
一种由粗至精的RGB-D室内场景语义分割方法
2016-09-21 03:37刘天亮冯希龙顾雁秋戴修斌罗杰波
东南大学学报(自然科学版) 2016年4期
刘天亮 冯希龙 顾雁秋 戴修斌 罗杰波
(1南京邮电大学江苏省图像处理与图像通信重点实验室, 南京 210003)(2罗彻斯特大学计算机科学系, 美国罗彻斯特 14627)
一种由粗至精的RGB-D室内场景语义分割方法
刘天亮1冯希龙1顾雁秋1戴修斌1罗杰波2
(1南京邮电大学江苏省图像处理与图像通信重点实验室, 南京 210003)(2罗彻斯特大学计算机科学系, 美国罗彻斯特 14627)
为了标注室内场景中可见物体,提出一种基于RGB-D数据由粗至精的室内场景语义分割方法.首先,利用分层显著度导引的简单线性迭代聚类过分割和鲁棒多模态区域特征,构建面向语义类别的超像素区域池,基于随机决策森林分类器判决各个超像素区域的语义类别,实现粗粒度区域级语义标签推断.然后,为了改善粗粒度级的语义标签,利用几何深度导引和内部反馈机制改进像素级稠密全连接条件随机场模型,以求精细粒度像素级语义标注.最后,在粗、细粒度语义标注之间引入全局递归式反馈,渐进式迭代更新室内场景的语义类别标签.2个公开的RGB-D室内场景数据集上的实验结果表明,与其他方法相比,所提出的语义分割方法无论在主观还是客观评估上,均具有较好的效果.
RGB-D室内场景;语义分割;SLIC过分割;稠密CRFs;递归式反馈
场景理解一直都是图像处理与计算视觉领域研究的热点.给室内场景中每个像素稠密地提供一个预定义的语义类别标签,能为移动机器导航、人机交互和虚拟现实等应用提供丰富的视觉感知线索.根据不同的标注基元量化级别,相应方法可大致分为区域级语义标注法和像素级语义标注法2类.这2类方法能分别标注粗、细粒度级别的语义标签;前者标注效率较高且整体视觉效果较好,而后者标注层次化细节较高但标注效率较低.
文献[1]基于高斯核线性组合成对项势能的快速稠密全连通CRFs概率图模型,提出了RGB图像像素级语义标注推断算法.由于深度传感器具有强大捕获场景结构能力,学者们倾向将场景几何深度融入语义标注.文献[2]构建核描述子特征实现区域级RGB-D场景标注.文献[3]提出了解析RGB-D室内场景中区域级的主要平面和物体,并推断物体支撑关系.文献[4]采用一种反馈式前向神经网络作为判别分类器,从RGB图像、深度图像以及经旋转处理后的RGB图像[5]中提取尺度不变特征转换SIFT特征描述[6].而文献[7]提出基于多尺度RGB图像和深度图像的卷积网络实现RGB-D场景语义标注.文献[8]给出了能快速获取普通场景较高质量超像素区域的SLIC过分割方法,但该方法面对结构混乱、目标交叠且光照条件复杂的室内场景,其过分割效果欠佳.
针对上述方法难于选择标注基元量化级别及未充分利用场景几何深度等问题,本文设计了一种基于RGB-D数据和全局递归式反馈由粗至精的室内场景语义标注框架.与其他方法相比,所提出的语义分割方法无论在主观上还是客观评估上,均具有较好的效果.
1 室内场景语义标注方案
本文提出的方案主要包括粗粒度区域级标签推断和细粒度像素级标签求精2部分,如图1所示;二者之间引入全局递归式反馈机制,能交替迭代更新不同粒度级别的语义标签,有利于语义标签的有机整合.粗粒度区域级标签推断由改进型区域过分割、区域特征提取和融合、超像素语义标签池构建以及随机决策森林分类预测组成;RGB-D训练数据集输入图1中的左侧训练流程,而图1中的右侧测试流程可以查询图像和将对应深度图像作为输入;利用改进型区域过分割方法获取超像素区域,有效提取输入样本集中鲁棒区域特征,并构建超像素语义标签池,基于随机决策森林分类预测区域标签;测试流程利用对已训练的分类器测试输入样本.细粒度像素级标签求精构建一种基于几何深度信息和内部递归式反馈扩展的像素级稠密CRFs概率图模型,优化求精即可得到细粒度的标注.
