
综合评价中一种凹性指数型功效函数
2016-08-04 05:42封婷
统计与信息论坛 2016年7期
封 婷
(中国社会科学院 人口与劳动经济研究所,北京 100028)
综合评价中一种凹性指数型功效函数
封婷
(中国社会科学院 人口与劳动经济研究所,北京 100028)
摘要:目前主流功效函数多为凸性,在处理社会经济数据集中常见的右偏样本时效果难以令人满意。通过系统探讨凸性和凹性功效函数各自的适用特征,指出凹性函数在应用中有其必要性。归纳并使用偏度、区分度、P-P图三种方法作为分布形态的评判标准,比较了常见功效函数对指标原始数据分布形态的调整作用。在分析基础上,提出一种改进的凹性指数功效函数,能有效地处理右偏数据,且相比使用对数预处理的凸性功效函数更具适用性与便利性。
关键词:功效函数法;无量纲化方法;凹凸性变换;分布形态
一、文献综述
当前数据资料规模急速增长和类型多样化对数据管理水平提出了更高的要求。综合评价方法可以将多指标数据标准化和综合化,实现比较和监测,以供决策需要。功效函数法是一种既基础又实用的综合评价方法,它将评价过程分为两步:第一步是对单个评价指标样本标准化形成功效得分,使之具有可比性,从而解决不可公度的问题,这步也被称为无量纲化(或规范化、同度量化);第二步是使用合成模型将各个功效得分汇总形成总评价值,即加权合成。实践中功效函数综合评价法得到广泛应用,可归结为两方面的优点:其一,思路简明,过程和结果清晰直观,易于理解和应用;其二,多种无量纲化及合成方法可供选择,二者的组合更为灵活多变,可适用于不同数据类型,满足不同应用目的的需要[1]。
功效函数法无量纲化的过程中,可以调整样本分布形态,归纳起来,相关文献论及学理和方法两个层面的作用:从学理上说,功效函数的选择要反映出指标值与事物发展水平间的对应关系,其中又有主客观两方面含义,主观上要符合研究目的,体现评价的导向,客观上则应能反映高低水平区域发展的困难程度不同所带来的变动不均衡[1-2];方法层面,则要满足统计分析对数据的要求,对单个指标来说,指的是在样本数据分布偏度较大时校正分布,对不同指标来说,样本数据分布差异大时通过调整使分布趋同[3]。以上内容可概括为有效性、真实性以及稳健性三原则。
现有文献多认为非线性功效函数应具有凸性,即函数的二阶导数大于零[4]。对此有代表性的论述是:“一些经济指标达到一定数值后,再改善往往很难;而当指标值较差时,要改善相对来说比较容易。这就是说当指标数值处在不同水平时,要作进一步的等量改善,企业在经营管理上所作的努力是不一样的”[5]。这种说法在某些情况下成立,比如预期寿命、覆盖率或空气污染指数(负向指标),这类指标满意值受到比较强的限制,分别为生理限制、100%上限,或负向指标的下限0,因而在低水平增长快、高水平时增长同样数量难度变大,呈现出“天花板效应”;而从研究目的来说,这与分析宏观经济指标或者个体效益型指标时,横断面研究择优以及纵向研究鼓励优先发展的取向有关。
但在现实中,观测值集中在低水平的情况并不少见(即正向指标的样本分布右偏,本研究仅以正向指标为例,负向指标的分析和处理类似):强者恒强,高低水平之间差距逐渐拉大,使截面研究中指标取值集中在低水平,而纵向研究中从低水平发展往往更为困难,即表现出“粘地板效应”;在边际效用递减规律作用下,相比从低水平增长,高水平增加相同数量所反映的实际差异逐步减小;另外,社科领域研究更关注社会公平,也要求功效函数能甄别低水平的弱势群体。对这类数据如果用凸函数处理,首先,会使集中区域的功效得分进一步压缩,使大部分评价单位在该指标上的功效得分过小,降低了区分度;再者在原本分散的区域内评价值会更为分散,使极端值对分布的影响变大;此外,还要考虑到不同指标合成时,异常高分的单项指标值会“一白遮百丑”,从而掩盖其他指标的不足,而实际上不同指标的替代性并不会很高。这些问题会使单项指标值和总评价值无法反映评价对象的真实水平,从而有损于评价的真实性、有效性和稳健性。因此,应根据实际情况判断选用凹性或凸性的功效函数。

