
聚类分析在高校教务系统中的应用研究
2016-06-29 19:20施立珊李就娣莫卓达
电脑知识与技术 2016年13期
施立珊 李就娣 莫卓达
摘要:在教育大局势的不断改革之下,教师队伍不断地扩充。各高校的师资储备越来越多,如何提高教师的教学水平,成为了很多高校急需解决的难题。教学质量评价在某种意义上成为衡量教师教学的方向标。该文选取我院专业教师的教学质量评价分数作为研究对象,以聚类分析为挖掘向导来分析教学质量的各种因素,得出不同专业、不同职称教师对教学质量评价的影响程度。
关键词:教学质量评价;数据挖掘;聚类分析;凝聚聚类算法
中图分类号:TP301 文献标识码:A 文章编号:1009-3044(2016)13-0018-03
Abstract: Under the education situation of the reform, teachers constantly expanding. More and more universities faculty reserves, how to improve teachers' teaching level, has become the need to solve the problem of many colleges and universities. Teaching quality evaluation in some sense, become the direction of the teacher's teaching standard. This article selects in our professional teachers teaching quality evaluation scores as the research object, by clustering analysis for mining the guide to analyze the various factors of teaching quality, it is concluded that different professional, different title teachers' influence on teaching quality evaluation.
Key words:teaching quality evaluation; data mining; clustering analysis; clustering algorithm
大数据成为了当今非常热门的话题。数据的大量存储和简单罗列并没有给出数据实际的应用价值。在高校教学管理中,教师的教学质量评价数据也渐渐地成为了高校存储数据的重要组成部分[1]。而各高校如何有效的评价教师的教学水平和教学质量的高低,很大程度上没有准确的标准和统一的规范。而每个学期的教学质量评价数据某种程度上是可以给出教师教学水平的参考数据。这样的参考数据如果能够使用数据挖掘的相关方法去分析和计算,所得出的结论是可以为职能部门提高参考意见。
