
海量不完整数据上基于维度组合的Skyline查询*
2016-05-25 07:58刘赓浩宋宝燕王俊陆
计算机与生活 2016年4期
王 妍,银 彪,刘赓浩,宋宝燕+,王俊陆
1.辽宁大学信息学院,沈阳1100362.东北大学信息与工程学院,沈阳110819
ISSN 1673-9418 CODEN JKYTA8
Journal of Frontiers of Computer Science and Technology
1673-9418/2016/10(04)-0495-09
海量不完整数据上基于维度组合的Skyline查询*
王妍1,2,银彪1,刘赓浩1,宋宝燕1+,王俊陆1
1.辽宁大学信息学院,沈阳110036
2.东北大学信息与工程学院,沈阳110819
ISSN 1673-9418 CODEN JKYTA8
Journal of Frontiers of Computer Science and Technology
1673-9418/2016/10(04)-0495-09
E-mail: fcst@vip.163.com
http://www.ceaj.org
Tel: +86-10-89056056
* The National Natural Science Foundation of China under Grant Nos. 61472072, 61472169, 61300233 (国家自然科学基金); the National Basic Research Program of China under Grant No. 2014CB360509 (国家重点基础研究发展计划(973计划)); the National Science and Technology Support Program of China under Grant No. 2012BAF13B08 (国家科技支撑计划); the Foundation of Science Public Welfare of Liaoning Province under Grant No. 2015003003 (辽宁省科学事业公益研究基金项目); the Youth Foundation of Liaoning University under Grant No. LDQN201508 (辽宁大学青年科研基金).
Received 2015-06,Accepted 2015-09.
CNKI网络优先出版: 2015-09-16, http://www.cnki.net/kcms/detail/11.5602.TP.20150916.1659.010.html
摘要:随着互联网、物联网等信息技术的快速发展,多维数据日益增多,这些海量数据中往往伴随着大量的不完整数据,如何从海量不完整数据中高效地获取用户所需的近似的结果集是一个亟需解决的问题。针对海量高维的不完整数据集,提出了一种基于维度组合的Skyline查询算法,通过构建RankList数据结构提高查询效率,并减少不完整数据对查询结果的影响;利用维度的不同组合,划分出查询子空间,并渐进地查询出每个子空间的最优先点,从而获得海量不完整数据集上均匀分布的Skyline点。实验结果表明,该算法与Iskyline算法相比,平均查询效率提高了85%,并且在数据量大、维度高时,较普通方法查询效率更高。
关键词:海量不完整数据;维度组合;Skyline
1 引言
随着社会的飞速进步和科学技术水平的不断提高,数据规模不断扩大。数据通常具有多维的属性值,且数据获取的方式呈现多样化,由于设备或其他原因导致元组数据缺失或其属性值缺失的问题越来越普遍[1]。从海量不完整数据中,高效地获取用户所需的结果是一个亟需解决的问题。
目前,对多维不完整数据的处理方法通常是对数据集进行清洗、修复等预处理[2-4],然后再通过Skyline[5-6]等方法进行查询处理。而在海量数据的背景下,预处理阶段需要花费大量的时间代价。为节省预处理的时间,一些学者提出,根据不完整数据缺失属性将它们分到不同的属性缺失列中,并动态查找Skyline点。但是Skyline查询随着数量的增大和维度的增加,查询代价呈指数增长,此方法不适用于海量不完整数据集。有些学者为了提高Skyline算法的查询效率,提出了低维抽样组合的算法。该算法查询效率得到提升,但只能查询出数据集中的局部轮廓点,会缺失较多全局Skyline点。
对于海量的维数较高的不完整数据,本文摒弃了传统方法中的预处理阶段,给出一种对这类数据直接查询处理的方法:海量不完整数据上基于维度组合的Skyline查询(combination of dimension Skyline query, CDskyline)。该方法首先构建RankList数据结构,然后基于维度组合进行子空间的划分,并对子空间进行编码。这种策略充分考虑了各个维度组合的查询结果,并减少了不完整数据对查询结果的影响。通过扫描RankList结构,查询出各个子空间的最优先点,从而得到最终的查询结果。所得结果均匀分布并接近真实轮廓。最后进行了实验,结果表明CDskyline算法高效适用于海量不完整数据,并显著提高了查询效率,快速获取了用户所需的近似结果。
2 相关工作
文献[7]提出了RBSSQ(replacement based Skyline sets queries)算法,通过替换策略解决了Skyline查询中数据元组属性丢失的问题。文献[8-10]提出了使用值填充的方法解决数据不完整问题的Skyline查询方法。文献[7-10]对数据集进行预处理,然后执行Skyline算法。但预处理阶段消耗系统资源过多,修复后的数据存在一定的误差,导致查询结果不准确。针对海量不完整数据集,目前的查询预处理代价较大,会显著增加系统的响应时间。