表1 凸性与凹性功效函数适用特征对比表
凹、凸性功效函数适用特征的归纳见表1,可以看出,选择凹性还是凸性的功效函数,不能一概而论,需要考虑的问题包括:研究目的、分布或发展中的不平衡性、边际效用变化规律以及样本分布偏度。
然而,现有非线性功效函数多为凸函数,不能直接用于需要凹函数处理的情况,通常需要与对数预处理结合使用。但对数处理亦有其局限:一是原始数据中可能会取零或负值,由此产生得分缺失的问题;二是当指标为分类变量时,会压缩值域范围,且处理后的变量失去了实际含义。为解决这一问题,本研究从凹凸性变换的适用性入手,讨论单项指标无量纲化方法的选择,并尝试使用偏度、区分度和P-P图等作为判断标准,系统地对比和评价常见功效函数无量纲化方法对指标原始数据分布形态的调整作用,以此为基础,提出一种凹性的指数型功效函数,在处理右偏样本时更为稳健、有效。
本研究使用的示例数据来自2011-2012年“中国老年健康影响因素跟踪调查”(CLHLS),选取独居或与家人同住的7 176名老人作为分析对象,选用的分析变量是“老年人去年家庭总收入”。选择示例数据的主要考虑是:其一,收入是社会经济调查数据集中常见且重要的变量;其二,作为连续型变量对各种功效变换特别是取对数等方法适用性强,便于进行多种方法的演示和比较。样本的描述统计见表2“原始数据”行。数据处理使用SPSS 19.0统计分析软件。
二、功效得分分布形态的标准初探
本研究将使用偏度、区分度和P-P图三种标准来评判单项指标功效得分分布形态特征,在应用中,三种标准各有侧重。
(一)偏度
偏度反映功效得分分布的对称性。参照表1的适用性分析,为避免评价值过度集中在高水平或者低水平,因此偏度应比较接近零。另外为指标合成的需要,各项指标功效得分的偏度应较为接近。
(二)区分度
区分度又叫辨识度或粒度,是指统计指标在区分各评价单位某方面特征时的能力与效果,反映了功效得分分布的分散程度。大部分评价值差异很小会导致评价效果不佳,因此,一般认为评价指标的区分度应尽量高,以供决策取舍[1,6]。
本研究计算区分度的方法是经典测量理论中的极端分组法,将分数排序,而后用以下公式计算区分度(D):
从公式可以看出,这种区分度计算方法关注两端平均水平是否拉开差距,来反映功效得分的整体间距,该方法在应用中有效且稳定[7]353-360。目前区分度及其计算方法在统计学研究中不多见,俞立平等使用了类似的算法,将高低水平分组比例取20%,而在心理、教育、考试测量领域应用较为充分[6-9]。
(三)P-P图
P-P图是根据变量的累积比例与指定分布的累积比例之间的关系所绘制的图形,用来检验数据是否符合指定的分布。本研究使用的是均匀分布P-P图,因为均匀分布累积概率线性增加,将指标得分累积概率与均匀分布相比,清晰直观,有助于理解分布形态的特征。而使用直方图法,同一变量在不同绘图尺度下形态有差异,并且直方图通常呈锯齿状,也会对判断有所干扰。
根据以上偏度、区分度和P-P图的含义、所反映的分布特征和判断标准,应用中可以互相参照,把握分布形态的特点。本研究将使用这三种标准对常见功效函数的凹凸性及其对样本分布形态的调整效果进行比较分析,并提出一种新的凹性指数功效函数。
三、常见功效函数对指标分布形态的调整作用
功效函数法按照函数形式可分为线性和非线性两大类,而非线性功效函数法常用的是对数和指数功效函数两种。将样本原始值转换成功效得分的过程中,进行线性处理不改变分布的形态,而进行非线性变换则不可避免会改变分布形态特征。
本研究主要目的是比较不同功效函数对指标分布形态的调整效果,因篇幅所限,不再重写函数的一般形式,为了便于对比,表2列示的均为参数已确定的形式。参数决定的方法是:将均值无量纲化之后的得分(如果计算中涉及的话)定于50,功效得分范围定为[0,100]*两处例外分别是:彭非等的方法无法将下限定为0,只能定不允许值的得分为50;王学全法只能固定满意值和均值得分,不允许值的功效得分无法确定。。
