01-28
电脑爱好者(2017年22期)2017-12-04
初中生世界·八年级(2017年3期)2017-03-24