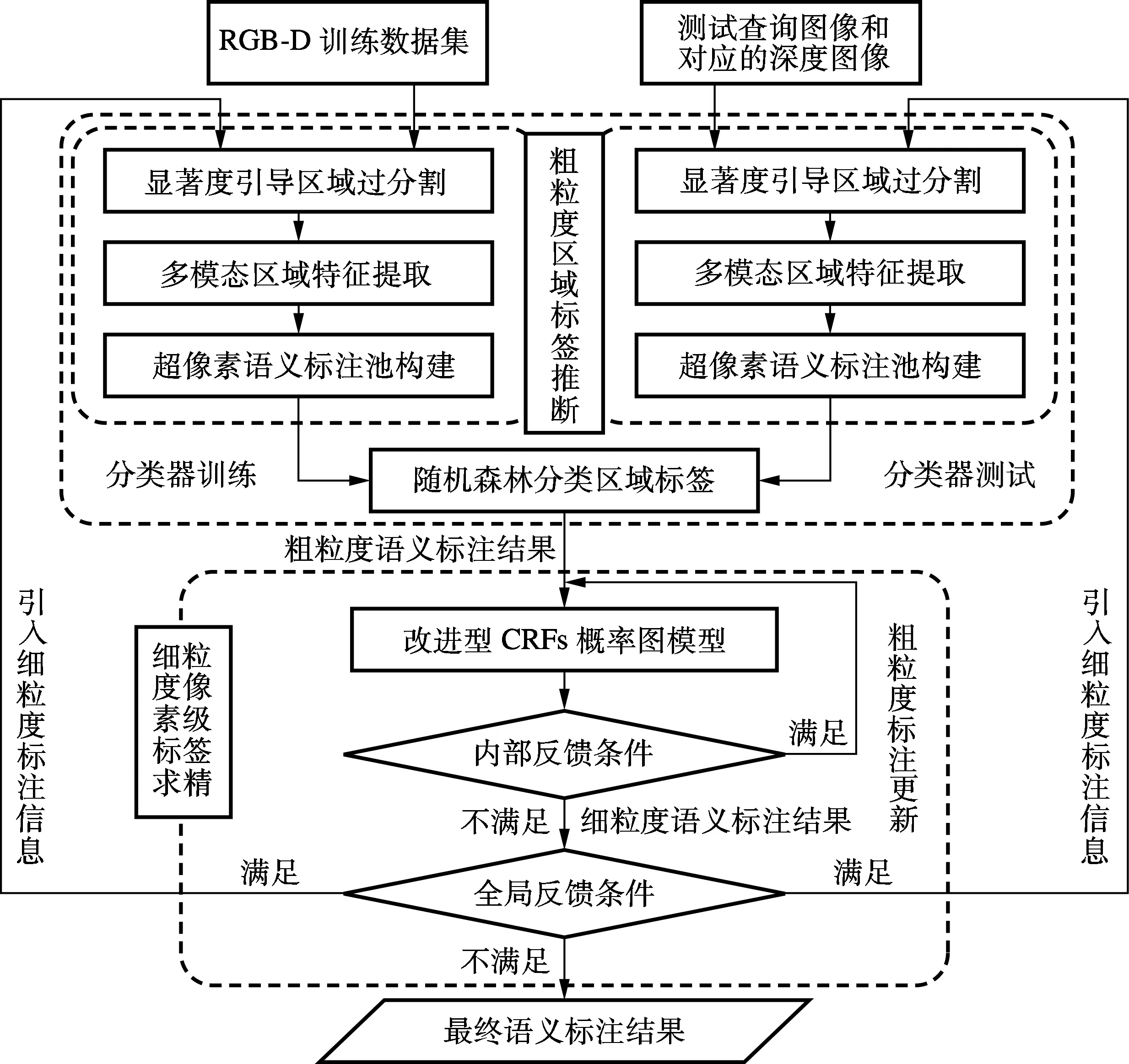
图1 室内场景语义分割流程图
2 粗粒度区域级语义标签推断
2.1显著度导引改进SLIC过分割
针对目前快速SLIC过分割法[8]处理杂乱室内场景难以得到较高边缘一致性的超像素问题,本文利用图像分层显著度导引简单线性迭代聚类,得到较紧凑的超像素区域.受文献[8-9]启发,本文在传统SLIC过分割法[8]的5维(3维RGB通道和2维位置通道)聚类空间基础上,引入额外3个多模态视觉感知通道(1维多尺度融合的图像分层显著度[9]、1维深度信息和1维语义标签图),将传统SLIC过分割法扩展增至8维,任意特征聚类中心w和t之间相似性测度为
(1)
dcds=[(Lw-Lt)2+(aw-at)2+(bw-bt)2+
(2)
(3)
(4)
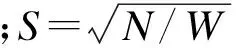
2.2多模态区域特征提取
为了实现粗粒度区域级语义标签推断,根据训练或测试流程需要,对RGB-D训练数据集或测试数据集中RGB图像和对应深度图D中即得的各个超像素区域,提取区域级鲁棒多模态特征描述.首先,根据预设摄像机内部参数、深度图D及点云库[10]计算对齐于RGB图像I各像素点的表面法向量n;接着,依次计算各个过分割超像素内的区域特征单元并归一化;然后,将其串联拼接成即得的超像素区域的多模态特征.其特征单元包括区域像素质心、色彩HSV分量均值与相应直方图、彩色RGB图像的梯度方向直方图(histograms of oriented gradients, HOG)、基于深度图像的HOG以及由深度图像衍生得到场景的表面法线向量图像的HOG等多模态视觉特征.
2.3超像素语义标签池构建
利用RGB-D输入数据合理构建超像素语义标签池,以训练或测试随机决策森林分类器.对训练数据的超像素集合中的各个超像素,根据RGB-D训练数据集中包含的基准标签信息和多模态特征向量,分别整合该所有超像素对应的各个条目,并采用映射准则将基准标注信息的类别标签映射至训练数据的超像素集,获取该各个超像素分别对应的类别标签,构成训练数据的超像素集对应的语义标签池.为保证正确映射至每个超像素的类别标签具有唯一性,经基准标注图像映射后,若某超像素区域包含多种既定的类别标签,将该超像素中像素数目比例最大的类别标签视为其判定该超像素的正确标签.测试用超像素语义标签池可以采用类似方法构建.
