
基于MPCP协议的任务最坏阻塞时间分析
2016-12-07 02:09曹永立杨茂林
电子科技大学学报 2016年6期
曹永立,杨茂林,廖 勇
(电子科技大学信息与软件工程学院 成都 610054)
基于MPCP协议的任务最坏阻塞时间分析
曹永立,杨茂林,廖勇
(电子科技大学信息与软件工程学院成都610054)
多处理器天花板协议(MPCP)是经典的基于挂起机制的实时锁协议,被广泛应用于分组固定优先级(P-FP)调度下的多核/多处理器实时系统中。然而针对P-FP+MPCP调度的任务最坏阻塞时间分析往往过于保守,影响系统的可调度性。因此,该文提出一种计算实时任务最坏阻塞时间的新方法。其中实时任务模拟为非临界区与临界区的交替序列。该方法通过分析任务多次请求某一共享资源所需的最短执行时间,以及任务在任意时间内累计执行临界区时间的上限,提高了已有分析方法的计算准确性。可调度性实验表明,该方法优于已有方法,提高了系统可调度性。
阻塞;多核;分组调度;实时锁协议;实时系统
在实时系统中,任务互斥访问关键数据结构、I/O设备等共享资源时,需要采用实时锁协议以避免死锁、阻塞链,同时减小优先级反转所造成的调度损失。在基于共享内存的多处理器实时系统中,文献[1]提出了一种单处理器优先级天花板协议(priority ceiling protocol,PCP)[2]的多处理器天花板协议(multiprocessor priority ceiling protocol,MPCP)。该协议适用于分组固定优先级(partitioned fixedpriority,P-FP)[3-4]调度下的多核/多处理器实时系统。
