
融合句法结构变换与词汇语义特征的文本蕴涵识别
2015-11-04 06:19张志昌姚东任陈松毅鲁小勇
计算机工程 2015年9期
张志昌,姚东任,刘 霞,陈松毅,鲁小勇
(西北师范大学计算机科学与工程学院,兰州730070)
融合句法结构变换与词汇语义特征的文本蕴涵识别
张志昌,姚东任,刘 霞,陈松毅,鲁小勇
(西北师范大学计算机科学与工程学院,兰州730070)
传统文本蕴涵识别方法仅停留在词汇级的识别,无法涉及句法、语义等方面,造成识别结果的F值较低。针对该问题,提出一种将句法结构的变换和传统词汇语义特征结合的中文文本蕴涵识别方法。对文本进行基于句法分析树变换的预处理,将句法分析中适用于文本蕴涵识别的特征加入到相关的统计和词汇语义特征中,使用统计机器学习的方法对由文本片段T和假设的文本片段H组成的文本对进行蕴涵关系分类,并经过语义规则的修正处理得到最终的识别结果。在NTCIR RITE3上的评测结果表明,与III&CYUT,Yam raj等相比,该方法能获得较高的F值。
中文文本蕴涵;句法结构变换;词汇语义特征;词汇统计特征;统计机器学习
1 概述
在自然语言处理的很多实际应用(如问答系统、多文档自动摘要、信息抽取、机器翻译评测等方面)中,经常需要进行文本的相似匹配或者语义推断。这些应用面临的一个主要困难是自然语言表达形式上的歧义性(同义异形、同形异义)。为了能够有效地解决在实际应用中进行文本语义推理所面临的歧义现象,Dagan和G lickman在2004年提出[1]用文本蕴涵这一概念为这些歧义现象建立一种统一的模型和处理框架。
所谓文本蕴涵[2]是指一个文本H中的意思可以通过另一个文本T推断得到。更确切地讲,给定一个文本片段T和被称为假设的文本片段H,根据T的上下文语境进行解释时,H的含义可以从T的含义中推断出来,则称T蕴涵H,记做T=>H。例如:T:百度的总部在北京市海淀区;H:百度的总部在中国。这样,T=>H,但是H≠>T。
近年来,随着人们对文本蕴涵重要性的认识,越来越多的学者加入到这个研究方向上来。已有的文本蕴涵识别方法主要有以下3种:
(1)基于逻辑推理解码[3-5]的方法。将文本T和假设H转化为逻辑表示形式ΦT和ΦH,然后利用公理证明引擎,借助各种蕴涵规则和知识B,判断是否能从ΦT推出ΦH,即判断是否(ΦT∧B)=>ΦH如果能够推出,则蕴涵。该方法直观、容易理解,但是如果没有足够的蕴涵规则和知识,则公理证明引擎很难从文本T的逻辑表示推出假设H的逻辑表示。
(2)在两文本间进行对齐和相似度计算的方法。计算T(或其某个局部)和H(或其某个局部)的各种相似度,如果该值超过一定阈值,则认为T蕴涵H。相似度的计算大致可分为如下3种:1)词汇层面,计算两文本表层字符串相似度[6];2)句法层面,计算T和H句法分析树的某2个子树的树相似度[7];3)在浅层语义的层面进行。即在计算T的某个局部和H之间的相似度时,结合两者的语义角色标注信息[8]。另外,当T蕴涵H时,H中的词汇在T中也并不一定连续出现。所以,将T和H相对应的词汇进行对齐也可以视为相似度的一种度量[9]。这类方案不可避免地要应用到类义字典(知网、W ordNet等)、蕴涵规则等各种语言知识资源,而中文的资源又相对缺乏,导致这方面的研究受限。