2.4随机森林分类区域标签
采用随机决策森林[11]分类判别即得的超像素区域的语义标签.随机森林F由K个二进制决策树Tk(k=1,2,…,K) 集成.每个决策树节点n通过二值判决即得场景区域的多模态特征来分类相应实例.F决策树训练步骤如下:① 随机多次自举重采样训练集;② 采用深度优先策略,将即得构建的多个训练样本集分别训练随机决策树,每个节点n根据二值决策函数选择合适的自举重采样的候选特征参数θ和阈值τ,以产生最大的信息增益,如此往复;③ 据此统计分类投票结果,以得票最多的语义分类作为F分类器的输出.
根据已训练的随机森林F,对每个超像素区域r,从决策树根节点遍历每个决策树Tk;根据二值决策准则,分叉每个树节点,直至到达叶节点l;用概率p(c|n)关联二值决策时所到达节点的类别标签c,c∈C,C为所有语义标签的集合,并平均所遍历的各决策树Tk,用以编码类别标签的经验后验概率;将F中最大后验分类概率对应的语义类别视为相应场景区域所预测的标签,即
(5)
3 细粒度像素级语义标签求精
3.1融合几何深度的稠密CRFs概率图模型

(6)
式中,Ψu(xi)为节点i对应像素ei出现类别xi的一元势能,即
(7)
(8)
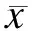
Ψp(xi,xj)=μ(xi,xj)K(fi,fj)
(9)
(10)
式中,xi和xj分别为节点i和j对应的可能类别标签;μ(xi,xj)为波茨模型标签兼容函数,μ(xi, xj)=1, xi≠xj;K(fi,fj)为高斯核的线性组合,fi和fj分别为节点i和j的相应特征向量;pi和pj分别为相应的坐标位置向量;Ii和Ij分别为相应的RGB彩色向量;di和dj分别为相应的深度值;ni和nj分别为节点i和j相应的表面法线向量;wa和ws分别为高斯外观核和平滑核的权值系数;θα, θβ, θγ和θδ为控制邻近两像素点同属于某一类的参数;θχ为平滑核控制系数,能控制标签的孤立区域大小.