文献[11]提出了在分布式环境下通过对Skyline点进行抽样,模拟高维Skyline数据集的算法SSRD (sampling Skylines by reduced dimensions)。首先随机选择出一个部分维度组合的数据集,然后在这个数据集上计算出Skyline点,作为近似的全局轮廓数据。这种方法只能查询出数据集中的局部Skyline点,缺失大量的全局轮廓数据,因此不能反映全局的轮廓。基于各维数据综合考虑的Skyline算法研究较少。
文献[12]提出了一种基于不完整数据的Iskyline (incomplete data Skyline query)算法。该算法根据不完整数据缺失属性将它们分到不同的缺失属性列中,并动态查找局部和全局的Skyline点。该算法只适合少量不完整数据集,当数据规模过大时查询代价呈指数增长。该算法将不完整数据与完整数据分开查询,没有考虑两者之间的支配关系,得到的结果存在较大误差。
3 基于维度组合的数据集划分
3.1构建RankList数据结构
当数据量大且含有较多不完整数据,特别是维度也较高时,直接进行Skyline查询效率较低。为了提高查询效率,并减少不完整数据对查询结果的影响,本文引入了RankList数据结构,将元组id有序存入结构列表,在RankList结构之上进行查询。
RankList数据结构由多个列表组成,每个列表对应不完整数据集的一维数据。每个列表di由数个桶Pmn组成,di维属性值相同的元组放置同一个桶中,因此每一列中所含桶的数目与di维含有相异属性值的多少有关。桶中元素值与元组在该维属性值是否缺失有关,若某元组在该维属性值缺失,则把“—”存入桶中,多个“—”出现时,只存储一次,且放置于列表的末端。若某元组该维的属性值不缺失,则存入该元组的id,把在该维属性值相同的元组id号存放于一个桶中。某一列表的多个桶按照桶中元组在该维的属性值升序排列,排序号用Ranki表示。
为了表明用户对各个维度的偏好程度,本文对各个维度引入非负权值。为方便计算,设定权值越小的维度在查询时越重要。RankList结构中的列表按照各维度权值升序排列,重要的维度排在前面,便于提高Skyline点查询效率。
用一个简单的例子来说明RankList数据结构。表1中不完整数据集C由9个三维元组构成,其中“—”表示某元组在该维属性值缺失。
设不完整数据集C的3个维度的权值分别为0.4、0.2和0.5,表2给出了数据集C对应的RankList结构。

Table 1 Example of incomplete data sets表1 不完整数据集实例

Table 2 RankList structure表2 构建的RankList结构
由于海量数据的数据量较大,在构建RankList结构时,将数据进行分片排序,并行执行排序算法[13],提高构建RankList结构的效率。
3.2基于维度组合的空间划分
Skyline查询[14]是针对多维元组查询的操作,元组之间的关系由是否“支配”来判定。
定义1(元组的支配关系[15])元组tx支配元组ty(记为tx≻ty)当且仅当在所有维度tx都不比ty差,且在至少一个维度tx比ty好,即∀k,tx[k]≤ty[k]且∃l, tx[l]< ty[l]。在元组属性值越小越优的情况下,显然元组tx要优于元组ty。
不被其他元组支配的元组为Skyline点,Skyline点构成的集合即为Skyline查询结果。
设数据维度集合为Q,集合W中任意元素都是集合Q的元素,则称W为Q的维度子集。若某些元组在某个维度子集上不被支配,则这些元组中必含有Skyline点,故全局Skyline点可以通过维度子集渐进式地查出。
定义2(空间划分)数据集C由n维元组数据组成,用di代表元组的第i维,元组的维度{d1,d2,…,dn}构成集合Q。若某个维度集合W中的任一元素属于Q,则称集合W为维度集合Q上的空间。
例如,某个数据集由{d1,d2,d3}三维构成,有23-1个空间,如{d1},{d2},{d3},{d1,d2},{d1,d3},{d2,d3},{d1,d2,d3}。
定义3(空间关系)一般对于两个空间A、B,如果空间A中的任意一个元素(维)都是空间B的元素,就说A、B有包含关系,称空间A为空间B的子空间,记作A⊆B,同时也称空间B为空间A的父空间。空间B的全部子空间构成的集合记为Sub_ss(B)。
例如,空间A由维{d1}构成,空间B由{d1,d2}构成,则称空间B为空间A的父空间,空间A为空间B的子空间。
空间编码:数据集C中元组有n维,用di代表第i维。令空间W为维度集合Q的任一空间,编码规则为,存在于空间W中的维dp(p∈[1,n])用“1”代表,存在于维度集合Q但不存在于W中维dq(q∈[1,n])用“0”代表。例如,某个数据集由{d1,d2,d3}三维构成,子空间{d1,d3}用编号“101”表示。
3.3子空间最优先点的获取
定义4(优先点)在数据集C中,任一元组xi各维的值在RankList结构中的排序号Ranki(i∈[1,n])的集合表示为{Ranki1,Ranki2,…,Rankin}。在任意m维空间中,对该m维上任意完整元组xi计算其Ranki集合,并求出该集合中最大排序号Pi,即Pi=max{Ranki1, Ranki2,…,Rankim}。然后,求出该m维空间所有元组的Pi最小值Pmin,即Pmin=min{P1,P2,…,Pn},Pmin对应的元组xj称为优先点,该空间的优先点集合记为D。
