
基于小字符集藏文拉丁转写系统的设计与实现
2016-05-04 00:41陈小莹艾金勇
中文信息学报 2016年3期
陈小莹,艾金勇
(1.西藏民族大学 信息工程学院,陕西 咸阳 712082;2.西藏民族大学图书馆,陕西 咸阳 712082)
基于小字符集藏文拉丁转写系统的设计与实现
陈小莹1,艾金勇2
(1.西藏民族大学 信息工程学院,陕西 咸阳 712082;2.西藏民族大学图书馆,陕西 咸阳 712082)
随着藏语语言信息技术的迅速发展,藏文拉丁转写成为迫切需要解决的重要课题之一。该文在前人有关藏文拉丁转写研究的基础上,设计并实现了基于小字符集方案的藏文拉丁转写系统。文章通过对小字符集编码方案的特征分析,同时根据藏文正字法知识,提出了基于小字符集编码的藏文拉丁转写算法,并对具体算法策略进行了分析和说明,最后在Windows平台进行了程序的实现。藏文拉丁转写方案的设计与实现,可以解决藏文多编码系统之间的兼容性问题。
藏文;拉丁转写;小字符集;占位辅音
1 引言
在国内外藏学研究领域,藏文拉丁转写实现了现代藏文与拉丁转写之间的相互转换。近年来,由于藏语语言信息技术的迅速发展,拉丁转写形式不仅可以作为多文种少数民族文字处理平台上文字的识读和研究工具,还可以解决藏文多编码系统之间的兼容性问题,前期已经有不少学者进行了相关的研究。陈丽娜等在《藏文拉丁转写的研究与实现》一文中针对大字符集编码的字符特征在OpenOffice.org中实现了藏文的拉丁转写[1]。民族所的江荻研究员在《藏文的拉丁字母转写方法》一文中系统的阐述了藏文的拉丁转写原则和目前拉丁转写方案,并归纳出比较全面的藏文拉丁字符字母转写的规则[2]。祁坤钰等在2008年《基于国际标准编码系统地藏文拉丁文转写规则模型》一文中针对基本集编码体系,提出了藏文变长序列码到拉丁文转写的转换模型,文中并没有涉及具体的算法[3]。康才畯等在《基于Unicode编码的藏文转写拉丁文本的算法》中虽然提出了关于Unicode编码的藏文拉丁转写算法,但是关于藏文黏写字符等特殊现象并没有针对性的处理,而在现代藏文中这种现象还是普遍存在的[4]。综上所述,尽管在藏文拉丁转写方面前期已经有了相当多的成果,但是在小字符集编码的藏文拉丁转写的具体实现上还有待进一步的研究。基于此,本文基于小字符集编码体系,提出藏文拉丁转写算法,并在Windows 平台下设计实现了该算法。
2 现代藏文音节的结构和编码特点
2.1 现代藏文的结构特点
