
自适应Web页面数据抽取方法*
2016-12-13 06:51陈晓雷李晓光宋宝燕
计算机与数字工程 2016年11期
王 龙 陈晓雷 李晓光 宋宝燕
(辽宁大学信息学院 沈阳 110036)
自适应Web页面数据抽取方法*
王 龙 陈晓雷 李晓光 宋宝燕
(辽宁大学信息学院 沈阳 110036)
针对Web页面数据抽取问题,提出了一种基于抽取模板的自适应Web页面数据抽取方法。给出了自适应web数据抽取的整体流程,详细介绍了抽取模板中抽取规则和自适应搜索规则的定义方式,web页面与抽取模板的匹配方法,以及抽取路径失效后目标数据的搜索与抽取模板的自适应修改过程。实验结果表明,基于抽取模板的自适应web页面数据抽取方法的召回率和查准率都达到95%以上,方法中的自适应搜索规则有效地减少了抽取模板的制定数量。
自适应; 数据抽取; Web数据; 抽取模板; 匹配度
Class Number TP391.1
1 引言
Web数据抽取是Web数据挖掘工作中的一步重要的过程[1]。Web数据抽取就是将Web页面上半结构化的数据按照一定的方法抽取出来,保存为结构化格式,如保存为XML文件或者存储到数据库中等[2~3]。传统的Web数据抽取方法大多是针对某一类特定信息源的数据抽取,主要由一系列预先定义的抽取规则以及这些规则的执行代码组成,并没有充分利用页面数据的结构特征,且对页面的结构有一定要求,若页面结构是动态变化的便不能很准确的进行数据抽取,导致数据抽取失败。
Web数据抽取技术可分为基于页面DOM结构的数据抽取技术[4~9]、基于统计理论的数据抽取技术[10~12]和基于页面视觉特征的数据抽取技术[13~15]。其中基于页面DOM结构的数据抽取技术应用最为广泛。
当前基于页面DOM结构的研究大多集中在对特定的页面进行推导,根据某类网页特征生成树中的数据对象的对应实例路径,在网页结构发生变化时无法自适应,即使发生的变化很小,仍然需要进行人工分析与修改。为减少人工干预,本文提出一种基于抽取模板的自适应Web页面数据抽取方法。文中首先给出自适应Web数据抽取的整体流程,然后设计了一种基于模板的自适应数据抽取方法,最后进行了实验讨论与分析。
2 自适应Web数据抽取整体流程
基于模板的自适应数据抽取过程主要分为五个阶段,分别为:初始准备阶段、模板准备阶段、模板匹配阶段、数据抽取阶段和自适应修改阶段。根据待抽取页面的性质不同,抽取过程可能含全部五个阶段,也可能只包含其中的一部分,具体过程如图1所示。
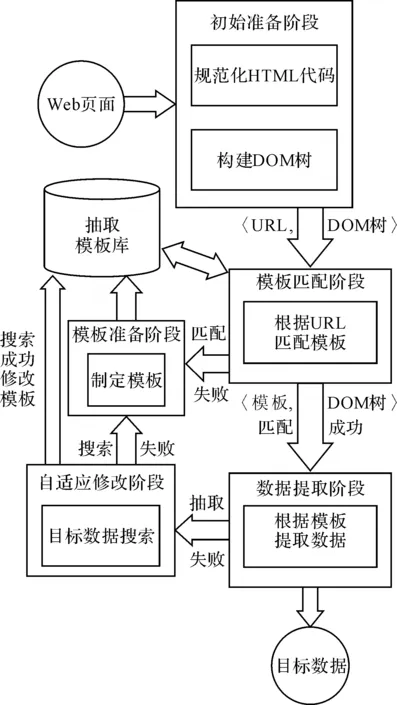
图1 自适应数据抽取整体流程
自适应Web数据抽取方法的整体步骤如下:
Step1:抓取Web页面HTML源代码,规范化,并构建网页DOM树;
Step2:提取页面URL,与抽取模板库中的模板进行匹配,如果匹配成功,则按照匹配度由高到低的顺序依次根据抽取模板中的抽取规则抽取目标数据,直到目标数据抽取成功。如果匹配不成功则制定新的抽取模板;
Step3:如果不存在目标数据抽取全部成功的模板,则提取错误项最少的模板进行自适应修改;
Step4:根据模板中的搜索规则按自底向上的顺序计算DOM树中节点的评价值;
Step5:如果遇到评价值大于搜索阈值的节点,则搜索成功,将节点数据作为目标数据,并将节点的XPath表达式加入模板对应数据项的XPath队列中;否则制定新的抽取模板。
3 基于模板的自适应数据抽取方法
3.1 抽取模板定义
网页数据抽取模板主要由地址块和数据块两部分组成,数据块中每条数据的定义除了包含数据的抽取规则以外,还包含了自适应修改规则,数据抽取模板的详细信息如图2所示。

图2 网页数据抽取模板
