
基于Hadoop的协同过滤推荐并行化研究
2016-05-21 15:57曹萍
计算机时代 2016年5期
摘 要: 针对协同过滤(CF)推荐技术处理大数据时的计算效率问题,分析了CF算法的并行化。并行化CF算法采用Hadoop平台的MapReduce并行编程模型,改善大数据环境下CF算法在单机运行时的计算性能。在实验部分,设计不同集群环境下的加速比实验,验证该算法在大数据环境中具有的计算性能。
关键词: 协同过滤; 计算效率; 加速比; Hadoop; 大数据
中图分类号:TP391 文献标志码:A 文章编号:1006-8228(2016)05-30-04
Abstract: For the computational efficiency problem existing in big data processing with collaborative filtering (CF) recommendation, parallel computing of CF is analyzed. Parallelized CF algorithm uses MapReduce parallel programming model on Hadoop platform, which improves the computational efficiency of single PC to process big data. In the experiment section, the speedup experiments in different cluster environments are designed to verify the better computing performance of the algorithm in big data processing.
Key words: collaborative filtering; computational efficiency; speedup; Hadoop; Big data
0 引言
互联网时代,网络资源纷杂,信息过载,个性化推荐成为缓解用户在网络中的信息迷茫问题的重要途径[1]。在多项目、多领域的推荐中,因不依赖用户或项目内容,具有较好通用性的协同过滤算法[2]成为较成功的推荐技术,因而其改进也受到广泛关注。然而改进的算法通常是以牺牲计算效率换取计算准确度的提升。随着大数据时代的来临[3-7],解决计算效率的问题也迫在眉睫。由于单机模式的计算能力有限,而分布式计算具有多资源、可扩展、高效计算等优势,用分布式计算实现高效的CF算法,既能提高推荐准确度,又能保证计算效率。目前主要使用云计算平台Hadoop实现算法的并行化,如文献[8-13]等是通过将算法移植至Hadoop得到高计算性能的算法。
本文将协同过滤推荐算法与开源分布式平台Hadoop结合,研究协同过滤推荐算法的并行化,探索其MapReduce过程设计,比较单节点计算与多节点计算在计算效率上的差别,证明并行化后的算法在计算效率上的优势,其更能适应大数据环境。我们将并行化的CF算法简称为PCF(CF in Parallel)。
1 CF算法及Hadoop平台概述
1.1 CF算法概述
协同过滤技术的思想简单易懂,利用群体的观点为个人进行推荐,比如,日常生活中我们经常会参照身边朋友的意见或行为,购买一些商品或作出某种选择。在协同过滤技术中,用户之间是有联系的,他们可以是朋友、邻居,根据趣味相投原则,邻居用户的喜好是一致或相近的,所以,对于当前用户为其推荐邻居的偏好项目。CF技术通过所有用户的偏好、评分信息,经过用户相似度的度量,找到特定用户的邻居集合,根据最近邻的兴趣信息,为其作出项目推荐。
协同过滤推荐算法一般步骤为:构建用户-项目评分矩阵,据此计算用户或项目相似度,进而计算预测评分、取前N个预测评分高的项目产生推荐集。以user-based算法为例,具体如下[14]。
⑴ 构建评分矩阵。如表1所示。
⑵ 以用户的相似度为计算目标,寻找邻居用户。余弦相似性、修正的余弦相似性、Pearson系数相关为三种常见的相似度计算方法。
其中Pearson系数相关计算两用户的相似度sim(i,j),用户i与用户j共同评分的项目集合为Iij,用户i已作出评分的均值为。
⑴
⑶ 生成推荐。
① 计算预测值。
平均加权策略:用户i对项目c的预测评分值:
⑵
② Top-N形式的推荐集。