数据挖掘作为数据分析和应用的有效手段在日益增多的大数据面前可以显示出足够的应用价值。而现实生活中可以应用大数据进行分析的地方非常的多。学生每个学期对所任课程教师的教学评价成为了高校教学管理数据中非常重要的组成部分。本文引用我校教师教学质量评价数据进行分析和挖掘,最终得出有意义的参考价值数据。
1 教学质量评价的必要性及采取的方法
目前各高校教师岗位的不断扩充,对于高等院校教育的学生而言,教学质量的好坏将极大地影响他们在社会上的竞争力[2]。如果采用传统的评价指标和体系即学生掌握知识的多少和教师上课数量的多少来衡量已经不能很好地反映教师的教学质量水平。在科技快速发展的今天如果还只是停留在传统的数量统计层次是很难适应社会的高效发展。
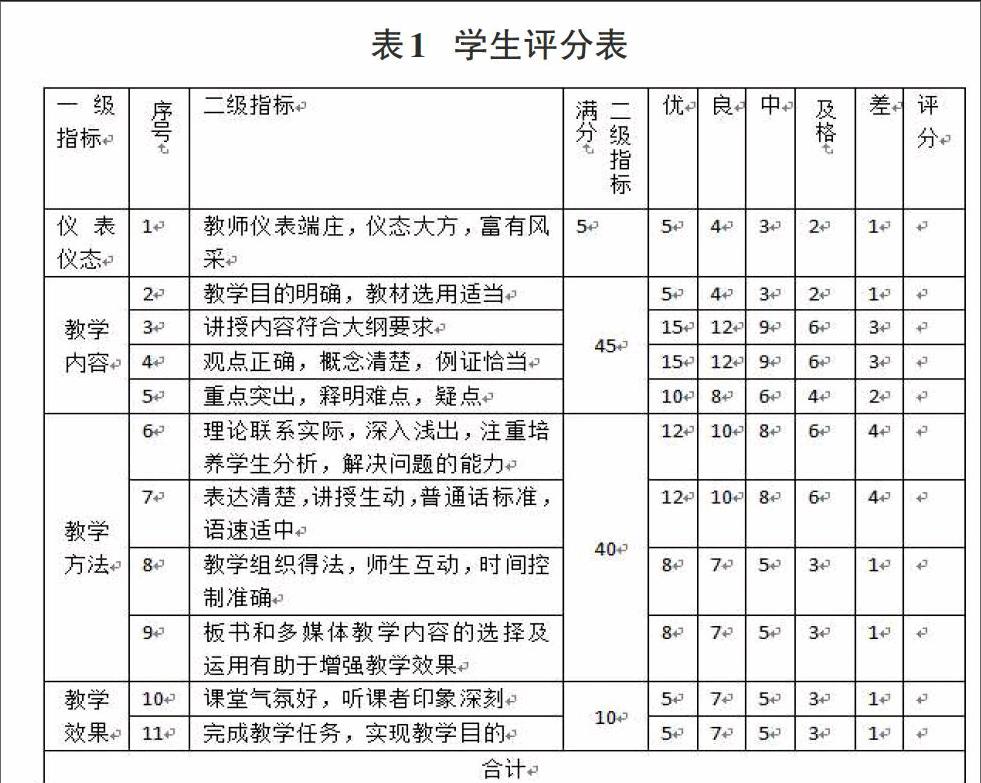
如今各大高校都采用学生的教学质量评价分数来衡量教师本学期教学质量的高低。虽然某种程度上存在一定的不客观性。但是随着评价体系的不断改革,现有的评价分数已经能很好地反映该现实问题。比如学生评价数据的前10%和后10%的数据会被去掉、数据中出现的满分和零分也会去掉、在评价标准中增加了适当的权重值。这样得出的有效分数就能客观分析出相应的结论。下表为学生评分表的一级指标和二级指标。
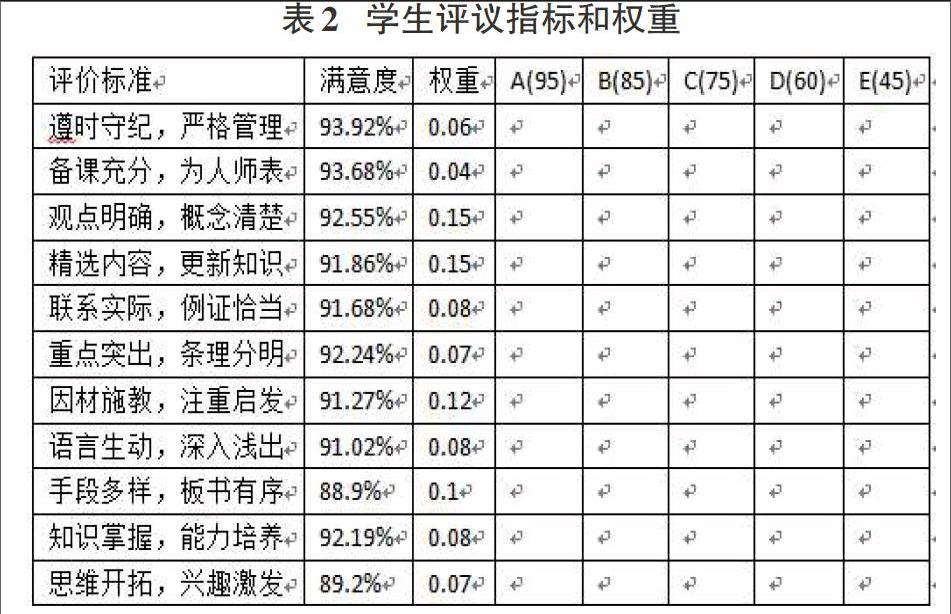
面前正在我校施行的评价体系并没有区分不同专业课程、不同语种课程和公共选修课程的评价区别。所有课程采用的是相同的评价指标。以我校广东外语外贸大学南国商学院的教学质量评价体系中的指标和权重值如下。
为避免学生在给教师的评分中占据主导地位,应适度加强教师学生互评以及学生之间的互评,舍弃评分中不合常理的数据,以达到评分的公平性。因此,制定完善的评价体系是全面推动素质教育的关键所在[2]。
2挖掘对象及挖掘过程
2.1数据选择
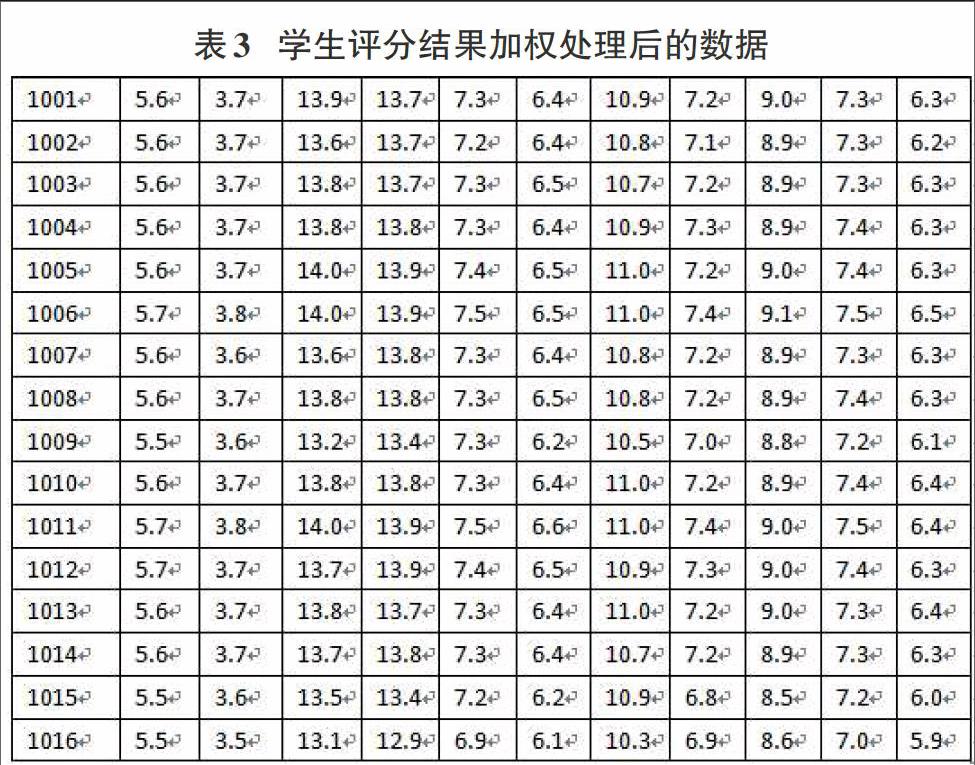
此次运用的是广外南国商学院信息学院16名教师在2012-2014年中一个学期对比四个学期(四年评分采取四年的评分取平均分值)的聚类结果为切入点,以期待获得更多更好的有实用价值的数据信息,评价标准如表3,在学生评分表中教师工号采取顺序虚拟工号,加权平均分后的表如表3。
2.2 挖掘过程
2.2.1 聚类算法[3]
聚类算法文字描述如下[a-d]
1)初始分类。令k=0,每个模式自成一类,即Gi(0)={xi}(i=1,2,…,c)。
2)计算各类间的距离Dij,生成一个对称的距离矩阵D(k)=(Dij)m+n,m为类的个数。