满意值、不容许值和均值的确定可以使用理想化值,也可以使用样本特征值,如满意值可以使用理想化的值(如最优值、历史最佳水平或正向指标取值的理论上限),或使用样本中正向指标的最大值或者逆向指标的最小值,表示为x1。不容许值和均值也可类似确定,分别表示为x0和xm。值得一提的是,这两种确定思路下常见功效函数对正、逆向指标表达式一致,苏为华也针对王学全指数型功效函数指出了这一点。本研究为演示和比较需要,均使用样本统计量。

表2 常见功效函数得分参数一览表
注:数据来源于2011-2012年“中国老年健康影响因素跟踪调查”(CLHLS)独居或与家人同住的7 176名老人 “老年人去年家庭总收入”。
(一)线性功效函数
线性功效函数对指标的处理相当于去掉截距并将尺度参数标准化到100。其二阶导数为零,因此功效得分与样本相比,只是均值和标准差相应缩减,即集中趋势和离中趋势有所改变,而分布形态与原始数据相同,偏度为1.34,区分度为0.61(所有功效函数的参数均汇总于表2,下同)。
(二)对数型功效函数
对数功效函数可以看作先进行对数预处理,再使用处理值计算线性功效得分,所以对数功效函数也被称为广义线性功效函数。如联合国开发计划署(UNDP)使用线性功效函数计算人类发展指数(HDI)的三个指标,但对于国民收入指标,为了体现每增加一美元收入提升人类发展水平的边际效用递减,先作自然对数处理,而后使用线性无量纲化方法得到国民收入分指数[9]。对数处理有很多好的性质,如:严格单调,具有较强的凹性,从而能改变分布形态,能缩减值域区间,因此对增长较快、跨度大的指标处理效果好;在纵向研究时,对数值的差分即为增长率的对数,具有实际意义;对于相对指标来说,对数处理后只差一个负号,使功效函数可以实现对指标正逆形式同一化[10]。
然而并非所有变量都适合对数预处理,比如取值包括零(如本例)或者负值的变量,对数处理会产生缺失值,本例中由此造成96个评价值缺失;对分类变量评价时,作对数处理会进一步压缩取值范围,并且取对数后的值无实际意义。以本例为代表的社会调查数据中含零变量和分类变量很多,对数处理的使用受到限制。
实际应用中,很多经济管理方面的成本/效益类指标通常为连续型变量并且不取零值,适宜根据需要进行对数预处理,并与凸性功效函数结合使用,这也是凸性功效函数被广泛接受的原因之一。因此,本研究也列出了对数预处理与不同功效函数的组合及结果。
本例计算对数功效函数时与苏为华所用公式相比有两个变动[10]:一是使用对数处理值的最小值(lnx)0替代原公式中最小值的对数lnx0,否则样本最小值为0的情况下(本例即是如此),最小值对数会缺失,使公式不可计算;二是为便于与其他方法比较,将值域从[60, 100]变为(0, 100]。
对数功效函数的凹性来自于使用对数函数进行预处理,而线性变换不影响偏度、区分度等分布形态统计量。本例对数功效函数得到的功效得分偏度为-0.65,分布变为左偏,因此均值由线性功效函数的26.65上升到79.71,而标准差减小到线性功效函数的一半左右,得分在高分处密集,使区分度大幅度降低到0.33。
(三)指数型功效函数
王学全提出了一种指数型功效函数,认为均值包括分布的信息,在指数部分分子和分母都使用均值(也可以是理想化的合格水平)作为调整截距的参数。彭非等对王学全的方法进行了改进,将指数部分分子和分母的截距参数由均值变为不容许值,认为这样得到的功效得分对样本分布依赖小,比较稳健。但两种函数均为凸性,因此在样本分布右偏的情况下,处理后的功效得分偏度进一步增加,且区分度也随之降低。示例数据由王学全法计算的功效得分偏度1.84,区分度0.53;而彭非等法变换后偏度1.70,区分度为0.55。