书面藏语的“字”是由藏文字符和梵音藏文等字符构成的,共有30个辅音字母,10个梵音藏文字母,5个元音符号和3个梵音藏文元音符号,其中[a]为零位元音[5]。藏文的基本单位是音节,音节与音节间用音节符“.”分隔,句子与句子之间用单垂符“|”分隔,段落与段落之间用双垂符“||”分隔。每个藏文音节结构上由“基字”、“上加字”、“下加字”、“前加字”、“后加字”、“重后加字”以及元音组成,它不仅具有横向拼写性,同时也具有纵向拼写性,其中前加字、基字、后加字与重后加字横向拼写。而在纵向上可能有上加字、基字、下加字和元音的纵向拼写。构成藏文字的前加字、基字、上加字、下加字、后加字、重后加字和元音统称为藏文字的部件。每个结构位置上的部件都有固定的构造规则,除开基字外所有结构位置上的部件都可以空缺。
2.2 藏文的编码特点
在藏文信息处理中存在两种不同的字符集编码和实现方案。一种是以藏文编码字符集基本集为基础,以垂直预组合的方法显示藏文,简称大字符集法。另一种是基于ISO/IEC 10646(Tibetan)的藏文编码方案,以动态组合的方法显示藏文,简称小字符集法。大字符集主要是在计算机中以上下叠加的字母作为一个整体进行编码的,这种方法将需要动态组合的上加字、基字、下加字和元音组合成为一个字丁,对每个字丁在藏文编码字符集中进行编码。但是这种方式的处理会导致大量的兼容字符,从而增加了系统处理的复杂性。而且这种方式需要对现有的藏文数据的所有组合方式进行预组合,难以实现所有系统的兼容。小字符集方法是将藏文完全按拼音文字处理,以其基本组成构件,包括元音字符、辅音字符、上下加字等为基本编码对象进行编码的方法,这是完全符合ISO的所有评估程序和批准原则的一个方案,是目前国际上较为流行的一种藏文编码方案。而且随着计算机技术的进一步发展,国际标准的小字符集可以胜任任何应用,目前大字符集实际已经被大多数系统放弃。
3 系统结构
现代藏文拉丁转写系统的结构如图1所示。整个现代藏文拉丁转写系统从功能上可以分为知识库管理与维护、藏文文本预处理、藏文字丁部件分解和拉丁转写四个主要模块。下面分别介绍各个模块的功能和实现方式。
3.1 藏文文本预处理
藏文文本预处理模块主要有藏文特殊字符的规范化处理和藏文黏着词的分离和还原两个部分,针对现代藏文文本中出现的特殊现象进行处理,以得到规范化的藏文音节字。
3.1.1 特殊字符的规范化处理