3.2两层递归式标签反馈机制
为了改善语义标注精度和稳定性,细粒度像素级标注中先建立内部反馈机制;将细粒度语义标签作为额外通道,反馈至粗粒度区域级语义标签推断,以改善SLIC过分割,实现在模型输入/输出之间全局递归式标签反馈.首先,采用改进型概率图模型求精粗粒度语义标注,以更新细粒度像素级标注;然后,根据1.1节得到的过分割区域,将相应区域中即得的细粒度级别标注中类别标签反馈映射至其区域级语义标签超像素集;最后,根据该超像素集中的类别标签和过分割信息,更新区域结构粗粒度级别标注,将比较更新前后对应的超像素语义标签是否一致作为迭代结束的判断标准.鉴于仅通过一次求精步骤难以使所得标注达到最优,本文方法采用递归式策略保证在像素级语义标签优化时对粗标注的求精效果达到较高水平.
4 实验与分析
4.1主观评估
采用NYU Depth V2[3]与SUN3D[12]室内场景RGB-D数据集评测实验.NYU Depth V2数据集有1 449组RGB-D图像对(795组训练和654组测试)和相应的4种语义类别(Structure, Floor, Furniture和Props).SUN3D数据集有1 869组RGB-D图像对(1 121组训练和748组测试)和相应的15种语义类别(Bed, Cabinet, Wall, Ceiling, Floor, Sofa, Picture, Lamp, Curtain, TV, Door, Bathtub, Close stool, Washbasin和Props).图2和图3分别给出了本文方法在NYU Depth V2与SUN3D数据集上的实验结果.
比较图2(c)与(d)可知,细粒度像素级语义标签求精提升粗粒度语义标注的效果较为显著,目标边缘更接近场景的真实边缘;引入像素间丰富上下文能有效修正粗粒度语义标注结果中某些误标的标签.另外,图2(d)视觉标注效果明显优于图2(e),标签图边缘更清晰且正确率更高.文献[13]方法属于传统像素级标注方案,难以构建鲁棒、辨识力强的像素级特征描述;而本文方法充分融合场景图像中不同层次多模态信息,有利于得到正确率较高的像素级语义标签.
图3(d)、(e)与(c)相比,在视觉效果上均有较大提升,其原因是像素间引入稠密的上下文信息;而图3(e)也明显优于图3(d),原因在于引入了几何深度信息与内部反馈机制.图3(a)最左侧图中,因台灯光源过强,使得RGB图像中台灯灯罩周边区域被过度曝光,台灯的轮廓和纹理信息失效;而传统方法难以从图3(c)中获得台灯的边缘信息.而引入独立于光照条件的场景深度,能为场景语义标签上下文推断,带来更具鲁棒性、判别力强的上下文约束.

(a) RGB图像

(b) 基准标注图像

(c) 本方法最终标注

(d) 本方法粗粒度语义标注

(e)文献[13]方案的语义标注
4.2客观评估
表1给出NYU Depth V2数据集的实验结果,其评价指标有平均雅尔卡指数和像素标注准确率[3].平均雅尔卡指数为混淆矩阵中对角线(针对定义的语义类别,测试数据集中从属于某语义类别的像素获得正确语义类别标签的概率)的均值;像素标注准确率表示测试数据集中每个像素经标注后获得正确语义类别标签的概率.由表1可得,相比于其他方法[2-3,13],本文方法在总体性能上有一定提升,特别是Structure和Furniture 两种语义结构类别的标注.其原因是引入的有效深度信息能揭示场景中物体间的内在结构,能有效抑制噪声且保护图像细节.与文献[14]相比,本文方法整体性能上稍差,原因是本文方法不需要较多额外计算资源用于预先拟合场景的地心引力坐标系[14],并将其作为参考,因而使得Floor语义标注不够理想.