3)找出前一步求得的矩阵D(k)中的最小元素,设它是Gi(k)和Gj(k)间的距离,将Gi(k)和Gj(k)两类合成一类,于是产生新的聚类G1(k+1),G2(K+1),…,令m=m-1。
4)检查类的个数。如果类书m大于2,令k=k+1,转至2);否则,停止。
如果某一循环中具有最小类间距离不只一个类时,则对应这些最小距离的类可以同时合并。上述算法步骤给出了从N类至2类的完整聚类过程呢个,停止条件有两个,其一是以类间距离门限T作为停止条件,即取距离门限T,当D(k)中最小阵元大于T时,聚类过程停止;其二是以预定的类别数目作为停止条件,当类别合并过程中,类数小于或等于预定值时,聚类过程停止。
2.2.2 具体挖掘过程
1)将每一样本看成一类
计算距离矩阵D(1)的计算方法:dij=[(xi-xj)i(xi-xj)]1/2=[(xi-xj)2]1/2,例如:
D120=((5.6-5.6)2+(3.7-3.7)2+(13.9-13.6)2+(13.7-13.7) 2+(7.3-7.2) 2+(6.4-6.4) 2+(10.9-10.8) 2+(7.2-7.1) 2+(9.0-8.9) 2+(7.3-7.3) 2+(6.3-6.2) 2)1/2,计算距离矩阵D(0)。
2)D(0)中的最小阵元是0.14,它是G40和G100之间的距离,将它们合并为一类,得一新的分类为G11={G40,G100}={X4,X10} G21={G10} G31={G20} G41={G30} G51={G50} G61={G60} G71={G70} G81={G80} G91={G90} G101={G110} G111={G120} G121={G130} G131={G140} G141={G150} G151={G160} 计算合并后的距离矩阵D(1)。
3)以此类推分别计算D(1)、D(2)、D(3)、D(4)、D(5)、D(6)、D(7)。在D(7)中的最小阵元是0.63,它是G17与G37之间的距离,将它们合并为新的一类,G18={G17,G37}={X15,X16,,X9} G28={G27}={X4,X10,X1,X3,X7,X8,X13,X14,X2,X12,X5,X6,X11},最后G18和G28合并为一类,算法结束。
2.2.3 聚类树
学生评教的分数采用最近距离聚类的凝聚聚类结果数如图1所示:
从树型结果图中可清晰看见各观测量的聚类情况,聚类结果明显。
2.2.4 系统聚类挖掘结果分析
对于聚类结果,这16名教师可以8次迭代过程:
第一次迭代过程是编号为{1004,1010}的教师;
第二次迭代过程加入了编号为{1001,1003,1007,1008,1013,1014},{1006,1011}的教师;
第三次迭代过程加入了编号为{1002}的教师;
第四次迭代过程加入了编号为{1012}的教师;