藏文文本中除了包括正常的规范字符外,还可能会出现英文缩略词、简写词、数字、符号等一些不属于藏文字符的其他字符,这些不属于藏文字符的其他字符直接影响着文本信息处理的正确性,所以在拉丁转写之前应该要进行规范化处理。
处理方式主要是归纳现代藏文中出现的一些非规范字的类别,并给出它们在规范化藏文词表上的规范写法,提取出转换规则,建立相应的规则知识库。在遇到此类特殊字符时只需要按照相应的规则进行转换即可。
3.1.2 黏写字符的处理

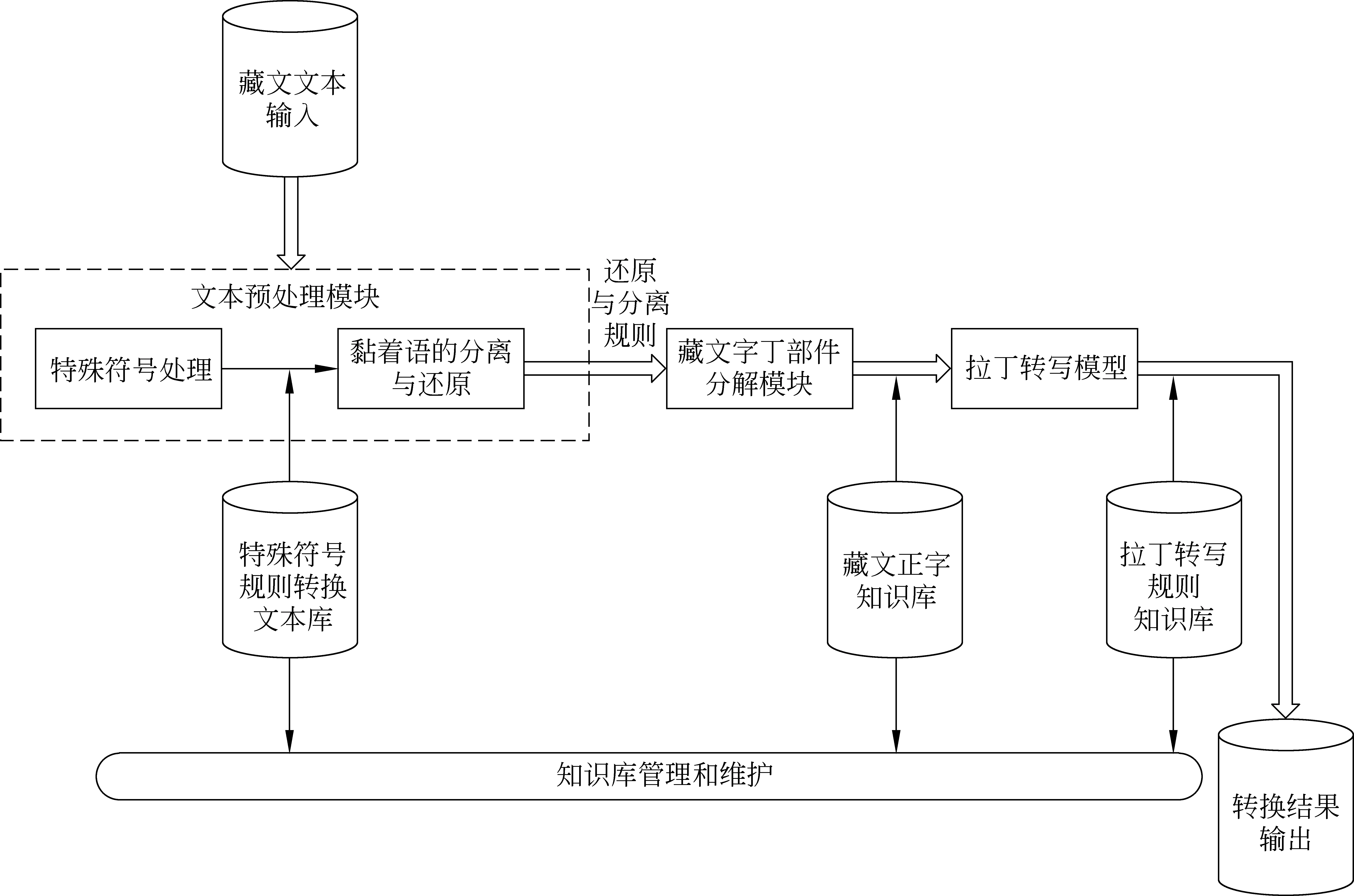
图1 拉丁转写系统结构图
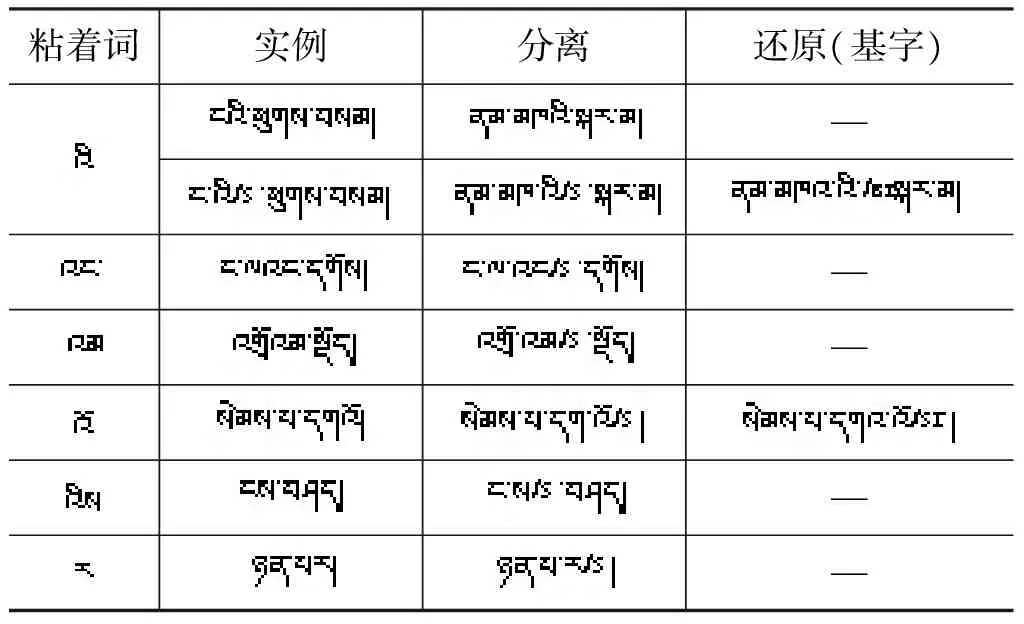
粘着词实例分离还原(基字)—————
其中表中字母s表示此音节字是分离后得到的,sr表示此音节字是分离后对前一音节字做还原后得到的。
3.2 知识库管理和维护
该模块的主要功能是维护和管理拉丁转写系统中所设计的三个知识库的规范和管理,即对系统中需要调用的藏文正字知识库、特殊符号特征规则库、拉丁转换规则知识库内容的完善和维护,以便数据的有效调用和管理。
3.3 藏文字丁部件分解3.3.1 小字符集编码特点
3.3.2 藏文字丁部件的识别
藏文字丁部件分解根据藏文音节构字规则及藏文小字符集编码的特点分解各个位置上的字符。其核心在于寻找藏文的基字丁。
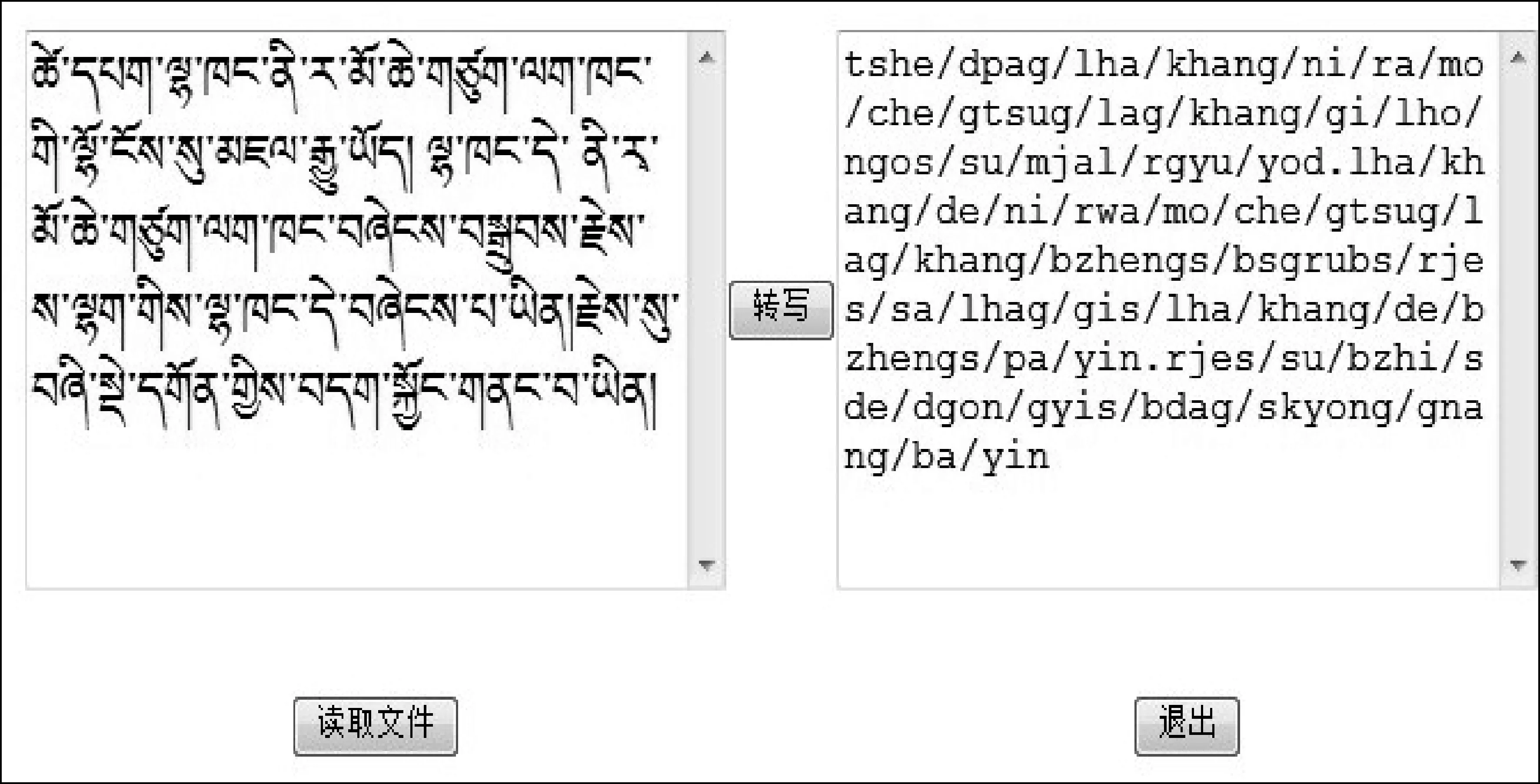
若令C表示藏文占位辅音编码集合,V表示藏文元音字符编码集合,NC表示藏文非占位辅音编码的集合,同时根据藏文本身特征,设定下加字集合U,则U属于NC,同时设定音节中编码字符串为l1l2……ln(1= 1) 输入音节字符串l1l2……ln,根据字符串匹配法找出其在集合C、V和NC中的字串C1C2……Cm、Vt和NC0NC2……NCk。k的值获取后可根据以下几种情况定位基字的位置并确定各部件字符。 2) 若k=2,则该音节中非占位辅音编码串为NC1NC2,此时由小字符集编码的特征判定此时组合字符中必定包含上加字和下加字,而按照藏文输出顺序,就可以确定出两个非占位辅音NC0NC2分别为基字丁Ba和下加字Up,从而确定出基字丁位置。 4) 若k=0,则该音节中无非占位辅音编码串,表明该藏文音节没有上加字和下加字形式存在。此时判定基字位置需要依据元音字符进行判定。若t>0,则可以判定元音前面的辅音字符必定为基字。如果t=0,则需要根据音节宽度进行进一步判别,判别时利用藏文正字法进行分别讨论得出对应的基字Ba。 待基字编码串Ba确定后,再根据Ba是否属于集合NC进一步来判定其他部件的位置。