
基于社交影响力的推荐算法
2016-02-27 03:41陈升波孙知信
计算机技术与发展 2016年6期
房 旋,陈升波,宫 婧,,孙知信
(1.南京邮电大学 计算机学院、软件学院,江苏 南京 210003;2.南京邮电大学 理学院,江苏 南京 210023;3.南京邮电大学 宽带无线通信与传感网技术教育部重点实验室,江苏 南京 210003)
基于社交影响力的推荐算法
房 旋1,陈升波2,宫 婧2,3,孙知信3
(1.南京邮电大学 计算机学院、软件学院,江苏 南京 210003;2.南京邮电大学 理学院,江苏 南京 210023;3.南京邮电大学 宽带无线通信与传感网技术教育部重点实验室,江苏 南京 210003)
社交网站的兴起促使社交推荐成为了推荐系统领域的热门研究方向。微博是一类具有代表性的社交网站,其用户之间以一对多的不对等关系为主,如何为微博用户推荐潜在的关注对象是社交推荐中的一个重要研究点。文中针对微博类社交网站中用户间关系不对等的特点,结合用户间的交互行为信息,提出了一种社交影响力的计算方法,并在此基础上提出基于社交影响力的推荐算法(SIB)。该算法通过计算用户社交影响力矩阵,然后使用K个最近邻(K-NearestNeighbor,KNN)算法找出目标用户的邻居集合,借助邻居集合帮助推荐。该算法综合考虑了微博社交网站中的两种社交关系,能有效地对微博类社交网站进行个性化推荐。通过在真实数据集上进行实验,证明该算法在微博类社交网站中的推荐效果比单纯的基于用户协同过滤(User-basedCollaborativeFiltering,UCF)算法有一定程度的提升。
社交网络;微博;社交影响力;协同过滤;推荐算法
1 概 述
随着网络技术的发展,为用户提供个性化推荐成为了目前互联网服务的一个重要内容。推荐系统[1]的概念最早是在1997年提出的,一开始主要被用在电商网站中,向用户推荐感兴趣的商品[2]。
推荐系统的核心是推荐算法。早期的推荐算法主要分为基于内容的推荐算法和协同过滤算法。
基于内容的推荐算法的核心就是提取物品的特征,然后用TF-IDF方法计算各个特征的权重[3],并根据这些特征与用户的喜好进行匹配,从而向用户进行推荐。相比于多媒体信息(视频、音频、图片等),文本类项目(新闻、网页、博客)的特征相对容易提取,因而基于内容的推荐方法在文本类推荐领域得到了广泛应用。
协同过滤算法主要分为两大类:基于记忆(memory-based)和基于模型(model-based)[4]。基于记忆的方法又可以分为基于用户(user-based)[5]和基于项目(item-based)[6]的方法。基于用户的协同过滤算法思想是找到和目标用户相似的邻居用户,利用邻居用户的评分来估计目标用户的评分。基于项目的协同过滤算法认为,不同项目之间存在相似性,当需要估计目标用户对某个项目的评分时,可以根据该目标用户对相似项目的评分进行估计。
基于模型的推荐算法主要是利用数据挖掘、机器学习和概率统计等方法,对用户的历史行为数据进行分析,建立用户模型,从而进行推荐[7]。
虽然协同过滤算法的商业应用非常成功,但是其存在的问题也不容忽视。冷启动和数据稀疏性是协同过滤算法最突出的两个问题。
近年来,随着Facebook、腾讯微博等社交网站的兴起,如何利用用户与用户之间的社交关系进行个性化推荐成为了研究的热点。社交关系中包含了大量信息,如果能充分挖掘并利用好这些信息,可以在一定程度上缓解传统协同过滤算法存在的问题,对后者是一个有效的补充,可以改善推荐的效果。文献[8]利用Social Networks Analysis (SNA)理论分析微博内容,从中提取出关键词作为特征图谱,并以此来构建用户与用户以及用户与商品之间的关系,从而进行商品推荐。文献[9]认为在社会语境中存在两个有效的语境因素—个体偏好和人际影响,可以将用户-项目矩阵分解成用户-项目偏好矩阵和用户-项目影响力矩阵,并据此提出了一种基于社会语境的推荐框架。文献[10]重新定义了社交网络中的相似度属性、相似度构成及其计算方法,提出了一种改进的协同过滤推荐算法。文献[11]则从待推荐对象间的关系出发,提出了一种结合推荐对象间关联关系的社会化推荐算法。Nirmal Jonnalagedda等在文献[12]中提出了利用Twitter来提取用户的兴趣爱好和新闻的流行程度,进而向用户提供个性化的新闻推荐。文献[13]提出利用目标用户的历史数据构建一个个性化的候选项排序模型,同时提出一种具备多种推荐策略的推荐系统,可以向Twitter用户推荐一些值得关注的对象。
