
个人信用评分模型比较数据挖掘分析
2017-03-25 22:21李卯
时代金融 2017年6期
关键词:随机森林
李卯
【摘要】为了有效控制和防范信贷风险,商业银行必须对借款人做出准确的信用评估。本文通过利用传统的Logistic回归与随机森林模型,分别建立信用评分模型,并比较两个模型的优缺点以达到最佳的预测效果,从而有效的降低商业银行的个人信用评估风险,更好地实现银行利润最大化。
【关键词】信用评分 Logistic回归 随机森林
一、引言
常用的信用评分技术一般分统计学方法和非统计学方法。统计学方法包括线性回归、判别分析、Logistic回归,决策树等,非统计学方法包括线性规划、神经网络、遗传算法等。但是对于这些开发信用模型的技术,哪种方法最好,还没有一致的结论。
Logistic回归方法以其强大的稳健性和泛化能力被较多地应用到评估方法中;神經网络对不完全信息具有很强的处理能力,能够解决现实生活中的非线性问题,而且分类精度非常高,也是优先选择的信用评估方法;支持向量机能处理小样本、高维度的数据,并且获得较高的分类精度,对处于发展阶段的信用评估系统也是一个不错的选择。
总的来说评价指标体系被分为两大类:体现还款能力的指标和体现还款意愿的指标。这些指标相对较容易获得,并且能在一定程度上反映个人的真实还款能力和还款意愿,但是这些指标比较片面,容易出现误判,而且门槛非常高。
本文以真实的信贷数据为分析对象,使用常见的Logistic回归、随机森林来进行研究。利用它们分别建立模型,对客户进行分类,并比较模型预测结果。对比发现,两个模型都有一定的预测能力,能将好坏客户适度地区分开来。
二、样本数据
本文建模时所采用的数据集Credit是一家数据挖掘网站上提供的真实数据,客户资料为一家德国信贷银行的信贷审批数据(German Credit data)。该数据包含了个人客户在向银行提出贷款申请时所提供的个人信息(如:性别、年龄、资产情况等)。其中该数据包括1000条记录,定义了两类信用卡客户,第一类为700个“好客户”,第二类为300个“坏客户”。该数据集中有21个变量,其中20个是特征变量(自变量),而good-bad是响应变量(因变量)。
三、实证研究
(一)Logistic回归分析
在建立Logistic回归模型时,随机选取700样本作为训练集,余下300样本作为测试集,以0.5为概率界限,对训练集样本和测试集样本中的客户进行预测分类。
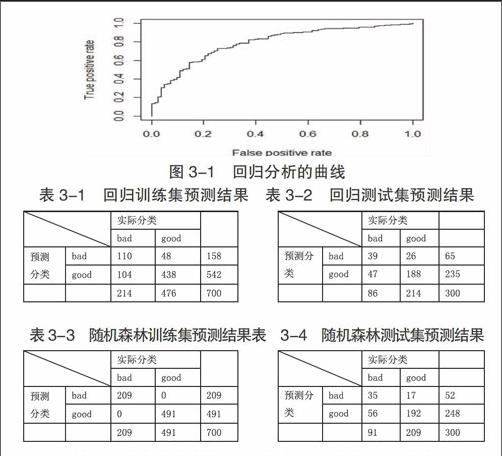
本文利用软件选用逐步变量选择法,从模型的输出结果中,可以计算出一个客户是一个好客户的概率:首先,使用样本中为“好客户”的比率作为阈值。对整个数据集进行预测,虽然总的精度达到0.74,但是对于“坏客户”的预测错误率为74/(12+74)=0.86,没有达到理想中的效果。当阈值为0.5时预测效果没有达到理想状况,因此尝试采用曲线来选择最佳的诊断界限值,使用软件得出回归分析的曲线如图3-1所示。
通过曲线确定的阈值,并由此进行预测,其分类混合矩阵如下所示。
由预测结果可知,测试集样本预测结果精度高达0.76,而且“坏客户”预测为“好客户”的错误率下降到26/(39+26)=0.4。采用ROC曲线来确定阈值,对训练集来说,这种预测方式不仅总的预测精度得到提升,更重要的事对“坏客户”的预测精度得到提升,因为预测成功可能产生违约风险的“坏客户”对于银行来说才是最重要的。
(二)随机森林分析
本文选取500颗树在训练集上建立随机森林模型,与Logistic回归一样,随机选取700样本作为训练集,余下300样本作为测试集,在测试集上进行预测。通过基于OOB数据的模型误判率均值确定随机森林模型当mtry数值为10时误差最小。
由结果可以看到,训练样本误差率为0,测试样本误差率为(56+17)/300=0.24。从结果看,随机森林预测结果的误差率是比较小的。
四、总结
在将信用好的客户判定为信用不好的客户从而拒绝其贷款申请的方面,无论是训练样本还是测试样本,其预测正确精度是:随机森林大于Logistic回归模型;在第二类误判,即将信用不好的客户判定为信用好的客户从而接受其贷款申请方面,无论是训练样本还是测试样本,其预测正确精度是:随机森林大于Logistic回归模型(一般而言,在银行和其他金融机构的实际操作中,第二类误判给银行造成的损失更大)。从整体分类精度来看,随机森林的整体预测精度能达到75%以上,而传统的Logistic回归模型整体分类精度只能达到70%左右。
从以上分析可以得出,两种方法都可用于信用评分模型,其中Logistic回归目前在信用评价领域应用最为广泛,而随机森林算法是数据挖掘领域较为成功的算法。从预测结果也可以看出,模型的稳健性是Logistic回归的优点,而缺点在于其预测精度不如随机森林等数据挖掘算法;对于随机森林算法,其模型的训练效果和预测精度都很好。综上所述,本文认为利用随机森林算法建立信用评分模型比较合适的方法。
传统的分析方法与新型的机器学习方法各有利弊,在选择和运用时要注意具体情况。在此也可以做出如此猜想,将传统的分析方法与机器学习相结合使用。例如,可尝试采用参数方法与非参数方法相结合的方式建立混合模型,即用决策树或随机森林提取特征变量交互作用项,引入到回归方程中,从而完善Logistic回归,起到变量选择,考虑交互作用项的作用。
在国际金融危机背景下,利用先进的计量分析技术构建有效的消费者信用评估体系成为平衡控制风险与追求增长的关键。消费者信用评估是通过建立信用评分模型,对信贷申请客户的后续信用行为进行预测,并基于客户的特征变量将其划分为“好客户”和“坏客户”,其分类精度直接关系信贷的风险。
参考文献
[1]任潇,姜明辉,车凯,王尚.个人信用评估组合模型选择方案研究[J].哈尔滨工业大学学报,2016(5),67-71.
[2]朱晓明,刘治国.信用评分模型综述[J].统计与决策,2007(2):103-105.
[3]萧超武,蔡文学,黄晓字,陈康.基于随机森林的个人信用评估模型研究及实证分析[J].管理科学,2014(6):111-113.
[4]王帅.个人信用评分混合模型研究[D].华东师范大学硕士学位论文,2010.
[5]张丽娜,赵敏.我国商业银行个人信用评分指标体系分析[J].市场周刊(理论研究),2007(8):115-117.
猜你喜欢
南水北调与水利科技(2016年6期)2017-01-06
现代电子技术(2015年15期)2015-08-14
现代电子技术(2015年8期)2015-07-09