如果Ba属于NC,则其后面的占位辅音依次为后加字和重后加字。前面紧挨着该辅音字符的必为上加字,若前面还有占位字符,则为前加字;否则该藏文音节中一定不存在上加字,其后的占位辅音依次为后加字和重后加字,其前面的占位辅音为前加字。最后根据得到的结果确定出各位置上的部件编码。 3.4 转写规则 藏文拉丁字母转写是指在不必理解词句语义的情况下,按照读音将藏文字母转换成拉丁字母的方法。对于藏语文字信息处理而言,拉丁转写更多的是作为现代藏语的识读和研究工具,因此本文以藏文的音节为基本单位,依据音节的组织结构,对音节的各个部分分别进行转写,实现了基于现代藏语语音的声韵母转化方案。 前面已经确立了藏文音节的各部分部件,但是由于组合型梵音藏文字符的存在,所以还需要进行特殊处理,首先判断藏文音节中不带音基字丁是否存在于文献[11]所列举的新创字符表中,若存在则将其作为一个整体进行拉丁转换。否则就根据藏文音节的声韵母组合方式进行组合就可以了。藏文单音节的声母=前加字+不带音基字丁,韵母=元音+后加字+重后加字。对照藏文拉丁转写规则知识库后,得到藏文声母和韵母各自对应的拉丁字母串。则藏文对应的拉丁转写=声母拉丁转写+韵母拉丁转写。转化过程中提出以下几个规则。 规则1 按照声韵母拼读方式对藏文音节中各部件依次读取,然后参照民族所江荻研究员文献[11]中提出的藏文拉丁转写系统实现转写。 规则2 藏文转写成拉丁字母时,转写后的符号一律使用小写字母。 规则3 不带元音符号的藏文音节字,则默认被转写成包含元音“a”,该元音被放在韵母前边。 在计算机Windows平台下,随机选取了部分藏文文本进行了拉丁转写测试,转写主要是藏文到拉丁文的转写。抽取的文本分别来自藏文主流网站的新闻和个人网页中的藏文文章。图2是测试样例中截取的一部分。 图2 藏文文本及转换结果 测试结果表明,在转换过程中会出现两种错误,一种是因为部分藏文文本不符合现代藏文的构字方法,所以在基字确定上出现错误从而造成转写不正确,这种情况系统会在可能错误的转写字符处高亮显示出来以便人工修改;还有一种情况是由于黏写字符以及文本规范化过程中的处理结果不准确而造成的转写错误,这种情况还需要人工针对新的文本情况进行问题分析并修正相应的规则。 论文中主要讨论了基于小字符集编码的藏文音节拉丁转写的实现方法。本文采用的拉丁转写规则依据藏语声韵母体系进行,规则中只需要完善藏文声母拉丁对照表和藏文韵母拉丁对照表,就可以转换所有的藏字,所需要的库很小,可移植性强。