需注意的是,王学全法同大多数函数一样,表达式只有两个参数,因此在限定满意值功效得分为100、均值为50之后,对不容许值的得分就无法限定了,本例中功效得分的最低值高达38.88,这显示,在样本中低于平均值的评价单位数量更多、原取值差别不大,即在分布右偏的情况下,经过这种凸函数处理后,大部分评价单位的功效得分被进一步压缩在[38.88, 50]一个很小的范围内。
另外,两种指数型功效函数法相比,因为王学全法包含样本均值作为参数,而均值事实上含有样本分布的信息,在分布有偏的情况下,使用均值的变换对偏度调整作用更大。使用均值作为参数的调整效果在使用对数处理值功效变换时更为明显。对数处理之后分布变为左偏,此时再使用两种凸性的指数功效函数处理都能够减小偏度和增加区分度。彭非等法将对数处理后的偏度由对数函数的-0.65轻微调整到-0.43,而区分度也略提高,从0.33提高到0.40;而王学全法将偏度调整到略右偏的0.24,区分度则增至0.58。
为确定对数处理与这两种指数型功效函数复合变换的凹凸性,求导得到对数处理、王学全法复合变换的二阶导数为:
e(lnx-(lnx)M)/((lnx)1-(lnx)M)ln2
其符号取决于ln2-(lnx)1+(lnx)M项的正负,即满意值与均值的比值,倍数大于2则复合函数为凹函数,小于2则为凸函数,本例中取值为负,复合函数为凹性。而对数处理、彭非等法复合变换的二阶导数为:
e(lnx-(lnx)0)/((lnx)1-(lnx)0)ln2
其符号取决于ln2-(lnx)1+(lnx)0项的符号,即满意值与不容许值的比值,倍数大于2则复合函数为凹性,小于2则为凸性,本例中取值为负,复合变换为凹函数。指标值对数变换下两种指数功效函数的凹凸性取决于满意值与均值或者不容许值比值是否大于2,而非指标原分布的形态特征,在本例中收入差距较大,因此两种方法的二阶导数都为负值,但对于取值范围不太大或者均值或不容许值绝对数值偏小的变量,二阶导数取正的可能性增加,而对负向指标来说,满意值小于均值或不容许值,二阶导数必为正数,复合函数为凸性。总之,这两种变换的凹凸性与样本分布偏度无直接关联,不便于应用者按需使用。
常见功效函数的应用分析也表明,标准差或标准差与均值比值这些分布离中趋势的参数,不能很好地刻画分布形态特征。如表2中标准差与均值比值最高的是原始数据和线性功效函数得分,但事实上二者从偏度、区分度和均匀分布P-P图上看都不甚理想。
四、一种改进的凹性指数型功效函数
从示例数据处理结果反映出,在调整右偏数据分布形态时,常见功效函数及其对数复合函数,处理效果不理想,适用性也不强。为此,本研究试图构造一种新型的凹性功效函数。
(一)构造思想
在文献和分析的基础上,新函数构造思想主要来自以下三个方面:首先,通过文献研究,确立函数构造的基本原则,即功效函数对指标分布的调整,应具备有效性、真实性及稳健性。其次,函数构造的目的,是满足统计实践中对凹性功效函数的需求。针对表1归纳的需要凹性功效函数处理的应用情境,本研究构造的函数应为凹性,即二阶导数恒为负,且与已有函数不同,构造函数的凹性不依赖于对数预处理,以提高对不同类型变量的适用性。再次,本研究提出的判断指标分布形态特征的三个标准,即偏度、区分度和均匀分布P-P图,是判断所构造函数调整效果的依据。
在应用常见功效函数的过程中,本研究发现效果最好的是与对数预处理结合使用的王学全指数型功效函数,但其存在几点不足,包括凹凸性不确定,使用对数预处理适用性受限,以及只有两个待定参数,自由度较低,从而只能确定均值到满意值的分布范围,无法将不满意值到均值之间的得分有效区分。针对这些不足,本研究考虑增加参数个数,以指数变换为主体,并确保函数为凹性,对王学全法进行改进,然后在分析和应用中论述函数的特点。
(二)函数形式
根据上述函数构造思想,通过对王学全指数型功效函数的改进,本研究提出一种凹性的指数型功效函数,形式为:d=a-be(x-xm)/(x0-xm)lnc。其中d为单项评价值,x0为不容许值,xm为均值,a、b、c是三个待定参数。