以表2为例,查找{d2,d3}空间(空间编码为“011”)的优先点集。根据定义计算出“011”空间中各个元组的最大排序号:P1=max{Rank12,Rank13}= max{2,9}=9;同理,P2=4,P3=4,P4=5,P5=5,P6=6,P7= 5,P8=7。然后,求出该空间的Pi最小值:Pmin=min{P1,P2,P3,P4,P5,P6,P7,P8}={P2,P3},即“011”空间的优先点集为{x2,x3}。
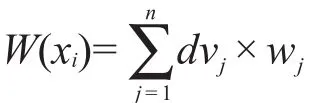
由定义4的实例可知,“011”空间的优先点集为{x2,x3}。计算:

由于6.9>4.6,故“011”空间的最优先点为x3元组。
定理1最优先点一定为Skyline点。
证明由元组支配关系的定义可知,Skyline点是不被其他点(元组)支配的点(元组)。从优先点定义可知,优先点集中可能存在一个点或多个点。下面针对这两种情况,对“最优先点一定为Skyline点”进行证明。
当某空间的优先点集D中只有一个点时,根据最优先点的定义可知,该点为最优先点x。再根据优先点的定义可知,优先点集外的任意一点至少有一维属性值大于x点对应维的属性值,即不存在支配x点的元组。因此,这个最优先点x就是Skyline点。
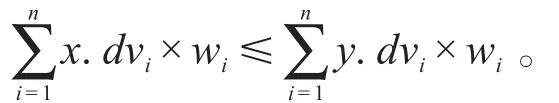
以表2为例,查询“011”空间及其子空间的最优先点。根据定义4、定义5可得,“010”空间最优先点为x7,“001”空间最优先点为x6,“011”空间最优先点为x3,其中x7为不完整元组。图1中,白色点为非Skyline点,曲线上的点均为Skyline点,其中黑色点代表最优先点,蓝色点代表非最优先点。从图1可以看出这些最优先点均匀地分布在Skyline点集中,在实际应用中这些最优先点渐进地被查询出来,既可以反映整体数据的轮廓,又可以提高查询效率。
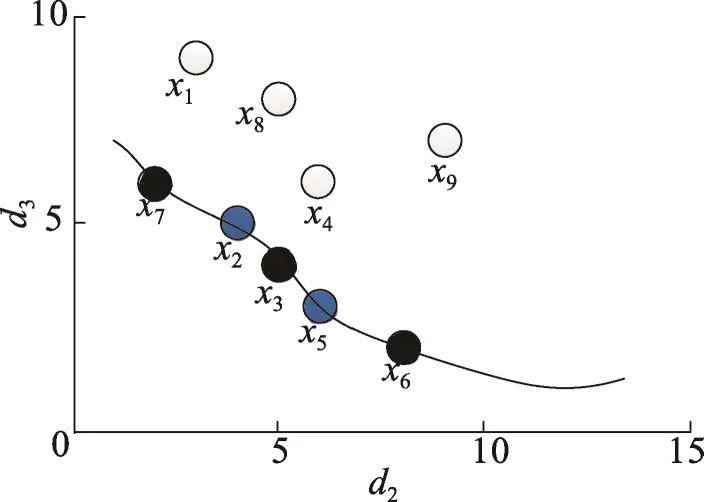
Fig.1 The highest priority points图1 最优先点的实例
4 基于空间划分的Skyline查询
针对海量不完整数据,CDskyline算法处理过程是首先构建RankList结构,并按序扫描RankList结构中各个桶,基于空间划分策略查询出各个空间的最优先点,得到最终的Skyline点集。
CDskyline算法的伪代码如算法1所示。首先构建RankList结构,然后按序依次横向扫描列表中各桶,调用算法2查询桶内是否有最优先点,扫描各桶直到某桶的空间编号等于2n-1(n为元组的维数)为止。该桶之后不会再扫描到Skyline点,因为该桶之后的点都能被该桶中的点支配。令MaxNo代表当前空间最大编号。
算法1 CDskyline
输入:海量不完整数据集
输出:最优先点集
1.根据数据集构建RankList结构
2. i=1,j=1;
3. While(MaxNo<2n-1)do
4.读取RankList结构中第i行、第j列的桶Pij;
5. Query(P);
6.更新i,j的值
7. end while
从最优先点定义可知,最优先点是空间中属性综合排序较靠前的元组,并且为Skyline点,在该空间具有较好的代表性。因此在对各个空间进行查询时,只需抽取出各个空间的最优先点,即可获得海量不完整数据的Skyline点。横向扫描RankList结构中桶Pij,并对桶Pij中元组映射的空间进行编码,根据定义4计算P桶中的点是否为该空间优先点。若桶Pij中点的id为“—”,则跳过该桶不做处理。如果桶Pij中的点是空间优先点,则根据定义5从这些优先点中找到最优先点,具体步骤详见算法2。
算法2 Query(Pij)
输入:桶Pij,Pij中包含元组(p1,p2,…,pn)
输出:某空间的最优先点
1. For (any point piin Pij) do
2. pi.No= Bitset(pi.No, j);
3. if (pi.No>MaxNo) then
4. MaxNo= pi.No;
5. end if
6. if (space[pi.No].state==False) then
7. space[pi.No].MaxValue== pi.Value;
8. space[pi.No].sp= pi;
9. Insert pi.No into NoList;
10. space[pi.No].state==true;
11. else
12. if (pi.No in NoList) then
13.if (pi.Value 14.space[pi.No].MaxValue==pi.Value; 15.space[pi.No].sp= pi; 16.end if 17. end if 18. end if 19. end for 20. for (any pi.No in NoList) do 21. if space[pi.No].sp has not been outputted then 22. Output space[pi.No].sp; 23. for (any q in Sub_ss(space[pi.No])) do 24.if (space[q].state==false) then 25.space[q].state=true; 26.end if 27.end for 28. end for 29. NoList = null; 令pi.No代表元组pi对应的空间编号;置位函数Bitset(pi.No,j)用于修改元组pi对应的子空间编号,其中j代表被扫描维;space[]代表空间;space[].sp代表空间的最优先点;pi.value代表pi点各属性值与权值乘积之和;space[].state代表空间状态是否被扫描过;NoList代表桶中最优先点映射的空间列表。 