但是由于藏文本身存在一些梵文和外来的新造词,这些词语在基字判别上可能会出现错误,因此需要在以后的工作中进一步完善部件识别规则,最终实现一个完整的藏文转写拉丁字母系统。 [1] 陈丽娜.藏文拉丁转写的研究与实现[J].计算机工程与设计,2006,01: 15-17. [2] 江荻.藏文的拉丁字母转写方法[J]. 民族语文,2006,01: 45-53. [3] 祁坤钰.基于国际标准编码系统的藏文拉丁文转写规则模型[J]. 西北民族大学学报(自然科学版),2008,03: 15-18. [4] 康才畯,江荻. 基于Unicode编码的藏文转写拉丁文本的算法[A].中国中文信息学会.中国计算语言学研究前沿进展(2009-2011).中国中文信息学会,2011: 5. [5] 江荻,周季文. 论藏文的序性及排序方法[J]. 中文信息学报,2000,01: 56-64. [6] 才旦夏茸.藏文文法详解[M].西宁:青海民族出版社,1988. [7] 关白,才科扎西.现代藏文音节字自动校对研究[J]. 计算机工程与应用,2012,29: 151-156. [8] 才智杰.藏文自动分词系统中紧缩词的识别[J]. 中文信息学报,2009,01: 35-37. [9] 扎西次仁.国际标准藏文计算机编码字符集的研究[J]. 中国藏学,1995,02: 127-143. [10] 周季文.藏文拼音教程[M],北京: 民族出版社,1983,10. [11] 江荻,龙从军.藏文字符研究: 字母、读音、编码、字频、排序、图形、拉丁字母转写[M],北京: 社会科学文献出版社,2010,08. Design and Implementation of the Tibetan Transcription SystemBased on Small Character Set CHEN Xiaoying, AI Jinyong (1. School of Information Engineering,Tibet University for Nationalities,Xianyang,Shanxi 712082,China;2. Library of Tibet University for Nationalities,Xianyang,Shanxi 712082,China) With the rapid development of information technology