
基于流形正则化半监督学习的污水处理操作工况识别方法
2016-07-07 12:12赵立杰王海龙陈斌沈阳化工大学信息工程学院辽宁沈阳110142
化工学报 2016年6期
关键词:污水处理
赵立杰,王海龙,陈斌(沈阳化工大学信息工程学院,辽宁 沈阳 110142)
基于流形正则化半监督学习的污水处理操作工况识别方法
赵立杰,王海龙,陈斌
(沈阳化工大学信息工程学院,辽宁 沈阳 110142)
摘要:污水处理过程容易受外界冲激扰动影响,引发污泥上浮、老化、中毒、膨胀等故障工况,导致出水水质质量差,能源消耗高等问题,如何快速准确识别污水操作工况故障至关重要。针对污水工况识别过程中现有监督学习方法未利用大量未标记数据蕴含的丰富操作工况信息,采用基于流形正则化极限学习机的半监督学习方法,监视生化污水处理过程操作运行工况。该方法在学习过程中,在标记和未标记数据输入空间构建图拉普拉斯算子,通过随机特征映射建立隐含层,在流形正则化框架下,求解隐含层和输出层之间的权重,保留随机神经网络的计算效率和泛化性能。仿真实验结果表明,基于半监督极限学习机的污水处理工况识别在准确率与可靠性方面相对优于基本极限学习机方法。
关键词:污水处理;极限学习机;半监督算法;流形正则化
2015-10-30收到初稿,2016-03-14收到修改稿。
联系人及第一作者:赵立杰(1972—),女,博士,教授。
Received date: 2015-10-30.
Foundation item: supported by the National Natural Science Foundation of China (61203102, 61573364) and the Research Project of Liaoning Provincial Educational Department (L2013158, L2013272).
引 言
污水生化处理是缓解水环境污染的有效途径。由于生化处理系统的主体是有生命的细菌,其培养驯化、调整恢复非常缓慢和困难,且受外界环境的变化影响较大,如pH波动、供氧不足、负荷的冲击、有毒物质的流入、错误操作等,常常引起污泥上浮、老化、中毒、膨胀、漂出等二沉池故障工况。如果不及时发现和处理,直接影响系统的出水指标和操作成本,甚至造成系统的停滞、瘫痪和破坏[1]。另外,由于污水处理机理复杂,工艺内部交互耦合、出水水质指标不能连续在线检测且化验周期漫长,现有的以精确数学模型为基础、以控制系统性能指标为目标的优化控制理论与方法难以应用,导致污水处理稳定性差、效率低、成本高等问题,因此识别污水处理过程操作工况对于增强污水处理厂优化运行和优化控制具有重要意义。
污水处理操作工况识别方法主要有基于解析模型方法、基于定性经验知识方法和基于数据驱动方法三大类。基于解析模型的方法需要准确的机理模型,而污水处理过程由于非线性、多变量、非平稳复杂特性,很难获取准确的数学模型。文献[2]采用正反向混合推理机制,以故障树的形式表示知识库中的知识,开发了城市污水处理厂日常运行故障诊断专家系统。Carrasco等[3]建立了基于模糊推理的污水处理故障诊断专家系统,并且在实际污水厂成功应用。污水处理故障诊断专家系统性能很大程度上取决于专家知识库的完备性。基于数据驱动方法包括多元统计方法[4]、支持向量机[5]和神经网络方法等。基于多元统计的数据驱动污水处理故障诊断充分利用了污水处理过程DCS采集海量数据的优势,但是该类方法往往缺乏故障分类标记的监督指导,在故障定位能力方面略有不足。支持向量机和神经网络可以充分利用标记数据指导作用,是一种有监督的学习方法。文献[6]基于多分类概率极限学习机神经网络方法识别污水处理过程工况。这些监督学习方法通常假设数据样本已标记且样本数量足够。
为减少标记代价,提高识别准确率,自动利用少量已标记数据和大量未标记数据的半监督学习受到工业界和学术界的关注[7-10]。半监督学习方法,如TSVM[11],LapRLS和LapSVM[12]等,通常假设标记数据样本和未标记数据样本具有相同的边界分布,利用未标记的样本帮助学习平滑的数据几何结构。文献[13-14]在流形正则框架下引进ELM[15]模型平衡标记数据和未标记数据,通过在监督学习问题中加入和流形相关的正则化项,可以尽可能多地利用无标记数据,使得模型输出保持原特征空间的几何结构。文献[16]在流形正则极限学习机二分类基础上,提出了基于流形正则化极限学习机半监督学习算法,通过与支持向量机、拉普拉斯偏最小二乘法、拉普拉斯支持向量机等方法比较,实验验证了基于流形正则化半监督的极限学习机方法具有较高的准确性和泛化性。
针对污水工况识别过程中现有监督学习方法未利用大量未标记数据蕴含的丰富操作工况信息,本文采用基于流形正则化极限学习机的半监督学习方法,监视生化污水处理过程操作运行工况。
1 城市污水处理过程描述
城市污水处理过程采用活性污泥二级生化处理工艺,如图1所示。
进水经过预处理和初沉池去除污水中悬浮固体和漂浮物后,进入曝气池和二沉池组成的二级生物处理单元。曝气池内微生物降解有机物进行新陈代谢,二沉池内污泥通过重力作用进行固液分离。处理过的污水从沉淀池溢流排出,污泥从二沉池底部回流到曝气反应池以维持适当的污泥浓度,剩余污泥经浓缩、消化、压滤脱水处理。
污水处理厂通常在入水、初沉池、曝气池和二沉池以及出水处检测水质、水量指标,各监测点变量名称和含义见表1。在污水处理厂运行操作过程中,常见的异常操作工况包括入水水质指标超负荷、欠负荷运行、入水水量的冲击如干旱、暴雨等事件以及污泥上浮、老化、中毒、膨胀、漂出等二沉池问题。
2 半监督极限学习机
2.1极限学习机
极限学习机ELM是一种用于训练单隐含层前馈神经网络方法。由于ELM随机初始化输入权值和隐含层偏置,最小二乘方法求解输出权值,克服了传统梯度下降学习算法训练速度慢、容易陷入局部极小点、学习率敏感等不足,该方法具有学习速络输出为度快,泛化能力强等优点[15]。

