
密集小站网络下基于协作滤波的缓存内容决策和用户归属*
2016-12-19 11:05余江,邱玲
中国科学院大学学报 2016年6期
余 江, 邱 玲
(中国科学技术大学中国科学院无线光电通信重点实验室,合肥 230027)(2016年1月7日收稿; 2016年3月2日收修改稿)
随着互联网的高速发展,据工业界预计,第5代移动通信系统的容量需提升1 000倍[1].为应对海量数据增长,增加小站密度,实现密集组网极具前景.在密集小站网络下,由于小站数量激增,为节省成本,考虑采用铜缆或毫米波部署回程链路,而这可能导致小站回程链路容量受限[2].为克服该限制,一种有效的方案是在小站上部署缓存[3],若用户请求文件在缓存中,小站直接通过无线链路传输该文件;否则需经由回程链路从核心网中获取,再通过无线链路传输该文件,使得用户的传输速率不仅与无线信道条件有关,还受限于回程链路容量.另一方面,小站在考虑接入哪些用户时,除考虑信干燥比等因素外,还需考虑用户请求文件在缓存中的命中率.因此,如何决策缓存内容以提高命中率,并基于此优化用户归属有待研究.
目前,学术界已逐渐聚焦对该问题的研究[4-8].由于缓存容量有限,合理预测用户未来请求,并根据文件流行性确定缓存内容以提高命中率显得尤为重要.一种常见的简化方案是假设文件全局流行性服从Zipf分布[4-5].基于该假设,Pantisano等[6]提出一种缓存协助的最大化系统吞吐量的用户归属算法;Zhou等[7]提出一种最大化小站和用户能量效率的用户归属方案.然而Zink等[8]指出局域网内,Youtube上视频文件的全局流行度和局部流行度的关联度并不大.假设文件全局流行度服从Zipf分布尽管合理,但却失去了利用文件局部流行性和关联做出更精准预测的能力.进一步,Pantisano等[9]利用用户行为信息预测其请求文件的概率,提出一种最小化小站回程链路带宽分配的用户归属算法.然而,在缓存内容决策上,文献[9]和文献[6-7]类似,仍采用随机缓存策略或缓存最受欢迎文件,未考虑缓存内容的优化决策.因此,如何基于用户历史行为更精准地决策缓存内容,并基于此确定用户归属有待研究.
基于上述研究现状,本文利用基于用户的Top N协作滤波推荐系统[10]决策小站缓存内容,提出一种最大化系统吞吐量的低复杂度用户归属方案.基于用户的Top N协作滤波推荐系统通过计算用户间的相似性,为用户推荐与其相似用户请求过而该用户尚未请求的文件,进而预测用户未来请求,以在小站缓存最可能被尽可能多用户请求的文件,提高缓存命中率.具体地,问题解决分2个阶段.首先根据用户历史行为确定小站缓存内容.随后根据缓存内容确定用户归属.为保证用户间的比例公平,形成用户间吞吐量比例约束下的系统吞吐量最大化问题.由于该问题为混合整数规划问题,难以直接求解,因此本文提出一种低复杂度归属算法.通过对用户未来请求文件更精准的预测及其归属的优化,所提方案提升了系统性能,缓解了回程链路压力.
1 系统模型
考虑由N个小站及M个用户组成的密集小站网络的下行链路传输,如图1所示.该网络中,小站和用户集合分别表示为:S={1,2,…,N}和U={1,2,…,M}.
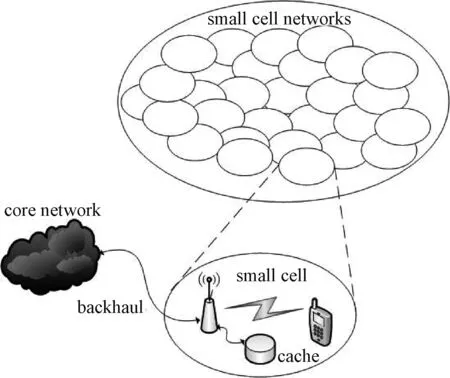
图1 系统模型Fig.1 System model
每个小站通过回程链路连接到核心网,小站i的回程链路容量为Bi,配置容量为Qi的缓存,存储从文件库F下载的部分文件子集Ci⊂F.每个用户j请求一系列文件Fj={f1,…,fm}⊂F,简单起见,假设所有文件大小相等,为s.设小站i的传输功率为Pi,小站i和用户j间的信道增益为hij,其中包括路径损耗和小尺度衰落.W为系统带宽,因此,根据香农公式可得用户j归属到小站i时可达传输速率为
(1)
其中,N0为噪声功率,Ij表示所有干扰用户j的小站集合,即Ij={Si}.设小站i对用户j的资源分配比例为βij,考虑用户以时分复用多址接入(TDMA),即βij为实变量,故有∑j∈Uβij=1.