计算邻居集中的用户i对各项目的加权评分平均值,Top-N推荐集取前N个且不属于Ii(用户i评分的项目集合)的项。
1.2 存在问题
1.2.1 矩阵稀疏问题
协同过滤是目前个性化推荐应用中的主流技术,然而随着大数据时代的到来,系统内的项目不断增多,用户规模日渐壮大,用户不可能对每个或大多数项目都做出评价。当用户或项目数量增大速度远远大于用户对项目的评分速度时,就导致数据量虽然增大,CF技术所依赖的评分矩阵却越来越稀疏,激化了该技术中一直存在的数据稀疏性问题,导致邻居用户或项目的计算准确性降低,对评分的预测出现偏差,影响推荐效果。针对稀疏性问题,目前主要的改进方向是矩阵填充或降维技术。
1.2.2 冷启动问题
处于信息化时代,人们与互联网的接触越来越频繁,越来越多的新用户或新项目加入进来:新用户无历史行为信息,无法寻找到邻居以获得个性化服务;新项目评分信息较少甚至没有,故无法寻找到邻居以得到推荐。这是CF技术中的冷启动问题,前者是用户冷启动,后者是项目冷启动。冷启动问题也可以理解成数据稀疏性的极端情况。针对该问题,目前主要是借鉴CBF的思想,结合用户或项目本身的属性信息完成推荐,缓解冷启动[1]。
1.2.3 可扩展问题
一个好的推荐系统不仅仅预测的准确度要高,同样重要的还有实时性。系统运算速度与评分矩阵的大小紧密关联,而用户规模和项目规模决定了矩阵的规模。面对急速增长的用户量和项目量,协同过滤技术中可扩展问题的重要性日渐突出。针对该问题,目前的研究一方面是利用聚类技术,通过概率计算或设定阈值,在确保能够尽量多地找到目标用户或项目的邻居前提下,将搜索空间缩至最小,以提高计算速度,缓解CF中的可扩展问题[15];另一方面,跳出单机的局限,采用多核计算或云计算并行化方法,相对多核方式的核数有限、高实现成本,云计算的优势凸显,越来越多的研究与应用采用该方法解决推荐领域的高准确度和低计算效率的矛盾。
1.3 Hadoop简介
Hadoop起源于Apache公司的Lucene和Nutch项目[16],是谷歌云计算理论的Java语言实现。其中并行计算模型MapReduce是Hadoop中最核心的部分,它是一种可靠、高效的并行编程模型和计算框架,借助于HDFS等分布式技术,能够处理各类PB数量级的大数据[17],其构成部分主要有一个主控服务JobTracker,若干个从服务TaskTracker,分布式文件系统HDFS,以及客户端Client[18]。MapReduce通过分解任务、合并结果的分而治之思想,实现可分解、可并行处理大数据集上的并行计算。MapReduce的任务执行过程由Map和Reduce两阶段构成,每次Map和Reduce的输入和输出均是键值对
2 基于MapReduce的CF算法分析
利用MapReduce并行计算模型实现CF算法的并行化,从原始的用户-评分矩阵计算出推荐结果,需要多个MapReduce过程,本章节具体分析。
2.1 用户相似度的计算
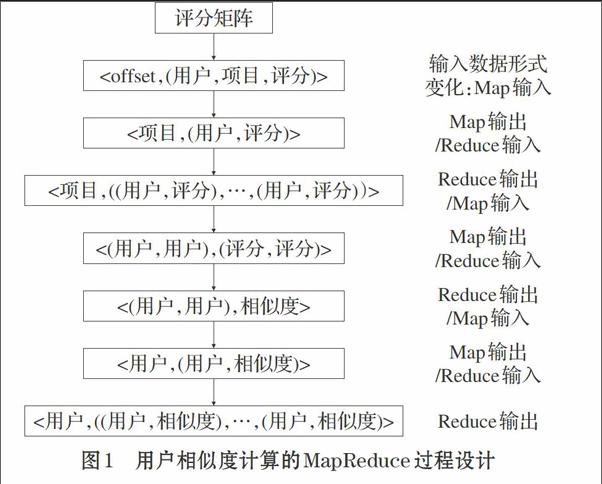
根据公式⑴,分析得用户相似度计算的MapReduce过程如图1,共包含三个MapReduce过程,每个过程都可并行运行。
输入:评分矩阵,当前用户id。
输出:当前用户与其他用户的相似度值。
最后,当目标用户需要推荐时,根据预测分值排序,返回TOP-N推荐集。至此,推荐完成。
在所有阶段的MapReduce过程设计没有改变算法的数学计算关系,所以对算法的计算结果没有影响,在Hadoop平台上运行与非并行模式下运行的推荐结果是一样的,但是,并行模式Hadoop下的算法,有高效的大数据集计算能力,可扩展性较高。
3 PCF算法的实现及实验分析
3.1 实验设计
实验的Hadoop平台使用6台PC机,搭建完全分布式环境。其中1台部署namenode和jobtracker,另5台部署datanode和tasktracker。集群配置如表4所示。
3.2 实验结果与分析
根据实验结果,绘制加速比曲线图,如图3所示。
随着节点数量的增加,加速比呈总体增长趋势,体现了良好的可扩展性。但当节点数增加到一定数量时,加速比趋于稳定。
4 结束语
本文介绍了CF算法,Hadoop云平台概况,为了实现高效的推荐算法,以user-based CF为例,分析了其在MapReduce并行编程上的过程设计,即PCF算法,并在开源云计算平台Hadoop上实现。通过变化集群节点数目和数据集规模大小,对加速比进行评估,实现较高计算效率的推荐。然而,一方面由于实验条件的限制,搭建的集群规模有限;另一方面,是对Hadoop平台的直接应用。下一步可以结合Hadoop中任务调度等方面的性能优化,进一步提高计算能力,以适应不断壮大的大数据。
