
K—Means算法及其在卷烟零售门店库存聚类分析中的应用
2017-03-20 16:59盛剑樊红龚天任程幸福
商业经济 2017年3期
盛剑+樊红+龚天任+程幸福

[摘 要] 为准确了解市场库存和需求,减小商业库存压力,实现对零售户进行按需供货,发现零售户群体共性特征,通过考察零售户的年销售量和年库存量,基于Spark+MLlib的kmeans++算法实现对零售户行为的聚类,并根据收集所得的卷烟销售扫码数据采用KMeans+进行聚类分析,将客户分为三大类别,得到了较为合适的分类结果,给出了相应的销售和库存的管理策略,这为卷烟销售和库存管理策略的制定提供决策支持。
[关键词] K-Means算法;卷烟零售户;库存聚类分析
[中图分类号] F272 [文献标识码] A
[文章编号] 1009-6043(2017)03-0128-02
Abstract: In order to accurately understand the market inventory and demand, reduce the pressure of business inventories, implement the on-demand supply to retailers and find out the common features of retailers groups, the study investigates their annual sales and inventory level. The customer can be divided into three categories based on the kmeans++ algorithm of Spark + MLlib and clustering analysis of collected the code data of cigarette sales by means of KMeans +. The appropriate classification results, and corresponding management strategy of sales and inventory, which provide decision support.
Key words: K-Means algorithm, cigarette retailers, inventory clustering analysis
一、前言
KMeans算法是聚类分析中的常用算法,它是数据划分或者分组处理的重要方式,目前在电子商务、生物科学、图像处理、Web文档分类等领域都得到了有效的应用,如许多文献利用KMeans进行聚类分析将客户细分特定的类型,同时根据其所属类别进行群组协同推荐。论文根据收集所得的卷烟销售扫码数据采用KMeans进行聚类分析,以期更为准确了解市场销售和库存情况,减小商业库存压力,实现对零售户進行按需供货,发现零售户群体共性特征,为制定合理的卷烟销售和库存管理策略提供决策支持。
二、实验平台选择
Spark是一个基于内存的分布式计算系统,是由UCBerkeley AMPLab实验室于2009年开发的开源数据分析集群计算框架,是BDAS(Berkeley Data Analytics Stack)中的核心项目,被设计用来完成交互式的数据分析任务。MLlib是建立在Apache Spark上的分布式机器学习库,Spark的机器学习有分类和回归、协同过滤、聚类、降维和特征提取和变换等[2]。Spark将分布式内存抽象成弹性分布式数据集(Resilient Distributed Datasets,RDD)。RDD允许用户在执行多个查询时显式地将工作集缓存在内存中,以便后续的查询能够重用,这极大地提升了查询速度[2]。故论文选择了Spark+MLlib作为K-means算法的运行平台。
三、卷烟零售户销售量和库存的聚类分析
(一)原始数据及数据预处理
烟草公司在以往的经营中产生了海量的柜台扫码交易数据,本文数据来自贵阳市红华烟草公司零售门店在2014年1月1日至2015年3月20日之间产生的柜台扫码销售及库存数据,共有2014年1月1日至2015年3月20日的1797371条销售数据,有销售码、执照-代号、交易时间、商品代号、交易数量、单价、交易金额、门店名等字段,265071条库存数据,有库存数量、日期、时间、门店名等字段。本实验通过spark集群计算出每个零售门店在2014年1月1日至2015年3月20日之间日库存量之和与日销售量之和,最终得到了各零售户的年销售量(单位:箱)和年库存量(单位:箱)。例如,零售户1的销售量(单位:箱)和年库存量(单位:箱)分别为18706箱和57705箱,在数据进入模型之前进行了标准化。
