
一种高效的随机组卷算法的设计
2016-12-07 02:54周文君
电脑与电信 2016年7期
周文君
(湖南安全技术职业学院,湖南 长沙 410151)
一种高效的随机组卷算法的设计
周文君
(湖南安全技术职业学院,湖南 长沙 410151)
为了实现更好的教育测量,各大院校都在积极地进行题库系统的建设,组卷算法作为该类系统的核心,是研究的一大热点。本文分析了传统的随机组卷算法存在的不足,提出一种改进的随机组卷算法,实验结果表明,本算法能较快速地实现按要求组卷。
题库系统;随机组卷;存储过程
1 引言
随着高校信息化建设的推进,传统的人工制卷方式已无法满足高校课程考试的需求,其弊端也日益突显,许多高校都在积极地探索和研发题库管理系统,以期提高工作效率、实现教考分离、加强教学质量的监控,从而促进教学。题库管理系统中的关键技术是组卷算法的设计,即根据用户的组卷意愿(包括考试内容、章节、各类型试题数量、难度系数、时间等一系列的要求),自动从试题库中抽选试题生成试卷的过程,设计并实现高效、适合题库的组卷算法是题库管理系统重要的建设基础。本文分析了传统的随机组卷算法的工作原理及特点,在此基础之上提出了一种改进的随机组卷算法。
2 传统的随机组卷算法
随机算法是根据已经确定的组卷方案进行随机地抽取试题,最终合成试卷。随机组卷算法也有多种算法结构,一种随机算法是先计算出试题的总数N,生成一个1到N之间的随机数,然后将这个随机数作为试题序号来抽取题库中的试题,并在确定当前题不与已有试题重复之后,将该试题放入试卷中,此过程不断重复,直到抽满所需要的试题个数,完成制卷;另一种常见的随机算法,对前一种方式进行了改进,它将被抽取到的每一道试题都进行标记,这样抽取新的试题时不需要再与已有试题查重,而只需要查看其标记就知道该题是否已经抽取过,采用这种算法减少了试题查重的比较运算,但需要在数据库中增加一个标记属性列,且每道题仍需要判断标记的值,若已抽取过,则需要重新生成一个随机数,继续循环。
传统的随机组卷算法中,抽题方法虽然相对简单,但因为要避免重复抽取相同试题的情况,所以每抽取一道试题都需要将其与已有试题进行查重判断,存在大量的查重比较,需要耗费大量的时间,且因为存在重复抽题的可能性无法控制,试题抽取的次数将可能远远超过实际所需的试题量,最终导致组卷效率低下。
3 改进的随机组卷算法
3.1 获取一组互不相同的随机试题
经过分析,随机算法的关键是在于能高效地产生一组互不相同的随机数,将这一组随机数看成试题编号集,这样就可以实现对于同一类题型就的批量抽取,且省略了试题查重判断的步骤,从而大大提高随机组卷算法的效率。
《Programming pearls》一书提供了一个非常经典的随机算法,这个算法可以快速地生成一组互不相同的随机数,关键代码如下:
for(i=0;i<=n;i++)
{ x[i]=i;}//初始化
for(i=0;i<=n;i++)
{
t=rand(i,n);//产生一个i到n之间的随机数swap(x[i],x[t]);//交换值
out(x[i]);//输出一个随机数
}