表2给出了SUN3D数据集的本文方法结果,评价指标为每个语义类别的像素级语义标注准确
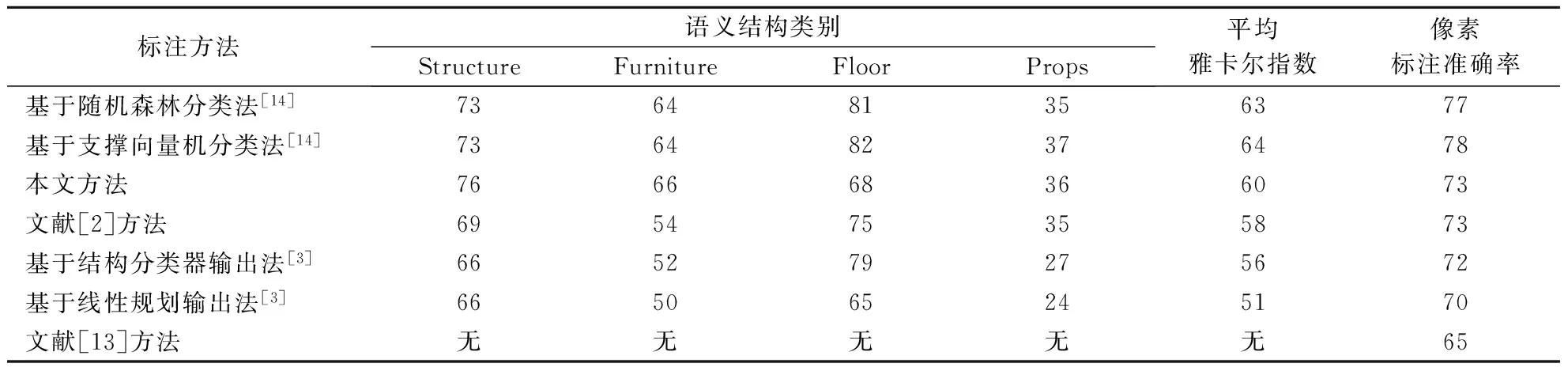
表1 NYU Depth V2数据集室内场景语义标注方法性能比较 %
注:“无”表示文献[13]中无此数据.
率.由表2可知,引入几何深度信息和内部递归式反馈能提升像素级标注准确率.内部递归式反馈使得标注信息不断迭代更新,最终标注结果趋于稳定且准确率得到提升.结合主观评估的图2可知,将有效可靠的几何深度信息引入改进概率图模型上下文推理语义标签时,能有效恢复被室内光照所隐藏的目标边缘,优化求精粗粒度标注.