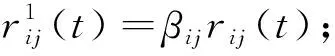
2 缓存内容决策和用户归属
2.1 基于协作滤波的缓存内容决策
由于用户行为信息多为仅记录用户操作的隐式信息,因此,相较于评分预测推荐系统,Top N推荐系统更适合预测用户未来请求.同时,在密集小站网络下,由于用户数远小于其可能请求的文件库大小,即M≪|F|,该场景下,基于用户的协作滤波推荐系统相较基于物品的协作滤波推荐系统,计算复杂度更低.因此,本文利用基于用户的Top N协作滤波推荐系统预测用户未来请求,并依此决策缓存内容,以在性能和复杂度间取得折中.
所提基于用户的Top N协作滤波推荐系统利用用户间相似性计算文件间相关性以预测用户未来请求文件.用户间相似性[10]通过余弦相似性计算如下:
(2)
其中,N(u)和N(j)分别表示用户u,j请求过的文件集合.因此,对于小区内的用户u,计算与其最相似的K个用户集合为S(u,K)={u1,u2,…,uK},则对于用户u,可预测其未来请求文件如下.首先,构建候选预测文件集合为
(3)
即将与用户u最相似的K个用户请求过而用户u未请求的文件作为候选预测文件.随后,计算用户u对Ru中每个文件f的感兴趣程度为
(4)
步骤1(预测用户未来请求文件):
1)计算用户间相似度wuj,∀u,j∈U;
2)∀u∈U,确定其K邻近用户集合S(u,K)及其候选预测文件集合Ru;
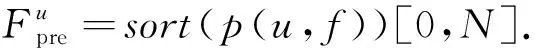
步骤2(确定缓存内容):
确定小站i的缓存内容为
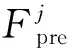
hitRatio(i)=(∑j∈Mmij/|Fj|)/M.
(5)
2.2 最大化系统吞吐量的用户归属策略
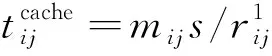
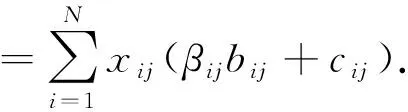
(6)
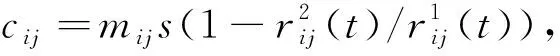
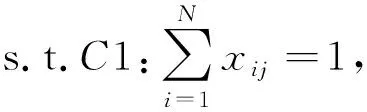
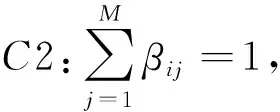
C3:L1:L2:…:LM=η1:η2:…:ηM.
其中,约束1表示每个用户最多接入一个小站,约束3表示用户间吞吐量的比例约束.由于P0为混合整数规划问题,难以直接求解.因此放松用户仅能接入一个小站的限制,允许用户同时接入多个小站,即xij=1,∀i,j,则原问题可转化为
P1为标准线性规划问题,其最优解存在且唯一,可通过内点法等凸优化方法求得[11].由于用户可接入多个小站,该最优解提供了原问题的一个性能上界.然而一方面由于内点法的求解复杂度过高为O(M3N3),另一方面允许用户接入多个小站实现复杂,因此亟需设计用户接入单小站时的低复杂度算法.注意到此时用户间吞吐量的比例约束可能难以满足,为使问题可解,放松P1中的等式约束(C3),最大化最小归一化吞吐量y,形成P1的近似问题为
问题P2的拉格朗日函数为
(7)
其中,λj≥0,δi≥0,μij≥0为拉格朗日乘子.求其KKT条件如下:
∂J/∂βij=λjbij/ηj-δi+μij=0,∀i,j.
(8)
μijβij=0,∀i,j.
(9)
根据式(8)、式(9)可得下述引理:
引理2.1对于小站i和k存在最优偏置因子θik,使得用户j在bij/bkj>θik时接入小站i,在bij/bkj<θik时接入小站k.
引理2.1可通过文献[12]中类似的方法证明,不再赘述.由引理2.1可知,用户j对小站i,k的选择依赖于用户j在小站i,k间基础吞吐量的比值bij/bkj,bij/bkj最小的用户有优先切换到小站k的权利.并且对于小站i,用户间吞吐量满足比例约束时其归一化吞吐量yi可表示为
yi=(βi1bi1+ci1)/η1=…
=(βi|Ai|bi|Ai|+ci|Ai|)/η|Ai|
=(1+∑j∈Aicij/bij)/(∑j∈Aiηj/bij).