图1 活性污泥污水处理工艺流程Fig.1 Flow chart of activated sludge wastewater treatment process

表1 污水处理过程监测变量Table 1 Wastewater treatment process variables
对于任意N个训练样本(xj, tj),假设具有ˆ个隐含层神经元和激活函数G(wi,bi, x ),ELM神经网

其中,x∈Rn,wi∈ Rn,βi∈ Rm。G(wi,bi, x )为与输入x对应的第i个隐含层神经元的输出;为第i个隐含层神经元与输出之间的连接权向量。激活函数g( x )取为RBF神经元时,隐含层输出为

其中,wi和bi分别为第i个径向基函数的中心和影响因子;R+是一个正实数集合。存在iβ,wi和bi,以零误差逼近这N个样本点,即

式(3)可以写成矩阵形式为

其中,H是ELM神经网络的隐含层输出矩阵

2.2流形正则化框架
半监督学习算法的建立需要以下两个前提[16]:①标记数据Xl和未标记数据Xu来自于相同的边界分布Px;②如果两个点x1、x2接近,那么条件概率P( y | x1)和P( y | x2)也是相似的。流行正则化框架提出最小化成本函数Lm

其中,Wij是xi和xj这两个类型之间的分段相似矩阵。相似矩阵W=[ Wij]通常情况下非零元素很少,因此需要在xi和xj这两个类型之间放置一个非零权值,如果xi和xj这两个点接近,也就是说xi是xj的k最近邻。非零权值通常由高斯公式计算,,或者设置为固定值1。
由于条件概率计算困难,采用数据样本的预测误差加权平方和近似Lm

yi、yj分别是数据样本xi和xj的预测值,采用矩阵形式简化表达式(6)

Tr(~)表示一个矩阵的迹,L= D− W是图拉普拉斯算子,D是对角矩阵,对角元素为。
2.3结合流形正则化框架与极限学习机的半监督学习算法
高维输入特征通常会引起模型复杂,泛化性能降低。实际上,高维空间数据分布在低维流形子空间上。通过有标记和无标记样本共同来挖掘嵌入在高维空间中数据分布的几何结构,然后在机器学习问题中加入流形正则化项,约束模型输出的几何形状,将有监督数据和无监督数据结合结合起来学习的半监督学习方法,有效解决高维度带来的模型高复杂度导致模型的泛化能力下降问题[16]。