其中,〈site〉表示数据抽取的网站,〈url〉表示数据抽取的页面网址,〈data〉表示需要抽取的数据,由多个〈node〉标签构成。〈node〉标签中,〈nodeId〉表示抽取数据的标识,〈title〉表示抽取数据的含义,〈xpaths〉表示需要抽取的页面数据的XPath路径表达式集合,〈rule〉表示数据搜索规则。〈rule〉标签中,〈keyword〉表示关键字规则;〈tag〉表示Html标签规则;〈context〉表示上下文规则,包含〈content〉和〈distance〉两个标签,分别为上下文内容和与当前节点的距离;〈font〉包含〈color〉和〈size〉两个标签,分别为字体颜色和字体大小。
3.2 模板匹配
网站下的同类页面通常是基于同一网页模板生成,在外观、内容布局和样式结构上都非常相似,其特点是它们的DOM树主干结构是相同的,只是叶子节点的填充数据不同。使用现有的判断页面相似性的算法效率较低,而且需要保存大量样本。通过观察发现,页面相似的网页,其url路径也是相似的,因此本文通过计算待抽取网页的url与抽取模板中的〈url〉标签数据的相似程度来获得待抽取网页与抽取模板的匹配度,匹配度R(w,m)可定义为
其中w为待抽取网页,m为抽取模板,urlw为待抽取网页的url地址,urlm为抽取模板中〈url〉标签的数据,S(url)表示将对应url以“/”分隔开的字符串集合,|S(urlw)∩S(urlm)|表示urlw和urlm中相同部分的字符串长度,|min(S(urlw),S(urlm))|表示urlw和urlm中较小的集合的长度。当待抽取网页的url的域名与抽取模板中的〈site〉标签数据相同,并且匹配度大于指定阈值t,即R(w,m)>t时,待抽取网页与抽取模板匹配成功。
3.3 数据搜索规则
由于XPath路径表达式对页面结构的变化比较敏感,在页面结构发生变化后,应用原有的XPath无法继续抽取数据,针对这种情况,根据页面目标数据的特征制定搜索规则。当页面结构发生变化导致原XPath表达式无法抽取目标数据时,程序自动应用这些规则搜索目标数据,再根据目标数据生成XPath表达式加入原XPath队列中,从而达到自适应Web页面结构变化,减少人工干预的目的。
1) 关键字搜索规则
如果目标数据对应的文本信息在Web页面中是惟一的,则在模板中的相应〈keyword〉标签中加入该文本信息,作为关键字规则。例如要抽取电子商务网站中商品分类页面中的“家用电器”类的URL信息,则可将“家用电器”作为该目标数据的关键字搜索规则。关键字相关度dkey(ntxt,mkey)可定义为:
其中ntxt为DOM树中节点数据对应的文本信息,mkey为模板中对应的〈keyword〉标签的值。
2) HTML标签搜索规则
如果目标数据对应的HTML标签信息在Web页面中是特殊的,则在模板中的相应〈tag〉标签中加入该HTML标签信息,作为HTML标签规则。例如要抽取新闻正文类页面中的新闻标题信息,新闻标题信息在〈h1〉标签中,则可将〈h1〉作为该目标数据的HTML标签搜索规则。HTML标签相关度dtag(ntag,mtag)可定义为:
其中ntag为DOM树中节点数据对应的HTML标签信息,|ntag|为ntag在DOM树中出现的次数,mtag为模板中对应的〈tag〉标签的值。
3) 上下文搜索规则
上下文表示页面中目标数据附近的固定信息。根据Web页面的视觉特征可以发现网页中的信息根据语义分块,语义相近的信息在页面的视觉上距离较近。如果要抽取的数据不容易搜索,但它有容易搜索的上下文,那么对目标数据的搜索可以转化为对其上下文的搜索。找到其上下文后,根据上下文的位置定位目标数据。例如文章的标题在作者、发表时间和正文等信息的上方,由于标题具有比较突出的特征,定位标题的位置后,根据标题的位置再寻找作者、发表时间等数据;商品价格的前面一般有“价格”两个字,定位价格标签,那么其后含有符合价格模式的字符串可认为是商品价格。设上下文数据与目标数据之间的同级及上级标签数量为两者之间的“距离”,若上下文数据在目标数据之前,“距离”为正值,否则为负值。上下文相关度可定义为
