
云计算环境下大数据分布规律的结构优化设计
2016-05-14 09:17邹华
现代电子技术 2016年8期
邹华
摘 要: 针对云计算环境下大数据分布不合理,导致运行效率差的问题,提出基于模糊聚类分析的云计算环境下大数据分布规律的结构优化方法,首先对特征的观测值进行规格化处理,保证每个特征值的取值均处于[0,1]范围内。其次获得在[0,1]范围内的相似系数描述数据间的相似度,通过相似矩阵获得云计算环境下大数据集上的模糊五阶相似矩阵。引入最短距离法,将其和相似矩阵融合,共同实现数据聚类,完成大数据分布规律结构的优化设计。仿真实验结果表明,所提方法使得数据分布更合理,而且运行效率和稳定性均较高。
关键词: 云计算; 大数据; 分布规律; 相似矩阵
中图分类号: TN911?34; TP393 文献标识码: A 文章编号: 1004?373X(2016)08?0018?03
Optimization design for structure of big data distribution regularity
in cloud computing environment
ZOU Hua
(Information Engineering College, TongRen University, Tongren 554300, China)
Abstract: Aiming at the poor operating efficiency caused by the unreasonable distribution of big data in cloud computing environment, a structure optimization method of big data distribution regularities in cloud computing environment, which based on the fuzzy cluster analysis, is proposed. Firstly, a normalization treatment for the observed values of the features is performed to ensure that the values are all controlled in the range of [0,1]. And then the similarity factor in the range of [0,1] is acquired to describe the similarity between the data, and the fuzzy five?order similar matrix on big data set in cloud computing environment is obtained according to the similar matrix. The single linkage method is used to integrate with the similarity matrix to achieve data clustering, and realize the optimization design of large data distribution structure. The simulation results show that this method not only can make the data distribution reasonable, but also has advantages of high operating efficiency and high stability.
Keywords: cloud computing; big data; distribution law; similar matrix