(10)
其中,Ai为接入小站i的用户集合.式(10)中最后一项根据∑j∈Aiβij=1得到.因此根据上述对P2最优解的分析,提出用户接入单个小站时的低复杂度归属算法如下
步骤1(用户预归属):根据最大信干燥比原则预归属用户到相应小站;
步骤2(归属更新):
1)根据式(10)计算各小站归一化吞吐量yi,∀i;
2)计算ψik=yi-yk,令Ψ={ψik|ψik<0,∀i,k};
3)寻找归一化吞吐量差距最大的2个小站
(i′,k′)←argminψik∈Ψψik;
4)寻找接入小站i′的用户中具有最小基础吞吐量比值的用户:j′=argminj∈Ai′bi′j/bk′j;
6)移除各小站中最近最不常使用的文件,更新各小站缓存;
7)循环步骤2,直到Ψ=∅.
上述算法表明当小站i′切换用户j′到小站k′后,小站k′的归一化吞吐量仍大于小站i′的归一化吞吐量时,才执行切换,因此可保证每次迭代最小归一化吞吐量单调不减,从而保证算法的收敛性.
3 仿真结果与分析
仿真中设M=200个用户和N=[60,300]个小站均匀分布在500 m×500 m的小区内,路径损耗为L(d)=128.1+37.6lgd,小站和用户间的信道服从独立同分布瑞利衰落.系统带宽为20 MHz,小站的传输功率为33 dBm,噪声功率为-114 dBm,小站回程链路容量Bi=[10,100]Mbps.仿真中采用Movielens数据集[13]建模用户请求,设每个用户请求3 900部电影中的15部电影,各用户间吞吐量的比例约束为η1∶η2∶…∶nM=1∶1∶…∶1.
为比较算法间性能差异,考虑下列对比算法.对比算法1为最大信干燥比算法[7],该算法归属用户到接收信干燥比最大的小站,且小站上无缓存.对比算法2在此基础上,考虑文件流行度服从Zipf分布,在小站上缓存文件库中最受欢迎文件.
图2、图3对比不同算法的缓存命中率.从图2可以看出,随着缓存文件数的增多,所提算法和对比算法2的缓存命中率均增加,且相较对比算法2有明显增益,当缓存文件数大于等于100时,所提算法增益均在10%以上.在固定缓存文件数为100时,图3显示随着用户数的增多,所提算法的增益愈发明显,这是因为随着用户历史行为信息的增多,能通过所提缓存决策算法挖掘的个性化信息也越多.
图4展示小站回程链路容量Bi=10 Mbps时,系统吞吐量和小站数的关系.可以看出,所提算法相较2种对比算法有明显的增益,尤其是在小站部署密度较大时,如小站数为220时,所提算法相较对比算法1、2的增益分别为19.1%和11.3%.这是因为所提算法一方面通过提升缓存命中率带来增益,另一方面在归属用户时使各小站间的负载尽可能均衡,减少了空闲小站数,进而带来了性能提升.
