
基于Spark的PFP?Growth并行算法优化实现
2016-05-14 09:17方向张功萱
现代电子技术 2016年8期
方向 张功萱

摘 要: 随着数据量的增大,FP?Growth算法压缩数据思想的优势就体现出来,基于MapReduce框架的PFP?Growth算法实现该算法在Hadoop平台上的并行化,但是MapReduce框架每次对作业进行操作都要将中间结果输出存储到磁盘,影响算法的效率。为了提高关联挖掘的效率,基于Spark平台,运用均衡分组的思想对该算法进行改进,同时在对具有很长前缀情况进行共享前缀的拆分,通过4个步骤使IPFP?Growth算法在Spark上实现。实验结果表明在Spark平台上优化过后的算法在性能上要优于PFP?Growth算法。
关键词: 并行化; Spark; 关联挖掘; PFP?Growth
中图分类号: TN911?34 文献标识码: A 文章编号: 1004?373X(2016)08?0009?05
Optimization of parallel FP?Growth algorithm based on Spark
FANG Xiang, ZHANG Gongxuan
(School of Computer Science and Engineering, Nanjing University of Science and Technology, Nanjing 210094, China)
Abstract:The advantage of the FP?Growth algorithm for compressing data is reflected with the increasing of the data size. With the MapReduce framework, the PFP?Growth algorithm can be parallelized on the Hadoop platform. However, when processing tasks with the MapReduce framework, the intermediate results need to be written to the disk, which will affect the efficiency of the algorithm. Therefore, based on Spark platform, this algorithm was improved according to the concept of balanced grouping to improve the efficiency of association mining. In addition, if there is a long prefix, the improved algorithm will split the shared prefix. The IPFP?Growth is implemented in Spark through four steps. The experimental results show that the performance of the algorithm optimized in Spark is superior to that of the PFP?Growth algorithm.
Keywords:parallelization; Spark; association mining; PFP?Growth
0 引 言