CDskyline算法通过横向扫描RankList结构中各个桶,渐进式地从各个空间中查询出最优先点,从而得到查询结果。以表2为例,简要说明CDskyline算法查询最优先点的过程。 (1)扫描RankList结构第一行第一列的桶,桶中的元组为x7,映射空间为“010”。根据算法2 Query()计算可知,x7元组为映射空间“010”的最优先点,故输出x7元组。 (2)扫描第一行第二列的桶,桶中元组为x3、x6,映射空间为“100”,x3元组的value值为4×0.4+5×0.2+ 4×0.5=4.6,同理得x6元组的value值为4.2,由于4.2 < 4.6,故x6元组为映射空间“100”的最优先点,输出x6元组点。 (3)扫描第一行第三列的桶,桶中的x6元组已经是“100”空间的点,同时又映射“001”空间,故x6元组为空间“101”的最优先点,同时修改其映射空间为“101”。由于x6元组已输出,故不再输出。此时遍历“101”空间的子空间,对未扫描的001空间状态置为true。 (4)按上述方法,依次扫描剩下的RankList结构,直到找到空间“111”的最优先点为止。 基于以上算法,本文设计了4个实验,从多个方面验证CDskyline算法的性能。实验主要关注以下几个方面的性能表现:(1)当维度从4维增加到16维时,各个算法响应时间的对比;(2)当维度从4维增加到16维时,各个算法结果集大小的对比;(3)数据集的大小对各个算法响应时间的影响对比;(4)数据集缺失率对算法响应时间的影响对比。 本实验的主机是一台8 GB内存,Intel Core i5-2400 3.10 GHz 4核CPU,台式PC机。实验中每个维的数据由正态分布函数产生,元组随机缺失其一维的数据生成实验数据,数据集中数据不完整率为10%。 5.1数据集的维度对响应时间的影响分析 本实验在不同的数据维度下,对算法性能进行分析。实验采用包含2×105条数据的数据集,维度的变化区间为[4,16],每一维的值域为[1,100],各维的权值均取1。实验将CDskyline算法和Iskyline算法进行对比,随着维度增加各自响应时间的情况如图2所示。 Fig.2 Influence of dimensions on response time图2 维度对响应时间的影响 从图2可以直观地看出,CDskyline算法比Iskyline算法具有更高的执行效率,并且随着维数的增加,CDskyline算法比Iskyline算法的优势更加明显。虽然CDskyline算法在高维时消耗的时间快速增长,但由于排序时间大致不变和子空间抽样的原因,使其时间消耗增长的速度比其他算法的增长速度慢。 5.2数据集的维度对结果集大小的影响分析 本实验在不同的数据维度下,对算法结果集大小进行分析。实验采用包含2×105条数据的数据集,维度的变化区间为[4,16],各维的权值均取1,每维的值域为[1,100]。实验将CDskyline算法和Iskyline算法进行对比,随着维度增加结果集数量的变化如图3所示。 Fig.3 Influence of dimensions on result set图3 维度对结果集的影响 从图3可以直观地看出,CDskyline算法比Iskyline算法的结果集小很多。由于CDskyline算法抽取的是属性空间的最优先点,故其抽取的Skyline点数不会超过2n(n为数据集的维数)个,从实验结果中已得到了验证。当数据集的维度较高时,CDskyline算法能从各个维度组合中渐进式地获取用户所需的Skyline点。由于两种算法得到的结果集大小差异较大,图3并不能详尽地反映CDskyline算法的变化趋势,该算法维度对结果集影响的详尽情况如图4所示。 Fig.4 Influence of dimensions on result set in CDskyline algorithm图4 CDskyline算法维度对结果集的影响 5.3数据集的大小对响应时间的影响分析 本实验分析数据集大小对算法响应时间的影响。实验数据集的维度为10,各维的权值均取1,每维的值域为[1,100],数据集大小变化区间为2×105~ 10×105条数据。实验将CDskyline算法和Iskyline算法进行对比,随数据集增加两种算法响应时间的变化如图5所示。 Fig.5 Influence of the size of dataset on response time图5 数据集大小对响应时间的影响 从图5中可以看出,CDskyline算法所花费的时间明显低于Iskyline算法所需时间,最初CDskyline算法所用时间约为Iskyline算法的30%,但随着数据集的增加,最终CDskyline算法所消耗时间约为Iskyline算法的20%。因为RankList结构列表中桶的有序性,抽样过程并没有随数据集的增加而消耗太多时间。但是由于需要对RankList结构进行排序和数据集的增加,CDskyline算法花费时间还是增加的。 5.4数据集的缺失率对响应时间的影响分析 本实验重点分析数据集缺失率对算法响应时间的影响。实验数据集的维度为10,各维的权值均取1,每维的值域为[1,100],数据集大小变化区间为2× 105~10×105条数据。设数据集缺失率为10%和20%,图6中用CDskyline_0.1与CDskyline_0.2表示。 Fig.6 Influence of missing data rate on response time图6 数据数据确实率对响应时间的影响 从图6中可以看出,缺失率对响应时间的影响不大。