
数据挖掘技术在水质自动监测站管理中的应用
2016-08-30 09:02章俊倪薇
治淮 2016年1期
章 俊 倪 薇
数据挖掘技术在水质自动监测站管理中的应用
章俊倪薇
水质自动监测站的水质数据质量和仪器状态、外界环境(水、电、天气等)、运维状态等息息相关,干扰因素很多,因此水质数据经常会有异常值产生,而且有些异常数据很难依靠人工判断,处理难度较大。近年来,由于大数据的迅速发展,使得数据挖掘技术逐渐成熟,各种挖掘算法被广泛运用于数据处理,并有许多成功应用的案例。本文尝试使用数据挖掘技术对新汴河团结闸水质自动监测站2014年1~6月的水质监测数据进行处理,剔除异常值,使有效数据能够均匀分布,从而提高数据质量和规范性,并通过人工监测数据进行验证,取得了好的效果。
一、数据处理方法的选择
数据挖掘有很多成熟的技术,但是在水质处理和预测计算方面运用的并不多。本文分析水质数据的特点,就单个水质参数而言,除非遇到突发性水污染事故,否则数据变化幅度不大,且都是正实数,不包含向量等复杂数据。目前水质自动监测站每天上传监测数据2~4条,频度不大。聚类分析法处理数据过程简单易懂,实用性较强,选择聚类分析法可以方便地解决数据处理问题,达到预期效果。
聚类分析是依据样本间关联的度量标准将其自动分成几个类,且使同一类中的样本相似,而属于不同类的样本相异的一组方法。一个聚类分析系统的输入是一组样本和一个度量两个样本间相似度(或相异度)的标准,聚类分析的输出是数据集的几个类(簇),这些类构成一个分区或分区结构。聚类分析的一个附加结果是对每个类的综合描述,这种结果对于进一步深入分析数据集的特征尤为重要。这样应用聚类分析法可以将水质数据中的离群数据即异常数据剔除掉,提高数据质量。
二、聚类分析法应用分析
聚类分析可以根据聚类中心点来进行数据筛选,一方面可以剔除孤立点,另一方面还可以剔除一些距离中心点过远的异常数据,不仅可以剔除异常数据,还可以使过滤后的数据具有良好的规范性。
本文选择的水质影响因子为高锰酸盐指数(CODmn)与氨氮(NH4),这两项都是影响水质的重要指标,具有很强的代表性。根据新汴河团结闸水质自动监测站从2014年1~6月的日监测数据,去除各种不完整数据后共有798组。按照月份分期,将每个月的数据分为3组(按旬划分),选取K-平均算法进行聚类分析,剔除样本数目过少的类。在计算中,如果每组的数据样本数少于该月样本总数的10%,剔除该类,并重新进行划分计算并不断重复此过程,直到最终划分的类中没有少于样本总数10%的类,确保没有异常样本点,从而使所获得的数据具有较好的规范性。
三、处理过程及结果分析
应用聚类分析法时采用SPSS(StatisticalPackagefortheSocial Science)软件,其是目前世界上最著名的数据分析软件。SPSS最突出的特点是操作界面友好,使用Windows的窗口方式即可展示各种管理和分析数据方法的功能,使用对话框就可展示出各种功能选择项,无需编程,只根据需要进行图形用户界面操作就可以实现数据的分析和处理。
在本文聚类分析研究中采用K-平均算法,其具体流程:(1)任意选择3个样本作为初始类的中心;(2)根据类中对象的平均值,将每个样本重新聚合到最相似的类;(3)更新类的平均值,即计算每个样本由样本的平均值,将其作为中心点;(4)重复(2)、(3)直到不再发生变化。
