
数据包位图索引压缩算法研究
2016-02-06 02:21袁沐春郭育辰
网络安全技术与应用 2016年8期
◆袁沐春 郭育辰
(中国人民公安大学 北京 102600)
数据包位图索引压缩算法研究
◆袁沐春 郭育辰
(中国人民公安大学 北京 102600)
为解决从存储海量数据包的数据库中快速找到少量的被需要的数据包的时间效率问题,本文引入位图索引数据库,并对三种常见的位图索引压缩算法做简要分析。
数据包;位图索引;数据库;算法
0 引言
传统的关系型数据库是面向更改的,存储在数据库中的数据需要经常改动。而位图索引数据库专门为科学数据设计,这些数据通常是由科学仪器或是科学仿真产生的,特点是数据量极其大,而且不再更改。位图索引数据库解决了如何在存储海量数据包的数据库中快速地找出那些少量被需要的数据包的问题,而传统的关系型数据库并不适合这项任务。
位图索引数据库中用到的技术主要是位图索引、位图压缩和归类。在位图索引数据库中,数据是按列存储的,一个列的数据存储在一起,并做位图索引。一个简单的位图索引的例子如表1所示。其中RowID表示对应值在表中第几行,生成的索引是一个矩阵,矩阵中每一行只有一个1,其余都是0,标1的位置对应于该行数据在这一列上的取值。这样生成的位图索引有一个比较大的缺点,索引的列数随着取值的多样性而线性增长。为了控制索引的大小和查询时间,需要对索引压缩和归类。压缩是减小索引中大量0带来的空间消耗,归类是对位图索引的一些列的合并。比如值1.01和1.02可以归类成1。通过归类可以减少位图索引的列数,增加查询和存储的效率。
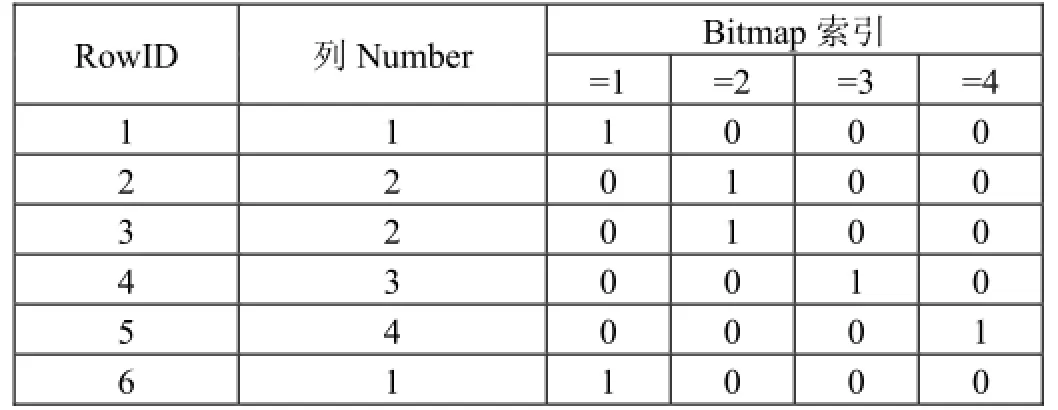
表1 位图索引示例
下面主要研究三种位图索引压缩算法WAH[1]、PLWAH[2]、COMPAX[3]。
1 WAH索引压缩算法
WAH索引压缩算法示例如表2所示。

表2 WAH索引压缩算法示例
WAH算法是FastBit索引数据库的默认算法,将位序列分成以31b(对于WAH64就是63b)为单位的group。这样,group有两种类型。
(1)Literal,即这31b中有0有1。
(2)Fill,即这31b全为0或者全为1。
在WAH算法中,最终形成的word是32b,其中最高位为类型的标志位。Literal类型的Group:类型标志位为0,余下的31b即为原来的literal group;Fill类型的Group:分为1-Fill和0-Fill。此时32b中类型标志位为1,第二位作为Fill类型的标志(0-Fill即为0,1-Fill即为1),余下的30b作为counter,表示连续出现多少个0-Fill(或者1-Fill)的 group。
2 PLWAH算法及改进
PLWAH算法和WAH算法类似,同样是将原始码流分成以31b为单位的group。Group也和WAH算法中提到的相同,一样分成Literal和Fill两种类型,但是压缩方式有变化,具体如下所示。
第一步:依照WAH算法对于Fill-Group和Literal-Group添加标志位与编码,形成一组以32b为单位的编码(标志位为0称为literal-word,标志位为1称为fill-word,下同)。此处的区别是对于fill-word只有低25b作为counter(WAH算法是低30b都是counter,PLWAH要留出中间的5b作为position list)。