(3)基于机器学习分类的方法[10]。判断文本T和假设H之间是否存在蕴涵关系可视为二元分类问题,利用机器学习方法,在大量的已标注文本蕴涵对(就是文本T和假设H)语料上训练得到分类模型。在需要识别新的文本蕴涵关系时,利用训练到的模型进行分类。该类方法既需要有大量的已标注的正例和反例文本蕴涵对,在构造文本T和假设H的特征向量时,也需要有各种语言和世界知识资源。
在上述方法中,利用公理证明引擎或者规则推理的方案都需要大量的外部知识模式,但这些模式库无法在短时间内构建起来。因此,将各种相似度计算的结果加入到特征向量,并利用已有的机器学习方法进行蕴涵关系识别的处理方式则成为文本蕴涵研究的主流方向。但随之而来的问题是难以找到一种或几种能够有效表达两文本之间蕴涵关系的特征。原因在于绝大多数特征选取的过程中并没有将句法结构的信息融入进来,而缺少了句法信息的词汇语义叠加和统计对于句子一级语义的歧义性判别十分有限,进而影响文本对之间的蕴涵关系识别。
针对已有方法的不足,本文在相关统计特征、词汇语义特征的基础上,将句法信息融合到浅层特征中。通过对句法分析树的裁剪变换,最大程度保留与蕴涵判别相关的句法信息。通过现有的机器学习算法进行训练、预测,并通过语义规则的修正处理得到最终的识别结果。
2 文本蕴涵识别建模
2.1 模型框架
本文所提出的蕴涵识别系统,其模型由预处理、特征融合、分类器和修正模块4个部分组成,具体的模型结构如图1所示。
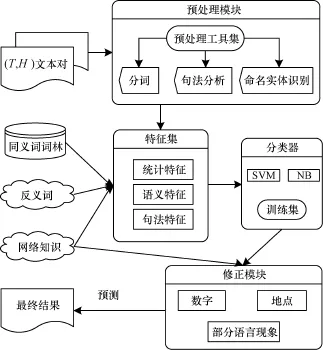
图1 本文模型结构
预处理模块的使用为文本的特征提取奠定了基础。本文系统主要使用了哈工大的LTP语言云作为分词和句法分析的工具,可以较好地完成预处理的相关工作。命名实体识别经过比较后决定采用了Stanford的分析器作为本文的处理工具。
2.2 传统特征集
本文使用统计机器学习方法对文本对进行分类时,利用了词的统计和语义特征进行蕴涵关系判别。
2.2.1 统计特征
系统利用词覆盖度fOverlap来表示文本对中相同词汇的重复率,采用如下公式:
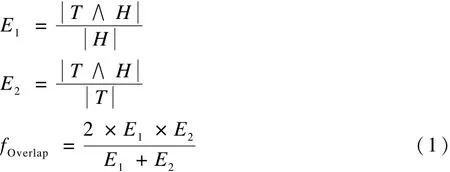
长度差fLength的特征有助于系统利用文本的长度进行蕴涵方向的辅助判定,公式为:
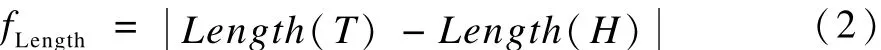
如果将文本表示成向量的形式,利用向量的余弦相似度比较文本的相似程度。余弦相似度fWordSim的定义如下:
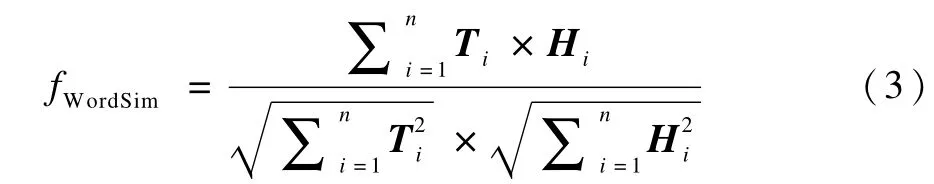