(a) RGB图像

(b) 基准标注图像

(c) 粗粒度语义标注

(d) 未引入深度信息及内部递归式反馈的标注

(e) 最终标注
图3 SUN3D数据集的本文标注方法结果
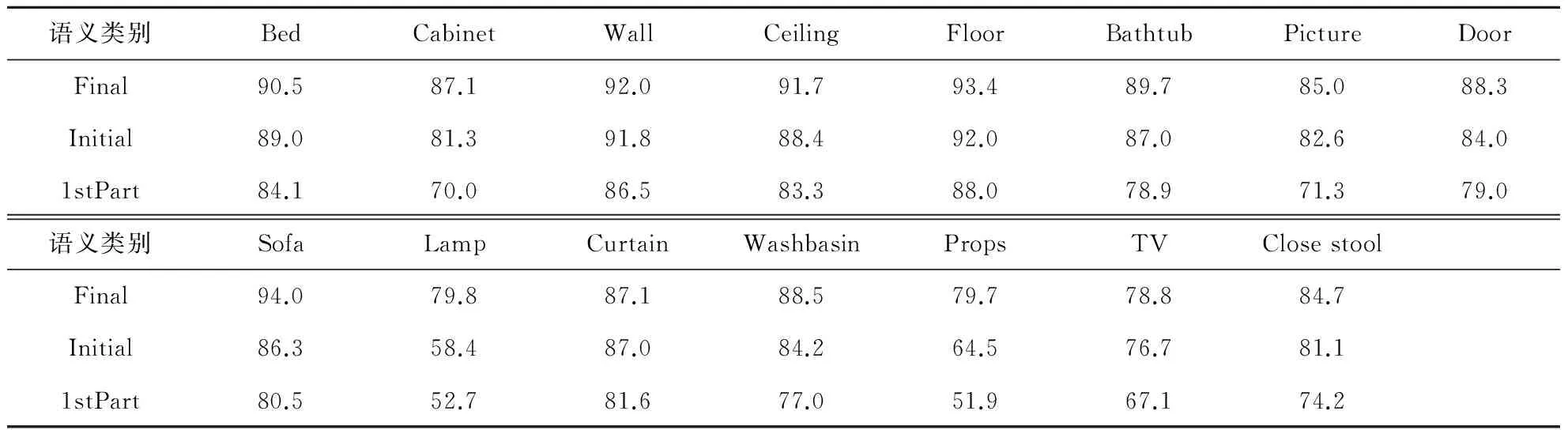
表2 SUN3D数据集本文方法标注语义准确率比较 %
注:Final表示包含深度信息及反馈机制结果;Initial表示不包含深度信息及反馈机制结果;1stPart表示粗粒度标注结果.
5 结语
本文提出一种基于RGB-D图像由粗至精的室内场景语义分割方法,包括粗粒度区域级语义标签推断与细粒度像素级语义标签求精.基于改进型SLIC过分割图像区域并提取其相应多模态区域特征,基于随机决策森林分类判决构建的超像素语义类别标签;利用场景几何深度和内部反馈机制改进像素级稠密CRFs概率图模型,引入全局递归式反馈渐进迭代更新室内场景的语义类别标签.相比于其他方法,本文方法能得到视觉表现力较强、标注准确率较高的语义标注结果.
References)
[1]Krhenbühl P, Koltun V. Efficient inference in fully connected CRFs with gaussian edge potentials [C]//25thAnnualConferenceonNeuralInformationProcessingSystems. Granada, Span, 2011:109-117.
[2]Ren X, Bo L, Fox D. RGB-(D) scene labeling: Features and algorithms [C]//IEEEConferenceonComputerVisionandPatternRecognition. Providence, RI, USA, 2012:2759-2766.
[3]Silberman N, Hoiem D, Kohli P, et al. Indoor segmentation and support inference from RGBD images [C]//12thEuropeanConferenceonComputerVision. Firenze, Italy, 2012:746-760. DOI:10.1007/978-3-642-33715-4-54.
[4]Silberman N, Fergus R. Indoor scene segmentation using a structured light sensor [C]//IEEEInternationalConferenceonComputerVisionWorkshops. Barcelona, Spain, 2011:601-608.
[5]Stasse O, Dupitier S, Yokoi K. 3D object recognition using spin-images for a humanoid stereoscopic vision system [C]//IEEE/RSJInternationalConferenceonIntelligentRobotsandSystems. Beijing, China, 2006:2955-2960. DOI:10.1109/iros.2006.282151.
[6]Lowe D G. Distinctive image features from scales-invariant keypoints [J].InternationalJournalofComputerVision, 2004, 60(2):91-110. DOI:10.1023/b:visi.0000029664.99615.94.
[7]Couprie C, Farabet C, Najman L, et al. Indoor semantic segmentation using depth information [C]//InternationalConferenceonLearningRepresentation. Scottsdale, AZ, USA, 2013:1-8.
[8]Achanta R, Shaji A, Smith K, et al. SLIC superpixels compared to state-of-the-art superpixel methods [J].IEEETransactionsonPatternAnalysisandMachineIntelligence, 2012, 34(11):2274-2282. DOI:10.1109/tpami.2012.120.
[9]Yan Q, Xu L, Shi J, et al. Hierarchical saliency detection [C]//IEEEConferenceonComputerVisionandPatternRecognition. Portland, OR, USA, 2013:1155-1162.