第二步:检查每个fill-word后的word。如果下一个word是literal-word且是nearly identical(表现为literal-word和上一个fill-word的差异小于等于s位,s此处暂且为1),则在fill-word的position list上填入下一个word(此时为literal-word)的差异位位置(此处是31b,因此差一位标号是1~3,留出5b目的在此),同时删去下一个word(因为信息已经保存在此fill-word中,没有必要继续留着),若fill-word后的word是如下三种情况:
(1)异类型的fill-word。
(2)非nearly identical的literal-word。
(3)同类型的fill-word(这种情况产生的原因是连续的fill-group超出了1个fill-word的counter计数范围),则position list不变。
进行扩展讨论:
对于32位PLWAH,由于nearly identical的定义中的s不为1,则在第一步时需要留出5*s位nearly identical,余下的32-2-5*s位为counter。在第二步时,向fill-word中的position list添加差异位时需按序添加差异位位置(5b标识一个差异位,5*s位标识至多s个差异位),当s=0时,PLWAH退化为WAH。
对于64位PLWAH,position list以6为单位,即留出6*s位作为position list,余下的64-2-6*s位为counter。
以PLWAH32,s=1为例,对PLWAH进行了小幅改进,即考虑连续出现极多的0或者1以至于1个word的counter无法完全容纳。此处选用的方法为使用两个连续的同类型fill-word,把两个counter部分视为一个大的counter,第一个fill-word记录LSB25位,第二个fill-word记录MSB25位(相当于50b的大counter),同时第一个fill-word的position list为空,第二个fill-word的position list照常计算,如表3所示。这样的好处是无需扩展word位数即可完成对更多连续码流的编码任务,节约index空间。
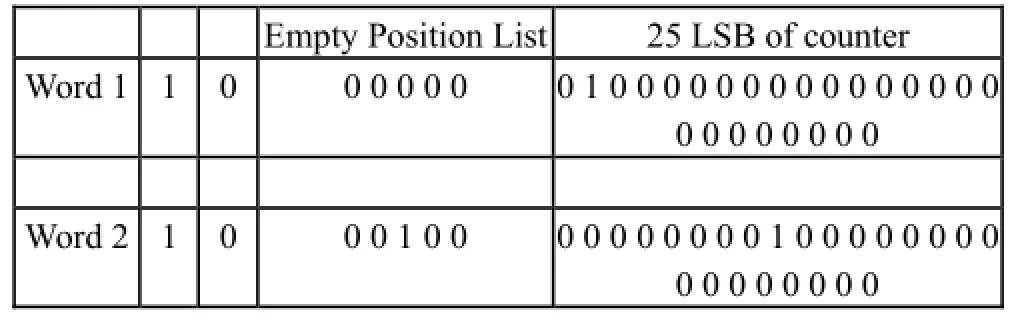
表3 PLWAH改进举例

25 MSB of counter
3 COMPAX算法
COMPAX压缩算法示例如图1所示。
COMPAX算法也是WAH的改进,这里以32b为例,但COMPAX的标志位相对较多。这里Literal和Fill的定义同WAH和PLWAH。同样是每31b分成一个group,并且将这些group按照以下特征分组。
(1)Literal-Fill-Literal(LFL),即一个literal group +N个Fill group+1个literal group,且这两个literal group 的非0位(或者非1位)在同一个byte上(一个group在前面补一位0即构成4个完整的byte,要求非0位在同一个完整的byte上)。
(2)Fill-Literal-Fill(FLF),即N个Fill-group+1个literal group+N个fill-group(对literal group要求同上)。
(3)Fill(F),分为0-Fill和1-Fill,无法按照(1)和(2)进行分组的fill-group即归入此类型。
(4)Literal(L),无法按照(1)和(2)进行分组的literal group 即归入此类型。
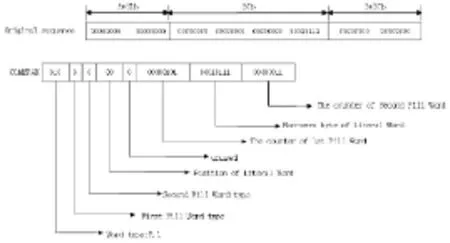
图1 COMPAX压缩算法示例
对于这4种类型,就有4种不同的word。
(1)L-word第一位为标志位1,余下31b即为原来的literal group。