其中,向量Ti和Hi是由文本T和H生成的n维向量。
2.2.2 词汇语义特征
本文系统使用基于《同义词林(扩展版)》的语义相似度计算[11]的方法,通过式(4)来实现文本对中的词汇语义的计算。式(4)的w1i和w2j表示T和H经过分词后的词语,而simw(w1i和w2j)是w1i和w2j之间基于《同义词词林(扩展版)》的相似度。
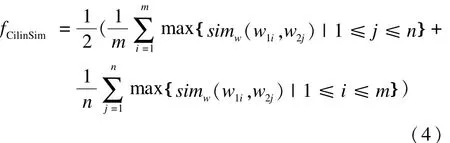
通过使用互联网上的反义词词典实现文本T和H中反义词的统计,得到的数量差作为一个特征fA。同理通过遍历2个文本对,得到否定词的个数,也作为一个特征fN加入到系统中。使用下式进行计算:
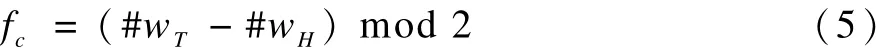
其中,c代表A或者N。
经过观察发现,命名实体出现的次数能在一定程度上反应文本对之间的蕴涵关系。因此,使用式(6)实现命名实体重叠度的计算:
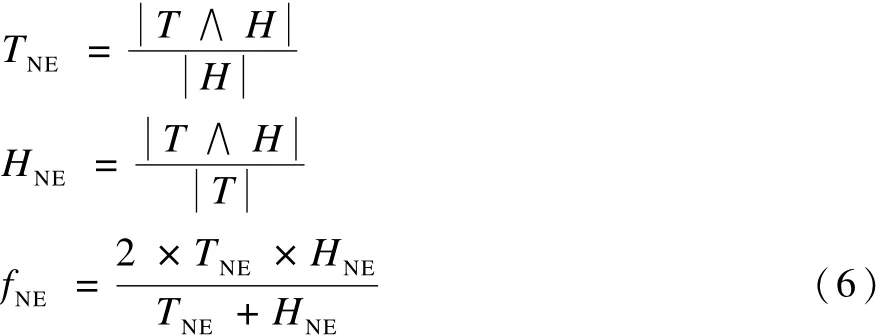
传统的特征工程可以在一定程度上表达文本对之间的蕴涵关系,但是并没有在句法结构和语义的层面解决这个问题。而所用的浅层词汇特征经常难以解释文本间语义的蕴涵关系。因此,本文将句法分析的结果融合到特征提取的过程之中,以检验中文句法结构特征对中文文本蕴涵识别的效果。
2.3 基于句法结构变换的句法特征
如前文所述,传统的特征工程是无法表达句法一级的蕴涵关系。下面的例子来自2014年NTCIRRITE3的测试语料:

一方面,这2句对话都拥有100%的字相似度,如果使用传统的特征,均会被判别为存在蕴涵关系。而事实上,第一个文本对T和H之间是不存在蕴涵关系的。因此,对句子本身的主谓、并列、从属等关系的获取可以大大提升系统的蕴涵识别能力。
而另一方面,过多的句法特征虽然保证了句法结构的完整性,但是对于蕴涵问题本身的解决是没有必要的。文本T蕴涵文本H意味着H中的全部信息一定可以在T中找到相同或近似的表述。因此,寻找2个文本中的公共字符串,不仅可以反映2个文本间信息的重叠程度,减少因中文分词工具对未登录词识别方面的错误而带来的对句子理解的影响,而且也可以减少需要处理的句法关系的数量。系统通过对句法分析后的节点进行聚合,将原本复杂的句法分析树变换成只包含影响蕴涵关系判别的最小信息树。
句法树结构变换的核心思想是通过聚合句法分析树的节点,将树中无用信息节点删除,生成2棵最小信息子树。例如:

两者的句法分析树形如图2所示。
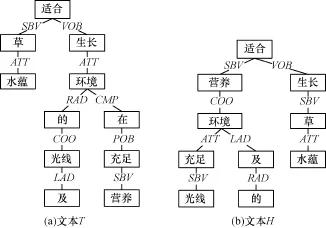
图2 实例的句法分析树
SBV,VOB等是哈工大LTP语言云对语言单位内成分之间的依存关系的分析结果,由于篇幅原因,详细内容请访问语言云官网。