上述算法的核心思想是把生成的随机数从目标集合中剔除出来,从而得到指定范围内互不重复的随机数。在随机
组卷算法中,从试题表中将满足课程名称、知识点要求、题型要求等组卷约束的试题集先筛选出来,得到一个中间结果集,将结果集中的试题编号赋值给数组变量(数组初始化操作),然后采用上述算法得到一组互不相同的、指定范围内的试题编号的集合。本算法如果在数据库服务器端采用存储过程的方式来实现,数组初始化的操作则需要通过游标遍历,将满足条件的所有试题编号保存到数组中。
除此之外,在SQL Server数据库中,可以直接通过top n结合order by newId()子句来实现随机抽题。newId()函数自动为关系表中每一条记录生成一个随机的uniqueIdentifier类型的唯一值,按照newId()对记录进行排序,可以实现为数据表中的记录进行随机排序,通过选择前n行试题来组成试卷。当处理的记录行较多时,使用该子句也比较消耗系统资源,通常在一定的数据处理的基础之上再使用此子句进行随机抽取记录。用order by newId()子句随机访问不需要循环判断,它只是在数据表随机重排后读取,因此速度相对较快,本文的组卷算法采用的就是这种方式。
3.2 数据库设计
为了方便客户端(Client)和服务器端(Server)数据传递的方便,数据的传递都以长字符串的形式进行,客户端和服务器端分别按照约定的规则进行组码和解码。例如,组卷约束表中,将命题方案表示成“110;205;303;502”,表示本试卷中“第一种题型出10道,第2种题型出5道,第3种题型出3道,第5种题型出2道”;在试卷表中将构成一份试卷的所有试题的编号按相同题型排在一起的原则表示成“编号;编号;编号;……”的形式进行保存,输出试卷时根据命题方案分解出题型及题量。因此,在组卷算法中大量地用到了临时表和游标来进行中间数据的处理。
组卷算法中主要涉及到三张表,分别是试题表、组卷约束表、试卷表。即根据组卷约束向试题表中抽取试题,将试题编号集保存至试卷表中。在数据库设计中,一张试题表包含所有类型的试题,一个组卷约束可以根据需要生成多份试卷,一份试卷表示为一条记录。
3.3 算法设计
结合上述分析,改进后的随机组卷算法流程如图1所示。本算法在SQL Server数据库服务器端设计成为存储过程,可以根据组卷要求生成N份试卷,如成功,则将组卷要求保存至组卷约束表(tMakePaper)中,并将组出的N份试卷保存至试卷表(tPaper)中,否则返回组卷失败的提示信息。
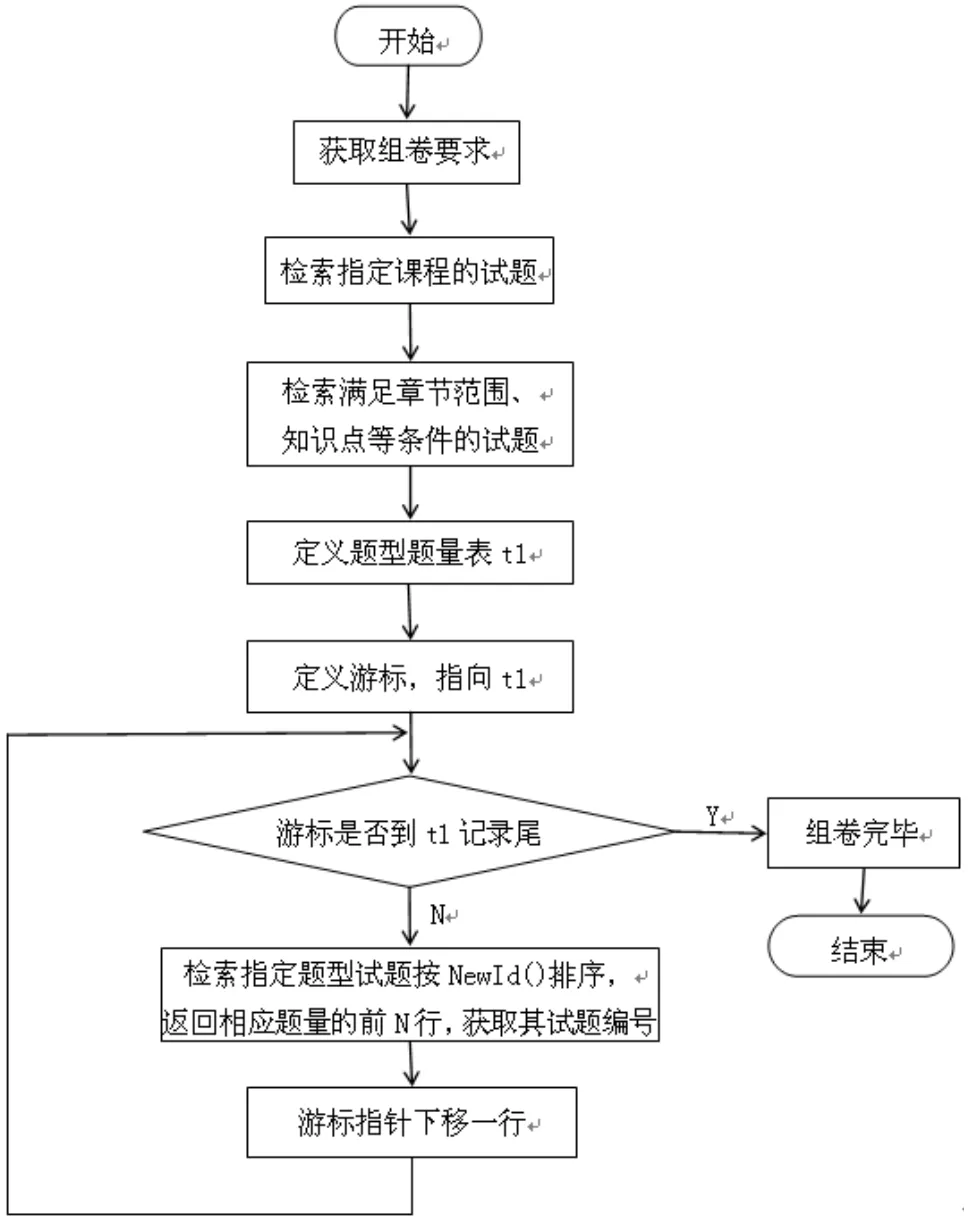
图1 随机组卷算法流程图
4 两种随机组卷算法的比较
改进后的随机算法可以实现批量地抽题,省略了大量的试题查重判断,算法的效率要明显高出传统的随机算法。将两种算法在SQL Server 2008中进行比较,用于测试的试题表中试题数量为1000道,在组卷约束条件一致的情况下各组20份试卷,改进后的随机组卷算法耗时27秒,普通随机组卷算法耗时69秒,改进的随机组卷算法具有明显的优势。
[1]江明清.论标准化试题数据库的建设[J].时代教育,2015(12):248-250.