这是因为通过属性值排序构建RankList结构时,若某元组缺少di维的属性值,该元组在RankList结构中di维的排序靠后。当查询各个子空间的最优先点时,这些不完整数据对查询的影响较小。 本文针对海量数据查询中面临的数据不完整、数据量大、维度较高等问题,提出了一种海量不完整数据上基于维度组合的Skyline查询方法(CDskyline)。该方法深入分析了数据集的不同维度对查询的影响,通过构建RankList结构和按维度组合划分的子空间扫描查找策略,直接对海量不完整数据进行查询,减少了传统数据处理中预处理带来的查询代价。该方法从各个子空间获取最优先点,从而渐进地得到用户所需的Skyline点。CDskyline适用于海量不完整数据的Skyline查询,具有较高的查询效率。 References: [1] Li Jianzhong, Liu Xianmin. An important aspect of big data: data usability[J]. Journal of Computer Research and Development, 2013, 50(6): 1147-1162. [2] Cao Jianjun, Diao Xingchun, Chen Shuang, et al. Data cleaning and its general system framework[J]. Computer Science, 2012, 39(Z11): 207-211. [3] Lin Yinhua, Zhang Chunhai, Liu Jie. Realization of data cleaning based on editing rules and master data[J]. Computer Science, 2012, 39(Z11): 174-176. [4] Chen Wei, Ding Qiulin. Based on the data cleansing rules and master data restoration algorithm implementation[J]. Microcomputer & Its Applications, 2005, 24(2): 44-45. [5] Wei Xiaojuan, Yang Jing, Li Cuiping, et al. Skyline query processing[J]. Journal of Software, 2008, 19(6): 1386-1400. [6] Zhu Lin, Guan Jihong, Zhou Shuigeng. Skyline computation: survey[J]. Computer Engineering and Applications, 2008, 44(6): 160-165. [7] Arefin M S, Morimoto Y. Skyline sets queries from databases with missing values[C]//Proceedings of the 22nd International Conference on Computer Theory and Applications, Alexandria, USA, Oct 13- 15, 2012. Piscataway, USA: IEEE, 2012: 24-29. [8] Alwan A A, Ibrahim H, Udzir N I, et al. Skyline queries over incomplete multidimensional database[C]//Proceedings of the 3rd International Conference on Computing and Informatics, Bandung, Indonesia, Jun 8-9, 2011. [9] Bu Fanyu, Chen Zhikui, Zhang Qingchen. Incomplete big data imputation algorithm based on deep learning[J]. Microelectronics & Computer, 2014, 31(12): 173-176. [10] Chen Zhikui, Lv Ailing, Zhang Qingchen. A new algorithm for imputing missing data based on distinguishing the importance of attributes[J]. Microelectronics & Computer, 2013, 30(7): 167-172. [11] Balke W T, Ountzer U, Zheng J X. Efficient distributed skylining for Web information systems[C]//Proceedings of the 9th International Conference on Extending Database Technology, Heraklion, Greece, Mar 14-18, 2004.Berlin, Heidelberg: Springer, 2004: 256-273. [12] Khalefa M E, Mokbel M F, Levandoski J J. Skyline query