(二)实验过程、结果及分析
1.Spark MLlib对经典K-means算法的改进
经典K-means聚类算法有两个典型的缺陷:(1)聚类数K的值是预先给定的,未必就是最优解;(2)初始聚类中心是随机选择的,可能会得到一个局部最优聚类,具有较高的平方误差。
对于经典K-means聚类算法的上述缺陷,许多学者提出了不同的改进方法,本文通过计算不同聚类数K的轮廓系数来确定最优聚类数K,轮廓系数结合了聚类的凝聚度和分离度,用于评估聚类的效果。该值介于-1-1之间,值越大,表示聚类效果越好[8]。
对于初始聚类中心的选择,Spark MLlib采用了kmeans++算法,所谓kmeans++算法其实就是在进行标准kmeans优化算法之前执行一个初始化聚类中心的过程,其具体计算步骤如下[9]:
(1)在数据点中随机选择一个聚类中心。
(2)对于每个数据点x,计算x到已选出的所有聚类中心的距离的最小值D(x)。
(4)重复(2)和(3)直到选出K个聚类中心。
(5)执行标准的K-means聚类算法。
2.聚类数K的选取
轮廓线是一种簇内数据一致性的检验和解释的方法,轮廓系数值取值区间为[-1,1],它代表一个对象属于它所在组的合理的程度及属于临近组的不合理程度。当大多数对象都有一个比较高的轮廓系数值时,我们认为这个聚类效果很好。对不同的聚类数K,分别计算其聚类结果的轮廓系数,我们选取K=6来进行聚类。
3.聚类结果分析
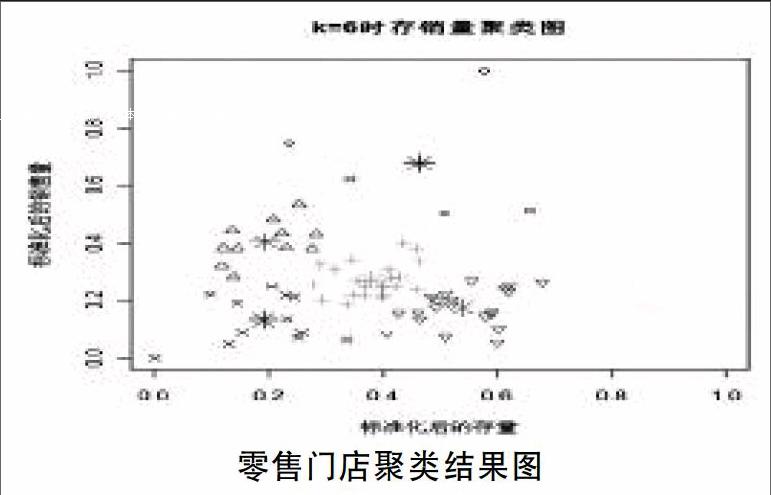
下图给出了卷烟零售户销量和库存数据标准化后聚类分析的可视化结果,从图中可以看出,Kmeans很好的把零售门店区分开了,结果是比较合理的。
依据上述结果,烟草公司可以制定如下的销售优化策略。
(1)如图,参看12个X形点,21个下三角点和5个菱形点,该三类店面销量要明显低于其他三类,而菱形店面存量最多,说明供求关系最不紧张,记作六类店面,下三角形店面平均存量次之,记作五类店面,X形店面平均存量最少,记作四类店面。
(2)12个十字店面销量要明显高于上述三类,供求紧张度1.403也低于上述三类。
(3)相互比较5个圆点店面和11个上三角店面,前者的销量虽然高于后者,但前者的存量却远比后者充裕,因此相比于前者,后者更迫切地需要补充存货。
四、结论
本文根据收集所得的卷烟销售扫码数据采用KMeans+进行聚类分析,将客户分为三大类别,得到了较为合适的分类结果,同时,针对客户的三个类别,给出了相应的销售和库存的管理策略,论文的实践可以为卷烟销售和库存管理策略的制定提供决策支持。
[参 考 文 献]
[1]晁源.互联网思维下的卷烟消费跟踪方法探究[J].中国商贸,2015(24)
[2]黎文阳.大数据处理模型ApacheSpark研究[J].现代计算机(普及版),2015(3)
[3]陈虹君.基于Spark框架的聚类算法研究[J].电脑知识与技术,2015(4),武汉大学学报(理学版),2003,49(5):571-574
[4]唐振坤.基于Spark的机器学习平台设计与实现[D].厦门大学硕士论文,2014
[5]吴哲夫,张彤,肖鹰.基于Spark平台的K-means聚类算法改及并行化实现[J].互联网天地,2016(1)
[6]李彦广.LIYan-guang基于Spark+MLlib分布式学习算法的研究[J].商洛学院学报,2015(2)2000,892:29-46
[7]Feller W. An introduction to probability theory and its applications (3rd ed.)[M]. New York: Wiley, 1969
[8]Silhouette (clustering). (2016, March 25). In Wikipedia, The Free Encyclopedia. Retrieved 16:39, March30, 2016, fromhttps: // en. wikipedia. org / w / index. php? title = Silhouette _ (clustering) & oldid=711931734
[9]K-means++. (2016, March 21). In Wikipedia, The Free Encyclopedia. Retrieved 16:37, March 30,2016,from https://en. wikipedia. org / w / index. php ? title = K-means %2 B% 2B & oldid = 711225275
[責任编辑:王凤娟]