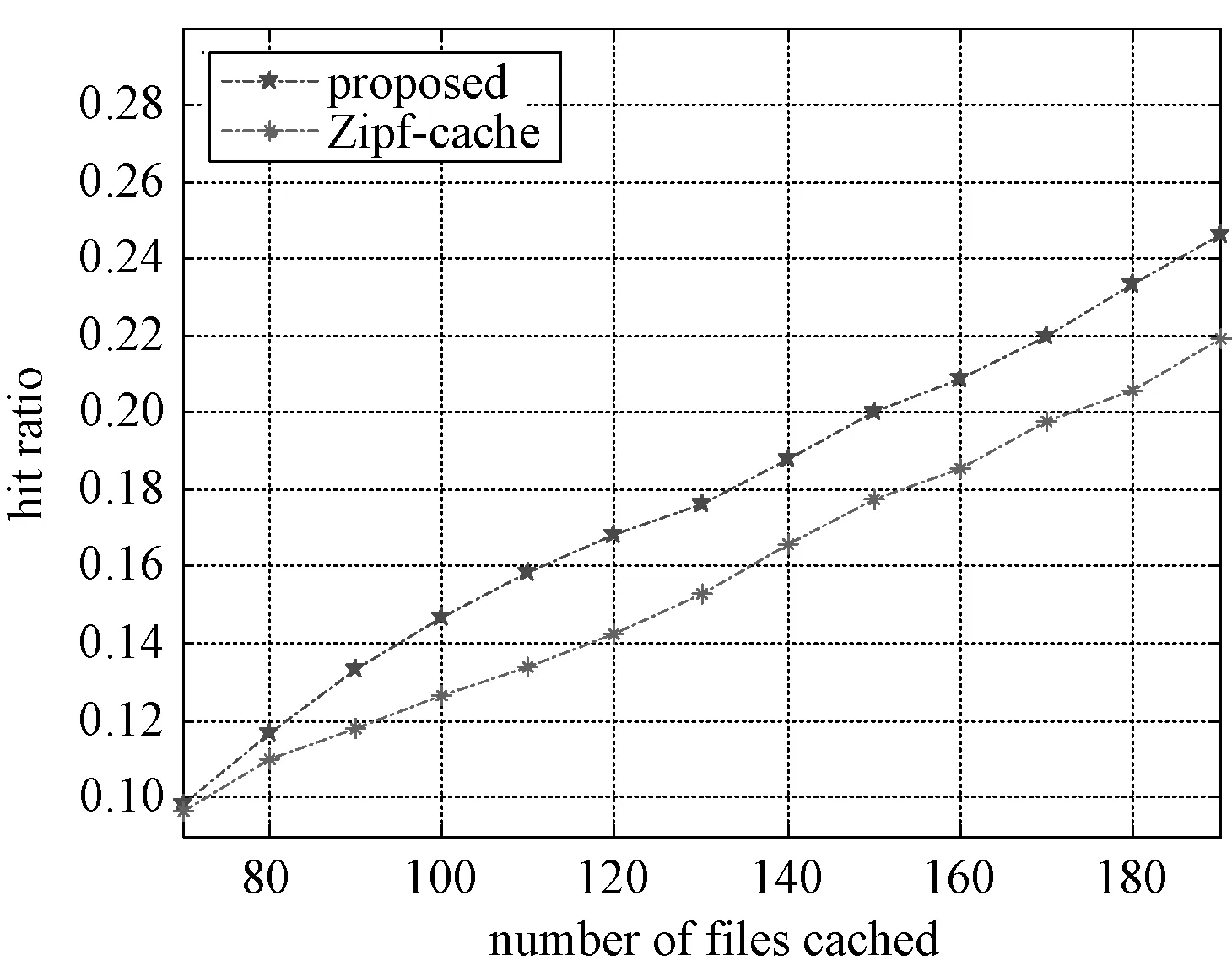
图2 缓存文件数与命中率关系Fig.2 Number of cache files versus hit ratio
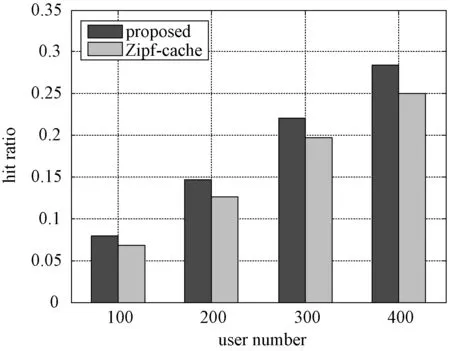
图3 用户数与命中率关系Fig.3 Number of users versus hit ratio
图5给出小站数为200时,系统吞吐量与小站回程链路容量的关系图.随着回程链路容量的增加,其容量逐渐不再受限,因此3种算法的系统吞吐量先增加最终趋于稳定.所提算法相较对比算法仍有明显增益,这是因为缓存命中率的提高在回程链路容量较小时会带来较大增益,而在回程链路容量充足时,合理的用户归属会带来较大增益.
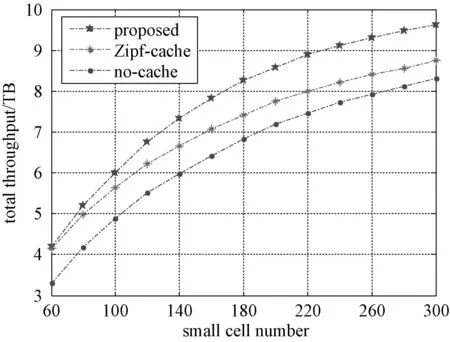
图4 小站数目与系统吞吐量关系Fig.4 Number of small cells versus throughput

图5 回程链路容量与系统吞吐量关系Fig.5 Backhaul bandwidth versus throughput
4 结束语
本文提出一种密集小站下,基于协作滤波的缓存内容决策和用户归属算法.本文首先利用基于用户的Top N协作滤波推荐系统确定小站缓存内容,以提高缓存命中率.随后形成一个系统吞吐量最大化的用户归属问题.通过放松约束条件,得出用户对小站的选择与其在不同小站的基础吞吐量之比相关的结论,并提出一种低复杂度归属算法.通过对缓存内容更精准的决策和用户归属的优化,所提算法相较已有算法在缓存命中率和系统吞吐量上有明显增益,缓解了回程链路压力,提升了服务质量.
猜你喜欢
加油站服务指南(2022年6期)2022-07-28
体育科技文献通报(2022年5期)2022-06-05
汽车工艺师(2021年7期)2021-07-30
兰州理工大学学报(2021年3期)2021-07-05
鸭绿江·华夏诗歌(2020年4期)2020-06-15
中国铁路文艺(2019年3期)2019-04-29
中国生殖健康(2019年11期)2019-01-07
长江丛刊(2018年31期)2018-12-05
诗潮(2018年5期)2018-08-20
NBA特刊(2017年8期)2017-06-05