随着计算机科技技术的逐渐发展,所涉及的数据量越来越大,人们对云计算环境安全性的要求也越来越高[1?2]。如何在不增加成本的情况下,提高整个系统的安全性和数据分布的合理性已成为相关学者研究的重点课题,受到了越来越广泛的关注[3?5]。目前,研究云计算环境下大数据分布规律的结构优化设计方法有很多,主要包括模糊聚类方法、详细度量方法和最小二乘法等,相关研究也取得了一定的成果。其中,文献[6]提出基于误差和曲线分析的云计算环境下大数据分布规律结构优化设计方法,通过误差分析法和实测数据直方图进行比较实现结构优化,但该方法存在实践过程复杂的弊端。文献[7]提出基于非线性最小二乘法的云计算环境下大数据分布规律结构优化设计方法,通过非线性最小二乘拟合法,获取数据的统计分布规律,但该方法的计算结果精度低,同时受外界环境的干扰较大。文献[8]提出基于线性整数规划的云计算环境下大数据分布规律的结构优化设计方法,通过线性整数规划对大数据的分布规律进行优化,但该方法仅限于数据无冗余的情况。
1 基于模糊聚类分析的云数据分布规律结构
优化设计方法
1.1 构建[X]上的模糊关系
在抽取数据特征的基础上,建立其在[X]上的模糊关系,为大数据分布规律结构优化设计提供基础依据。将相似系数构成的[n]阶矩阵称作相似系数矩阵,通过该矩阵即可描述[X]上的模糊相似关系。对该矩阵的等价闭包或等价类进行计算,即可建立待处理数据[X]的模糊关系。依据本文研究问题的特征环境,为了获取相似系数,需使相似系数满足自反、对称的条件,选择贴近度法对相似系数进行计算。两个模糊向量之间接近程度的体现即为贴近度,其满足自反、对称的条件,因此,可通过贴近度对相似系数进行描述。将[X]中的元素[Xi]和[Xj]看作是各自特征的模糊向量,用贴近度对相似系数[rij]进行描述,再采用绝对值减数法,取当[σ]接近海明距离时的贴近度,[rij]的表达式为:
[rij=1-cdpXi,Xjα] (1)
式中:[c],[α]用于描述常数;[p]用于描述不同距离的代码系数。取论域[X=x1,x2,…,x5],对其进行规格化处理,取[c=0.1],然后通过式(2)对相似系数进行计算,获取模糊五阶相似矩阵:
[R=rij= 1 0.1 0.8 0.5 0.30.1 1 0.1 0.2 0.40.8 0.1 1 0.3 0.10.5 0.2 0.3 1 0.60.3 0.4 0.1 0.6 1] (2)
获得数据特征在[X]上的模糊关系表达式后,需要对模糊五阶相似矩阵进行划分,为大数据分布规律结构优化设计提供依据。
1.2 大数据分布规律结构优化设计
在对其进行优化设计之前,需要用最短距离法对类和类之间的距离进行计算,也就是用[dij]([i,j=1,2,…,n])描述样本[i]与[j]之间的距离,则有:
[dij=k=1pxik-xjk] (3)
如果用[G1,G2,…]描述类,则第[k]类[Gk]和第[r]类[Gr]之间的距离为:
[Dkr=mindij:i∈Gk,j∈Gr] (4)
在获得最短距离的情况下,采用最短距离对云计算环境下大数据分布规律结构进行优化设计,其详细过程如下:
(1) 假设样本之间的距离为[dij]([i,j=1,2,…,n]),依据[dij]获取距离矩阵[D0]。由于开始时所有样本均自成一类,所以[Dkr=dkr];
(2) 找出[D0]中的最小元素[Gk]与[Gr],将[Gk]与[Gr]合并成一个新类[Gp=Gk,Gr];
(3) 对新类与其他类的距离进行计算,假设类[Gp]和[Gq]之间的距离为:
[Dpq=mindij:i∈Gp,j∈Gq =minmindij:i∈Gk,j∈Gq,mindij:i∈Gr,j∈Gq =minDkq,Drq]
将[D0]中的第[k]行和第[r]行、第[k]列和第[r]列,通过式(5)合并为一个新行新列,获取的新矩阵用[D1]进行描述;
(4) 对[D1]重复上述对[D0]的两个步骤以获取[D2],以此类推,直至剩下[k]类为止。
若某一步中最小元素多于一个,则和上述最小元素相应的类可以同时合并。