为了确保实时任务在其截止时限内完成,需要对任务的可调度性进行定量分析。在基于P-FP+ MPCP的调度策略下,可调度性分析包含任务最坏阻塞时间分析。文献[1]将任务阻塞分为本地局部资源阻塞、本地全局资源阻塞、远程低优先级任务阻塞、远程高优先级任务阻塞,以及间接阻塞,并通过计算各部分阻塞时间的累加和得到任务最坏阻塞时间。由于前两个阻塞部分并非相互独立,该方法存在重复计算问题。文献[5]将任务描述为临界区与非临界区相间的模型,采用响应时间分析法(response time analysis,RTA)[6-8]计算任务远程阻塞时间。该方法减小了文献[1]中的重复计算问题,但没有考虑相邻临界区间的间隔,因此所得的最坏阻塞时间仍较保守。文献[3]利用任务中相邻临界区间的最短时间间隔,提出了新的任务最坏时间分析方法。该方法在相邻临界区最短时间间隔较大时可排除文献[1]中的部分保守计算,相反则可能得到更坏的结果。文献[9]改进了文献[5]中的计算方法,提高了任务最坏阻塞响应时间计算的准确性。为了进一步提高任务阻塞时间分析的准确性,本文结合文献[5]的任务模型以及文献[9]的RTA分析框架,提出了分析任务多次请求同一共享资源所需的最短执行时间,以及任务在任意时间内累计执行临界区上限的方法,并基于该分析方法提出一种新的任务最坏阻塞时间分析方法。该方法进一步减小了分析所得的任务最坏阻塞时间,实验表明,该分析方法可提高实时任务集合的可调度性。
1 任务模型
2 任务请求共享资源时间分析
令Ni,k表示请求资源的次数,τi,k,x表示第x次访问的临界区,Si,k,x表示与τi,k,x对应的临界区编号。如图1所示,,在其第3个临界区中第2个请求,因此。从ri,l到第x次请求的最短时间间隔可由式(1)计算如下:
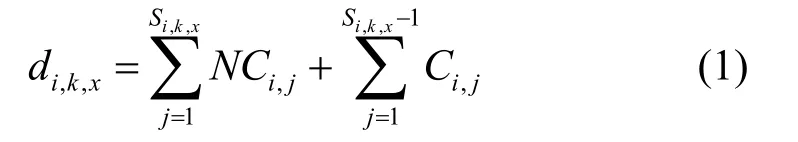
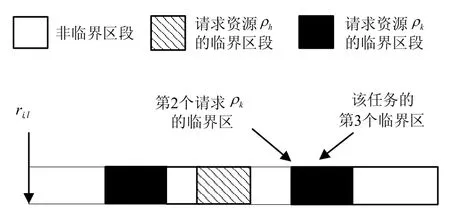
图1 任务模型示例,非临界区段与临界区段相互交错
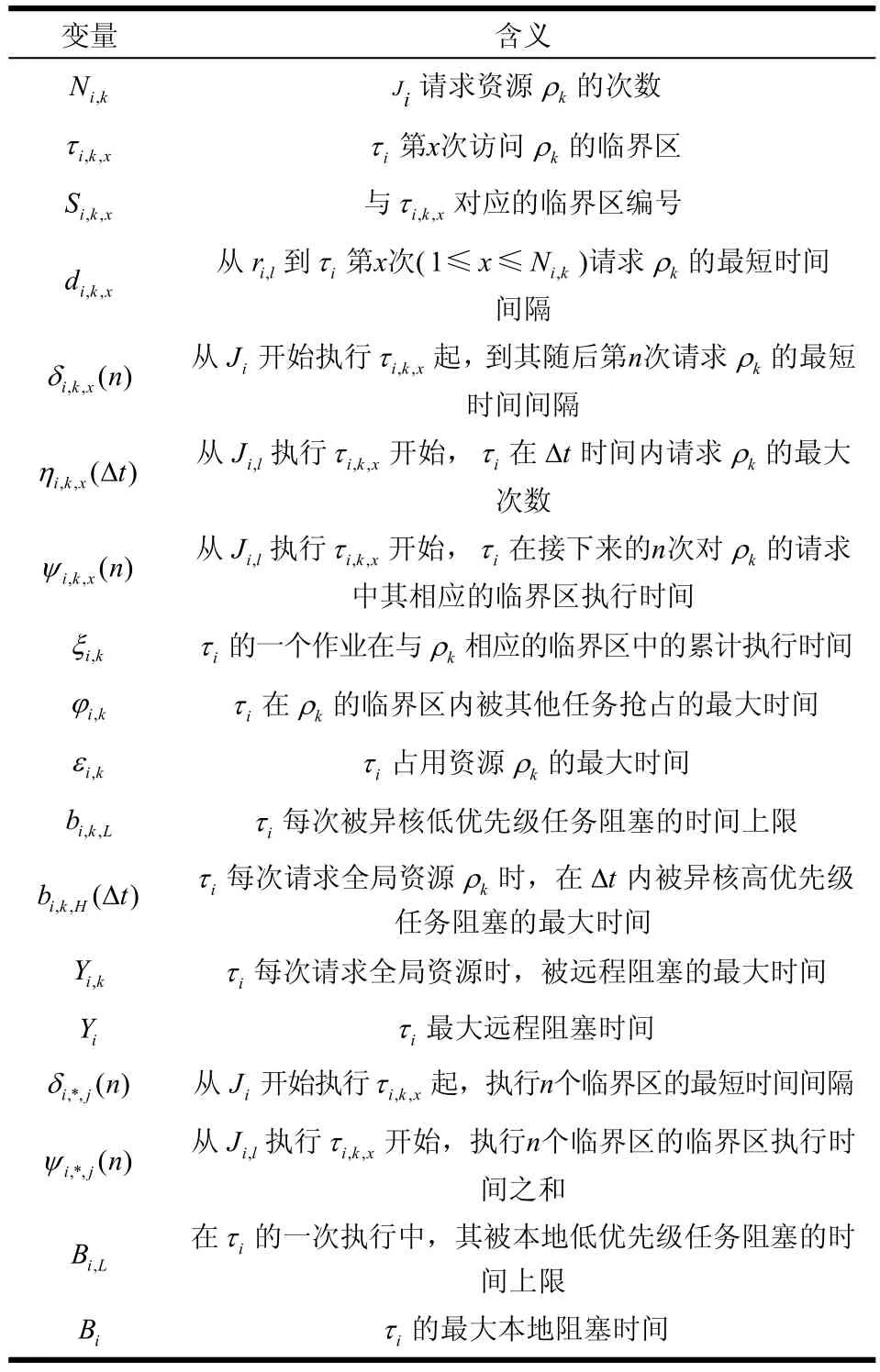
表1 本文变量列表

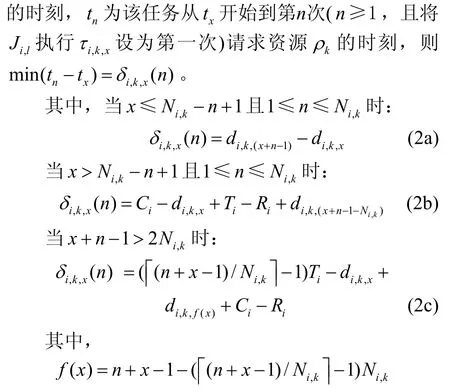
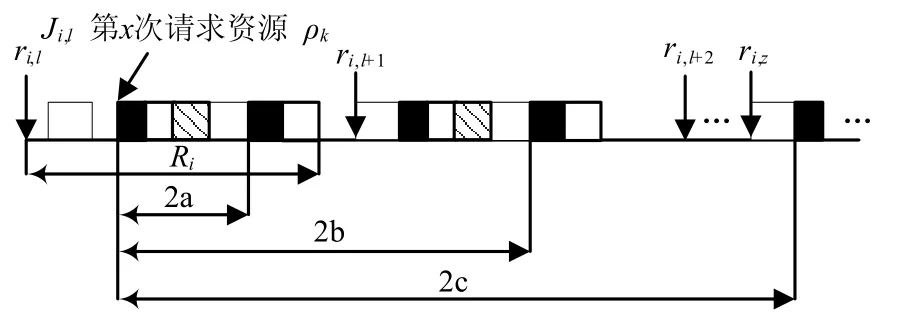
图2 从Ji,l第x次请求资源ρk开始,请求n次ρk所需时间示例


3 任务最坏阻塞时间分析
3.1远程阻塞时间
由于各全局资源的优先级天花板可能不同,任务在临界区内仍可能被抢占。如图3所示,由于,J2在ρk的临界区内被J1在t2时刻抢占,被J3在t3时刻抢占。根据文献[9],任务iτ在ρk的临界区内被其他任务抢占的最大时间为:
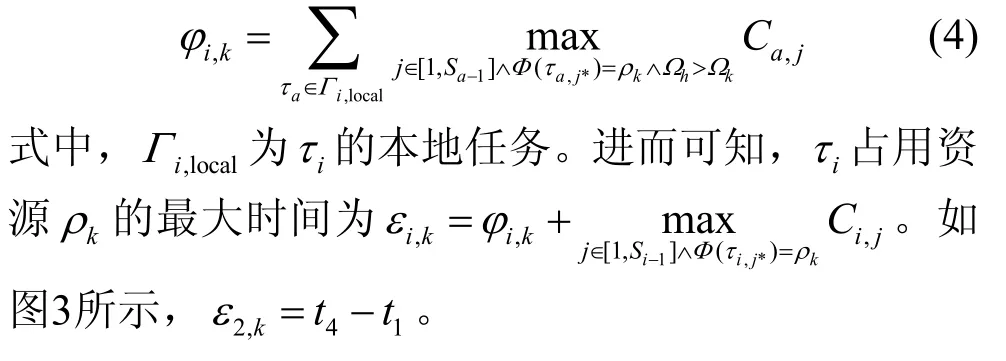
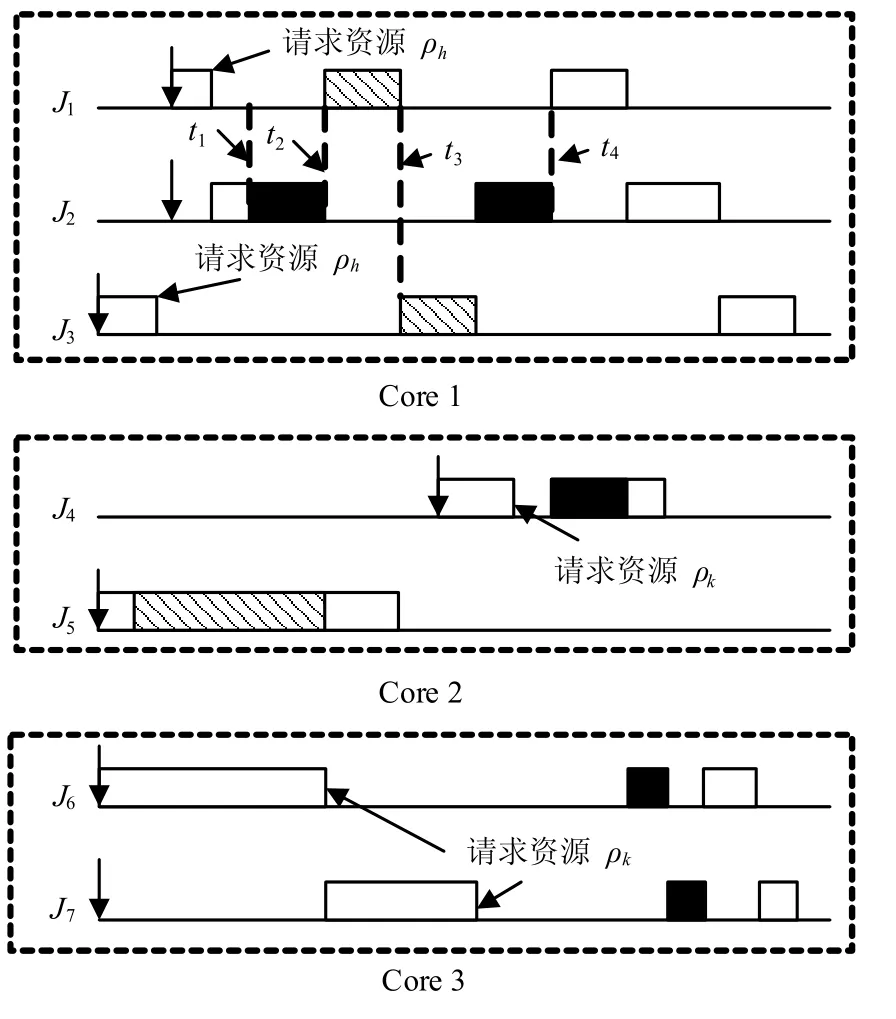
图3 远程阻塞示例
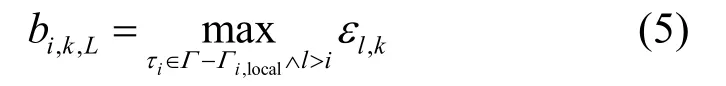
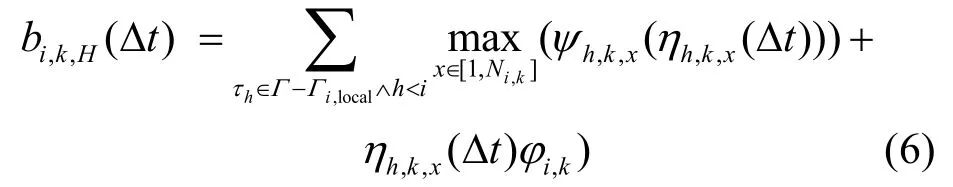
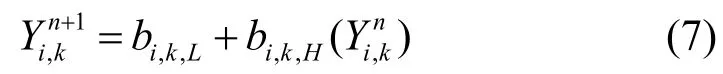
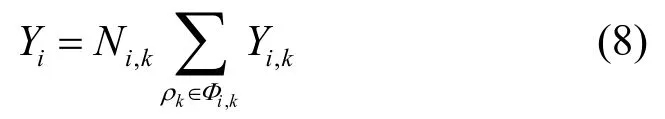
3.2本地阻塞时间
