
基于最大Jaccard相似度的互激励实体验证算法
2015-12-26 07:17刘宝超崔荣一
延边大学学报(自然科学版) 2015年1期
刘宝超, 崔荣一
( 延边大学工学院 计算机科学与技术学科 智能信息处理研究室, 吉林 延吉 133002 )
基于最大Jaccard相似度的互激励实体验证算法
刘宝超, 崔荣一*
( 延边大学工学院 计算机科学与技术学科 智能信息处理研究室, 吉林 延吉 133002 )
针对基于规则的信息抽取技术提出了一种互激励实体验证算法.该算法兼顾了信息抽取过程中互激励算法的优点,并在此基础上引入了实体等待队列,用于存储未被成功验证的实体,并以最大Jaccard相似度为原则进行实体验证.实验结果表明,将该算法应用在基于规则的参考文献命名实体抽取中,其抽取的准确率要比SermeX系统高约15%,比Para Tools系统高约40%.
互激励; 信息抽取; 参考文献; 实体验证
基于规则的信息抽取是应用比较广泛的一种抽取方式,一般包括规则获取和规则应用两个过程,其中规则获取是该方式中最为关键的部分,只要能够获取规则,抽取工作就完成了一大部分,而且抽取效率极高[1-2].可是,就抽取的准确率而言,基于规则的抽取方式要明显低于基于NLP(自然语言处理)和基于统计学习的方式,其原因在于该方式没有深入文本自身的含义,并且不考虑抽取结果的合理性,只要其符合抽取规则,就会被当作目标抽取出来[3].然而对于一些特殊领域的文本抽取,往往需要得到精确的抽取结果,因此鉴于上述情况,在抽取过程的最后阶段引入实体验证环节尤为重要[4].
科技论文中著录的文后参考文献属于半结构化的应用型文本,从众多样式的参考文献中自动提取出责任者、文献题名、出版地等信息是文献智能分析的重要内容之一[5-6].采用基于规则的信息抽取方式不仅可以实现对参考文献中责任者、文献题名、期刊名、会议名、卷期、时间等命名实体的抽取,同时该方法操作简单,而且抽取的准确率较高,是目前大部分信息抽取系统使用的主流抽取方式.例如CiteSeer系统就是采用启发式规则实现参考文献命名实体抽取的,并且该系统还能提供某一具体文献的“引用”和“被引用”情况以及文献的引用次数等信息[7].然而,这种仅按照启发式规则抽取的方式,其准确性仍依赖于被抽取文本自身的准确性和完整性[8].为了摆脱这种依赖和提高抽取准确率,本文在该抽取方法的最后阶段加入了实体验证环节,同时将改进的互激励算法(mutual bootstrapping)应用到该环节中,以进一步提高命名实体的抽取准确率.
1 互激励算法与原激励算法
互激励法无须指出所有实例与目标领域的相关性,但要给出一定量的种子词(关键词)进行整个过程的初始化.初始化首先由种子词获取一定量的规则模式,由于规则具有一定的普遍性,因此规则中所隐含的种子词一般要多于原来的种子词,只要充分利用信息抽取的规则模式,即可得到更多的种子词.在整个过程中,种子词推动规则模式的产生,而规则模式反过来又推动种子词的获取,形成相互激励的过程;反复该过程,直到没有新的符合要求的种子词或规则模式产生为止,即互激励过程结束[9-10].
当规则模式数量逐渐增多时,互激励法有可能将一定量的非种子词加入到种子词集中,使得算法效率和准确率降低,因此对新加入的种子词需要进行严格控制[11-12].多层激励法(multilevel level bootstrapping)又称为原激励法(meta bootstrapping),它在互激励法的基础上对种子词进行评分,通过分数值控制其是否能够加入到种子词集中,从而保证所选种子词的合法性,提高算法的效率.图1为互激励法与原激励法的关系,图2为改进的互激励法.
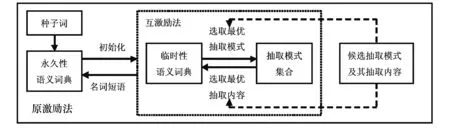
图1 互激励法与原激励法的关系

图2 改进的互激励法
2 互激励实体验证算法
Step 1 建立初始期刊名关键词库,
D ictionary={w1,w2,…,wn-1,wn},
(1)
其中wi(i=1,2,…,n)为种子词, n=|D ictionary|为种子个数.