由于频繁项挖掘Apriori算法需要频繁的访问数据库,造成了很大的开销,Han等人在2000年提出了一种基于内存存储结构的挖掘算法FP?Growth[1],它将数据库所有的事务压缩到一个FP?Tree数据结构中使整个数据库能够保存在内存中,只需要访问两次数据库就可以完成频繁项的挖掘。Li等人在2008年基于MapReduce框架实现了该算法的并行化即PFP?Growth算法[2]。但是MapReduce框架处理数据时会造成巨大的I/O开销,因为每一次MapReduce过程就是对磁盘进行一次读/写操作,其中shuffle过程为了容错还需要将中间结果存储到磁盘,增加了计算的时间,影响算法的效率。由于数据量的不断增加,传统的数据挖掘算法不能充分的发挥算法的效率,分布式并行处理是挖掘大规模数据的理想解决方案,文献[3]就是利用分布式来解决频繁项集的挖掘。文献[4?6]基于MapReduce框架对该算法的并行化实现,文献[7]从数据压缩的结构上考虑提出了一种使用位存储来进行挖掘频繁项,文献[8]在原算法的基础上添加了负载均衡的思想,对算法的性能有一定的提升。但以上文献都是基于Hadoop平台,即使在数据量不大的情况下得出结果仍需要很长的时间,在如今的大数据环境下并不适合在实际生产环境中的应用。
Spark是一个类似于Hadoop MapReduce的通用的并行计算框架,Spark拥有MapReduce框架所有的优点,比MapReduce更加优秀的一方面是,Spark所有计算的结果都可以保存在内存中,对于迭代的运算效率更加高。另一方面,Spark有着比MapReduce更多的算子,这使得在编写程序时有着更多的灵活性。
因此,本文基于Spark并行计算平台,对需要大量迭代计算的PFP?Growth算法在分组策略上进行了改进,在FP?Growth算法的挖掘过程中对具有共享前缀的情况下做了优化,同时运用了Spark一些优点,然后将改进过的算法在Spark平台上实现。
1 背 景
1.1 Spark对数据的操作方式
Spark基于内存的计算方式,提高了在当前大数据环境下数据处理的实时性,同时具备了高容错性和高伸缩性,允许用户将其部署在大量廉价的硬件之上,形成集群[9]。它和Hadoop 2.X生态系统可以实现无缝的衔接。Spark将分布式数据抽象为弹性分布式数据集RDD(Resilient Distributed Datasets),将一切对数据的操作转化为对RDD的操作。
对RDD的操作主要包括两种:Transformation(T)和Action(A)。T操作的输入类型是RDD,输出类型也是RDD;A操作的输入类型是RDD,输出类型是一个值或者一个数组。由于对RDD的操作是惰性的,T操作只是表明该操作被请求,而没有对具体的数据进行操作,只有出现了一个A操作以后,数据的读写请求才能真实的在集群上触发。这样的好处就是可以减少T操作的所要存储的中间数据。根据这个特性在编写程序的过程中就需要减少A操作的频率。文献[10]就是在Spark平台实现了频繁项挖掘Apriori算法的并行化,其实验结果也说明了在Spark平台上实现并行化算法具有很高的效率。
1.2 FP?Growth算法介绍
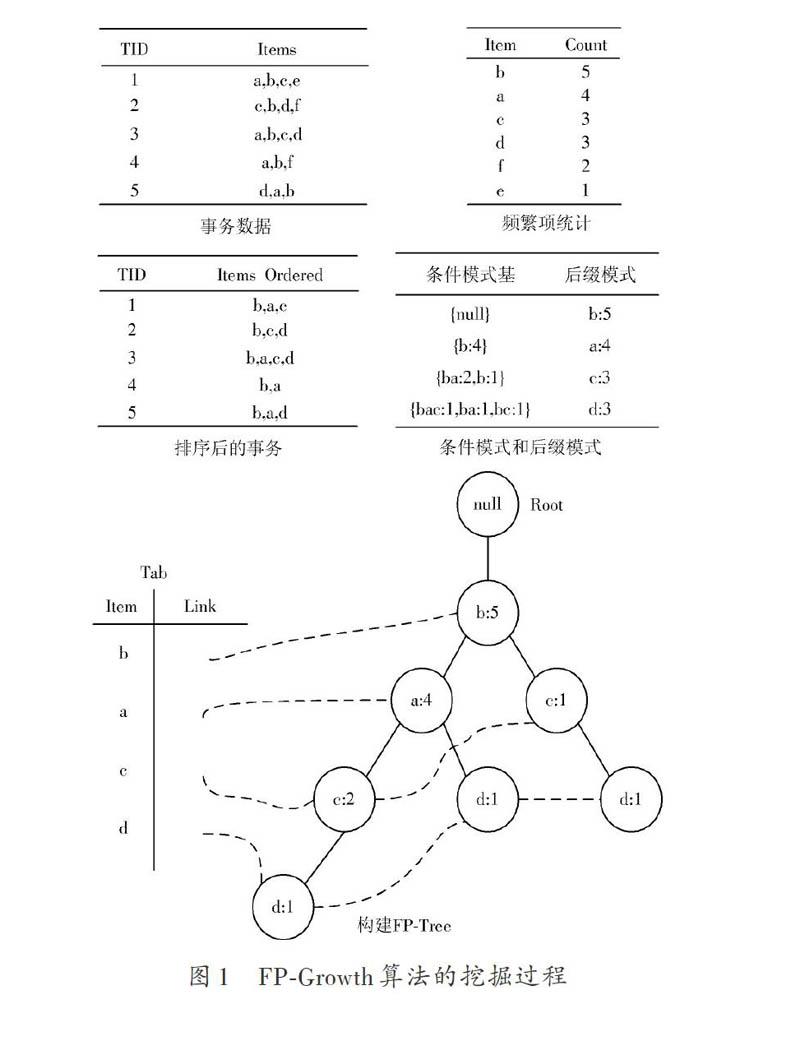
FP?Growth算法将整个数据库的事务进行压缩,该算法不会产生候选项集,采用一种频繁项集增长的方式来进行数据挖掘。该算法从逻辑上可以分为两个部分:第一部分是建树的过程,即把数据库转化为一棵FP?Tree,第二部分就是挖掘的过程,即递归的挖掘这棵FP?Tree,具体的步骤如下所述:
1.2.1 建 树
(1) 第一次扫描整个数据库,计算出所有项所出现的次数,找出满足支持度计数的项,并把这些项按支持度计数降序排列,这就是频繁?1项集,记为L。
(2) 第二次扫描数据库,并在每条事务中的项中先删除不满足支持度计数的项,以L中的顺序为大小规则进行降序排列记为d_list。
(3) 建立一个根节点为null的树。
(4) 建立一个表存储节点的信息记为Tab,包括两个属性(项,一个指向节点的指针)。
(5) 将d_list中的每条处理好的事务依次插入这棵树中,构建出该树的一条路径,在插入的过程中,同时用Tab的指针指向对应项的节点。并将每个节点的计数增加1。
1.2.2 挖 掘
(1) 从Tab表的尾部的项开始向上遍历FP?Tree,每次遍历得到该项的条件模式基,再根据第一部分将其条件模式基转化为一棵新的FP?Tree以及一个存储表,项与项的计数记为后缀模式。