参考文献(References):
[1] 李树青.个性化信息检索技术综述[J].情报理论与实践,2009.32(5):107-113
[2] Liu Z B,Qu W Y,Li H T,et al. A Hybrid CollaborativeFiltering Recommendation Mechanism for P2P Networks[J]. Future Genera-tion Computer Systems,2010,26(8):1409-1417
[3] Nature.Big Data[EB/OL].[2012-10-02].http://www.nature.com/news/specials/bigdata/index.html
[4] Bryant R E,Katz R H,Lazowska E D.Big-Data computing:Creating revolutionary breakthroughs in commerce,science, and society[R]. [2012-10-02].http://www.cra.org/ccc/docs/init/Big_Data.pdf
[5] Science.Special online collection:Dealing with data[EB/
OL]. [2012-10-02]. http://www.Sciencemag.org/sites/special/data/,2011.
[6] Manyika J,Chui M,Brown B,et al.Big data:The next frontier for innovation,competition,and productivity[R/OL].[2012-10-22].http://www.mckinsey.com/Insights/MGI/Research/Technology_and_Innovation/Big_data_
The_next_frontier_for_innovation
[7] Big Data Across the Federal Government[EB/OL].[2012-102].http://www.whitehouse.gov/sites/default/files/microsites/ostp/big_data_fact_sheet_final_1.pdf.
[8] 肖强,朱庆华,郑华,吴克文.Hadoop环境下的分布式协同过滤算法设计与实现[J].现代图书情报技术,2013.1:83-89
[9] 程苗,陈华平.基于Hadoop的Web日志挖掘[J]计算机工程,2011.37(11):37-39
[10] 张明辉.基于Hadoop的数据挖掘算法的分析与研究[D].昆明理工大学,2012.
[11] 李改,潘嵘,李章凤,李磊.基于大数据集的协同过滤算法的并行化研究[J].计算机工程与设计,2012.33(6):2437-2441
[12] 周源.基于云计算的推荐算法研究[D].电子科技大学,2012.
[13] 金龑.协同过滤算法及其并行化研究[D].南京大学,2012.
[14] 叶锡君,曹萍.ASUCF:基于平均相似度的协同过滤推荐算法[J].计算机工程与设计,2014.35(12):4217-4222
[15] 黄正.面向数据稀疏的协同过滤推荐算法研究与优化[D].华南理工大学,2012:25-29
[16] 陆嘉恒.Hadoop实战[M].机械工业出版社,2011.
[17] 陈全,邓倩妮.云计算及其关键技术[J].计算机应用,2009.29(9):2562-2567
[18] Tom.White著.周敏奇,王晓玲,金澈清,钱卫宁译.Hadoop:权威指南[M].清华大学出版社,2011.
猜你喜欢
软件导刊(2016年11期)2016-12-22
现代情报(2016年11期)2016-12-21
电脑知识与技术(2016年27期)2016-12-15
电脑知识与技术(2016年26期)2016-11-24
科技视界(2016年20期)2016-09-29