实际运用时,如果将不容许值的得分定为0,均值的得分定为50,满意值的得分定为100,代入功效函数表达式得到,A=100,B=50,C=ln2,应用的公式形式为:d=100-50e(x-xm)/(x0-xm)ln2。
(三)函数特点
该函数具有单调性,对正向指标来说一阶导数大于零,而逆向指标一阶导小于零,即正向指标单调递增,逆向指标单调递减。此外,相比目前常见功效函数方法,该指数功效函数在调整分布形态方面的特点有:其一,具有凹性,二阶导数小于零。在样本分布右偏而边际效用递减的情况下,使低水平增长时边际得分增加更多,可体现变量原值代表的真正差异以及平衡发展的思想,并且同使用对数变换的凹性处理相比,该功效函数适用性广,二阶导数恒为负从而凹凸性确定,且只进行一次指数运算,能够节省计算。其二,有三个待定参数,自由度高,使功效得分在值域中分布均匀。其三,函数形式中使用了样本的数值平均xm,使功效得分的分布与样本分布相关,可以随样本原有的分布特点改变分布形态调整的力度。
以上三点都能够提高该函数功效得分区分度,同时也避免了极端值的影响,使处理结果更为稳健。
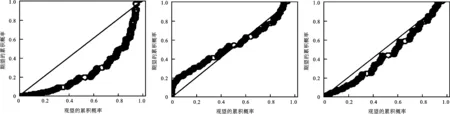
图1 原始数据(左)、对数王学全法(中)和本研究功效函数(右)的均匀分布P-P图
(四)调整效果
从对示例数据分布调整的结果来看,经过本研究构造的凹性指数型功效函数处理,功效得分偏度为0.32,接近于0;而区分度达到0.76,是所有方法中最高的;调整分布特征的效果可以由均匀分布P-P图直观看出,图1列出了原始数据(图1左),和偏度、区分度较好的对数王学全法(图1中)以及本研究功效函数(图1右)三种功效得分的P-P图。与均匀分布相比,原始数据在低水平集中度高;对数处理后的王学全法功效得分则是在中间水平和中高水平集中度较高,低水平分布密度较低;而本研究功效函数变换后仍然保持了原始分布在低水平集中的特征,只是集中度大幅降低,从而降低了偏度,并且由于在高水平和低水平分布均匀,区分度高于对数王学全法。
因此,在需要凹性功效函数处理时,这一改进的指数型功效函数评价法具有真实有效、适用性广、结果稳健的特点,便于根据实际需要应用。
五、总结与讨论
以本研究所使用示例数据为代表,针对微观单位、样本分布右偏、包含分类型变量、取值含有零值的调查数据集,随着大型社会调查的开展而越来越多见,为社会经济领域定量研究提供了坚实的数量基础。根据这类数据集的特点,评价现有功效函数的优缺点,构建新型的功效函数方法,使功效函数综合评价这一有力工具获得更广泛的应用,成为本研究的现实背景。
总结起来,本研究的主要工作是:首先,通过梳理文献,对凹凸性功效函数适用性进行了归纳,指出凹性函数在应用中确有其必要性。其次,提出以偏度、区分度、P-P图三种参考标准评价功效得分的分布形态,对它们反映出的特征和具体应用方式进行了介绍,以此为基础,对比分析了常见的功效函数方法。最后,通过改进现有的功效函数方法,提出一种新的凹性指数型功效函数,对右偏样本评价效果好,相比使用对数预处理的功效函数更具有适用性。
然而在具体应用中,需要注意以下几点。首先,不一定以偏度接近零、区分度高、P-P图吻合为绝对标准,应兼顾如实反映出实际的差距、功效得分分布的形态和统计性质良好等不同应用需求,也就是说,在评价的有效性和真实性两个方面,研究者需要做出自己的判断与取舍。再者,现有的功效函数均使用了极值作为参数,异常值的存在会使功效得分集中在高分(存在极端低值)或者低分区域(存在极端高值),评价结果差距不明显,降低区分度[11]。在这种情况下无法仅靠功效函数的选择进行调整,应首先考虑采用一定方法对异常值进行预处理。
此外,本研究讨论的是单项指标取值分布的调整,而在不同指标之间,可以对不同分布特征的样本数据选择不同的无量纲化方法,以P-P图相近为参考调整分布形态,在提高可综合性的同时,也有助于提高综合评价结果的效度和稳健性。
参考文献:
[1]苏为华.多指标综合评价理论与方法问题研究[D].厦门:厦门大学博士论文,2002.