在任务τi就绪前或被远程阻塞而挂起时,其本地低优先级任务可能被调度执行并请求共享资源。当低优先级本地任务获得并继承相应资源的优先级天花板时,其有效优先级将高于τi,从而发生优先级翻转,延迟τi的执行。在实时系统中,这种由优先级翻转引起的任务延迟被视作任务阻塞[10]。如图4所示,在J1挂起等待全局资源ρk期间,J2和J3相继请求全局资源ρk并挂起等待。此后,当J1执行非临界区时,J2和J3的共享资源请求相继得到满足,从而阻塞J1。
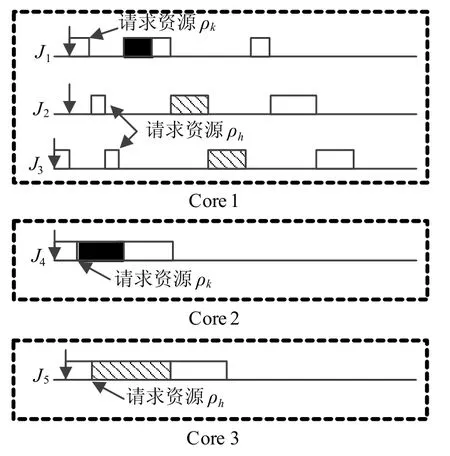
图4 本地阻塞示例
令Ni,G为τi的全局临界区数,则τi最多因远程阻塞而挂起Ni,G次。此外,由于在τi到达时低优先级任务可能已经获得共享资源,因此τi最多可被每个低优先级本地任务阻塞+ 1次。设τl为τi的本地低优先级任务,τl只有执行临界区时才可能阻塞τi,而在τi就绪后,τl只有在τi挂起期间才有机会执行其非临界区,因此τl在τi就绪期间的执行时间减去τi的远程阻塞时间即为τl对τi的本地阻塞时间。
设tx*为Ji,l开始执行第个临界区的时刻,tn*为该任务从tx*开始到τi第n次进入临界区的时刻。令,令表示τi从tx*起执行的n个临界区时间之和。其中,和的计算方法与定理1和推论2类似(推论1、2针对特定共享资源ρk的临界区,而和针对连续临界区)。根据以上分析,。由于因此。从而,在τi的一次执行中,其被本地任务阻塞的时间上限为:
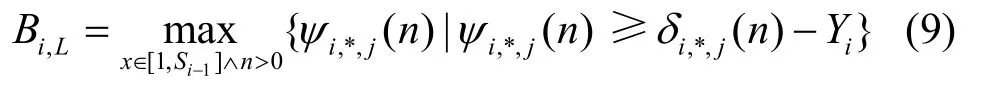