Step 2 将种子词拆分得
wi={wi1,wi2,…,wimi} (i=1,2,…,n),
(2)
其中mi=|wi|为种子词wi的长度.
Step 3 将待验证的文献题名R_name和期刊名R_type按照Step 2的方法进行拆分得:
R_name={u1,u2,…,un},
(3)
R_type={v1,v2,…,vt},
(4)
其中n=|R_name|, t=|R_type|.
Step 4 按(5)式定义分别计算R_name和R_type与D ictionary的Jaccrad系数J(R_name,D ictionary)和J(R_type,D ictionary),
J(A,B)=|A∩B|/|A∪B|,
(5)
其中A和B为两个集合.
Step 5 按下式计算文献题名相似度SR_name和期刊名相似度SR_type:
SR_name=max(J(R_name,wk), 0≤k≤n);
(6)
SR_type=max(J(R_type,wk), 0≤k≤n).
(7)
Step 6 if (SR_name>SR_type), 判定文献题名与期刊名顺序书写颠倒,调整抽取内容,并将R_name加入到D ictionary中, R_type加入到文献题名数据库中.
Step 7 if (SR_name Step 8 if (SR_name==SR_type), 无法确定抽取的内容是否准确,将R_name放入文献题名临时等待队列, R_type放入期刊名临时等待队列. Step 9 若文献未全部验证结束,返回Step 3, 否则如果验证队列空则转Step 13. Step 10 验证等待队列中的文献题名R_name和期刊名R_type, 返回Step 6. Step 11 在验证等待队列中的实体若出现 if (SR_name==SR_type), 这时不再放入等待队列,而是利用文献题名数据库按(8)式和(9)式计算相似度,并记录循环次数flag. SR_name=max(J(R_name,w_nk),0≤k≤n); (8) SR_type=max(J(R_type,w_nk),0≤k≤n). (9) 式中w_nk是按照Step 2中的方法对文献题名数据库中已验证成功的文献题名进行拆分的结果. Step 12 通过文献题名数据库验证时也出现SR_name==SR_type, 则说明文献题名和期刊名相同. Step 13 结束. 因为文献类型相对好确定,种子词获取相对容易,所以本文在Step 1中建立了一个初始文献题名关键词库,种子词wi(i=1,2,…,n)的选取是通过统计足够多的学位论文文后参考文献之后确定的出现最多的前n个关键词.Step 2中中文种子词拆分单位为汉字,而英文种子词拆分单位为空格. 在Step 8中导致无法确定的原因可能有两点: 1) D ictionary中的词数量过少,导致计算后SR_name==SR_type==0; 2) R_name和R_type本身很相似,如R_name=“中文信息学报发展综述”, R_type=“中文信息学报”,使得SR_name==SR_type≠0. 本文通过准确率P、召回率R和F(measure)值这3个常用指标对实验结果进行评价,这样可以较好地与SemreX和Para Tools系统所得结果进行比较,其计算公式如下: P=A/(A+C), (10) R=A/(A+B), (11) F=(α2+1)P*R/(α2P+R), (12) 其中: A表示提取的样本中抽取正确的文献数; B表示未能正确提取的文献数; C表示提取的样本中抽取错误的文献数; F为综合评价指标; α越大, R对F的影响越大,本文中取α=1. 实验数据由某高校计算机类硕士学位论文中著录的文后参考文献构成,共计741条,其中中文参考文献582条,英文参考文献159条.对每一条参考文献,根据参考文献信息抽取规则进行命名实体抽取,并计算出P,R,F值,然后与SemreX系统和Para Tools系统进行比较,对比结果见表1.由表1可以看出,本文抽取的各项指标的平均值要高于SemreX系统约15%,高于Para Tools系统约40%.另外,SemreX系统和Para Tools系统中所用的抽取方法只适用于英文文献的抽取,而本文提出的方法可以适用于中/英文文献的抽取,扩大了抽取范围. 本文针对基于规则的信息抽取技术提出了一种互激励实体验证算法,并将其应用在参考文献命名实体抽取中,实验结果表明:①在信息抽取中引入实体验证环节,能有效减少对抽取文本自身含义准确性的依赖;②在实体验证环节,将规则学习阶段的互激励法进行了改进,引入了实体等待队列,使得最终抽取的结果其P,R,F值3项指标远高于SemreX和Para Tools系统.由于本算法没有对D ictionary进行优化,存在运行时间较长的不足,因此本文将在今后的研究中运用组合数学原理和遗传算法等对D ictionary进行优化,以提高抽取效率. 表1 实验结果对比 [1] 李洪亮,黄莉.基于规则的百科人物属性抽取算法的研究[D].成都:西南交通大学,2013:11-25. [2] 李湘东,霍亚勇,黄莉.图书网页的自动识别及书目信息抽取研究[J].现代图书情报技术,2014(4):71-74. [3] 郭志鑫,金海,陈汉华.SemreX中基于语义的文档参考文献元数据信息抽取[J].