其中ndist为DOM树中节点数据与对应上下文之间的距离,mdist为模板中对应的〈distance〉标签的值。
4) 字体搜索规则
页面中的某些数据为了吸引用户注意,会在视觉特征上与其他数据加以区分,它们的字体颜色和字体大小跟普通文本有所区别。因此,在DOM树的节点中按照字体的颜色和大小可以搜索目标数据。字体相关度可定义为

其中nfont,color为DOM树中节点数据的字体颜色,mfont,color为模板中对应的〈color〉标签的值,equal为判断二者是否相同,相同返回1,否则返回0。nfont,size为DOM树中节点数据的字体大小,mfont,size为模板中对应的〈size〉标签的值。
根据以上规则,定义评价函数如下:
其中|dtag,dcont,dfont|表示dtag,dcont,dfont中值不为0的个数。当评价函数值大于搜索阈值时,搜索成功。
4 实验分析
为了有效评估和分析本文方法在数据抽取上的性能,采用10个主流网站的300个主题型网页作为实验数据集。这些试验网页分属于新闻类和论坛类。实验结果如表1所示。
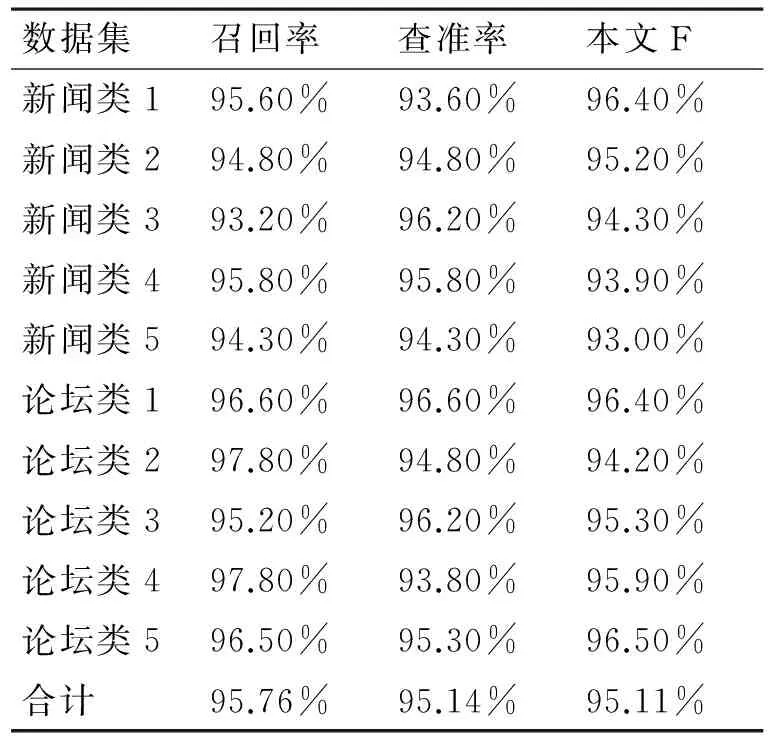
表1 性能测试结果
其中R为召回率、P为查准率,F为R和P的综合效率[16]。
从表1中可以看出,对于所有数据集,基于本文提出的数据抽取方法的召回率、查准率和综合效率始终保持在93%以上,平均分别达到95.76%、95.14%和95.11%。实验结果表明,本文提出的方法具有较高的召回率、查准率和综合效率,符合Web网页数据抓取的实际需求。
为了测试本文方法的自适应能力,采用五个主流博客网站中的页面作为实验数据集。每个网站中的页面由于采用的网页模板不同,因此页面的结构也不同,提取那些模板相似的网页作为实验数据,总共提取150个页面。实验结果如表2所示。

表2 自适应能力测试结果
从表2中可以看出,对于所有数据集,采用本文提出的自适应策略均能有效地降低制定模板的数量,减少人工干预,具有更高的适应性和智能性。
5 结语
本文提出一种基于模板的自适应Web页面数据抽取方法。在制定抽取模板时不仅定义相应的抽取规则,而且根据页面数据的文本特征、HTML标签特征、上下文特征和视觉特征定义自适应搜索规则。Web页面通过url相似性与模板进行匹配,匹配成功后按照抽取规则进行数据抽取。如果页面发生变化,XPath表达式失效,则根据自适应搜索规则重新搜索数据,并更新XPath。实验结果表明该方法具有较高的效率,并且有效地减少了抽取过程中的人工干预。
[1] Appelt D E. Introduction to information extraction[J]. Ai Communications, 999,12(3):161-172.
[2] Knoblock C A, Lerman K, Minton S, et al. Accurately and reliably extracting data from the web: A machine learning approach[J]. Intelligent exploration of the web. Physica-Verlag HD,2003,111:275-287.
[3] Broder A Z, Glassman S C, Manasse M S, et al. Syntactic clustering of the web[J]. Computer Networks and ISDN Systems,1997,29(8):1157-1166.
