
基于网络日志的用户查询推荐
2016-08-18 05:47王静山东科技大学信息科学与工程学院山东青岛266590
河南科技 2016年7期
王静>(山东科技大学 信息科学与工程学院,山东 青岛 266590)
基于网络日志的用户查询推荐
王静>
(山东科技大学信息科学与工程学院,山东青岛266590)
随着Internet的迅速发展,人们面对信息爆炸的现实。因此,需要根据用户的查询意图进行推荐。基于此,提出一种计算查询词相似度的方法,利用K-means对查询词进行聚类并计算聚类簇中心,当用户输入查询词后计算该查询词与每个聚类簇中心的相似度并降序排列,选取相似度最大的两个聚类簇对其进行查询推荐。
查询意图;K-means聚类;查询日志;查询推荐
Internet的迅速发展使得人们从未像现如今一样能够轻易获取数量如此庞大的信息,一方面数量丰富的信息极大地满足了人们对知识的渴望,另一方面海量涌现的信息使人们无法直接得到自己真正感兴趣的信息[1]。对于普通用户来说,Internet上的“信息迷航”和“信息过载”已经成为日益严重的问题。用户兴趣建模正是在这样的背景下产生的。
用户兴趣建模的关键是分析用户在互联网上访问数据的历史信息及行为信息,因为该信息隐藏了用户的目的与兴趣。根据用户兴趣模型,为其提供个性化、针对性的信息服务。而如何得到用户在互联网上访问数据的相关信息也是至关重要的。
1 相关工作
查询日志是大量用户长期使用搜索引擎产生的用户行为数据,在很多研究方向上都有着重要价值。为改善搜索引擎性能,可以在信息检索过程中进行查询扩展、查询推荐等;为加强自然语言理解,可以进行命名实体识别、文本分类等;也可以根据日志数据建立用户兴趣模型,进行个性化服务等。
近年来,许多研究工作开始使用查询日志中的clickthrough data来挖掘查询之间的语义相关关系。例如,段建勇等人[2]提取基于查询词的QueryRank算法对网络日志的用户进行兴趣建模,缺点是对网络日志的处理仍采用传统的文本处理的方法不具有针对性;Beeferman等人通过对query-URL二部图上使用凝聚聚类算法来发现相关查询;Wen等人同时考虑使用click-through data和查询文档的内容信息来确定相似查询,缺点是工作量比较大且不具有通用性。
2 查询日志
在当今的搜索引擎中,关于查询者和搜索引擎之间的交互关系会被记录下来,从而形成了用户查询日志。尽管搜索引擎各不相同,但完整的用户查询日志至少包含5个方面的信息:用户标识、该查询提交的时间、用户输入的查询词、该查询返回的结果以及用户的点击行为。本文使用搜狗实验室提供的用户查询日志,每条记录的内容如表1所示。

表1 查询日志的记录内容
3 查询词相似度
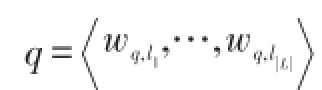

式(1)中,n(q,lj)表示针对查询词q点击lj的次数。
根据该向量形式,定义相似度函数,这里使用余弦相似度,如式(2)所示。

4 查询词推荐模型
制定基于相似度的相异度(准则函数值)计算公式,利用该公式将相似度较高的查询词归到某一个聚类簇中,相异度计算公式如式(3)所示。

式(3)中,sim(q,ci)是聚类簇ci中的任意一个查询词q与聚类簇中心ci的相似度。
每次聚类之后聚类簇中心的计算如式(4)所示。

式(4)中,nci是聚类簇ci中包含的query总个数。
当两次准则函数值的差值不超过0.01时,即达到我们的聚类结果,使用词频方法提取每个聚类簇的特征查询词,如式(5)所示。

式(5)中,nqi是查询词qi在聚类簇ci中出现的总次数,nci是聚类簇ci中所有查询词的总个数。
当用户输入查询词后,计算该查询词与每个聚类簇中心ci的相似度如式(6)所示。

根据相似度大小进行降序排列,选取排在最前面的两个聚类簇中的查询词,实现用户查询推荐。
5 结果与分析
由已有研究可知,在一段时间内用户的兴趣是比较稳定的,因此可以利用前面建好的查询词推荐模型对用户进行推荐。例如,当用户输入“数码科技”时,计算出与其相似度较高的两个聚类簇分别是“数码家电”和“科技信息”,推荐的序列对比如表2所示。

表2 关于“数码家电”和“科技信息”的查询推荐序列
为了测试该方法的准确性,从这150个聚类簇中随机选取30个,由3位专业人员对这30个聚类簇中排在前N(这里N取200)的查询词进行投票选取,计算其准确率和召回率,结果如表3所示。

表3 准确率和召回率
6 结语
由表3的结果可知,该方法提出的查询推荐模型是可行的,并且推荐效果良好。
本文通过对搜索引擎查询日志的结构进行分析,挖掘该结构下查询词之间的关系,根据该关系对查询词进行聚类并提取每个聚类簇的特征词。针对用户输入的查询词,利用本文的查询推荐模型对其进行推荐,更好地服务于用户。由于网络日志的数量庞大,所以在未来的工作中需要对聚类算法进行改进,提高聚类的效果和速度。
[1]吕新波,关毅.基于聚类的隐式用户兴趣建模[J].智能计算机与应用,2013(1):17-20.
[2]段建勇,魏晓亮,张梅,等.基于网络日志的用户兴趣模型构建[J].情报科学,2013(9):78-82.
User Query Recommendation Based on Web Log
Wang Jing
(College of Information Science and Engineering,Shandong University of Science and Technology,Shandong Qingdao 266590)
With the rapid development of Internet,people are facing the reality of information explosion. Therefore,we need to recommend according to the user's query intention.Based on this,a computation methods of query similarity was introduced,which used k-means to query clustering and calculate the clustering center,then calculated the similarity between query and each cluster center when the user input query and ranked in descending order,then selected the queries of the maximum similarity of two clusters to recommendation.
query intention;K-means cluster;query log;query recommendation
TP3
A
1003-5168(2016)04-0050-02
2016-03-23
王静(1991-),女,硕士,研究方向:人工智能。
猜你喜欢
华人时刊(2021年13期)2021-11-27
心声歌刊(2020年4期)2020-09-07
铁道通信信号(2019年6期)2019-10-08
思维与智慧·上半月(2018年9期)2018-09-22
小学生(看图说画)(2017年6期)2017-11-06
雷达学报(2017年6期)2017-03-26
互联网天地(2016年1期)2016-05-04
智能系统学报(2015年4期)2015-12-27
中国卫生(2015年12期)2015-11-10
新疆大学学报(自然科学版)(中英文)(2014年2期)2014-11-06