“营养及光线充足的环境”是2个句子中的公共字串。除了公共字串部分之外,作为实体的“水蕴草”在两句均被错分成了2个词;左侧的句法树中“水蕴”、“草”、“适合”以及“生长”节点组成的子树会与右侧句法树中由“适合”、“水蕴”、“草”以及“生长”节点组成的子树进行近似子树的判别。若经过算法判定两者相似度大于阈值,则将句法树中的这些节点合并成一个节点,从而得到生成的最小信息树,如图3所示。

图3 实例的最小信息树
最小信息树裁剪算法如下:
输入 具有节点{ν1,ν2,…,νn}和{ν1′,ν2′,…,νn′}的句法树T,H,以及保存有节点间依存句法关系的结构体
输出 T,H生成的最小信息树Ti,Hi,保留了T,H之间信息蕴涵部分,删除原本2个句法树中与文本蕴涵识别无关的语义信息,使得T,H之间相对复杂的蕴涵关系可以用Ti,Hi最小信息树的方式表示
SteP1 令DT,DH为待处理节点集,其中,Di= Ø。然后利用KMP算法来寻找T,H中全部公共字符串作为独立子树dij加入Di,i=T,H。
SteP2 以较小的树为对象,寻找T,H所有的公共最大近似子树(表述相似的字串)。其中,最大近似子树的寻找采用字覆盖度的计算将可能作为最大近似的子树遍历搜索出来。经过反复人工调整、观察,当最终字覆盖度的值大于等于0.76时,利用式(2)进行判断,将满足最大近似子树的节点按原树Ti的组织形式diK加入到Di中;否则继续寻找,直到遍历完整个子树。寻找最大近似子树的节点不能涉及Step1中处理过的点。
SteP3 变换T和H,合并待处理Di中每个diχ所涉及的全部节点,新节点的位置由合并节点的最大父节点决定,选择完后从Di中删除。保留节点间的句法结构、节点到根节点的路径以及路径上的节点,直到Di为Ø。如果两子树中出现相同类型命名实体,即使不是同一个实体也保留其节点。
SteP4 删除T和H中没有处理过的节点,并输出生成最终的最小信息树Ti,Hi。
系统将2棵子树的词汇相似度定义为l,句法结构的相似度定义为s,相似度Sim的计算都采用式(7):
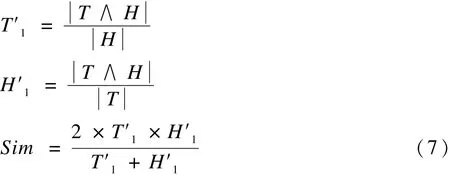
进而近似子树的相似度Simt测量定义为:

其中,0≤α,β≤1,α+β=1,通过人工调试和观察,当α=0.55,β=0.45时能相对较好地区别字符串是否近似。
最小信息树虽然在原句法树的基础上节点数量已大大减少,但是最小信息树本身依旧保留了一些语义特征。因此,对2个最小信息树相似度的比较不应仅仅使用统计特征。本文采用式(8),最大程度使用最小信息树中的特征进行相似度计算:
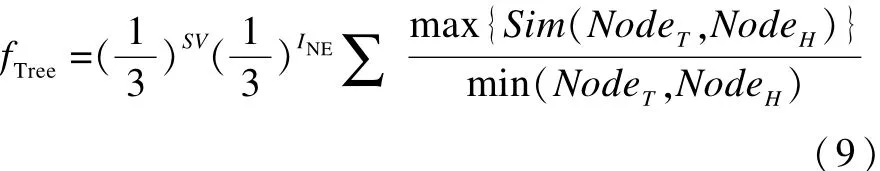
其中,INE表示命名实体判别结果,判别公式为:

SV是依存句法分析中主谓判断,判别公式为:

通过上述方式将部分的句法分析结果作为特征加入到系统中,然后通过基于高斯混合分布的朴素贝叶斯和支持向量机(Support Vector Machine,SVM)算法进行分类。
2.4 修正模块的介绍