其中,图拉普拉斯矩阵L由标记数据和未标记数据共同建立,模型输出预报矩阵,正则项系数λ控制数据分布的几何形状。
模型训练过程中,模型倾向于适配训练样本多的类,类间数据样本个数不均衡会影响半监督学习效果。为缓解样本不均衡模型泛化性降低问题,通过对不同类分别施加不同惩罚参数,避免样本多的类出现过拟合,样本少的类被忽略。假设样本xi属于类ti,类ti有Nti个训练样本,为平衡类间个数不均衡带来的误差,类间惩罚参数Ci等于C0除以所属类的个数Nti

其中,C0是ELM模型正则项参数。将约束因子带到目标函数中,写成矩阵形式

Y∈Rnh × n0是训练目标值,第l行为Yi,其余行为零,C是对角矩阵,前l行对角元素为[C]ii=C(i= 1, L , l),其余值为零。关于β目标函数的梯度
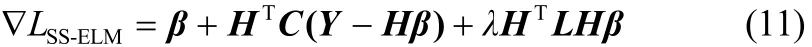
通过设置梯度为零,求解β。当标记数据的个数大于隐含层神经元个数时

当标记数据的个数小于隐含层神经元个数时,

Il+u是一个l+ u维的单位矩阵。当设置平衡参数λ为零、对角矩阵元素[C]ii=Ci(i=1, L , l)为常量时,式(12)、式(13)提高极限学习机算法学习效率。
半监督极限学习机SS-ELM算法如表2所示。

表2 半监督极限学习机SS-ELM算法Table 2 Algorithm of semi-supervised ELM
3 实验结果及讨论
本节主要研究半监督极限学习机在污水处理过程操作工况识别性能,并与传统监督学习方法极限学习机ELM进行对比。
污水处理数据来源于UCI数据库[17]。该数据是Manresa城市污水处理厂1990~1991年日常监测数据,共包含527样本,38个属性变量,涵盖12类不同的操作工况,包括2类正常工况、1类入水欠负荷、2类固体超负荷、3类暴雨工况、4类二沉池异常工况。事实上,UCI_WWTP污水处理厂采集来的数据存在缺失和离群点,这类数据会恶化模型学习性能。本文采用一种能够抑制离群点的鲁棒EMPCA数据校正方法[18]进行离群点识别和缺失数据的处理。数据预处理前后部分属性变量处理结果如图2所示。从图2可以看出,经过鲁棒EMPCA数据校正后数据变量中离群点能够被识别,缺失点得到合理估计。

图2 数据预处理前后变量趋势对比Fig.2 Variable trend comparison before and after data preprocessing
针对半监督学习需要大量标记和无标记样本数据训练,本文选用常见的3类污水处理工况:正常、超负荷和欠负荷工况,460个样本进行半监督学习。考虑生物需氧量BOD水质指标获取时间长,忽略各监测点BOD变量,剩余31个变量作为模型数据集。正常工况、超负荷工况和欠负荷3类工况分别编码为整数Ⅰ、Ⅱ、Ⅲ,如表3所示。

表3 污水处理数据集和编码Table 3 Wastewater treatment data and encoding
3类工况数据集合样本个数分别为275、116和69。模型训练和测试过程中,整个数据集合被划分为4个部分:带标记的数据集合L,校验集合V、未标记数据集U和测试数据样本集T。有标记数据集合L和未标记数据集U用于训练半监督SS-ELM模型,校验集合V用于模型超参数选择。
污水操作工况识别半监督SS-ELM方法训练包括输入权值随机初始化和输出权值求解。在计算隐含层输出矩阵H过程中,激活函数采用Sigmoid类型函数,输入权值和偏差一致分布在(−1,1)范围内。隐含层节点nh设定在100~2000范围内,每隔100递增。文中采用分类精度和误差评价模型的性能,两者均百分比表示。其中,分类精度等于测试数据正确分类样本个数占总样本个数的百分比。分类误差等于100减识别精度。图3显示了隐含层节点数目对识别精度的影响。从图3中可以看出,隐含层节点个数选为200。