由于在任务τi就绪前或被远程阻塞而挂起时,其所有本地低优先级任务均可能先后被调度执行并请求共享资源,因此τi的本地阻塞时间不大于所有本地低优先级任务对请求造成的最大阻塞之和,即:
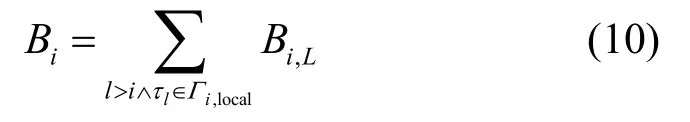
4 可调度性实验
本节实验在Microsoft VS平台上进行,根据UUnifast-Discard算法[11]随机产生任务集合。其中,任务周期在[200,1 000]内服从均匀分布,ui在[0.05,0.2]内随机产生,Ci根据任务CPU利用率定义由ui与Ti决定。每个任务有x∈[1,10]个临界区,各临界区长度y∈[0.5,8]。系统中有q=20个共享资源,任务各临界区访问各共享资源的概率均等,且每个任务集合中最多有20个任务访问同一个共享资源。
将以上所得任务集合按照Worst-Fit算法(以避免任务分配故障问题[12])进行任务分配(本文模拟m=8核处理器),并采用Raj[1]、KDR[5]、YLLH[9],以及本文提出的方法(Proposed)计算任务最坏阻塞时间。根据各方法所得最坏阻塞时间,采用文献[5]的RTA方法分析任务集合的可调度性。每次实验随机产生h=5 000个任务集合,分别计算以上4种分析方法的可调度率α。其中,可调度率计算方法如下:设一次实验随机产生c个任务集合,其中由分析方法A得出有g个任务集合可调度,则方法A的可调度率为α=g/ c 。由于以上各方法的所得的任务最坏阻塞时间不相同,而实验中采用了相同的可调度分析算法,因此,实验结果中各方法的可调度率反映了最坏阻塞时间的差异对的系统可调度性的影响。可调度率越高的方法,其分析所得的最坏阻塞时间越小。