2.4.1 数字归一化处理
和实际的语言现象相同,在RITE3的评测语料中也存在有同一个数字多种不同表达形式的问题。例如:
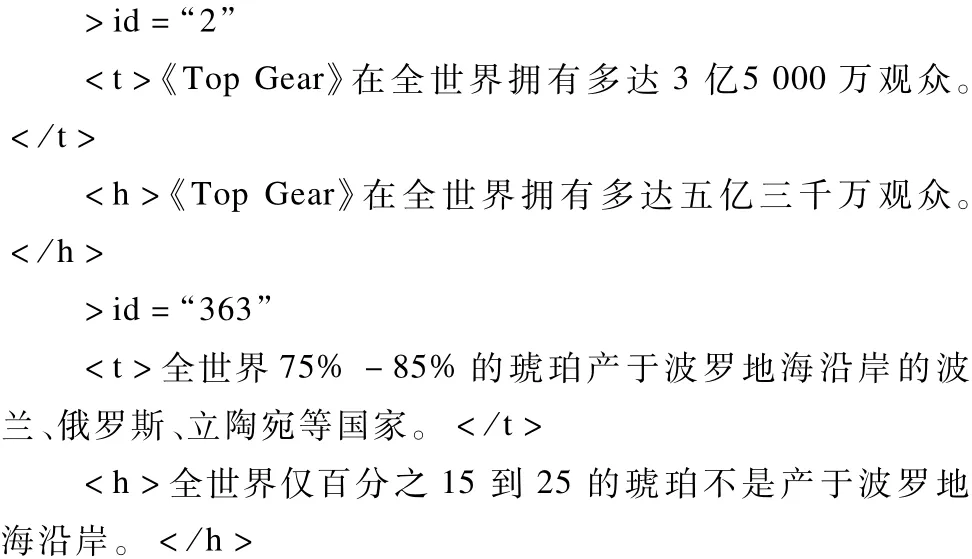
第1个例子中出现的现象只需要进行相关数字表述的归一化处理就可以判断出两句是不存在蕴涵关系的;第2个例子中,数字本身并没有直接关系,因此,两者蕴涵关系的识别需要进行简单的语义推理。针对这类现象,将否定词的出现作为对数字进一步处理的评判标准。
2.4.2 地点特征处理
对于地点特征的处理,仅仅依靠命名实体识别是无法满足文本蕴涵判别的需求。例如:

这2个实例都满足蕴涵关系,但中国和亚洲的上下位关系,以及夏威夷与它的别称檀香山的识别,只有通过维基百科等这样的世界知识才能够进行相关内容的判别。利用词条下的相关内容,根据关键字匹配,创建命名实体的等价或从属关系,就可以进行蕴涵判别。
3 评测结果与分析
3.1 评测语料与评价标准
日本国立情报学研究所(National Institute of Informatics,NII)组织的NTCIR(NII Test Collection for IR Systems)在2011年开始了文本蕴涵识别(Recognizing Inference in Text,RITE)方面的评测工作[12]。RITE的目的是评测系统识别特定语句关系的能力。本文所述的系统参加了2014年NTCIR-11中文简体RITE3任务,其中,用于训练的文本对个数为581,测试语料的文本对个数为1 200。评测的文本包括历史、政治、地理、体育等多种题材,覆盖了推理、复述、从句等诸多语言现象,较为全面地评估了系统的蕴涵判别能力。
系统的整体性能对于具体的文本蕴涵关系的识别主要包括如下性能参数,即准确率P(Precision)、召回率R(Recall)以及F值(F-measure),计算公式如下:


其中,文本之间的关系r包括蕴涵与不蕴涵2种情况。将准确率和召回率进行综合考虑的F值是RITE3评测的首要标准。
3.2 结果分析
表1是参与NTCIR RITE3中文简体蕴涵判别二分问题(蕴涵-不蕴涵)评测的系统中成绩最好的一些系统的性能指标[13],其中,NWNU系统为使用本文方法实现的系统。4个评测指标中,Macro-F1表示系统平均F值;ACC使用式(15)表示系统正确识别的总数,而不是2种关系判别的准确率的平均值;Y-F是系统关于存在蕴涵关系的文本对识别的F值;N-F则是系统针对不存在蕴涵关系的文本对识别的F值。
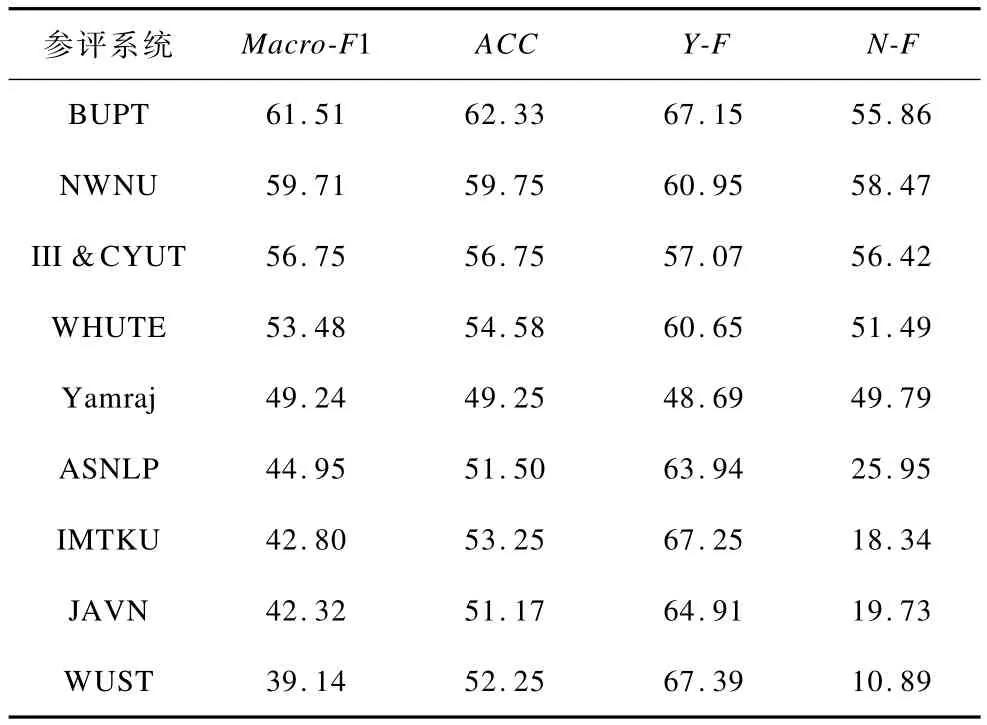
表1 NTCIR RITE3中文蕴涵识别评测结果%
可以看出,本文方法在Macro-F1,ACC,N-F均取得了不错的分值,高出平均Macro-F1值的49.99%近10%。