图3 隐含层节点数目对识别精度的影响Fig.3 Influence of hidden neuron number on recognition accuracy
实验过程中,基于校验集分类精度确定合适的参数C0和λ。寻优过程中,模型参数C0和λ设置范围为。图4显示不同参数C和λ0对识别精度的影响。图4中参数C0和参数λ采用对数坐标lgC0和lgλ表示,由图4确定最优参数C0= 0.1和λ=0.01。
保持模型参数不变情况下,设置不同比例的标记和未标记数据比较模型性能。不同数量标记数据的SS-ELM和传统ELM方法性能对比如图5所示。图5显示,当标记数据量不断增加时,SS-ELM模型误差趋向降低。图6显示了在加入不同数量未标记数据下SS-ELM和ELM性能对比。图6显示,随着未标记数据增多,半监督方法SS-ELM识别精度优于传统ELM,这是因为未标记样本扩充了训练数据样本。

图4 参数C、λ对识别精度的影响Fig.4 Influence of parameters C and λ on accuracy

图5 不同数量的标记数据测试误差Fig.5 Influence of different number of labeled data on test error

图6 加入未标记数据个数测试误差Fig.6 Influence of unlabeled data on test error
4 结 论
针对污水处理过程存在少量已标记样本和大量未标记样本,采用基于流形正则化半监督极限学习机方法,通过随机产生隐含层参数,避免复杂的迭代过程从而提高学习速率,融合未标记样本信息,增强模型分类识别精度,避免标记数据少模型精度不足问题。仿真实验结果表明,基于半监督极限学习机的污水处理故障识别方法准确率与可靠性相对优于传统极限学习机方法。
符号说明
bi,wi——分别为第i个隐含层神经元阈值和连接权值
C——惩罚因子系数对角矩阵
C0——预报误差的惩罚参数初始值
D——稀疏相似对角矩阵
F——神经网络输出矩阵
L——图拉普拉斯算子
Tr(~)——矩阵的迹
{Xl, Yl}——训练集标记数据
Xu——非标记数据
yi,yj——分别为样本数据xi和xj的预测值
β——隐含层权值矩阵
λ——平衡参数
References
[1]FIKAR M, CHACHUAT B, LATIFI M A. Optimal operation of alternating activated sludge processes [J]. Control Engineering Practice, 2005, 13 (7): 853-861.
[2]CHONG H G, WALLEY W J. Rule-based versus probabilistic approaches to the diagnosis of faults in wastewater treatment processes [J]. Artificial Intelligence in Engineering, 1996, 10 (3): 265-273.
[3]CARRASCO E F, RODRÍGUEZ J, PUÑAL A, et al. Rule-based diagnosis and supervision of a pilot-scale wastewater treatment plant using fuzzy logic techniques [J]. Expert Systems with Applications, 2002, 22 (1): 11-20.
[4]TOMITA R K, SONG W P, SOTOMAYOR O A Z. Analysis of activated sludge process using multivariate statistical tools—a PCA approach [J]. Chemical Engineering News, 2002, 90 (3): 283-290.
[5]FAN X W, DU S X, WU T J. Rough support vector machine and its application to wastewater treatment processes [J]. Control and Decision, 2004, 19 (5): 573-576.
[6]GUO H, JEONG K, LIM J. Prediction of effluent concentration in a wastewater treatment plant using machine learning models [J]. Journal of Environmental Sciences, 2015, 32 (105): 90-101.
[7]SHAHSHAHANI B M, LANDGREBE D A. Using partially labeled data for normal mixture identification with application to class definition [C]//Geoscience and Remote Sensing Symposium, 1992. IGARSS '92. International. IEEE, 1992:1603-1605.
[8]NIYOGI P. Manifold regularization and semi-supervised learning: some theoretical analyses [J]. Journal of Machine Learning Research, 2013, 14 (1): 1229-1250.
[9]ZHU X. Cross-domain semi-supervised learning using feature formulation [J]. IEEE Trans. Syst., Man, Cybern. - Part B: Cybern., 2011, 41 (6): 1627-1638.
[10]WANG G, WANG F, CHEN T, et al. Solution path for manifold regularized semi-supervised classification [J]. IEEE Trans. Syst., Man, Cybern. - Part B: Cybern., 2012, 42 (2): 308-319.
[11]VAPNIK V N. Statistical Learning Theory [M]. New York: Wiley, 1998.
[12]BELKIN M, NIYOGI P, SINDHWANI V. Manifold regularization: a geometric framework for learning from labeled and unlabeled examples [J]. Journal of Machine Learning Research, 2006, 7 (3): 2399-2434.
[13]LIU J, CHEN Y, LIU M, et al. SELM: semi-supervised ELM with application in sparse calibrated location estimation [J]. Neurocomputing, 2011, 74 (16): 2566-2572.