图5中,每个任务有4个临界区,临界区长度为1.5。该实验显示,各方法的可调度率均随系统利用率增加而下降,其中新方法的可调度率高于其余方法。新方法通过计算任务执行多个临界区所需的执行时间下限以及在任意时间内执行临界区的时间上限,将给定时间内不可能发生的阻塞时间排除在分析所得的最坏阻塞时间以外。而其余方法对任务在某段具体时间内是否会发生任务阻塞不敏感,使得分析结果较保守。
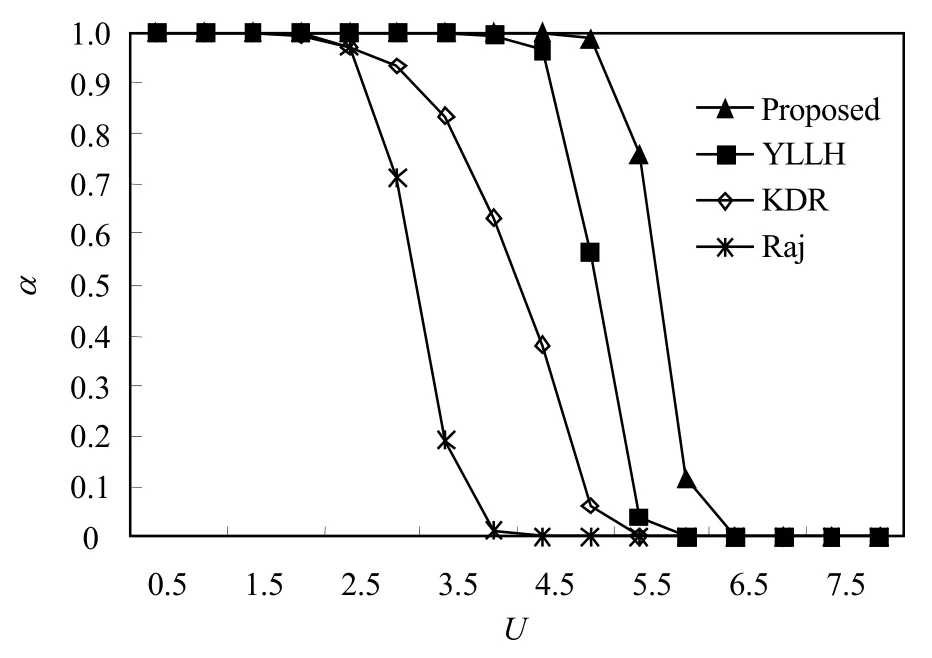
图5 x = 4,y = 1.5时α与U的关系
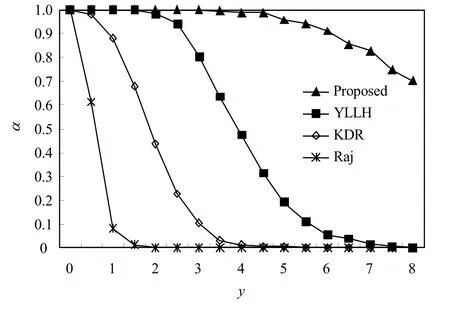
图6 x = 4,U = 4时α与y的关系
图6中,系统利用率为4,每个任务有4个临界区。由于任务阻塞时间随临界区长度增加而增加,各分析方法的可调度率均随临界区长度增加而下降。当y≤3.5时Proposed的可调度率为1;而在y=3.5时,YLLH与KDR的可调度率分别约为0.62和0.03,Raj为0。当y>3.5时,Proposed的可调度率下降速度低于其余方法。图7中,系统利用率为4.5,任务临界区长度为1.5。随任务的临界区数增加,任务在最坏情况下被阻塞的次数随之增加,从而降低了可调度率。其中,各方法的α值随x的变化趋势与图6相似,Proposed的可调度率明显高于其余方法。
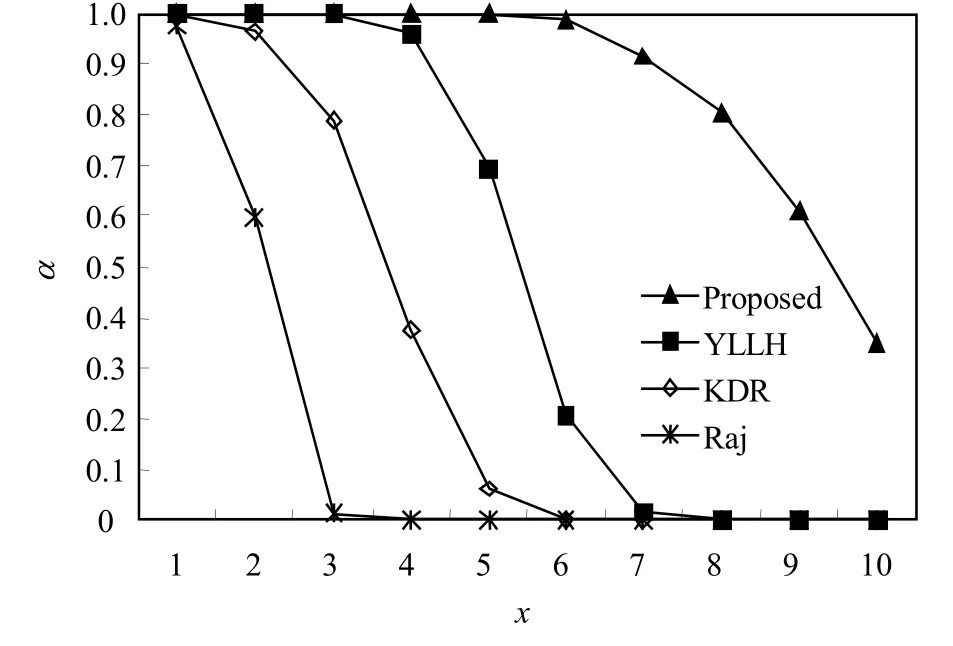
图7 y = 1.5,U = 4.5时α与x的关系
5 结 束 语
本文针对P-FP+MPCP调度,采用文献[5]的任务模型,将任务模拟为非临界区与临界区的交替序列,并对任务访问共享资源的时间关系进行定量分析。通过分析得出任务在任意时间内执行临界区段的时间之和,从而得出任意任务在给定时间内对其他任务造成的最大阻塞。在此基础上,结合文献[9]的阻塞时间分析框架,提出一种新的任务最坏阻塞时间分析方法。可调度性实验结果显示,新的分析方法明显优于已有方法,提高了系统的可调度性。
本文的研究工作得到华为基金(IRP- 2012-02-07)及开源项目www.aCoral.org的资助,在此表示感谢。
[1]RAJKUMAR R. Real-time synchronization protocols for shared memory multiprocessors[C]//IEEE International Conference on Distributed Computing Systems. Paris: IEEE,1990: 116-123.
[2]SHA L,RAJKUMAR R,LEHOCZKY J. Priority inheritance protocols: an approach to real-time synchronization[J]. IEEE Transactions on Computers,1990,39(9): 1175-1185.
[3]SCHLIECKER S,NEGREAN M,ERNST R. Response time analysis on multicore ECUs with shared resources[J]. IEEE Transactions on Industrial Informatics,2009,5(4): 402-413.