in Tibetan language,Tibetan transcription into Latin becomes an important issue. This article designs and realizes such a transcription system that based on a small character set. According to the Tibetan orthography knowledge,the paper proposes the transcription algorithm according the characteristics of a small Tibetan/Latin character set encoding. The implementation of the Tibetan Latin transcription system can solve compatibility issues between the different Tibetan codes. Tibetan; Latin transliteration; small character sets; placeholder consonant 陈小莹(1983—),实验师,硕士,主要研究领域为实验语音学及计算机应用。E⁃mail:ajycyt@126.com艾金勇(1983—),馆员,硕士,主要研究领域为藏文信息处理。E⁃mail:ajy0529@126.com 2014-05-20 定稿日期: 2014-11-06 西藏自治区科技厅项目(2015ZR-14-19) 1003-0077(2016)03-0074-05 TP391 A
4 转写结果测试
5 结语

猜你喜欢
考试与评价·八年级版(2021年4期)2021-08-14
西藏研究(2021年1期)2021-06-09
考试与评价·八年级版(2020年3期)2020-11-02
考试与评价·八年级版(2020年6期)2020-11-02
布达拉(2020年3期)2020-04-13
VOGUE服饰与美容(2019年4期)2019-06-11
西夏学(2019年1期)2019-02-10
中央民族大学学报(自然科学版)(2018年1期)2018-06-27
快乐作文·低年级(2017年9期)2017-10-11
老年世界(2017年2期)2017-03-16