上述研究表明,大多数算法把重心放在对用户历史评分信息或者文本内容的挖掘上,对于社交关系中包含的互动信息仍未能进行充分挖掘,推荐的准确度仍有提高的空间。针对这一问题,文中引入社交影响力的概念,在基于用户的协同过滤算法的基础上,提出一种基于社交影响力的SIB(Social Influence-Based)推荐算法,并对其推荐效果进行验证。
2 SIB推荐算法
传统的基于用户的协同过滤算法通过计算用户相似度矩阵,来寻找用户的最近邻居。这里的相似度矩阵是一个对称矩阵,即认为用户与用户之间的关系是对等的。
然而在社交关系中,用户与用户之间不一定是对等关系。现实生活中也是这样,两人即使是好友,对方在自己心目中的地位和自己在对方心目中的地位也不一定完全对等,只能说好友之间的关系的对等程度普遍要大于陌生人。因此,文中采用社交影响力来描述用户与用户之间的社交关系。社交影响力表示的是单向的社会关系,这比传统的相似度更加适用于社交场景。
2.1 算法介绍
SIB推荐算法通过挖掘用户之间的社交关系数据,建立用户之间的社交影响力矩阵,从而为用户提供推荐。该算法流程见图1。

图1 融合社交网络信息的协同过滤算法流程
首先根据用户评分信息计算出用户之间的相似度,然后根据用户的社交信息计算出用户的基础影响力,通过线性融合的方式将二者结合起来,形成影响力矩阵。接着对用户的影响力进行排序,找到对目标用户影响力最大的K个邻居用户,利用这些邻居用户对待预测项目的评分估计目标用户对待预测项目的评分,挑选出预测评分最高的L个项目作为推荐列表。
2.2 相关定义
在微博系统中,用户的社交关系主要有两种(如图2所示):一种是关注/被关注的静态关系;另一种是提及(mention)/转发(re-post)/评论(comment)的动态的互动关系。同一个用户的关注用户集合和互动用户集合并不一定完全重合。关注/被关注的关系用关注影响力来衡量,用follow表示;互动关系用互动影响力来衡量,用interact表示。文中利用关注影响力和互动影响力来计算用户之间的社交影响力。

图2 微博系统中的两种社交关系
定义1:关注影响力follow(u,v)。
(1)
其中,outDegree(u)指用户u关注的人数,在社交图中用顶点的出度表示。
关注影响力的含义如下:
(1)如果用户u和用户v互相关注了对方,那么u和v很可能互相认识,甚至是现实中的朋友。在这种情况下,他们之间有相似爱好的可能性很大,同时他们推荐给对方的东西更容易被接受,即他们对对方都有较大的影响力。
(2)如果用户u关注了v,而v未关注u。这种情况可能是因为v的某些方面是u所喜欢的,u是v的“粉丝”。那么可以认为v对于u是有一定影响力的,而u对于v则没有什么影响力。在这种情况下,考虑到有些用户倾向于关注很多对象,其关注行为的价值就会变低,而有些用户倾向于关注少量对象,其关注行为的价值就会比较高,因此将用户u关注的人数纳入计算。用户u关注的人越多,其中某个被关注对象v对他的影响力就会降低。
(3)如果用户u和用户v都没有关注对方,那么他们之间的关注影响力为0。
定义2:社交行为action(u,v)。
社交行为指提及(mention)、转发(re-post)和评论(comment)。action(u,v)表示用户u对用户v发起的社交行为的次数,具体来说就是u提及v的次数(at(u,v))、u转发v的微博次数(re(u,v))以及u评论v的微博次数(com(u,v))三者之和。
定义3:互动影响力interact(u,v)。
interact(u,v)=
(2)
其中,action(u,v)表示用户u对用户v发起的社交行为次数;actionSum(u,v)表示u,v之间的互动总次数;MIN_ACTION_SUM是一个阈值,当u,v之间的互动总次数小于这个阈值时,互动影响力设为0,以减少噪音。
互动总次数的公式如下:
actionSum(u,v)=action(u,v)+action(v,u)
(3)
f1是一个系数,其计算公式为:
(4)
函数f(x)定义如下:

(5)

(6)
其中,R表示的是用户u对用户v发起的社交行为次数占u,v之间互动总次数的比重,该值越大说明u越关注v。
当R=0时,说明u根本不关注v,则v对u的影响力为0;
当R大于0小于0.5时,说明u不是很关注v,但v对u的影响力会随着R的增大而增大;
当R=0.5时,说明u,v之间的互动关系是比较平衡的,基本上是“有来有往”,那么u和v是好友的可能性很大,可以认为此时v对u的影响力最大;
当R大于0.5小于1时,说明u很关注v,但v不是很关注u,可以认为u是v的“粉丝”,此时v对u的影响力比较大,但会随着R的增大而减小;