[4] Liu, Ling, Calton Pu, and Wei Han. XWRAP: An XML-enabled wrapper construction system for web information sources[C]//Proceedings of the 16th International Conference on Data Engineering. IEEE,2000:611-621.
[5] Liu, Bing, Robert Grossman, and Yanhong Zhai. Mining data records in Web pages[C]//Proceedings of the ninth ACM SIGKDD international conference on Knowledge discovery and data mining. ACM,2003:601-606.
[6] Zhai, Yanhong, and Bing Liu. Web data extraction based on partial tree alignment[C]//Proceedings of the 14th international conference on World Wide Web. ACM,2005.
[7] Crescenzi, Valter, Giansalvatore Mecca, Paolo Merialdo. Roadrunner: Towards automatic data extraction from large web sites[J]. VLDB,2001:109-118.
[8] Arasu, Arvind, and Hector Garcia-Molina. Extracting structured data from web pages[C]//Proceedings of the 2003 ACM SIGMOD international conference on Management of data. ACM,2003:337-348.
[9] Gupta S, Kaiser G, Neistadt D, et al. DOM-based content extraction of HTML documents[C]//Proceedings of the 12th international conference on World Wide Web. ACM,2003:207-214.
[10] 孙承杰,关毅.基于统计的网页正文信息抽取方法的研究[J].中文信息学报,2004,18(5):17-22. SUN Chengjie, GUAN Yi. A Statistical Approach for Content Extraction from Web Page[J]. Journal of Chinese Information Processing,2004,18(5):17-22.
[11] Song M, Wu X. Content extraction from web pages based on Chinese punctuation number[C]//Proceedings of the International Conference on Wireless Communications, Networking and Mobile Computing. IEEE,2007:5573-5575.
[12] 周佳颖,朱珍民,高晓芳.基于统计与正文特征的中文网页正文抽取研究[J].中文信息学报,2009,23(5):80-86. ZHOU Jiaying, ZHU Zhenmin, GAO Xiaofang. Research on Content Extraction from Chinese Web Page Based on Statistic and Content-Features[J]. Journal of Chinese Information Processing,2009,23(5):80-86.
[13] Cai D, Yu S, Wen J R, et al. VIPS: a Vision-Based Page Segmentation Algorithm[R]. Microsoft technical report, MSR-TR-2003-79,2003.
[14] Liu W, Meng X, Meng W. Vide: A vision-based approach for deep web data extraction[J]. Knowledge and Data Engineering, IEEE Transactions on,2010,22(3):447-460.
[15] Cai D, Yu S, Wen J R, et al. Extracting content structure for web pages based on visual representation[C]//Web Technologies and Applications, Asian-pacific Web Conference, Xi’an,2003:406-417.
[16] Laender A H F,Ribeiro- Neto B A,Da Silva A S,et al.A Brief Survey of Web Data Extraction Tools[J].SIGMOD Record,2002,31(1):84.
Adaptive Web Data Extraction Method
WANG Long CHEN Xiaolei LI Xiaoguang SONG Baoyan
(School of Information, Liaoning University, Shenyang 110036)
According to the web page extraction, an adaptive web data extraction method based on extraction template was proposed. The adaptive web extraction process was given. The extraction rules and the adaptive search rules were defined, the matching method of the web page and the extraction template was presented, and the process of target data search and extraction template adaptive repair was described in details. Experimental results showed that the recall rate and precision rate were more than 95%, and the method can effectively reduce the quantity of extraction templates.
adaptive, data extraction, Web data, extarction template, matching degree
2016年5月3日,
2016年6月27日
国家自然科学基金(编号:61472169);辽宁省科学技术基金(编号:20141049);辽宁大学博士启动基金资助。作者简介:王龙,男,博士,讲师,研究方向:机器学习,数据挖掘,大数据管理,图数据管理技术等。陈晓雷,男,硕士研究生,研究方向:机器学习,数据挖掘等。李晓光,男,博士,教授,研究方向:数据库技术,数据挖掘,大数据管理,图数据管理技术等。宋宝燕,女,博士,教授,研究方向:数据库技术,大数据管理,图数据管理技术等。
TP391.1
10.3969/j.issn.1672-9722.2016.11.022
猜你喜欢
保健医苑(2022年1期)2022-08-30
动漫界·幼教365(中班)(2021年4期)2021-05-23
成都信息工程大学学报(2021年6期)2021-02-12
电脑爱好者(2020年17期)2020-09-14
车迷(2018年11期)2018-08-30
电子制作(2018年10期)2018-08-04
魅力中国(2018年5期)2018-07-30
海峡姐妹(2018年3期)2018-05-09
电子制作(2017年2期)2017-05-17
Coco薇(2015年11期)2015-11-09