计算机研究与发展,2006,43(8):1368-1374. [4] Cheng Xianyi, Zhu Qian, Wang Jin. The Principle and Application of Chinese Information Extraction[M]. Beijing: Science Press, 2010:181-182. [5] 孙明,陆春生,徐秀星,等.一种基于SVM和AdaBoost的Web实体信息抽取方法[J].计算机应用与软件,2013,30(4):101-106. [6] 张秀秀,马建霞.PDF科技论文语义元数据的自动抽取研究[J].现代图书情报技术,2009(2):102-106.[7] Li Chaoguang, Zhang Ming, Deng Zhihong, et al. Automatic metadata extraction for scientific documents[J]. Computer Engineering and Applications, 2002,21(10):189-191. [8] Liu Wei, Yan Hualiang. A unified and automatic web news object extraction approach[J]. Computer Engineering, 2012,38(11):167-169. [9] Zhang M, Yin P, Deng Z H, et al. SVM+BiHMM: a hybrid statistic model for metadata extraction[J]. Journal of Software, 2008,19(2):358-368. [10] Wang Shuang. Research of web information extraction technology oriented to digital tourism website[D]. Xi’an: Xidian University, 2012. [11] 龚立群,马宝英,常晓荣.科技文献元数据自动抽取研究综述[J].计算机系统应用,2013,22(3):11-15. [12] 杨春磊,邵堃基.基于模式匹配的结构化信息抽取研究[D].合肥:合肥工业大学,2013:11-30. [13] 陈先军.文后参考文献引著质量及其审查方法[J].中国科技期刊研究,2014,25(9):1145-1148. Mutual incentive entity verification algorithm based on the max Jaccard similarity LIU Baochao, CUI Rongyi* (IntelligentInformationProcessingLab.,DepartmentofComputerScience&Technology,CollegeofEngineering,YanbianUniversity,Yanji133002,China) The technology of information extraction rules is proposed based on a mutual incentive entity authentication algorithm. The algorithm has both advantages of information extraction in the process of incentive algorithm, and on the basis of introducing the entity waiting queue, used to store has not been successfully verified entity, with the max Jaccard similarity principle of entity authentication. The experimental results show that, if the algorithm is applied in the reference named entity extraction, the extraction precision is higher than SermeX system about 15%, and is higher than Para Tools system about 40%. mutual incentive; information extraction; reference; entity verification 2014-12-07 基金项目: 吉林省科技发展计划项目(20140101186JC) 1004-4353(2015)01-0042-04 TP391.1 A *通信作者: 崔荣一(1962—),男,博士,教授,研究方向为模式识别、智能计算.3 实验结果及分析
4 结论
猜你喜欢
西江月(2021年2期)2021-11-24
中国卫生产业(2020年26期)2020-12-28
糖尿病新世界(2020年17期)2020-11-28
科学导报·学术(2020年26期)2020-10-21
小学生学习指导(低年级)(2020年4期)2020-06-02
软件(2020年3期)2020-04-20
国际比较文学(中英文)(2019年1期)2019-11-12
青年文学家(2016年32期)2016-12-23
东方教育(2016年4期)2016-12-14
中华奇石(2015年7期)2015-07-09