(2) 如果这棵新的FP?Tree为单分支的结构,就对路径上的项进行组合,并与后缀模式相结合;如果不是单分支的结构就跳转到步骤(1)并合并后缀模式,直到挖掘到根节点(null)。
FP?Growth算法具体过程如图1所示。
2 IPFP?Growth算法的并行化实现
2.1 IPFP?Growth算法在Spark上的实现
本文的IPFP?Growth算法建立在PFP?Growth算法的基础之上,采用Scala语言编写,IPFP?Growth算法在Spark上的并行实现整个过程分为4个步骤:
(1) 读取原始数据库将其按频繁?1项集顺序递减排列;
(2) 根据文件大小确定分组个数,按照分组规则将其分为若干组;
(3) 对每个组分别进行频繁项挖掘;
(4) 将每个组的结果进行合并。
算法的整体逻辑图如图2所示。由于原始数据是存储在HDFS中的,超出一个Block大小文件将自动被切分为许多Block,原始分区数s等于文件的总大小/每个Block块的大小+1。
第(1)步中,先从HDFS获取数据库信息转化为初始RDD,利用RDD的faltMap操作将原本的每条事务合并成一个List集合并通过cache操作保存在内存中以便后期的重用,这样只需要对HDFS上的数据进行一次访问,而原PFP?Growth算法需要两次访问HDFS,基于cache是Spark的计算核心之一。接下来将List集合中的每条事务中的每一项(Item)进行map操作,转化为
第(2)步中,首先将每条事务进行最小划分,以图1第一条事务为例,{a,b,c,e}经过第(1)步的处理变为{b,a,c},其中划分给c组的序列为{b,a,c},发送给a组的序列为{b,a},发送给b组的序列为{b},以这种最小划分的方式来对List中的每一条事务进行划分。明显可以看出三个不同组的挖掘所用的开销是不同的,接下来对每一个小组的挖掘开销进行估计,按照均衡分组的规则再进一步合并,确保每一组挖掘的开销基本相同,最后将所有的分组用Hash的方法放在均衡放在每个patition中,保证每个patition中的组数相同。
第(3)步中,采用mapPartitions操作分别对每个分区中的的序列采用2.1节中所描述的FP?Growth算法,但是这里并不是挖掘组中所有的频繁项,而是挖掘以每一组后缀集合中的所有为后缀的频繁项。这里对原FP?Growth算法做了一个优化,不仅仅是判断是否为单分支,在FP?Tree为非单分支结构时也需要判断该FP?Tree是否有共享前缀。当存在一段共享前缀的情况下进行拆分挖掘再合并的思想。具体方法在2.3节中详细介绍。
第(4)步中,将第(3)步中的每一组挖掘的结果进行合并,得到整个数据库的挖掘结果,同时将各个分区计算的结果合并到同一个分区内,最后将结果输出到HDFS上。
2.2 均衡分组及优化算法
本文对PFP?Growth算法的改进主要体现在三个方面上。首先,对数据分组的数目根据频繁?1项集的数目进行了估算,而PFP?Growth算法数据的分组数只是根据手工设定的;其次,根据分组的数目,均衡的将频繁?1项集的最小划分分配到各个组里面,使得每个组的计算量都大致相同,而PFP?Growth算法并没有考虑负载均衡;最后,在采用原FP?Growth算法基础上当出现共享前缀的情况下进行了优化,而PFP?Growth算法采用的只是原FP?Growth算法来进行挖掘。
分组对并行效率起着关键的作用,首先是分组的个数,其次要考虑每个组内的计算量,由于并行计算结束的时间取决于最后一个子任务的完成时间,所以对每个组所用的计算时间都应该大致相等。
均衡分组目的是使每个分组内的计算量保持一致,首先需要确保分组后挖掘的局部频繁项集为全局频繁项集,因此原数据最小划分的依据是以该频繁项为后缀的所有List的集合,由于FP?Growth是一个递归算法,根据项在频繁?1项集中的位置,对该项集的计算量大小可作如下估计:T=log L,其中:T为计算量的大小;L为该项在频繁?1项集中的位置。
在分组数目的确定上,原始数据中频繁?1项集的数目记为t,假设分组数目为g,当m>t时,各个组的计算量必然不一致,此时并行计算的时间取决于最长后缀的分组(频繁?1项集这种支持度计数最小的项)。为了确保均衡分组的有效性,分组数目g应满足公式:
[n×p≥g, n≥1t=m×g, m>1] (1)
式中:p代表分区数目。一个分区可以包含多个分组,在Spark的上分区数目决定了并行计算的粒度,因为在Spark执行过程中每个阶段的任务数和分区数始终保持一致,任务调度器会根据不同的阶段调度任务在worker节点中的Executor上执行,所以也需要保证每个分区内的组数相同,同时也要让各个分组之间的计算量保持平衡,这就是分组数目的依据。均衡分组示意图如图3所示。图3中假设一共有18个满足支持度的项(即最小划分),分组数目为6,其中x轴代表着频繁?1项集的支持度计数从小到大的顺序,同时也代表着最小划分的组号,y轴代表对该最小分组的的计算量估计,图3中虚线与x坐标轴的交点为参考交点。当支持度计数最大时,该项处于List的第一位,以该项为后缀的频繁模式只有该项本身,所以计算量为0。图3(b)中直线l与经过对称变换后的曲线的交点所对应原曲线的x坐标轴,即为每个分组中的内容,如图3所示。采用这样的划分可以保证在某一时刻总是将最大计算量的那个后缀模式项放在存在计算量最小的那个分组,剩下这样可以保证让大部分的组内的计算量保持一致。
在对FP?Tree进行挖掘时,对于具有前缀共享路径的情况下做了优化,在这种情况下,对FP?Tree的挖掘分为了两个部分,单分支部分和非单分支的结构。先将单一前缀路径视为一个节点,通过排列组合的方式得出挖掘结果,然后将剩下的非单分支的结构进行递归挖掘。因为对非单分支结构的FP?Tree的挖掘是需要递归来完成的,单分支只要通过简单的排列组合来实现频繁项的挖掘,如果在挖掘的过程中出现了一个有很长前缀的非单分支结构,通过拆分能够减少计算所需的时间。该算法伪代码如图4所示。
为了清晰地表达出该优化策略,文中用了一个简单的事务数据作为例子,假设事务数据库为{(T1:a,b,c,e),(T2:a,b,c,d,e),(T3:a,b,c,d,f)},首先构建FP?Tree如图5所示。
图5 具有共享前缀的拆分
设频繁集阈值为2,则单分支的挖掘结果为A={a:3,b:3,c:3,ac:3,bc:3,ab:3,abc:3},非单分支的挖掘结构结果为B={e:2,d:2},最后将两个结果做笛卡尔乘积操作,即 A×B={ae:2,be:2,ce:2,ace:2,bce:2,abe:2,abce:2,ad:2,bd:2,cd:2,acd:2,bcd:2,abd:2,abcd:2}(后缀为e,d的频繁项集),在笛卡尔积结果中的支持度计数为B中的支持度计数。
3 实验结果及分析
3.1 实验环境
Hadoop集群由4台物理主机构成,其中,1台为主节点(master),3台为从节点(slave)。每台物理机的主要配置如下:8个内核,内存为22.5 GB,磁盘容量为80 GB。Java版本为Java?7?oracle,Scala版本为2.11.2,Linux系统为Ubuntu12.04,Hadoop版本为2.4.0。Spark同样部署在该4台物理主机之上,1台主节点3台从节点,运行模式为Spark alone模式,Spark版本为1.3.0,采用运行内存的50%来缓存RDD。
3.2 实验数据及结果
实验设置:本实验采用Intellij作为开发环境,一共实现了PFP?Growth算法和IPFP?Growth算法两个算法。在实验中采用了两个数据集,都是由IBM数据生成器生成,第一份数据集的大小为576 MB,事务平均长度为36 MB,项集数目为100,包括500 000条事务数据记录,第二份数据集的大小为1.11 GB,事务平均长度为72 MB,项集数目为200,包含500 000条事务数据记录,对两份生成数据集先用Scala程序预处理,去除原始生成数据中的多余的空格,得到两份数据的大小分别是51.55 MB和119.69 MB。接下来对两份事务数据进行随机采样,在支持度0.75下统计运行时间。首先将PFP?Growth算法在两个数据集上进行测试,然后再运行本文中对该算法进行优化后的IPFP?Growth算法,最后将两个算法的运行时间进行比较。实验结果如图6、图7所示。