[4]BRANDENBURG B. Improved analysis and evaluation of real-time semaphore protocols for P-FP scheduling[C]// IEEE International Conference on Real-Time Embedded Technology and Application Symposium. Philadelphia: IEEE,2013: 141-152.
[5]LAKSHMANAN K,NIZ D,RAJKUMAR R. Coordinated task scheduling,allocation and synchronization on multiprocessors[C]//IEEE International Conference on Real-Time System Symposium. Washington D. C: IEEE,2009: 469-478.
[6]AUDSLEY N,BURNS A,RICHARDSON M,et al. Applying new scheduling theory to static priority preemptive scheduling[J]. Journal of Software Engineering,1993,8(5): 284-296.
[7]BINI E,BUTTAZZO G. Schedulability analysis of periodic fixed priority systems[J]. IEEE Transactions on Computers,2004,53(11): 1462-1473.
[8]BRIL R,LUKKIEN J,VERHAEGH W. Worst-case response time analysis of real-time tasks under fixed-priority scheduling with deferred preemption[J]. Real-Time Systems,2009,42(1-3): 63-119.
[9]YANG Mao-lin,LEI Hang,LIAO Yong. Synchronization analysis for hard real-time multicore systems[J]. Applied Mechanics and Materials,2012,241-244: 2246-2253.
[10]BRANDENBURG B,ANDERSON J. Optimality results for multi-processor real-time locking[C]//IEEE International Conference on Real-Time Systems Symposium. San Diego: IEEE,2010: 49-60.
[11]DAVIS R,BURNS A. Improved priority assignment for global fixed priority pre-emptive scheduling in multiprocessor real-time systems[J]. Real-Time Systems. 2011,47(1): 1-40.
[12]刘加海,杨茂林,雷航,等. 共享资源约束下多核实时任务分配算法研究[J]. 浙江大学学报(工学版),2014,48(1): 113-117. LIU Jia-hai,YANG Mao-lin,LEI Hang,et al. A research for multicore real-time task allocation algorithms[J]. Journal of Zhejiang University(Engineering Science),2014,48(1): 113-117.
编辑蒋晓
Worst-Case Blocking Time Analysis for MPCP
CAO Yong-li,YANG Mao-lin,and LIAO Yong
(School of Information and Software Engineering,University of Electronic Science and Technology of ChinaChengdu610054)
Multiprocessor priority ceiling protocol (MPCP)is a classical suspension-based real-time locking protocol,wildly used in partitioned fixed-priority (P-FP)scheduled multiprocessor/multicore real-time systems. However,prior worst-case task blocking time (WCTBT)analysis is pessimistic,which negatively impacts the system schedulability. Therefore,a novel WCTBT analysis is proposed. In this analysis,a task is modeled to be an alternative sequence of normal and critical section segments. By analyzing the minimum execution time required for a task to request several shared resources,this method improves the accuracy of prior work and provides an upper bound on the cumulative execution time for a task to execute critical sections in any time interval. Schedulability experiments indicate that the proposed method outperforms the existing methods and improves the system schedulability significantly.
blocking;multicores;partitioned scheduling;real-time locking protocols;real-time systems
TP301.6
A
10.3969/j.issn.1001-0548.2016.06.022
2015 − 03 − 14;
2015 − 12 − 26
国家自然科学基金(61103041);国家863重大项目(2012AA010904);中央高校基本科研业务费(ZYGX2012J070)
曹永立(1992 − ),男,主要从事信息工程方面的研究.
猜你喜欢
军事文摘(2022年20期)2023-01-10
英语文摘(2021年11期)2021-12-31
北京航空航天大学学报(2021年9期)2021-11-02
重型机械(2020年2期)2020-07-24
铁道通信信号(2020年10期)2020-02-07
北京航空航天大学学报(2019年9期)2019-10-26
成都信息工程大学学报(2019年3期)2019-09-25
中国航海(2019年2期)2019-07-24
三门峡职业技术学院学报(2019年1期)2019-06-27
学生天地(2018年19期)2018-09-07