[14]LI L, LIU D, QUYANG J. A new regularization classification method based on extreme learning machine in network data [J]. Journal of Information & Computational Science, 2012, 9 (12): 3351-3363.
[15]HUANG G B, ZHU Q Y, SIEW C K. Extreme learning machine: theory and application [J]. Neurocomputing, 2006, 70:489-501.
[16]HUANG G, SONG S, GUPTA J N, et al. Semi-supervised and unsupervised extreme learning machines [J]. IEEE Transactions Cybernetics, 2014, 44 (12): 2405-2417.
[17]http://archive.ics.uci.edu/ml/datasets/Water+Treatment+Plant.
[18]ZHAO L J, CHAI T Y, CONG Q M. Operating condition recognition of pre-denitrification bioprocess using robust EMPCA and FCM [C]// CHAI T Y. The Sixth World Congress on Intelligent Control and Automation, IEEE WCICA. Dalian, 2006: 9386-9390.
Identification of wastewater operational conditions based on manifold regularization semi-supervised learning
ZHAO Lijie, WANG Hailong, CHEN Bin
(College of Information Engineering, Shenyang University of Chemical Technology, Shenyang 110142, Liaoning, China)
Abstract:The wastewater treatment process is vulnerable to the impact of external shocks to cause sludge floating, aging, poisoning, expansion and other failure conditions, resulting in effluent deterioration and high energy consumption. It is urgent to quickly and accurately identify the operating conditions of wastewater treatment process. In the existing supervised learning methods all the data are labeled which are time consuming and expensive. A multitude of unlabeled data to collect easily and cheaply have rich and useful information about the operating condition. To overcome the disadvantage of supervised learning algorithms that they cannot make use of unlabeled data, a semi-supervised extreme learning machine algorithm based on manifold regularization is adopted to monitor the operation states of biochemical wastewater treatment process. The graph Laplacian matrix is constructed from both the labeled patterns and the unlabeled patterns. Extreme learning machine algorithm is adopted to handle the semi-supervised learning task under the framework of the manifold regularization. It constructs the hidden layer using random feature mapping and solves the weights between the hidden layer and the output layer, which exhibit the computational efficiency and generalization performance of the random neural network. The results of simulation experiments show that the fault identification method based on semi supervised learning machine has superiority to the basic extreme learning machine in improving the accuracy and reliability.
Key words:wastewater treatment; extreme learning machine; semi-supervised learning; manifold regularization
中图分类号:TP 391
文献标志码:A
文章编号:0438—1157(2016)06—2462—07
DOI:10.11949/j.issn.0438-1157.20151625
基金项目:国家自然科学基金项目(61203102,61573364);辽宁省教育厅科学研究项目(L2013158, L2013272)。
Corresponding author:Prof. ZHAO Lijie, zlj_lunlun@163.com
猜你喜欢
中国应急管理科学(2022年2期)2022-05-23
建材发展导向(2022年2期)2022-03-08
今日农业(2021年20期)2021-11-26
建材发展导向(2021年15期)2021-11-05
环境保护与循环经济(2021年12期)2021-03-16
山东冶金(2019年3期)2019-07-10
资源节约与环保(2018年1期)2018-02-08
资源节约与环保(2018年1期)2018-02-08
消费导刊(2017年24期)2018-01-31
中国资源综合利用(2017年4期)2018-01-22