第五次迭代过程加入了编号为{1005}的教师;
第六次迭代过程加入了编号为{1006,1011}的教师;
第七次迭代过程是编号为{1015,1016}的教师;
第八次迭代过程加入了编号为{1009}的教师;
第九次迭代过程是合并前后两个分类的教师。
2.2.5 四学期教师评分聚类分析
按照上述计算方法得出四个学期的聚类树结果。
此次运算还把四学期中所有的专业必修,专业选修,通选课,公共课,二级辅修课分类取平均值如下:
3 聚类结果的指导作用
通过上述的聚类挖掘过程,我们能都很好的得出在教学质量评价中哪些因素对数据的影响值较大,哪些次之。这样的影响因素虽然不能成为主要的内容,但是能够很好地反映出学生对教师所授课程的综合评价。教师可以很好的分析该结论数据这样对今后改进教学质量和效果都会有很大的帮助。
从上述一个学期和四个学期我系16名老师的聚类结果看,首先迭代聚类的是公共基础课和应用软件课程,往后聚类的才是专业性较强的必修课程。从课程性质和教学效果中,我们能够分析出公共基础课程的学习较为简单,通俗易懂,学生学习起来不会有太大的难度,这样对于评价分数而言是占据很大的优势。而应用软件的课程多数是多媒体设计类的课程,比如ps、flash等相关课程。这样的课程本身就有它自己的特色,教学效果非常明显,学生容易上手,普遍受到大家的欢迎。而专业课程枯燥乏味,学习起来难度较大,往往会出现一个学期讲下来学生都没有听懂。教学效果没有上述两门课程好,这样就直接导致数据的偏差。以上的分析和现实事件是非常吻合的。
但是对于极个别老师应用多种教学手段不断改进教学方法,对课程内容和课堂效果把握较好的老师,无论是什么类型的课程都普遍受到学生好评。
从表4中可以看出,专业必修课,公共课和计算机二级课程的评分相对比较高,处于基础的课程学生的学习兴趣相对高出许多。对于专业选修课,设计专业知识的实操性强学生的学习上相对会有压力,学习的动力也会有所削弱因此评分也相对较低。得出另外一个结果:学生对所有课程的评价要对不同的课程有所区别,这样才能做到公平公正,因为从学生的评分中我们能看出,专业课程学习的学生和公共课程学习的学生对老师的要求是有很大区别的,所以在制定课程评分指标的时候要有区别对待。
参考文献:
[1] 张钰莎.数据挖掘在高校图书馆服务中的应用研究[J].廊坊师范学院学报,2015(7).
[2] 张钰莎.数据挖掘技术在教学质量评估中的应用研究[D].广州:暨南大学,2012.
[3] 蒋盛益.商务数据挖掘与应用案例分析[M].北京:电子工业出版社,2014.
猜你喜欢
电力与能源(2017年6期)2017-05-14
考试周刊(2016年56期)2016-08-01
考试周刊(2016年8期)2016-03-12
信息通信技术(2015年6期)2015-12-26
电子设计工程(2014年18期)2014-02-27