当R=1时,说明v根本不关注u,u单方面关注v,此时v对u还是有一定影响力的,但不如好友对其的影响力大,将影响力的值定义为最大值的0.8倍。
定义4:基础影响力BaseInfluence(u,v)。
BaseInfluence(u,v)表示用户v对用户u的基础影响力。基础影响力越大,用户v推荐给用户u的东西被接受的可能性越大。
BaseInfluence(u,v)=
(7)
定义5:用户相似度[14]similarity(u,v)。
用户相似度是根据用户的历史评分信息计算出来的用户之间的相似程度。在基于用户的协同过滤算法中,常用的计算用户相似度的方法有余弦相似度、皮尔森相关系数、杰卡德相关系数等。
杰卡德相关系数衡量的是两个集合之间的相似程度,它更加适合于描述离散值集合的相似度。微博系统中的评分正好是离散的:接受推荐用1标注,拒绝推荐用-1标注,未表态用0标注。因此文中采用杰卡德相关系数来计算用户之间的相似度是合适的。
用户u和用户v之间的相似度用杰卡德相关系数表示如下:
其中,l{x}是一个指示函数,如果x值为真,则l{x}值为1;如果x值为假,则l{x}值为0。rui和rvi分别表示用户u和用户v对项目i的评分。I(u)和I(v)分别表示用户u和用户v有评分的项目集合。
定义6:社交影响力SocialInfluence(u,v)。
SocialInfluence(u,v)=(1-δ)•similarity(u,v)+ δ•BaseInfluence(u,v)
(9)
其中,similarity(u,v)是用户u和用户v的相似度;BaseInfluence(u,v)是用户v对用户u的基础影响力;δ是系数。
通过上述公式得到任意用户v对任意用户u的社交影响力,N个用户的社交影响力就构成一个N×N维的社交影响力矩阵。
有了社交影响力矩阵以后,就可以采用KNN算法[15]寻找目标用户影响力最大的K个用户,因为社交数据的稀疏性,为了避免邻居用户和目标用户之间影响力过小造成计算不准确,因此采用基于阈值的KNN算法。首先设定一个影响力阈值MIN_INFLUENCE,只有影响力大于这个阈值的用户才会被加入邻居集合,虽然这样得到的邻居数可能少于K个,但可以提高推荐准确度。
2.3 算法设计
算法1:寻找用户u的最大影响力邻居集合。
输入:社交影响力矩阵I,目标用户u,邻居数K,影响力阈值MIN_INFLUENCE;
输出:邻居集合N(u)。
S1:找出所有对u的影响力不为0的用户,加入邻居集合,并按照影响力倒序排列;
S2:取邻居集合最后一个用户,判断影响力是否大于阈值,如果是,转S3,否则转S4;
S3:判断当前邻居数是否大于K,如果是,转S4,否则转S5;
S4:将该用户从邻居集合中删除,转S2;
S5:返回邻居集合。
有了最大影响力邻居集合以后就可以根据邻居用户的评分信息来预测目标用户对未知项目的评分。预测用户u对未知项目i的评分采用如下公式:
(10)
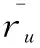
有了目标用户对未知项目的评分,就可以从未知项目中找出预测评分最高的L个项目,组成推荐集合推荐给目标用户。
算法2:SIB推荐算法。
输入:用户列表,用户评分数据,用户社交数据,目标用户u,邻居数K,推荐列表长度N,阈值MIN_ACTION_SUM、MIN_INFLUENCE;
输出:为目标用户u生成的推荐结果列表R。
S1:根据用户评分数据计算用户之间的相似度,得到用户相似度矩阵S;
S2:根据用户社交数据和阈值MIN_ACTION_SUM计算用户之间基础影响力,得到基础影响力矩阵B;
S3:根据社交影响力生成公式计算社交影响力,得到社交影响力矩阵I;
S4:根据算法1计算得到目标用户u的最大影响力邻居集合N(u);
S5:根据评分预测公式预测目标用户u对所有未知项目的评分,并将评分按照从高到低排序,取预测评分最高的前L个项目组成推荐列表R,推荐给目标用户u;
S6:算法结束。
3 实验设计及分析
3.1 实验数据及评价标准
为了验证文中提出算法的有效性,用KDD CUP 2012 Track1数据集进行实验。下面简要介绍一下所采用的数据集的基本情况。
KDD CUP 2012 Track1数据集中的数据来源于腾讯微博的真实数据,其中包含了1 000万用户和5万个项目,以及3亿条推荐记录和大约300万个社会网络的“关注(following)”行为。其中,用户对项目关注情况采用-1、0、1三个数值表示:接受关注用1表示,拒绝关注用-1表示,未表态用0表示。除此之外,该数据集中还包含用户属性、用户社交关系等信息。