(2)F-word第一位为标志位0,对于0-Fill第二、三位为00,对于1-Fill第二、三位为11。余下29b位counter,即记录有多少个连续这样的group。
(3)LFL-word第一位为标志位0,第二、三位为01,第四、五位标识第一个literal group的非零字节位置(共4b,标号为0~3),第六、七位标识第二个literal group的非零字节位置(共4b,标号为0~3),第八位标识F类型,0为0-Fill,1为1-Fill;第九到十六位为第一个literal group中非零字节,第十七到二十四位为Fill的counter,标示有多少个连续的fill group,第二十五到三十二位为第二个literal group中的非零字节。
(4)FLF-word第一位为标志位0,第二、三位为10,第四、五位为第一个fill的类型(0-Fill为00,1-Fill为11),第六、七位为第二个fill的类型,第八位空闲。第九到十六位为第一个fill的counter,第十七到二十四位为literal group的非零字节,第二十五到三十二位为第二个fill的counter。
在已知COMPAX的情况下,具体读码方式如下:
(1)如果第一位为1,为L-word。
(2)如果第一位为0;
1第二、三位为00:0-fill-word。
2第二、三位为11:1-fill-word。
3第二、三位为01:LFL。
4第二、三位为10:FLF。
4 结语
随着互联网的普及渗透,网络日常运营中生成积累的用户行为数据往往达到TB级甚至PB级。本文对数据包查询优化过程中的三种位图索引压缩算法进行研究改进,以期为庞大的数据流量管理与网络流量档案化提供更多的技术手段。
[1]Wu K,Otoo E J,Shoshani A.Optimizing bitmap indices with efficient compression[J].Acm Transactions on Database Systems,2006.
[2]Deli&#,ge,Fran&#,Pedersen T B.Position list word aligned hybrid:optimizing space and performance for compressed bitmaps[C]//EDBT 2010,13thInternational Conference on Extending Database Technology,Lausanne,Switzerland,March 22-26,2010.
[3]Fusco F,Stoecklin M P,Vlachos M.Net-Fli:On –thefly Compression,Archiving and Indexing of Streaming Network Traffic.[J].Proceedings of the Vld Endowment,2010.
猜你喜欢
中学生数理化·中考版(2021年10期)2021-11-22
销售与市场(营销版)(2021年10期)2021-11-21
铁道通信信号(2019年9期)2019-11-25
销售与市场(营销版)(2019年6期)2019-06-21
疯狂英语·新读写(2018年2期)2018-11-29
网络安全技术与应用(2017年9期)2017-09-20
数字技术与应用(2017年3期)2017-05-17
中学生数理化·七年级数学人教版(2017年12期)2017-04-18
电脑知识与技术(2014年13期)2014-07-18
城市建设理论研究(2012年35期)2012-04-23