为了分析不同特征对蕴涵分类性能的影响,本文从基本的特征开始,逐渐添加其他不同的特征,从而形成了不同的系统版本。将这些使用了不同特征的系统提交给评测组织方,得到了不同版本系统的性能评测结果。表2给出了系统性能在融合不同特征后的表现。前4个系统采用基于混合高斯分布的朴素贝叶斯(Naive Bayesian,NB)作为分类器,第5个使用基于径向基函数的支持向量机作为分类器。表2中的Y-Prec,Y-Rec,N-Prec,N-Rec分别表示系统对存在蕴涵关系的文本对判别的准确率和召回率,以及系统对不存在蕴涵关系的文本对判别的准确率和召回率。

表2 不同特征对系统性能影响的评测结果%
由表2可知,NWNU-CS-SVBC-01系统仅仅使用了字覆盖度作为特征,45.82%的Macro-F值反映了评测语料的判别难度。NWNU-CS-SVBC-02是将前文提到的统计特征和词汇语义特征(包括词汇覆盖度、词汇余弦相似度、文本H与T的长度差、基于《同义词词林(扩展版)》的词汇相似度、否定词与反义词的数理差异等)加入之后得到的新系统,在F值和准确率上都有5%左右的性能提升。NWNU-CSSVBC-03系统则是进一步加入了基于句法结构变换的最小信息树特征fTree,该特征表现了部分句法结构信息对蕴涵关系识别的影响,系统的F值因而有了近7%的增长。NWNU-CS-SVBC-04和NWNU-CSSVBC-05系统将之前描述的修正模块加入到系统中,但收效甚微。分析原因,一方面可能是语言的多样性使修正模块的普适性受到限制;另一方面,修正模块最终处理的相关语料过少也影响了最终F值的提升。
从前2届RITE的语料训练结果来看,基于朴素贝叶斯的分类效果是所有统计机器学习算法中效果最好的,支持向量机则稍低于朴素贝叶斯的分类效果。但是当在NWNU-CS-SVBC-05系统中使用支持向量机作为分类器时却得到了所有系统中最好的F值。
然而,本文系统还存在两点不足。首先,由于不同类型语言现象对句法结构的依赖程度不同,因此本文对句法分析的统一处理必然会存在局限性,进而影响系统对蕴涵关系的识别。其次,系统对于推理和词汇蕴涵类型的识别能力较弱,需要引入层次化更清晰的世界知识作为蕴涵识别的资源。
4 结束语
以NTCIR-11的RITE3为评测标准,本文设计并实现了面向中文文本的蕴涵识别系统。该系统将统计特征、词汇语义特征,以及经过了句法结构变换的句法特征作为分类特征向量,使用传统机器学习算法实现蕴涵关系的判别。评测结果证明了其有效性。今后将尝试针对不同语言表述现象进行蕴涵问题的分析和处理,通过建立适合蕴涵识别问题的规则和层次化的世界知识来增强蕴涵的自动推理能力。
[1] Dagan I,Glickman O.Probabilistic Textual Entailment:Generic Applied Modeling of Language Variability[C]// Proceedings of PASCAL Workshop on Learning Methods for Text Understanding and Mining.Grenoble,France:Association for Computational Linguistics,2004.