[2]王晓军.多指标综合评价中指标无量纲化方法的探讨[J].人口研究.1993(4).
[3]胡永宏. 对统计综合评价中几个问题的认识与探讨[J].统计研究,2012(1).
[4]彭非,袁卫,惠争勤. 对综合评价方法中指数功效函数的一种改进探讨[J]. 统计研究,2007(12).
[5]王学全. 多指标综合评分法中单项指标的非线性记分法[J]. 统计研究,1993(5).
[6]万玉成,严斌辉,王金德.基于属性数学模型的试卷质量综合评价方法[J].大学数学,2009(3).
[7]克罗克,阿尔吉纳. 经典和现代测验理论导论[M]. 上海: 华东师范大学出版社,2004.
[8]冯艳宾,马洪超.关于经典测量理论和项目反应理论中难度和区分度的探讨[J].中国考试,2012(4).
[9]UNDP联合国开发计划署. Human Development Report Technical Notes 2014[R/OL]. 2014[2015-12-19].http://hdr.undp.org/sites/default/files/hdr14_technical_notes.pdf.
[10]苏为华.对数型功效系数法初探[J].统计研究,1993(3).
[11]王青华,向蓉美,杨作廪. 几种常规综合评价方法的比较[J]. 统计与信息论坛,2003(2).
(责任编辑:张治国)
收稿日期:2015-12-25;修复日期:2016-03-07
作者简介:封婷,女,山东青岛人,统计学博士,助理研究员,研究方向:人口统计。
中图分类号:C813∶F064.1
文献标志码:A
文章编号:1007-3116(2016)07-0016-06
A Concave Exponential Ef-fective Function in Comprehensive Evaluation
FENG Ting
(Institution of Population and Labor Economics, Chinese Academy of Social Sciences, Beijing 100028, China)
Abstract:The convex effective functions, which are the majority currently, often fail in dealing right-skewed socio-economic data. Based on the thorough discussion on the applicability of convex and concave effective functions, the necessity of concave function is established. By using skewness, discrimination index and P-P plot as standards, the adjust effects are compared among common effective functions. From that, a new type concave exponential effective function is raised, which lends itself to right-skewed data and is more applicable and convenient than the log-preprocessing convex effective functions.
Key words:effective function; non-dimension method; concavity or convexity transformation; distribution morphology
【统计理论与方法】