通过上述分析对云计算环境下大数据分布规律结构进行优化设计,决定哪些数据需进行调整,哪些数据需进行转移,使云计算环境下大数据的分布通过不断地动态调整,能始终处于最佳位置。
2 仿真实验分析
为了验证本文提出的基于模糊聚类的云计算环境下大数据分布规律结构优化设计方法的有效性,需要进行相关的实验分析。两种方法分别进行10次实验,取其平均访问代价作为结果。在对两种方法进行评价的过程中,本文将相对访问成本作为衡量的标准,相对访问成本可描述成实际访问成本与基本访问成本的商,其和云计算环境下的拓扑结构无关。
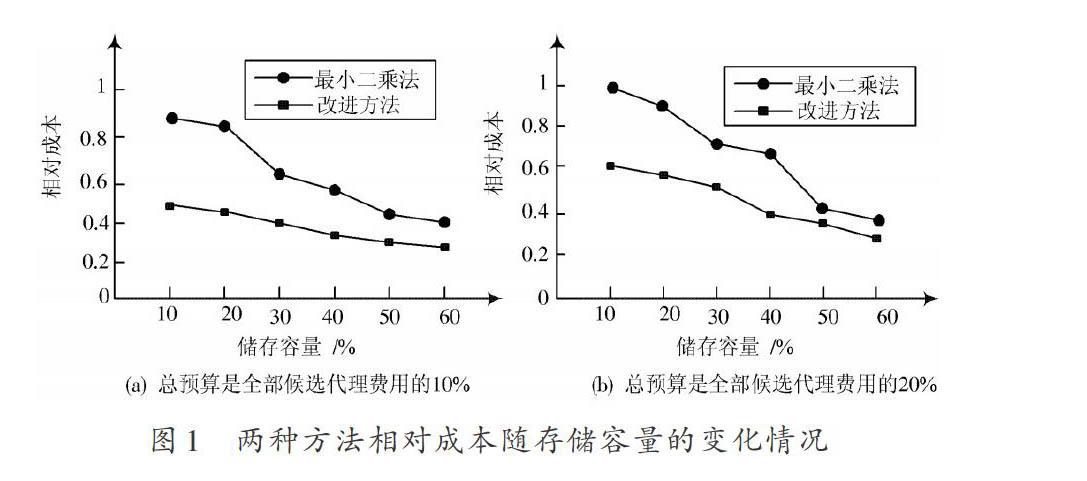
随着代理存储容量的增加,采用本文方法和最小二乘法进行大数据分布规律结构优化设计后的相对访问成本比较结果,如图1所示。图1(a)和图l(b)分别描述的是总预算,是全部候选代理费用的10%和20%的情况。
分析图1可以看出,随着存储容量的逐渐升高,本文方法的相对成本一直低于最小二乘法,当总预算从全部候选代理费用的10%增长至20%时,本文方法和最小二乘法的相对成本均在一定程度上有所增加,但本文方法的增加幅度明显低于最小二乘法,说明本文方法的性能优于最小二乘法,验证了本文方法的有效性。
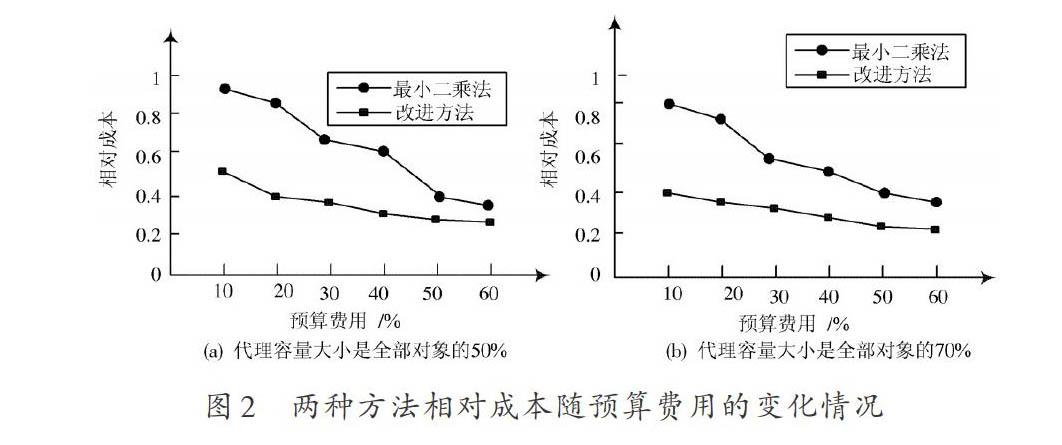
在各代理容量一定的情况下,云计算环境下预算费用逐渐增加时,本文方法和最小二乘方法相对成本的变化趋势,如图2所示。图2(a)描述的是代理容量大小是全部对象的50%的情况,图2(b)描述的是代理容量大小是全部对象的70%的情况。
分析图2可以看出,本文方法的性能明显优于最小二乘方法,在各代理容量或总预算较低时,本文方法的相对成本均低于最小二乘方法,当代理容量大小从50%到70%时,本文方法的相对成本基本没有发生改变,说明本文方法基本不受代理容量的影响,验证了本文方法的有效性。
3 结 论
本文提出基于模糊聚类分析的云计算环境下大数据分布规律的结构优化方法,对特征的观测值进行规格化处理,保证每个特征值的取值均处于[0,1]范围内,使数据特征只含有相对意。用[0,1]范围内的相似系数描述数据间的相似度,通过相似矩阵描述云计算环境下大数据集上的模糊相似关系。采用贴进度法运算相似矩阵的等价闭包或等价类。引入最短距离法,将其和相似矩阵融合,共同实现数据聚类,完成大数据分布规律结构的优化设计,使云计算环境下大数据的分布,通过不断地动态调整,可始终处于最佳位置。仿真实验结果表明,所提方法不仅相对成本较低,而且运行效率和稳定性均较高。
参考文献
[1] 周本海.浅谈云计算环境下大数据对电子商务的影响[J].经济研究导刊,2015(7):201?202.
[2] 王嘉,陈超.云计算环境下大规模数据处理的研究[J].中国电子商务,2013(9):42.
[3] 徐敏,徐勇.基于单一属性分布的数据质量评估模型[J].统计与决策,2013(11):4?8.
[4] 申倩,许美玉,姜春茂.云计算环境下任务调度研究综述[J].智能计算机与应用,2014,4(6):75?77.
[5] 张千,梁鸿,郉永山.云计算环境下基于模糊聚类的并行调度策略研究[J].计算机科学,2014,41(8):75?80.
[6] 陈鹏,刘爽,左莉,等.基于数据分布规律的分段组合支持向量机研究[J].微电子学与计算机,2015,32(3):94?99.
[7] 李鹏飞,赵勇,张顶立,等.基于现场实测数据统计的隧道围岩压力分布规律研究[J].岩石力学与工程学报,2013(7):1392?1399.
[8] 温创新,邱一凡,孙军.基于大数据和泊松分布的配件预测模型分析与建模[J].计算机与数字工程,2014,42(8):1412?1414.
猜你喜欢
电脑知识与技术(2016年21期)2016-10-18
大学教育(2016年9期)2016-10-09
科技视界(2016年20期)2016-09-29
科技视界(2016年20期)2016-09-29