[2] 袁毓林,王明华.文本蕴涵的推理模型与识别模型[J].中文信息学报,2010,24(2):3-13.
[3] Tatu M,Moldovan D.COGEX at RTE 3[C]//Proceedings of ACL-PASCAL Workshop on Textual Entailment and Paraphrasing.Prague,Czech Republic:Association for Computational Linguistics,2007:22-27.
[4] Harmeling S.Inferring Textual Entailment with a Probabilistically Sound Calculus[J].Natural Language Engineering,2009,15(4):459-477.
[5] Bar-Haim R,Berant J,Dagan I.A Compact Forest for Scalable Inference over Entailment and Paraphrase Rules[C]// Proceedings of Conference on Empirical Methods in Natural Language Processing.Singapore:Association for Computational Linguistics,2009:1056-1065.
[6] Malakasiotis P,Androutsopoulos I.Learning Textual Entailment Using SVMs and String Similarity Measures[C]// Proceedings of ACL-PASCAL Workshop on Textual Entailment and Paraphrasing.Association for Computational Linguistics.Prague,Czech Republic:Association for Computational Linguistics,2007:42-47.
[7] Maytham A,Allan R.Natural Language Inference for Arabic Using Extended Tree Edit Distance with Subtrees[J]. Journal of Artificial Intelligence Research,2013,48(5):1-22.