[2]张辉.基于.NET的题库管理与智能组卷系统设计与实现[J].教育理论与实践,2012,32(18):50-52.
[3]王少豪.校园网络考试系统中组卷算法的研究[J].电脑知识与技术,2013,9(29):6618-6620.
[4]莫家庆,林瑜华.基于.NET的题库管理系统设计与实现[J].计算机时代,2014(10):78-80.
[5]李勇.教育考试题库监测与评估的内容及机制研究[J].教育理论与实践,2014,34(25):25-28. An Efficient Randomized Algorithm for Generating Test Paper
Zhou Wenjun
(Hunan Vocational Institute of Safety Technology,Changsha 410151,Hunan)
For achieving better educational measurement,the construction of item bank system is actively carried out in all colleges and universities.As the core of the system,the algorithm for generating test paper is a hot research topic.This paper analyzes the short comings of the traditional randomized algorithm for generating test paper,and proposes an improved randomized algorithm.The experimental results show that the algorithm can generate the required test paper quickly.
item bank system;algorithm for generating test paper;stored procedure
TP311.2
A
1008-6609(2016)07-0049-02
周文君,女,湖南祁东人,硕士,讲师,研究方向:计算机应用技术。
猜你喜欢
中学生数理化(高中版.高二数学)(2022年5期)2022-06-01
中学生数理化·七年级数学人教版(2021年3期)2021-07-22
中学生数理化(高中版.高二数学)(2021年5期)2021-07-21
中学生数理化·七年级数学人教版(2020年10期)2020-11-26
数码世界(2020年11期)2020-11-23
中学生数理化·七年级数学人教版(2019年10期)2019-11-25
中学生数理化·八年级数学人教版(2019年11期)2019-09-10
中学生数理化·七年级数学人教版(2017年5期)2017-11-09
中学生数理化·高一版(2017年2期)2017-04-25
网络空间安全(2016年11期)2017-02-13