processing for incomplete data[C]//Proceedings of the 24th International Conference on Data Engineering, Cancun, Mexico,Apr 7-12, 2008. Piscataway, USA: IEEE, 2008: 556-565. [13] Wang Wenyi, Qiu Yong. A new algorthm for parallel merge sorting[J]. Computer Engineering and Applications, 2005, 41(5): 71-72. [14] Borzsony S, Kossmann D, Stocker K. The Skyline operator [C]//Proceedings of the 17th International Conference on Data Engineering, Heidelberg, Germany, Apr 2-6, 2001. Piscataway, USA: IEEE, 2001: 421-430. [15] Xin Junchang, Bai Mei, Dong Han, et al. An efficient processing algorithm for ρ-dominant Skyline query[J]. Chinese Journal of Computers, 2011, 34(10): 1876-1884. 附中文参考文献: [1]李建中,刘显敏.大数据的一个重要方面:数据可用性[J].计算机研究与发展, 2013, 50(6): 1147-1162. [2]曹建军,刁兴春,陈爽,等.数据清洗及其一般性系统框架[J].计算机科学, 2012, 39(Z11): 207-211. [3]林印华,张春海,刘洁.基于清洗规则和主数据的数据修复算法实现[J].计算机科学, 2012, 39(Z11): 174-176. [4]陈伟,丁秋林.数据清理中不完整数据的清理方法[J].微型机与应用, 2005, 24(2): 44-45. [5]魏小娟,杨婧,李翠平,等. Skyline查询处理[J].软件学报, 2008, 19(6): 1386-1400. [6]朱琳,关佶红,周水庚. Skyline计算研究综述[J].计算机工程与应用, 2008, 44(6): 160-165. [9]卜范玉,陈志奎,张清辰.基于深度学习的不完整大数据填充算法[J].微电子学与计算机, 2014, 31(12): 173-176. [10]陈志奎,吕爱玲,张清辰.基于属性重要性的不完备数据填充算法[J].微电子学与计算机, 2013, 30(7): 167-172. [13]王文义,邱涌.一种新的并行归并排序算法[J].计算机工程与应用, 2005, 41(5): 71-72. [15]信俊昌,白梅,东韩,等.一种ρ-支配轮廓查询的高效处理算法[J].计算机学报, 2011, 34(10): 1876-1884. WANG Yan was born in 1978. She is an associate professor at Liaoning University, Ph.D. candidate at Northeastern University, and the student member of CCF. Her research interests include massive data query technology, sensing data processing and big data management, etc. 王妍(1978—),女,辽宁抚顺人,辽宁大学副教授,东北大学博士研究生,CCF学生会员,主要研究领域为海量数据查询技术,感知数据处理,大数据管理等。 YIN Biao was born in 1987. He is an M.S. candidate at Liaoning University, and the student member of CCF. His research interest is massive data query technology. 银彪(1987—),男,河南漯河人,辽宁大学硕士研究生,CCF学生会员,主要研究领域为海量数据查询技术。 LIU Genghao was born in 1990. He is an M.S. candidate at Liaoning University, and the student member of CCF. His research interest is massive data query technology. 刘赓浩(1990—),男,辽宁大连人,辽宁大学硕士研究生,CCF学生会员,主要研究领域为海量数据查询技术。 SONG Baoyan was born in 1965. She received the Ph.D. degree in computer software and theory from Northeastern University in 2002. Now she is a professor at Liaoning University, and the senior member of CCF. Her research interests include database theory and techniques, RFID event stream processing techniques, big data management and graph data management, etc. 