由于原数据集比较庞大,为了提高实验效率,从原数据集中随机抽取一部分作为实验数据。在该实验中,随机抽取了3 000个用户对2 740个项目的关注信息,以及这3 000个用户的社交关系数据作为训练集。同时还随机抽取了500个用户作为测试集。
3.2 实验评估指标
实验采用的评价指标是MAE。MAE指标衡量的是推荐算法的准确率,值越小越好。
MAE计算的是预测评分和实际评分之间的平均误差,其定义为:
(11)
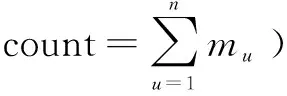
3.3 实验结果及分析
设定推荐列表长度L=5,BaseInfluence所占比重δ={0.2,0.4,0.6}。对于每个δ,都考察不同邻居数K情况下的实验结果,K={2,4,6,8,10,12,14,16,18,20},并且和传统UCF算法进行比较,见图3~5。

图3 δ取0.2时算法MAE指标随着邻居数K的变化曲线
从实验结果可以看出,文中提出的基于用户社交影响力的SIB推荐算法较传统UCF算法在推荐准确率上有所提升。因为社交数据相对于用户评分数据更为稀疏,随着δ值的变大,或多或少会引入噪声,影响SIB算法的推荐效果。但总体上可以看出,挖掘用户的社交数据对于提升推荐算法的推荐效果有着积极意义,尤其是针对微博类社交网站中用户关系不对等的特点,SIB算法中建立的影响力模型能够较好地描述这一特点。

图4 δ取0.4时算法MAE指标随着邻居数K的变化曲线

图5 δ取0.6时算法MAE指标随着邻居数K的变化曲线
4 结束语
在社交网站中,丰富的社交关系数据具有非常大的利用价值。利用用户的社交关系数据辅助推荐是目前社交类推荐系统研究的热点。微博系统作为目前非常流行的社交系统,有其自身的特点。好友关系在微博系统中并不是主要的社交关系,更多的是关注与被关注的关系。如何能更好地描述用户与用户之间这种不对等的社交关系,对于提升微博类社交网站的推荐效果有很大的意义。基于这方面的考虑,文中提出的SIB推荐算法充分利用了用户关注数据和互动数据,不仅在一定程度上可以缓解冷启动问题,而且对于传统UCF算法是一个很好的补充,提高了推荐算法的准确率。
后续研究需要继续考虑微博系统的特点,继续对其中的社交数据或者文本数据进行分析挖掘。例如,可以考虑微博内容的“话题性”、微博名人的领域权威性、被推荐对象之间的关联关系以及被推荐对象对普通用户的影响力等等。社交系统中的信息非常丰富,数据量非常大,也可以考虑对数据进行分布式处理,这样可以对更多的数据进行挖掘,提高处理的效率。
[1]ResinickP,VarianHR.Recommendersystems[J].CommunicationsoftheACM,1997,40(3):56-58.
[2]LindenG,SmithB,YorkJ.Amazon.comrecommendationsitem-to-itemcollaborativefiltering[J].IEEEInternetComputing,2003,7(1):76-80.
[3] 王嫣然,陈 梅,王翰虎,等.一种基于内容过滤的科技文献推荐算法[J].计算机技术与发展,2011,21(2):66-69.
[4]BreeseJS,HeckermanD,KadieC.Empiricalanalysisofpredictivealgorithmsforcollaborativefiltering[C]//Proceedingsofthe14thconferenceonuncertaintyinartificialintelligence.[s.l.]:[s.n.],1998:43-52.
[5]ResnickP,IakovouN,SushakM,etal.GroupLens:anopenarchitectureforcollaborativefilteringofnetnews[C]//Proceedingsofthe1994computersupportedcooperativeworkconference.[s.l.]:[s.n.],1994:175-186.
[6]SarwarB,KarypisG,KonstanJ.Item-basedcollaborativefilteringrecommendationalgorithms[C]//Proceedingsofthe10thinternationalconferenceonworldwideweb.[s.l.]:[s.n.],2001:285-295.