使用K-平均算法进行聚类,根据各个类的样本数目来剔除孤立点。第一次聚类结果见表1。
从表1中选取样本数少于该月样本总数10%的类进行剔除,得到新的数据并继续进行聚类和剔除异常样本,经过6次迭代最终得到不再有少于样本总数10%的类存在的表,其结果见表2。
每个月都有样本被剔除,因为水质变化非常复杂,受很多因素影响,本文在剔除异常数据时是以水域某一时段(某月)内的通常状况为标准,对于非正常状态对水域的影响因素考虑较少,为避免过多的删除数据,规定在某一时段内(某月)因机械或者人为等因素产生一些异常数据不应该大于该时段内所有监测数据的30%,若大于此上限,说明该月可能存在一些水质异常变化,比如突发水污染事故,则这些偏离常规的监测值也是水质真实状态的反映,不应被删除。经过6次迭代聚类,最终结果样本总数为583,剔除的样本数占原样本总数的27%,说明2014年上半年团结闸水质自动监测站的水质数据不是很稳定。

表1 K-平均算法聚类结果表
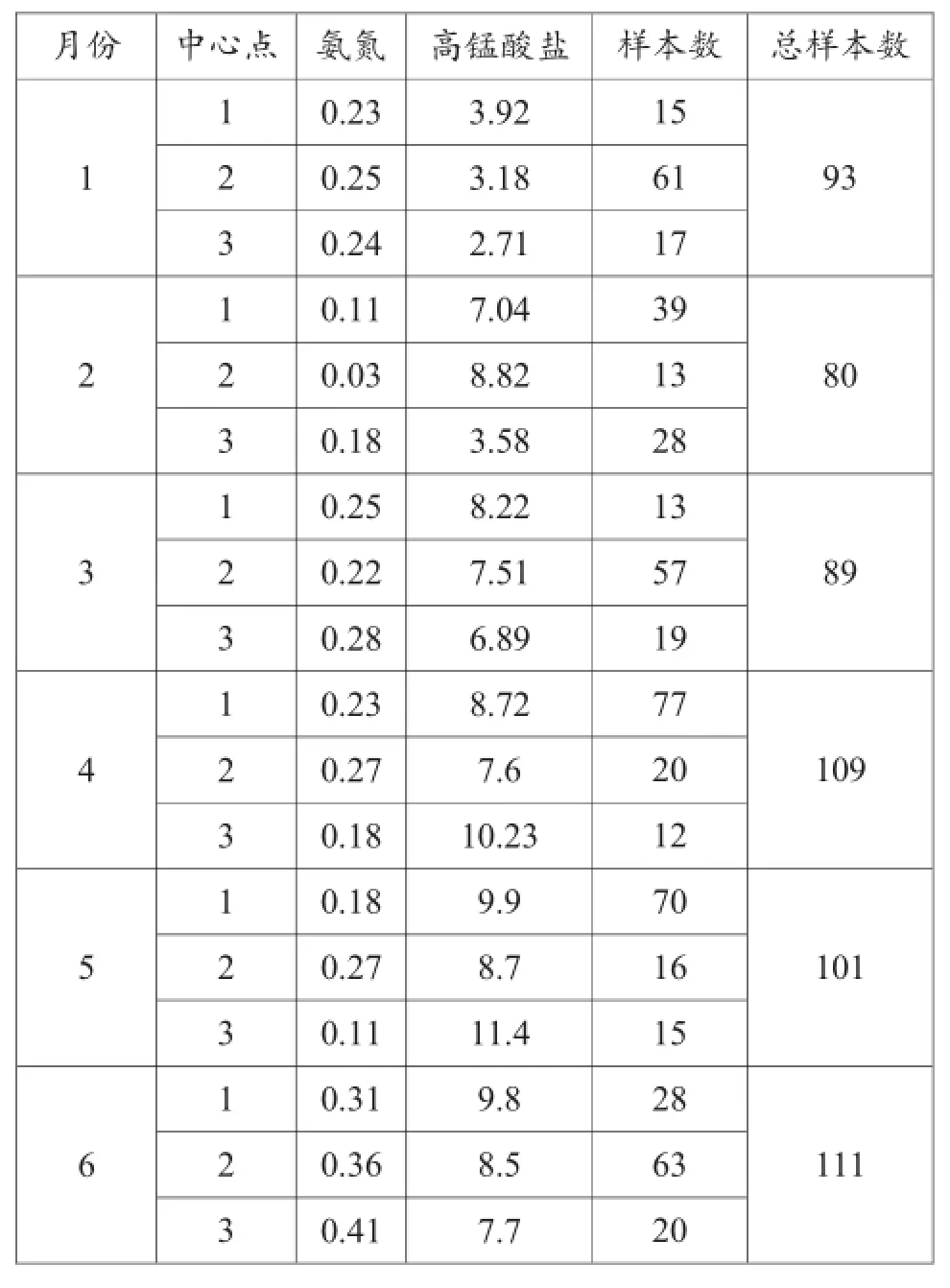
表2 K-平均算法聚类结果表
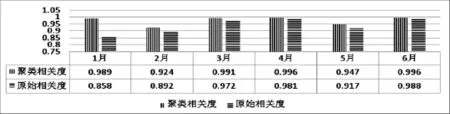
图1 高锰酸盐指数相关性图

图2 氨氮指数相关性图
四、数据结果验证
新汴河团结闸水质自动监测站位于皖苏两省省界,该站人工监测数据采用淮河流域水环境监测中心监测成果,数据具有很高的准确性和规范性。
因为每个月人工数据与自动监测站数据相比样本数过少,因此对其采取复制插值法,即每个人工数据复制一样的数量使其样本总数满足分析要求。相关性分析一样采用SPSS软件进行,并采用距离法,度量采用余弦来计算相似度矩阵,计算结果如图1和图2所示。
其中聚类相关性是指经过6次聚类后的数据与人工监测数据的相关度,原始相关度是指自动监测站原始监测数据与人工监测数据的相关度。
五、结论
从图1和图2中可以看出,无论是高锰酸盐指数因子还是氨氮因子,经过聚类后的数据与人工监测数据都表现出很高的相关度,尤其是数据变化幅度较大的高锰酸盐指数相关度提升更为明显。这说明了经过数据挖掘处理后的数据更能反映实际水质状况,比原始监测数据质量更好,规范性更强。综上所述,通过新汴河团结闸2014年1~6月的水质数据验证,说明数据挖掘技术能够较好的剔除水质自动监测站监测数据中的异常值,提高数据质量和规范性,更好地反映水质实际状况,为水资源保护工作提供技术支撑■
(作者单位:淮河流域水资源保护局233001南京市循环经济促进中心210008)
猜你喜欢
法律方法(2021年4期)2021-03-16
马克思主义哲学研究(2020年1期)2020-11-26
矿产勘查(2020年7期)2020-01-06
铁道通信信号(2019年11期)2019-05-21
资源节约与环保(2018年11期)2018-02-02
中国环境监察(2017年5期)2017-10-23
中国环境监察(2017年5期)2017-10-23
振动工程学报(2015年1期)2015-03-01
中国水利(2015年3期)2015-02-28
全球定位系统(2015年4期)2015-02-28