宋宝燕(1965—),女,辽宁开原人,2002年于东北大学计算机软件与理论专业获得博士学位,现为辽宁大学教授,CCF高级会员,主要研究领域为数据库理论与技术,RFID事件流处理技术,大数据管理,图数据管理技术等。 WANG Junlu was born in 1988. He received the M.S. degree from Liaoning University in 2014. Now he is an assistant engineer at Liaoning University, and the member of CCF. His research interests include database theory and techniques, big data processing techniques and massive data processing techniques, etc. 王俊陆(1988—),男,辽宁丹东人,2014年于辽宁大学获得硕士学位,现为辽宁大学助理实验师,CCF会员,主要研究领域为数据库理论与技术,大数据处理技术,海量数据处理技术等。 Skyline Query of Massive Incomplete Data Based on Combinational Dimensionsƽ WANG Yan1,2, YIN Biao1, LIU Genghao1, SONG Baoyan1+, WANG Junlu1 + Corresponding author: E-mail: bysong@lnu.edu.cn WANG Yan, YIN Biao, LIU Genghao, et al. Skyline query of massive incomplete data based on combinational dimensions. Journal of Frontiers of Computer Science and Technology, 2016, 10(4): 495-503. Abstract:With the rapid development of Internet, Internet of things and other information technology, and multidimensional data increasing, these massive data are often accompanied by a large number of incomplete data. So how to efficiently get the approximate result sets required by users from the massive incomplete data is an urgent problem to solve. This paper proposes a Skyline query algorithm for the massive high-dimensional incomplete data sets based on combination of dimensions. The algorithm constitutes RankList data structure to improve query efficiency and reduce the impact of incomplete data for query results, divides query subspaces by combining different dimensions, and incrementally checks out the highest priority point in the subspace, that is Skyline points uniformly distributed in the incomplete data set. The experimental results show that, compared with the Iskyline algorithm, the query efficiency of the proposed algorithm increases by 85% on average.And when the data are huge amount and high dimension, the algorithmbook=496,ebook=50shows higher query efficiency than the ordinary methods. Key words:massive incomplete data; combinational dimensions; Skyline 文献标志码:A 中图分类号:TP311.1 doi:10.3778/j.issn.1673-9418.15060455 实验及结果分析





6 结束语





1. School of Information, Liaoning University, Shenyang 110036, China
2. School of Information Science and Engineering, Northeastern University, Shenyang 110819, China