[10]Rusu R B, Cousins S. 3D is here: Point cloud library [C]//ProceedingsIEEEInternationalConferenceonRoboticsandAutomation. Shanghai, China, 2011:1-4.
[11]Stückler J, Waldvogel B, Schulz H, et al. Dense real-time mapping of object-class semantics from RGB-D video [J].JournalofReal-TimeImageProcessing, 2013, 10(4):599-609. DOI:10.1007/s11554-013-0379-5.
[12]Xiao J X, Owens A, Torralba A. SUN3D: A database of big spaces reconstructed using SfM and object labels [C]//14thIEEEInternationalConferenceonComputerVision. Sydney, Australia, 2013:1625-1632. DOI:10.1109/iccv.2013.458.
[13]Waldvogel B. Accelerating random forests on CPUs and GPUs for object-class image segmentation [D]. Bonn, German: Bonn University, 2013.
[14]Gupta S, Arbelaez P, Malik J. Perceptual organization and recognition of indoor scenes from RGB-D images [C]//IEEEConferenceonComputerVisionandPatternRecognition. Portland, Oregon, 2013:564-571. DOI:10.1109/cvpr.2013.79.
Coarse-to-Fine semantic parsing method for RGB-D indoor scenes
Liu Tianliang1Feng Xilong1Gu Yanqiu1Dai Xiubin1Luo Jiebo2
(1Jiangsu Provincial Key Laboratory of Image Processing and Image Communication,Nanjing University of Posts and Telecommunications, Nanjing 210003, China)(2Department of Computer Science, University of Rochester, Rochester 14627, USA)
A coarse-to-fine semantic segmentation method based on RGB-D information was proposed to label the visually meaningful components in indoor scenes. First, to complete coarse-grained region-level semantic label inference, the superpixel region pools for the semantic categories were constructed using hierarchical saliency-guided simple linear iterative clustering(SLIC) segmentation and robust multi-modal regional features, and the semantic category of each superpixel region can be judged based on random decision forest classifer. Then, to adjust coarse-grained semantic tag, a depth-guided pixel-wise fully-connected conditional random field model with an internal recursive feedback was presented to refine fine-grained pixel-level semantic label. Finally, a progressive global recursive feedback mechanism between coarse-grained and fine-grained semantic labels was introduced to iteratively update semantic tags of the predefined superpixel region in the given scenes. Experimental results show that the presented method can achieve comparable performance on the subjective and objective evaluations compared with other state-of-the-art methods on two public RGB-D indoor scene datasets.
RGB-D indoor scene; semantic parsing; simple linear iterative clustering (SLIC) segmentation; dense conditional random fields (CRFs); recursive feedback
10.3969/j.issn.1001-0505.2016.04.002
2015-12-07.作者简介: 刘天亮(1980—),男,博士,副教授,liutl@njupt.edu.cn.
国家自然科学基金资助项目(31200747,61001152,61071091,61071166,61172118)、江苏省自然科学基金资助项目(BK2010523,BK2012437)、南京邮电大学校级科研基金资助项目(NY210069,NY214037)、国家留学基金资助项目、教育部互联网应用创新开放平台示范基地(气象云平台及应用)资助项目(KJRP1407).
10.3969/j.issn.1001-0505.2016.04.002.
TP391
A
1001-0505(2016)04-0681-07
引用本文: 刘天亮,冯希龙,顾雁秋,等.一种由粗至精的RGB-D室内场景语义分割方法[J].东南大学学报(自然科学版),2016,46(4):681-687.
猜你喜欢
红外技术(2022年11期)2022-11-25
安阳工学院学报(2020年2期)2020-06-05
开放教育研究(2020年2期)2020-03-31
民族古籍研究(2018年1期)2018-05-21
电脑知识与技术(2017年26期)2017-11-20
信息安全研究(2016年3期)2016-12-01
中国社会历史评论(2016年2期)2016-06-27
现代语文(2016年21期)2016-05-25
长江学术(2016年4期)2016-03-11
新校长(2016年8期)2016-01-10