[7] 陈克寒,韩盼盼,吴 健.基于用户聚类的异构社交网络推荐算法[J].计算机学报,2013,36(2):349-359.
[8]ChangPei-Shan,TingI-Hsien,WangShyue-Liang.Towardssocialrecommendationsystembasedonthedatafrommicroblogs[C]//Procofinternationalconferenceonadvancesinsocialnetworksanalysisandmining.[s.l.]:IEEE,2011:672-677.
[9]JiangMeng,CuiPeng,WangFei,etal.Scalablerecommendationwithsocialcontextualinformation[J].IEEETransactionsonKnowledgeandDataEngineering,2014,26(11):2789-2802.
[10] 荣辉桂,火生旭,胡春华,等.基于用户相似度的协同过滤推荐算法[J].通信学报,2014,35(2):16-24.
[11] 郭 磊,马 军,陈竹敏,等.一种结合推荐对象间关联关系的社会化推荐算法[J].计算机学报,2014,37(1):219-228.
[12]JonnalageddaN,GauchS.Personalizednewsrecommendationusingtwitter[C]//ProcofIEEE/WIC/ACMInternationalconferencesonwebintelligenceandintelligentagenttechnology.[s.l.]:IEEE,2013:21-25.
[13]IslamM,DingChen,ChiChi-Hung.Personalizedrecommendersystemonwhomtofollowintwitter[C]//ProceedingsofIEEEfourthinternationalconferenceonbigdataandcloudcomputing.[s.l.]:IEEE,2014:326-333.
[14]DengYingying,LuTun,XiaHuanhuan,etal.AOPUT:arecommendationframeworkbasedonsocialactivitiesandcontentinterests[C]//ProceedingsofIEEE17thinternationalconferenceoncomputersupportedcooperativeworkindesign.[s.l.]:IEEE,2013:545-550.
[15] 黄创光,印 鉴,汪 静,等.不确定近邻的协同过滤推荐算法[J].计算机学报,2010,33(8):1369-1377.
A Recommendation Algorithm Based on Social Influence
FANG Xuan1,CHEN Sheng-bo2,GONG Jing2,3,SUN Zhi-xin3
(1.School of Computer Science,School of Software,Nanjing University of Posts and Telecommunications,class="content_center">Nanjing 210003,China;2.College of Mathematics & Physics,Nanjing University of Posts and Telecommunications,Nanjing 210023,China;3.Key Laboratory of Broadband Wireless Communication and Sensor Network Technology,Nanjing University of Posts and Telecommunications,Nanjing 210003,China)
The rise of social networking sites promotes social recommendation becoming the research hotspot in the field of recommender systems.As a representative social network,Weibo has unequal one-to-many relationship between users.How to recommend potential Weibo users concerned is an important research direction in the social recommendation.Aiming at the characteristics of unequal relationship between users in social network of Weibo,combined with the mutual behavior information between users,a computing method of social influence is proposed and on the basis,a SIB algorithm is also presented.By calculating the social influence matrix of user,this algorithm uses the KNN algorithm to find the target user set of neighbors,and helps to recommend with the aid of neighbors set.The algorithm considers the two kinds of social relations for social network in Weibo,which can effectively conduct personalized recommendation for social networking sites in Weibo.The experiment shows that the SIB algorithm can effectively improve the accuracy of recommendation system in social networks compared with UCF algorithm.
social network;Weibo;social influence;collaborative filtering;recommendation algorithm
2015-09-12
2015-12-16
时间:2016-05-25
国家自然科学基金资助项目(60973140,61170276,61373135);江苏省产学研项目(BY2013011);江苏省科技型企业创新基金(BC2013027);江苏省高校自然科学研究重大项目(12KJA520003);江苏省大学生创新创业训练计划项目(201410293023Z)
房 旋(1990-),男,硕士生,研究方向为移动开发、推荐系统;宫 婧,副教授,研究方向为计算机应用技术;孙知信,教授,研究方向为计算机应用技术。
http://www.cnki.net/kcms/detail/61.1450.TP.20160525.1706.036.html
TP
A
1673-629X(2016)06-0031-06
10.3969/j.issn.1673-629X.2016.06.007
猜你喜欢
意林彩版(2022年2期)2022-05-03
新班主任(2022年4期)2022-04-27
好日子(2021年8期)2021-11-04
科学大众(2020年23期)2021-01-18
第一财经(2020年4期)2020-04-14
汽车观察(2019年2期)2019-03-15
文苑(2018年17期)2018-11-09
NBA特刊(2018年14期)2018-08-13
人大建设(2017年11期)2017-04-20
中国卫生(2016年5期)2016-11-12