实验分析:从图6,图7两个数据集的实验结果可以看出,当事务数据不大时,两种算法的时间差距不大,随着事务数据量的增加,IPFP?Growth算法的优势越来越明显,都体现出了均衡分组的思想对算法的提高。在数据集1中由于平均事务长度较短,共享前缀优化对算法的提升不是很明显。在数据集2中,事务长度、项集数均为数据集1的2倍,FP?Tree的深度加深,长路径递归需要更长的时间,共享前缀的优化对算法的提高效果更加明显,因此在数据集2中,效率的提升比在数据集1上的测试结果更加高。说明本文从均衡分组以及挖掘过程中的优化,对FP?Growth算法上的改进,有利于提高算法在海量数据下挖掘的效率,同时随着节点数目和内存大小的增加,算法执行的时间在理论上能够大幅度减少。通过上述的分析,证明了本文提出的优化对算法的性能有一定提高,从而也说明了Spark平台适合需要迭代算法并行化。
4 结 语
针对目前的海量数据,本文基于Spark平台,将PFP?Growth算法从分组均衡、共享前缀拆分两个方面对原算法进行改进,提高了关联挖掘算法效率,在事务平均长度比较高的情况下提升效果更加明显,适用于生产环境中对实时性较高的应用。由于没有改变数据的存储结构,在实验过程中发现仍然有数据集本身数十倍甚至上百倍大小的中间结果需要保存在内存中。在大规模数据的情况下,FP?Growth算法递归调用自身,造成的后果可能是导致许多个条件FP?Tree同时被存储在内存中,内存依旧可能被占满,这是一种内存换取I/O开销的做法。接下来要做的可能就要从数据压缩结构上面考虑,使对原数据库数据的挖掘更加高效。
参考文献
[1] HAN J, PEI J, YIN Y. Mining frequent patterns without candidate generation [J]. ACM SIGMOD record, 2000, 29(2): 1?12.
[2] LI H, WANG Y, ZHANG D, et al. PFP: parallel FP?Growth for query recommendation [C]// Proceedings of the 2008 ACM Conference on Recommender Systems. [S.l.]: ACM, 2008: 107?114.
[3] 王智钢,王池社,马青霞.分布式并行关联规则挖掘算法研究[J].计算机应用与软件,2013(10):113?115.
[4] 曾志勇,杨呈智,陶冶.负载均衡的 FP?Growth 并行算法研究[J].计算机工程与应用,2010,46(4):125?126.
[5] 周诗慧.基于Hadoop的改进的并行Fp?Growth算法[D].济南:山东大学,2013.
[6] 吕雪骥,李龙澍.FP?Growth 算法 MapReduce 化研究[J].计算机技术与发展,2012,22(11):123?126.
[7] 杨雅双.关联规则的并行挖掘算法研究[D].西安:西安科技大学,2010.
[8] ZHOU L, ZHONG Z, CHANG J, et al. Balanced parallel FP?Growth with MapReduce [C]// Proceedings of 2011 IEEE Youth Conference on Information Computing and Telecommunications. [S.l.]: IEEE, 2010: 243?248.
[9] 高彦杰.Spark大数据处理:技术、应用与性能优化[M].北京:机械工业出版社,2014:1?2.
[10] QIU H, GU R, YUAN C, et al. YAFIM: A parallel frequent itemset mining algorithm with Spark [C]// 2014 IEEE International Parallel & Distributed Processing Symposium Workshops. [S.l.]: IEEE, 2014: 1664?1671.