[8] 吴晓锋,宗成庆.基于语义角色标注的新闻领域复述句识别方法[J].中文信息学报,2010,24(5):3-9.
[9] Wang Xiaolin,Zhao Hai,Lu Baoliang.BCM I-NLP Labeled-alignment-based Entailment System for NTCIR-10 RITE-2 Task[C]//Proceedings of the 10th NTCIR Conference.Tokyo,Japan:National Institute of Informatics,2013:18-21.
[10] Galitsky B.Machine Learning of Syntactic Parse Trees for Search and Classification of Text[J].Engineering Applications of Artificial Intelligence,2013,26(3):1072-1091.
[11] 田久乐,赵 蔚.基于同义词林的词语相似度计算方法[J].吉林大学学报,2010,28(6):602-608.
[12] 刘茂福,李 妍,姬东鸿.基于事件语义特征的中文文本蕴涵识别[J].中文信息学报,2013,27(5):129-136.
[13] Suguru M,Yusuke M,Tomohide S,et al.Overview of the NTCIR-11 Recognizing Inference in Text and Validation(RITE-VAL)Task[C]//Proceedings of the 11th NTCIR Conference.Tokyo,Japan:National Institute of Informatics,2014:9-12.
编辑 刘 冰
Textual Entailment Recognition Fused with Syntactic Structure Transformation and Lexical Semantic Features
ZHANG Zhichang,YAO Dongren,LIU Xia,CHEN Songyi,LU Xiaoyong
(College of Computer Science and Engineering,Northwest Norm al University,Lanzhou 730070,China)
The traditional textual entailment recognition methods only stay at vocabulary level,not involving the influence of the syntactic and semantic aspects,and reduce the F value of the identification results.In order to solve this problem,a Chinese text recognition method is proposed which is fused with the transformation of syntactic structure and traditional lexical semantic characteristics.This method makes the text preprocessing based on syntax analysis tree transformation,adds the text contains identification features of syntactic analysis into related statistics and lexical semantic characteristics,uses the statistical machine learning methods to make entailment relationship classification of text T and assumptions text H,and gets the final recognition result through the correction processing of semantic rules.Evaluation results with NTCIR RITE3 show that compared with III&CYUT,Yam raj,etc,the method can obtain higher F value.
Chinese textual entailment;syntactic structure transformation;lexical semantic feature;lexical statistical feature;statistical machine learning
张志昌,姚东任,刘 霞,等.融合句法结构变换与词汇语义特征的文本蕴涵识别[J].计算机工程,2015,41(9):199-204.
英文引用格式:Zhang Zhichang,Yao Dongren,Liu Xia,et al.Textual Entailment Recognition Fused with Syntactic Structure Transformation and Lexical Semantic Features[J].Computer Engineering,2015,41(9):199-204.
1000-3428(2015)09-0199-06
A
TP399
10.3969/j.issn.1000-3428.2015.09.037
国家自然科学基金资助项目(61163039,61163036,61363058);西北师范大学青年教师科研能力提升计划基金资助项目(NWNULKQN-10-2,NWNU-LKQN-12-23)。
张志昌(1976-),男,副教授、博士,主研方向:自然语言处理,数据挖掘;姚东任、刘 霞、陈松毅,硕士研究生;鲁小勇,工程师。
2014-11-19
2014-12-18 E-m ail:zzc@nw nu.edu.cn
猜你喜欢
当代陕西(2021年18期)2021-11-27
家庭影院技术(2021年2期)2021-03-29
家庭影院技术(2021年1期)2021-03-19
作文大王·低年级(2019年4期)2019-05-13
中国自行车(2018年11期)2018-12-03
中国自行车(2017年1期)2017-04-16
山西青年(2017年7期)2017-01-29
国际汉语学报(2016年1期)2017-01-20
高校应用数学学报A辑(2016年4期)2016-07-10
四川师范大学学报(自然科学版)(2015年2期)2015-02-28
